チュートリアル: Azure の SLES 仮想マシンで SQL Server の可用性グループを構成する
適用対象: ![]() Azure VM 上の SQL Server
Azure VM 上の SQL Server
Note
このチュートリアルでは、SQL Server 2022 (16.x) と SUSE Linux Enterprise Server (SLES) v15 を使用しますが、SQL Server 2019 (15.x) と SLES v12 または SLES v15 を使用して、高可用性を構成することもできます。
このチュートリアルでは、次の作業を行う方法について説明します。
- 新しいリソース グループ、可用性セット、Linux 仮想マシン (VM) を作成する
- 高可用性 (HA) を有効にする
- Pacemaker クラスターの作成
- STONITH デバイスを作成してフェンス エージェントを構成する
- SQL Server と mssql-tools を SLES にインストールする
- SQL Server Always On 可用性グループを構成する
- Pacemaker クラスター内に可用性グループ (AG) のリソースを構成する
- フェールオーバーとフェンス エージェントをテストする
このチュートリアルでは、Azure CLI を使用して、Azure にリソースをデプロイします。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
Azure Cloud Shell で Bash 環境を使用します。 詳細については、「Azure Cloud Shell の Bash のクイックスタート」を参照してください。

CLI リファレンス コマンドをローカルで実行する場合、Azure CLI をインストールします。 Windows または macOS で実行している場合は、Docker コンテナーで Azure CLI を実行することを検討してください。 詳細については、「Docker コンテナーで Azure CLI を実行する方法」を参照してください。
ローカル インストールを使用する場合は、az login コマンドを使用して Azure CLI にサインインします。 認証プロセスを完了するには、ターミナルに表示される手順に従います。 その他のサインイン オプションについては、Azure CLI でのサインインに関するページを参照してください。
初回使用時にインストールを求められたら、Azure CLI 拡張機能をインストールします。 拡張機能の詳細については、Azure CLI で拡張機能を使用する方法に関するページを参照してください。
az version を実行し、インストールされているバージョンおよび依存ライブラリを検索します。 最新バージョンにアップグレードするには、az upgrade を実行します。
- この記事では、Azure CLI のバージョン 2.0.30 以降が必要です。 Azure Cloud Shell を使用している場合は、最新バージョンが既にインストールされています。
リソース グループを作成する
複数のサブスクリプションがある場合は、これらのリソースをデプロイするサブスクリプションを設定します。
次のコマンドを使用して、リージョンにリソース グループ <resourceGroupName> を作成します。 <resourceGroupName> は、任意の名前に置き換えてください。 このチュートリアルでは East US 2 を使用します。 詳細については、次のクイックスタートを参照してください。
az group create --name <resourceGroupName> --location eastus2
可用性セットの作成
次の手順は可用性セットの作成です。 Azure Cloud Shell で次のコマンドを実行します。<resourceGroupName> は、実際のリソース グループ名に置き換えてください。 <availabilitySetName> の名前を選択します。
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
コマンドが完了すると、次の結果が得られます。
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
仮想ネットワークとサブネットの作成
IP アドレス範囲が事前に割り当てられた、名前付きサブネットを作成します。 次のコマンドで、これらの値を置き換えます。
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24前のコマンドでは、VNet と、カスタム IP 範囲を含むサブネットを作成します。
可用性セット内に SLES VM を作成する
BYOS (サブスクリプション持ち込み) の SLES v15 SP4 を提供する仮想マシン イメージの一覧を取得します。 SUSE Enterprise Linux 15 SP4 と修正プログラム適用 VM (
sles-15-sp4-basic) を使用することもできます。az vm image list --all --offer "sles-15-sp3-byos" # if you want to search the basic offers you could search using the command below az vm image list --all --offer "sles-15-sp3-basic"BYOS イメージを検索すると、次の結果が表示されます。
[ { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen1", "urn": "SUSE:sles-15-sp3-byos:gen1:2022.05.05", "version": "2022.05.05" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen1", "urn": "SUSE:sles-15-sp3-byos:gen1:2022.07.19", "version": "2022.07.19" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen1", "urn": "SUSE:sles-15-sp3-byos:gen1:2022.11.10", "version": "2022.11.10" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen2", "urn": "SUSE:sles-15-sp3-byos:gen2:2022.05.05", "version": "2022.05.05" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen2", "urn": "SUSE:sles-15-sp3-byos:gen2:2022.07.19", "version": "2022.07.19" }, { "offer": "sles-15-sp3-byos", "publisher": "SUSE", "sku": "gen2", "urn": "SUSE:sles-15-sp3-byos:gen2:2022.11.10", "version": "2022.11.10" } ]このチュートリアルでは
SUSE:sles-15-sp3-byos:gen1:2022.11.10を使用します。重要
可用性グループを設定するには、マシン名の長さが 15 文字未満である必要があります。 ユーザー名に大文字を含めることはできません。また、パスワードは 12 文字以上 72 文字以下である必要があります。
可用性セットに 3 つの VM を作成します。 次のコマンドで、これらの値を置き換えます。
