Azure SQL Managed Instance によるビジネス継続性の概要
適用対象: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
この記事では、Azure SQL Managed Instance の事業継続とディザスター リカバリー機能の概要について説明し、データの損失やインスタンスとアプリケーションが使用できなくなる可能性がある破壊的イベントからの復旧に関するオプションと推奨事項について説明します。 ユーザーまたはアプリケーション エラーがデータ整合性に影響を及ぼすとき、Azure Availability Zones またはリージョンでシステム停止が発生したとき、あるいはアプリケーションにメンテナンスが必要なときの対処方法について説明します。
概要
Azure SQL Managed Instance のビジネス継続性 とは、可用性、高可用性とディザスターを提供することで、中断が発生した場合でもビジネスを継続できるメカニズム、ポリシー、手順を指します。
ほとんどの場合、クラウド環境で発生する可能性がある破壊的なイベントは SQL Managed Instance によって処理されて、アプリケーションとビジネス プロセスの実行が維持されます。 ただし、次のようないくつかの破壊的なイベントがあり、軽減には時間がかかる場合があります。
- ユーザーが誤ってテーブルの行を削除または更新した。
- 悪意のある攻撃者がデータの削除やデータベースの削除に成功した。
- 致命的な自然災害イベントにより、データセンターまたは可用性ゾーンまたはリージョンがダウンします。
- 構成の変更、ソフトウェアのバグ、またはハードウェア コンポーネントの障害によって発生する、まれなデータセンター、可用性ゾーン、またはリージョン全体の停止。
可用性
Azure SQL Managed Instance には、ソフトウェアまたはハードウェアの障害から保護するコアの回復性と信頼性の保証が付属しています。 データベースのバックアップは自動化されており、破損や偶発的な削除からデータを保護します。 サービスとしてのプラットフォーム (PaaS) として、Azure SQL Managed Instance サービスは、業界をリードする可用性 SLA が 99.99% の既製機能として可用性を提供します。
高可用性
Azure クラウド環境で高可用性を実現するには、ゾーン冗長を有効にして、インスタンスが可用性ゾーンを使用してゾーン障害に対する回復性を確保します。 多くの Azure リージョンでは可用性ゾーンが提供されます。可用性ゾーンは、独立した電源、冷却、ネットワーク インフラストラクチャを持つリージョン内のデータ センターのグループで区切られます。 可用性ゾーンは、1 つのゾーンで障害が発生した場合に、リージョンのサービス、容量、および高可用性を再メインゾーンで提供するように設計されています。 ゾーン冗長を有効にすると、インスタンスはゾーンハードウェアとソフトウェアの障害に対する回復性を持ち、復旧はアプリケーションに対して透過的になります。 高可用性が有効になっている場合、Azure SQL Managed Instance サービスは 99.99% の高可用性 SLA を実現します。
障害復旧
リージョン間で可用性と冗長性を高めるために、ディザスター リカバリー機能を有効にして、致命的なリージョン障害からインスタンスを迅速に復旧できます。 Azure SQL Managed Instance のディザスタリカバリのオプションは次のとおりです。
- フェールオーバー グループ を使用すると、プライマリ インスタンスとセカンダリ インスタンスの間で継続的な同期が可能になります。 フェールオーバー グループは、読み取り/書き込みおよび読み取り専用のリスナー エンドポイントを提供しますメイン変更されないため、フェールオーバー後にアプリケーションの接続文字列を更新する必要はありません。
- geo リストア を使用すると、プライマリ リージョン内のデータベースにアクセスできないときに、Azure リージョン内の既存のインスタンスに新しいデータベースを作成して、geo レプリケートされたバックアップから復元することで、リージョンの停止から復旧できます。
事業継続を提供する機能
インスタンスの観点から、発生する可能性のある 4 つの主要な障害シナリオがあります。 次の表に、潜在的なビジネス中断シナリオを軽減するために使用できる SQL Managed Instance のビジネス継続性機能を示します。
| ビジネス中断シナリオ | ビジネス継続性に関係する機能 |
|---|---|
| データベースノードに影響を及ぼすローカルハードウェアまたはソフトウェアの障害。 | ローカルのハードウェアとソフトウェアの障害を軽減するため、SQL Managed Instance には高可用性アーキテクチャが組み込まれています。これにより、最大 99.99% の可用性 SLA でこれらの障害からの自動復旧が保証されます。 |
| 通常はアプリケーションのバグや人的ミスによって発生するデータの破損または削除。 このような障害はアプリケーション固有であり、通常、 サービスでは検出できません。 | SQL Managed Instance では、データ損失からビジネスを守るため、データベースの完全バックアップが毎週、データベースの差分バックアップが 12 時間または 24 時間ごと、トランザクション ログ バックアップを 5 分~ 10 分ごとに、自動的に作成されます。 デフォルトでは、バックアップは geo 冗長ストレージに 7 日間保存され、ポイントインタイム リストアのバックアップ保存期間は最大 35 日間まで設定可能です。 インスタンスが削除されていない場合、または長期保存を構成している場合、削除された時点に削除されたデータベースをリストアできます。 |