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>- 例: "Standard_D16s_v3"<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "SUSE:sles-15-sp3-byos:gen1:2022.11.10" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
前のコマンドでは、前に定義した VNet を使用して VM を作成します。 さまざまな構成の詳細については、az vm create に関する記事を参照してください。
コマンドには、128 GB のカスタム OS ドライブ サイズを作成するための --os-disk-size-gb パラメーターも含まれています。 後でこのサイズを大きくする場合は、インストールに合わせて適切なフォルダー ボリュームを拡張し、論理ボリューム マネージャー (LVM) を構成します。
各 VM のコマンドが完了すると、次のような結果が得られます。
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/sles1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
作成された VM への接続をテストする
Azure Cloud Shell で次のコマンドを使用して、それぞれの VM に接続します。 自分の VM の IP がわからない場合は、こちらの Azure Cloud Shell のクイックスタートに従ってください。
ssh <username>@<publicIPAddress>
接続に成功すると、Linux ターミナルを表す次の出力が表示されます。
[<username>@sles1 ~]$
「exit」と入力して SSH セッションを終了します。
SUSEConnect に登録して高可用性パッケージをインストールする
このチュートリアルを完了するには、更新プログラムを受け取り、サポートを受けるために、VM を SUSEConnect に登録する必要があります。 これで、HA を有効にするパッケージのセットである High Availability Extension モジュール ("パターン") をインストールできるようになります。
この記事全体を通して各 VM で同じコマンドを実行する必要があるため、各 VM (ノード) の SSH セッションを同時に開いておくと便利です。
複数の sudo コマンドをコピーして貼り付けていて、パスワードの入力が求められる場合、追加のコマンドは実行されません。 各コマンドを個別に実行してください。
各 VM ノードに接続して、次の手順を実行します。
VM を SUSEConnect に登録する
VM ノードを SUSEConnect に登録するには、すべてのノードについて、次のコマンドでこれらの値を置き換えます。
<subscriptionEmailAddress><registrationCode>
sudo SUSEConnect
--url=https://scc.suse.com
-e <subscriptionEmailAddress> \
-r <registrationCode>
High Availability Extension をインストールする
High Availability Extension をインストールするには、すべてのノードで次のコマンドを実行します。
sudo SUSEConnect -p sle-ha/15.3/x86_64 -r <registration code for Partner Subscription for High Availability Extension>
ノード間にパスワードなしの SSH アクセスを構成する
パスワードレス SSH アクセスを使用すると、VM で SSH 公開キーを使用して相互に通信できるようになります。 各ノードで SSH キーを構成し、それらのキーを各ノードにコピーする必要があります。
新しい SSH キーを生成する
必要な SSH キー サイズは 4,096 ビットです。 各 VM で /root/.ssh フォルダーに変更し、次のコマンドを実行します。
ssh-keygen -t rsa -b 4096
この手順では、既存の SSH ファイルを上書きするように求められる場合があります。 このプロンプトに同意する必要があります。 パスフレーズを入力する必要はありません。
SSH 公開キーをコピーする
各 VM 上で、ssh-copy-id コマンドを使って、先ほど作成したノードから公開キーをコピーする必要があります。 ターゲット VM 上でターゲット ディレクトリを指定する場合は、-i パラメーターを使用します。
次のコマンド内の <username> アカウントは、VM の作成時に各ノード用に構成したものと同じアカウントにすることができます。 root アカウントを使うこともできますが、運用環境ではお勧めしません。
sudo ssh-copy-id <username>@sles1
sudo ssh-copy-id <username>@sles2
sudo ssh-copy-id <username>@sles3
各ノードからのパスワードレス アクセスを確認する
SSH 公開キーが各ノードにコピーされたことを確認するには、各ノードから ssh コマンドを使用します。 キーを正しくコピーした場合は、パスワードの入力を求められず、接続は成功します。
この例では、最初の VM (sles1) から 2 番目と 3 番目のノードに接続しています。 繰り返しになりますが、<username> アカウントは、VM の作成時に各ノード用に構成したものと同じアカウントにすることができます。
ssh <username>@sles2
ssh <username>@sles3
各ノードでパスワードを必要とせずに他のノードと通信できるように、3 つのノードすべてからこのプロセスを繰り返します。
名前解決を構成する
名前解決は、DNS を使用するか、各ノードで etc/hosts ファイルを手動で編集することで構成できます。
DNS と Active Directory の詳細については、「Linux ホスト上の SQL Server を Active Directory ドメインに参加させる」を参照してください。
重要
前の例では、プライベート IP アドレスを使用することをお勧めします。 この構成でパブリック IP アドレスを使用すると、設定が失敗し、VM が外部ネットワークに公開されるおそれがあります。
この例で使用されている VM とその IP アドレスを次に示します。
sles1: 10.0.0.85sles2: 10.0.0.86sles3: 10.0.0.87
クラスターを構成する
このチュートリアルでは、最初の VM (sles1) はノード 1、2 番目の VM (sles2) はノード 2、3 番目の VM (sles3) はノード 3 です。 クラスターのインストールの詳細については、「Azure の SUSE Linux Enterprise Server に Pacemaker をセットアップする」を参照してください。
クラスターのインストール
次のコマンドを実行して、ノード 1 に
ha-cluster-bootstrapパッケージをインストールし、ノードを再起動します。 この例では、sles1VM です。sudo zypper install ha-cluster-bootstrapノードが再起動されたら、次のコマンドを実行してクラスターをデプロイします。
sudo crm cluster init --name sqlcluster出力は次の例のようになります。
Do you want to continue anyway (y/n)? y Generating SSH key for root The user 'hacluster' will have the login shell configuration changed to /bin/bash Continue (y/n)? y Generating SSH key for hacluster Configuring csync2 Generating csync2 shared key (this may take a while)...done csync2 checking files...done Detected cloud platform: microsoft-azure Configure Corosync (unicast): This will configure the cluster messaging layer. You will need to specify a network address over which to communicate (default is eth0's network, but you can use the network address of any active interface). Address for ring0 [10.0.0.85] Port for ring0 [5405] Configure SBD: If you have shared storage, for example a SAN or iSCSI target, you can use it avoid split-brain scenarios by configuring SBD. This requires a 1 MB partition, accessible to all nodes in the cluster. The device path must be persistent and consistent across all nodes in the cluster, so /dev/disk/by-id/* devices are a good choice. Note that all data on the partition you specify here will be destroyed. Do you wish to use SBD (y/n)? n WARNING: Not configuring SBD - STONITH will be disabled. Hawk cluster interface is now running. To see cluster status, open: https://10.0.0.85:7630/ Log in with username 'hacluster', password 'linux' WARNING: You should change the hacluster password to something more secure! Waiting for cluster..............done Loading initial cluster configuration Configure Administration IP Address: Optionally configure an administration virtual IP address. The purpose of this IP address is to provide a single IP that can be used to interact with the cluster, rather than using the IP address of any specific cluster node. Do you wish to configure a virtual IP address (y/n)? y Virtual IP []10.0.0.89 Configuring virtual IP (10.0.0.89)....done Configure Qdevice/Qnetd: QDevice participates in quorum decisions. With the assistance of a third-party arbitrator Qnetd, it provides votes so that a cluster is able to sustain more node failures than standard quorum rules allow. It is recommended for clusters with an even number of nodes and highly recommended for 2 node clusters. Do you want to configure QDevice (y/n)? n Done (log saved to /var/log/crmsh/ha-cluster-bootstrap.log)次のコマンドを使用して、ノード 1 のクラスターの状態を確認します。
sudo crm status成功した場合、出力には次のテキストが含まれています。
1 node configured 1 resource instance configuredすべてのノードで、次のコマンドを使用して、
haclusterのパスワードをより安全なものに変更します。rootのユーザー パスワードも変更する必要があります。sudo passwd haclustersudo passwd rootノード 2 とノード 3 で次のコマンドを実行して、最初に
crmshパッケージをインストールします。sudo zypper install crmsh次に、コマンドを実行してクラスターを参加させます。
sudo crm cluster join想定される対話の一部を次に示します。
Join This Node to Cluster: You will be asked for the IP address of an existing node, from which configuration will be copied. If you have not already configured passwordless ssh between nodes, you will be prompted for the root password of the existing node. IP address or hostname of existing node (e.g.: 192.168.1.1) []10.0.0.85 Configuring SSH passwordless with root@10.0.0.85 root@10.0.0.85's password: Configuring SSH passwordless with hacluster@10.0.0.85 Configuring csync2...done Merging known_hosts WARNING: scp to sles2 failed (Exited with error code 1, Error output: The authenticity of host 'sles2 (10.1.1.5)' can't be established. ECDSA key fingerprint is SHA256:UI0iyfL5N6X1ZahxntrScxyiamtzsDZ9Ftmeg8rSBFI. Are you sure you want to continue connecting (yes/no/[fingerprint])? lost connection ), known_hosts update may be incomplete Probing for new partitions...done Address for ring0 [10.0.0.86] Hawk cluster interface is now running. To see cluster status, open: https://10.0.0.86:7630/ Log in with username 'hacluster', password 'linux' WARNING: You should change the hacluster password to something more secure! Waiting for cluster.....done Reloading cluster configuration...done Done (log saved to /var/log/crmsh/ha-cluster-bootstrap.log)すべてのマシンをクラスターに参加させたら、リソースを確認して、すべての VM がオンラインになっていることを確認します。
sudo crm status次の出力が表示されます。
Stack: corosync Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum Last updated: Mon Mar 6 18:01:17 2023 Last change: Mon Mar 6 17:10:09 2023 by root via cibadmin on sles1 3 nodes configured 1 resource instance configured Online: [ sles1 sles2 sles3 ] Full list of resources: admin-ip (ocf::heartbeat:IPaddr2): Started sles1クラスター リソース コンポーネントをインストールします。 すべてのノードで次のコマンドを実行します。
sudo zypper in socatazure-lbコンポーネントをインストールします。 すべてのノードで次のコマンドを実行します。sudo zypper in resource-agentsオペレーティング システムの構成。 すべてのノードで次の手順を一通り実行します。
構成ファイルを編集します。
sudo vi /etc/systemd/system.confDefaultTasksMaxの値を4096に変更します。#DefaultTasksMax=512 DefaultTasksMax=4096vi エディターを保存して終了します。
この設定をアクティブにするには、次のコマンドを実行します。
sudo systemctl daemon-reload変更が成功したかどうかをテストします。
sudo systemctl --no-pager show | grep DefaultTasksMax
ダーティ キャッシュのサイズを小さくします。 すべてのノードで次の手順を一通り実行します。
システム制御構成ファイルを編集します。
sudo vi /etc/sysctl.confファイルに次の 2 行を追加します。
vm.dirty_bytes = 629145600 vm.dirty_background_bytes = 314572800vi エディターを保存して終了します。
次のコマンドを使用して、すべてのノードに Azure Python SDK をインストールします。
sudo zypper install fence-agents # Install the Azure Python SDK on SLES 15 or later: # You might need to activate the public cloud extension first. In this example, the SUSEConnect command is for SLES 15 SP1 SUSEConnect -p sle-module-public-cloud/15.1/x86_64 sudo zypper install python3-azure-mgmt-compute sudo zypper install python3-azure-identity
フェンス エージェントを構成する
STONITH デバイスでは、フェンス エージェントが提供されます。 このチュートリアルでは、以下の手順が変更されています。 詳細については、Azure フェンス エージェントの STONITH デバイスの作成に関するページを参照してください。
Azure フェンス エージェントのバージョンを確認して、更新されていることを確認します。 次のコマンドを使用します。
sudo zypper info resource-agents
次の例のような出力が表示されます。
Information for package resource-agents:
----------------------------------------
Repository : SLE-Product-HA15-SP3-Updates
Name : resource-agents
Version : 4.8.0+git30.d0077df0-150300.8.37.1
Arch : x86_64
Vendor : SUSE LLC <https://www.suse.com/>
Support Level : Level 3
Installed Size : 2.5 MiB
Installed : Yes (automatically)
Status : up-to-date
Source package : resource-agents-4.8.0+git30.d0077df0-150300.8.37.1.src
Upstream URL : http://linux-ha.org/
Summary : HA Reusable Cluster Resource Scripts
Description : A set of scripts to interface with several services
to operate in a High Availability environment for both
Pacemaker and rgmanager service managers.
新しいアプリケーションを Microsoft Entra ID に登録します
Microsoft Entra ID (旧称 Azure Active Directory) に新しいアプリケーションを登録するには、次の手順に従います。
- 「 https://portal.azure.com 」を参照してください。
- Microsoft Entra ID の [プロパティ] ウィンドウを開き、
Tenant IDをメモしておきます。 - [アプリの登録] を選択します。
- [新規登録] を選択します。
- 名前を入力します (
<resourceGroupName>-appなど)。 [サポートされているアカウントの種類] については、[Accounts in this organizational directory only (Microsoft only - Single tenant)] (この組織のディレクトリ内のアカウントのみ (Microsoft のみ - 単一テナント)) を選択します。 - [リダイレクト URI] で [Web] を選択して URL (たとえば http://localhost) など) を入力し、[追加] を選択します。 サインオン URL は、任意の有効な URL を指定することができます。 完了したら、[登録] を選択します。
- 新しいアプリの登録用に [Certificates and Secrets] を選択し、[新しいクライアント シークレット] を選択します。
- 新しいキー (クライアント シークレット) の記述を入力し、[追加] を選択します。
- シークレットの値を書き留めます。 これは、サービス プリンシパルのパスワードとして使用します。
- 概要を選択します。 アプリケーション ID をメモします。 これは、サービス プリンシパルのユーザー名 (下記の手順のログイン ID) として使用します。
フェンス エージェントのカスタム ロールを作成する
「Azure CLI を使用して Azure カスタム ロールを作成する」チュートリアルに従ってください。
JSON ファイルは次の例のようになります。
<username>を任意の名前に置き換えます。 これは、このロール定義を作成するときに重複が発生しないようにするためです。<subscriptionId>は、実際の Azure サブスクリプション ID に置き換えます。
{
"Name": "Linux Fence Agent Role-<username>",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [
],
"AssignableScopes": [
"/subscriptions/<subscriptionId>"
]
}
ロールを追加するには、次のコマンドを実行します。
<filename>は、対象のファイルの名前に置き換えます。- ファイルが保存されているフォルダー以外のパスからコマンドを実行する場合は、ファイルのフォルダー パスをコマンドに含めます。
az role definition create --role-definition "<filename>.json"
次の出力が表示されます。
{
"assignableScopes": [
"/subscriptions/<subscriptionId>"
],
"description": "Allows to power-off and start virtual machines",
"id": "/subscriptions/<subscriptionId>/providers/Microsoft.Authorization/roleDefinitions/<roleNameId>",
"name": "<roleNameId>",
"permissions": [
{
"actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"dataActions": [],
"notActions": [],
"notDataActions": []
}
],
"roleName": "Linux Fence Agent Role-<username>",
"roleType": "CustomRole",
"type": "Microsoft.Authorization/roleDefinitions"
}
サービス プリンシパルにカスタム ロールを割り当てる
最後の手順で作成したカスタム ロール Linux Fence Agent Role-<username> をサービス プリンシパルに割り当てます。 すべてのノードに対して、これらの手順を繰り返します。
警告
ここからは所有者ロールを使用しないでください。
- [https://resources.azure.com](https://portal.azure.com) に移動します
- [すべてのリソース] ペインを開きます
- 1 つ目のクラスター ノードの仮想マシンを選択します
- [アクセス制御 (IAM)] を選択します
- [ロールの割り当ての追加] を選択します
- [ロール] 一覧からロール
Linux Fence Agent Role-<username>を選択します - [アクセスの割り当て先] は既定値の
Users, group, or service principalのままにしておきます。 - [選択] 一覧に、前に作成したアプリケーションの名前 (
<resourceGroupName>-appなど) を入力します。 - [保存] を選択します。
STONITH デバイスを作成する
ノード 1 で次のコマンドを実行します。
<ApplicationID>は、自分のアプリケーション登録の ID 値に置き換えます。<servicePrincipalPassword>は、クライアント シークレットの値に置き換えます。<resourceGroupName>は、このチュートリアル用に使用しているサブスクリプションのリソース グループに置き換えます。<tenantID>と<subscriptionId>は、自分の Azure サブスクリプションの値に置き換えます。
crm configureを実行して crm プロンプトを開きます。sudo crm configurecrm プロンプトで、次のコマンドを実行してリソースのプロパティを構成します。これにより、次の例に示すように
rsc_st_azureというリソースが作成されます。primitive rsc_st_azure stonith:fence_azure_arm params subscriptionId="subscriptionID" resourceGroup="ResourceGroup_Name" tenantId="TenantID" login="ApplicationID" passwd="servicePrincipalPassword" pcmk_monitor_retries=4 pcmk_action_limit=3 power_timeout=240 pcmk_reboot_timeout=900 pcmk_host_map="sles1:sles1;sles2:sles2;sles3:sles3" op monitor interval=3600 timeout=120 commit quit次のコマンドを実行して、フェンス エージェントを構成します。
sudo crm configure property stonith-timeout=900 sudo crm configure property stonith-enabled=true sudo crm configure property concurrent-fencing=trueクラスターの状態を確認して、STONITH が有効になっていることを確認します。
sudo crm status次のテキストのような出力が表示されます。
Stack: corosync Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum Last updated: Mon Mar 6 18:20:17 2023 Last change: Mon Mar 6 18:10:09 2023 by root via cibadmin on sles1 3 nodes configured 2 resource instances configured Online: [ sles1 sles2 sles3 ] Full list of resources: admin-ip (ocf::heartbeat:IPaddr2): Started sles1 rsc_st_azure (stonith:fence_azure_arm): Started sles2
SQL Server と mssql-tools をインストールする
以下のセクションを使用して、SQL Server と mssql-tools をインストールします。 詳細については、SUSE Linux Enterprise Server への SQL Server のインストールに関するページを参照してください。
このセクションのすべてのノードでこれらの手順を実行します。
SQL Server を VM にインストールする
SQL Server をインストールするには、次のコマンドを使用します。
Microsoft SQL Server 2019 SLES リポジトリ構成ファイルをダウンロードします。
sudo zypper addrepo -fc https://packages.microsoft.com/config/sles/15/mssql-server-2022.repoリポジトリを最新の情報に更新します。
sudo zypper --gpg-auto-import-keys refreshMicrosoft パッケージの署名キーをシステムに確実にインストールするには、次のコマンドでキーをインポートします。
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc次のコマンドを実行して SQL Server をインストールします。
sudo zypper install -y mssql-serverパッケージのインストールが完了したら、
mssql-conf setupを実行し、プロンプトに従って SA パスワードを設定し、エディションを選択します。sudo /opt/mssql/bin/mssql-conf setupNote
SA アカウントには必ず強力なパスワードを指定してください (大文字と小文字、10 進数の数字、英数字以外の記号を含む、最小 8 文字の長さ)。
構成が完了したら、サービスが実行されていることを確認します。
systemctl status mssql-server
SQL Server コマンドライン ツールをインストールする
次の手順で SQL Server コマンドライン ツールの sqlcmd と bcp をインストールします。
Zypper に Microsoft SQL Server リポジトリを追加します。
sudo zypper addrepo -fc https://packages.microsoft.com/config/sles/15/prod.repoリポジトリを最新の情報に更新します。
sudo zypper --gpg-auto-import-keys refreshunixODBC開発者パッケージと共に mssql-tools をインストールします。 詳細については、「Microsoft ODBC Driver for SQL Server をインストールする (Linux)」を参照してください。sudo zypper install -y mssql-tools unixODBC-devel
便宜上、PATH 環境変数に /opt/mssql-tools/bin/ を追加することができます。 完全なパスを指定せずにツールを実行できます。 次のコマンドを実行して、ログイン セッションと対話型および非ログイン セッションの両方の PATH を変更します。
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc
source ~/.bashrc
SQL Server の高可用性エージェントをインストールする
すべてのノードで次のコマンドを実行して、SQL Server の高可用性エージェント パッケージをインストールします。
sudo zypper install mssql-server-ha
高可用性サービスのポートを開く
SQL Server および HA サービスのすべてのノードで、ファイアウォール ポート 1433、2224、3121、5022、5405、21064 を開くことができます。
sudo firewall-cmd --zone=public --add-port=1433/tcp --add-port=2224/tcp --add-port=3121/tcp --add-port=5022/tcp --add-port=5405/tcp --add-port=21064 --permanent sudo firewall-cmd --reload
可用性グループを構成する
次の手順を使用して、対象の VM の SQL Server Always On 可用性グループを構成します。 詳細については、「Linux で高可用性を実現するために SQL Server の Always On 可用性グループを構成する」を参照してください
可用性グループを有効にして SQL Server を再起動する
SQL Server インスタンスをホストする各ノードで可用性グループを有効にします。 その後、mssql-server サービスを再起動します。 各ノードで、次のコマンドを実行します。
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
証明書を作成する
Microsoft では、AG エンドポイントに対する Active Directory 認証をサポートしていません。 そのため、AG エンドポイントの暗号化には証明書を使用する必要があります。
SQL Server Management Studio (SSMS) または sqlcmd を使用して、すべてのノードに接続します。 次のコマンドを実行して、AlwaysOn_health セッションを有効にし、マスター キーを作成します。
重要
自分の SQL Server インスタンスにリモートで接続する場合は、ファイアウォールでポート 1433 を開いておく必要があります。 さらに、各 VM の NSG でポート 1433 へのインバウンド接続を許可する必要があります。 インバウンド セキュリティ規則の作成の詳細については、「セキュリティ規則を作成する」を参照してください。
<MasterKeyPassword>は、実際のパスワードに置き換えます。
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GOSSMS または sqlcmd を使用してプライマリ レプリカに接続します。 以下のコマンドを実行すると、プライマリ SQL Server レプリカの
/var/opt/mssql/data/dbm_certificate.cerに証明書が作成され、var/opt/mssql/data/dbm_certificate.pvkに秘密キーが作成されます。<PrivateKeyPassword>は、実際のパスワードに置き換えます。
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
exit コマンドを実行して sqlcmd セッションを終了し、SSH セッションに戻ります。
証明書をセカンダリ レプリカにコピーし、サーバー上に証明書を作成します
作成された 2 つのファイルを、可用性レプリカをホストするすべてのサーバー上の同じ場所にコピーします。
プライマリ サーバー上で次の
scpコマンドを実行して、証明書をターゲット サーバーにコピーします。<username>とsles2を、使用しているユーザー名とターゲット VM 名に置き換えます。- すべてのセカンダリ レプリカに対してこのコマンドを実行します。
Note
root 環境が提供される
sudo -iを実行する必要はありません。 代わりに、各コマンドの先頭でsudoコマンドを実行できます。# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>ターゲット サーバー上で、次のコマンドを実行します。
<username>は、実際のユーザー名に置き換えます。mvコマンドにより、ある場所から別の場所にファイルまたはディレクトリが移動されます。chownコマンドは、ファイル、ディレクトリ、またはリンクの所有者とグループを変更するために使用します。- すべてのセカンダリ レプリカに対してこれらのコマンドを実行します。
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*次の Transact-SQL スクリプトでは、プライマリ SQL Server レプリカ上に作成したバックアップから証明書を作成します。 強力なパスワードでスクリプトを更新してください。 解読パスワードは、前の手順で .pvk ファイルの作成に使ったのと同じパスワードです。 証明書を作成するには、すべてのセカンダリ サーバーで sqlcmd または SSMS を使用して次のスクリプトを実行します。
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
すべてのレプリカにデータベース ミラーリング エンドポイントを作成する
sqlcmd または SSMS を使用して、すべての SQL Server インスタンスで次のスクリプトを実行します。
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
可用性グループを作成する
sqlcmd または SSMS を使用して、プライマリ レプリカをホストする SQL Server インスタンスに接続します。 次のコマンドを実行して、可用性グループを作成します。
ag1を、希望する AG 名に置き換えます。sles1、sles2、およびsles3の値は、レプリカをホストする SQL Server インスタンスの名前に置き換えます。
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'sles1'
WITH (
ENDPOINT_URL = N'tcp://sles1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'sles2'
WITH (
ENDPOINT_URL = N'tcp://sles2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'sles3'
WITH (
ENDPOINT_URL = N'tcp://sles3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Pacemaker 用の SQL Server ログインを作成する
すべての SQL Server インスタンスで、Pacemaker 用 SQL Server ログインを作成します。 次の Transact-SQL により、ログインが作成されます。
<password>は、独自の複雑なパスワードに置き換えます。
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
すべての SQL Server インスタンスで、SQL Server ログインに使用される資格情報を保存します。
ファイルを作成します。
sudo vi /var/opt/mssql/secrets/passwdファイルに次の 2 行を追加します。
pacemakerLogin <password>vi エディターを終了するには、まず Esc キーを押し、コマンド
:wqを入力してファイルを書き込み、終了します。ファイルが root によってのみ読み取り可能になるようにします。
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
セカンダリ レプリカを可用性グループに参加させる
対象のセカンダリ レプリカで次のコマンドを実行して、AG に参加させます。
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOプライマリ レプリカと各セカンダリ レプリカで次の Transact-SQL スクリプトを実行します。
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GOセカンダリ レプリカを参加させたら、 [Always On 高可用性] ノードを展開して、SSMS オブジェクト エクスプローラーでそれらを確認できます。
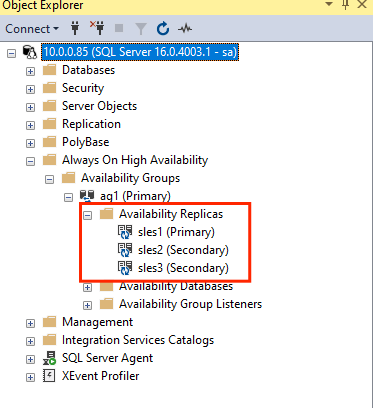
可用性グループにデータベースを追加する
このセクションは、可用性グループへのデータベースの追加について説明する記事に従います。
この手順では、次の Transact-SQL コマンドを使用します。 プライマリ レプリカ上でこれらのコマンドを実行します。
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery model
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
セカンダリ サーバーにデータベースが作成されたことを確認する
各セカンダリ SQL Server レプリカで次のクエリを実行して、db1 データベースが作成され、SYNCHRONIZED 状態にあるかどうかを確認します。
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
db1 に対して synchronization_state_desc が SYNCHRONIZED と示される場合は、レプリカが同期されていることを意味します。 セカンダリでは、プライマリ レプリカの db1 が表示されます。
Pacemaker クラスター内に可用性グループのリソースを作成する
Note
バイアスフリーなコミュニケーション
この記事には、この文脈で使用した場合に不快感を与えると Microsoft が考える slave (スレーブ、奴隷) という用語の言及が含まれています。 これはソフトウェアに現在表示されるものであるため、この記事に出現します。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
この記事は、Pacemaker クラスターへの可用性グループのリソースの作成について説明するガイドを参考にしています。
Pacemaker を有効にする
自動的に開始されるように Pacemaker を有効にします。
クラスター内のすべてのノードで、次のコマンドを実行します。
sudo systemctl enable pacemaker
AG クラスター リソースを作成する
crm configureを実行して crm プロンプトを開きます。sudo crm configurecrm プロンプトで、次のコマンドを実行してリソース プロパティを構成します。 次のコマンドを使用すると、可用性グループ
ag1に、リソースag_clusterが作成されます。primitive ag_cluster ocf:mssql:ag params ag_name="ag1" meta failure-timeout=60s op start timeout=60s op stop timeout=60s op promote timeout=60s op demote timeout=10s op monitor timeout=60s interval=10s op monitor timeout=60s interval=11s role="Master" op monitor timeout=60s interval=12s role="Slave" op notify timeout=60s ms ms-ag_cluster ag_cluster meta master-max="1" master-node-max="1" clone-max="3" clone-node-max="1" notify="true" commit quitヒント
「
quit」と入力して、crm プロンプトを終了します。プライマリ ノードと同じノードで実行されるように、仮想 IP のコロケーション制約を設定します。
sudo crm configure colocation vip_on_master inf: admin-ip ms-ag_cluster: Master commit quitIP アドレスが事前フェールオーバー セカンダリのノードを一時的に指さないようにするには、順序制約を追加します。 次のコマンドを実行して、順序制約を作成します。
sudo crm configure order ag_first inf: ms-ag_cluster:promote admin-ip:start commit quit次のコマンドを使用して、クラスターの状態を確認します。
sudo crm status出力は次の例のようになります。
Cluster Summary: * Stack: corosync * Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum * Last updated: Mon Mar 6 18:38:17 2023 * Last change: Mon Mar 6 18:38:09 2023 by root via cibadmin on sles1 * 3 nodes configured * 5 resource instances configured Node List: * Online: [ sles1 sles2 sles3 ] Full List of Resources: * admin-ip (ocf::heartbeat:IPaddr2): Started sles1 * rsc_st_azure (stonith:fence_azure_arm): Started sles2 * Clone Set: ms-ag_cluster [ag_cluster] (promotable): * Masters: [ sles1 ] * Slaves: [ sles2 sles3 ]次のコマンドを実行して、制約を確認します。
sudo crm configure show出力は次の例のようになります。
node 1: sles1 node 2: sles2 node 3: sles3 primitive admin-ip IPaddr2 \ params ip=10.0.0.93 \ op monitor interval=10 timeout=20 primitive ag_cluster ocf:mssql:ag \ params ag_name=ag1 \ meta failure-timeout=60s \ op start timeout=60s interval=0 \ op stop timeout=60s interval=0 \ op promote timeout=60s interval=0 \ op demote timeout=10s interval=0 \ op monitor timeout=60s interval=10s \ op monitor timeout=60s interval=11s role=Master \ op monitor timeout=60s interval=12s role=Slave \ op notify timeout=60s interval=0 primitive rsc_st_azure stonith:fence_azure_arm \ params subscriptionId=xxxxxxx resourceGroup=amvindomain tenantId=xxxxxxx login=xxxxxxx passwd="******" cmk_monitor_retries=4 pcmk_action_limit=3 power_timeout=240 pcmk_reboot_timeout=900 pcmk_host_map="sles1:sles1;les2:sles2;sles3:sles3" \ op monitor interval=3600 timeout=120 ms ms-ag_cluster ag_cluster \ meta master-max=1 master-node-max=1 clone-max=3 clone-node-max=1 notify=true order ag_first Mandatory: ms-ag_cluster:promote admin-ip:start colocation vip_on_master inf: admin-ip ms-ag_cluster:Master property cib-bootstrap-options: \ have-watchdog=false \ dc-version="2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712" \ cluster-infrastructure=corosync \ cluster-name=sqlcluster \ stonith-enabled=true \ concurrent-fencing=true \ stonith-timeout=900 rsc_defaults rsc-options: \ resource-stickiness=1 \ migration-threshold=3 op_defaults op-options: \ timeout=600 \ record-pending=true
[テスト フェールオーバー]
これまでの構成が成功していることを確認するために、フェールオーバーをテストします。 詳細については、「Linux での Always On 可用性グループのフェールオーバー」を参照してください。
次のコマンドを実行して、プライマリ レプリカを
sles2に手動でフェールオーバーします。sles2は、実際のサーバー名の値に置き換えてください。sudo crm resource move ag_cluster sles2出力は次の例のようになります。
INFO: Move constraint created for ms-ag_cluster to sles2 INFO: Use `crm resource clear ms-ag_cluster` to remove this constraintクラスターの状態を確認します。
sudo crm status出力は次の例のようになります。
Cluster Summary: * Stack: corosync * Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum * Last updated: Mon Mar 6 18:40:02 2023 * Last change: Mon Mar 6 18:39:53 2023 by root via crm_resource on sles1 * 3 nodes configured * 5 resource instances configured Node List: * Online: [ sles1 sles2 sles3 ] Full List of Resources: * admin-ip (ocf::heartbeat:IPaddr2): Stopped * rsc_st_azure (stonith:fence_azure_arm): Started sles2 * Clone Set: ms-ag_cluster [ag_cluster] (promotable): * Slaves: [ sles1 sles2 sles3 ]しばらくすると、
sles2VM がプライマリになり、他の 2 つの VM がセカンダリになります。 もう一度sudo crm statusを実行し、出力を確認します。出力は次のようになります。Cluster Summary: * Stack: corosync * Current DC: sles1 (version 2.0.5+20201202.ba59be712-150300.4.30.3-2.0.5+20201202.ba59be712) - partition with quorum * Last updated: Tue Mar 6 22:00:44 2023 * Last change: Mon Mar 6 18:42:59 2023 by root via cibadmin on sles1 * 3 nodes configured * 5 resource instances configured Node List: * Online: [ sles1 sles2 sles3 ] Full List of Resources: * admin-ip (ocf::heartbeat:IPaddr2): Started sles2 * rsc_st_azure (stonith:fence_azure_arm): Started sles2 * Clone Set: ms-ag_cluster [ag_cluster] (promotable): * Masters: [ sles2 ] * Slaves: [ sles1 sles3 ]crm config showを使用して、もう一度制約を確認します。 手動フェールオーバーが理由で別の制約が追加されたことを確認します。次のコマンドを使用して、ID が
cli-prefer-ag_clusterの制約を削除します。crm configure delete cli-prefer-ms-ag_cluster commit
フェンスをテストする
次のコマンドを実行して、STONITH をテストできます。 sles3 に対して sles1 から次のコマンドを実行してみてください。
sudo crm node fence sles3