| まれなデータセンターまたは可用性ゾーンの停止。自然災害イベント、構成の変更、ソフトウェアのバグ、ハードウェア コンポーネントの障害が原因である可能性があります。 | データセンターまたは可用性ゾーン レベルの停止を軽減するには、SQL Managed Instance で Azure Availability Zones を使用するためのゾーン冗長性を有効にし、Azure リージョン内の複数の物理ゾーン間で冗長性を提供します。 ゾーン冗長を有効にすると、最大 99.99% の高可用性 SLA を使用して、ゾーン障害に対するマネージド インスタンスの回復性が確保されます。 |
| 致命的な自然災害が原因である可能性がある、すべての可用性ゾーンとそのデータセンターに影響を与えるまれなリージョンの停止。 | リージョン全体の停止を軽減するには、次のいずれかのオプションを使用してディザスター リカバリーを有効にします。 - フェールオーバーに使用されるセカンダリ リージョン内のレプリカへのフェールオーバー グループとの継続的なデータ同期。 - geo リストアを使用するために、バックアップストレージの冗長性をジオ冗長バックアップストレージに設定します。 |
RTO と RPO
ビジネス継続性計画を開発するときは、破壊的なイベントが発生してから、アプリケーションが完全に復旧するまでの最大許容時間について理解します。 アプリケーションを完全に復旧するために必要な時間は、目標復旧時間 (RTO) と呼ばれます。 また、予期しない破壊的なイベントからの復旧中にアプリケーションが損失を許容できる最大データ更新 (期間) 量についても理解しなければなりません。 潜在的なデータ損失は、目標復旧時点 (RPO) と呼ばれます。
次の表で、各ビジネス継続性オプションの RPO と RTO の比較を示します。
| ビジネス継続性オプション | RTO: ダウンタイム | RPO: データ損失なし |
|---|---|---|
| 高可用性 (ゾーン冗長の使用) |
通常は、30 秒未満です。 | 0 |
| ディザスター リカバリー (顧客管理フェールオーバー ポリシーでのフェールオーバー グループの使用) |
通常は、60 秒未満です。 | 0 以上 (レプリケートされていない破壊的イベントの前のデータ変更によって異なります) |
geo 復元を使用したディザスター リカバリー |
12 時間 | 1 時間 |
ビジネス継続性チェックリスト
可用性を最大化し、より高いビジネス継続性を実現するための規範的な推奨事項については、次を参照してください。
同じ Azure リージョン内でデータベースを復旧する
自動データベース バックアップを使用すると、過去の特定の時点にデータベースを復元できます。 この方法で、人的ミスによるデータ破損から復旧できます。 ポイントインタイム リストア(PITR)により、破損イベントが発生する前のデータの状態を表す新しいデータベースを、同じインスタンスまたは異なるインスタンスに作成できます。 復元操作は、ターゲット インスタンスの現在のワークロードにも依存するデータ操作のサイズです。 非常に大規模なデータベースや非常にアクティブなデータベースの場合、復旧にはさらに長い時間がかかることがあります。 復旧時間について詳しくは、データベースの復旧時間に関するページをご覧ください。
ポイントインタイム リストア (PITR) のサポートされている最大バックアップ保持期間がアプリケーションに十分でない場合は、データベースの長期保有期間 (LTR) ポリシーを構成することで、保持期間を延長できます。 詳細については、「Long-term backup retention」(長期バックアップ リテンション) をご覧ください。
データベースを既存のインスタンスに復旧する
まれではありますが、Azure データセンターが停止することもあります。 停止が発生すると、ビジネスが中断します。この中断はわずか数分で解消されることもありますが、数時間に及ぶ場合もあります。
- オプションの 1 つは、データ センターの停止が終了し、インスタンスがオンラインに戻るのを待つことです。 このオプションは、オフラインのデータベースが許容されるアプリケーションで有効です。 たとえば、常時作業する必要のない開発プロジェクトや無料試用版がこれに該当します。 データセンターが停止したとき、停止がどれくらい続くかわからないため、このオプションはしばらくの間データベースが必要ない場合にのみ有効です。
- geo 冗長 (GRS) または geo ゾーン冗長 (GZRS) ストレージを使っている場合のもう 1 つのオプションは、geo 冗長データベース バックアップを使って、任意の Azure リージョン内の任意の SQL マネージド インスタンスにデータベースを復元することです (geo リストア)。 geo リストアでは、ソースとして geo 冗長バックアップが使われ、障害によってデータベースまたはデータセンターにアクセスできない場合でも、データベースを最後に使用可能な時点に復旧できます。 使用可能なバックアップは、ペアのリージョンにあります。
- 最後に、インスタンスにフェールオーバー グループを使って geo セカンダリを構成している場合は、カスタマー(推奨)またはマイクロソフトマネージドフェールオーバーを使って、停止から速やかに復旧できます。 フェールオーバー自体には数秒しかかかりませんが、サービスがマイクロソフトマネージド geo フェールオーバーをアクティブにするには、少なくとも 1 時間かかります (構成されている場合)。 これは、機能停止の規模に見合ったフェールオーバーを確実に行ううえで必要な時間です。 また、ペアのリージョン間の非同期レプリケーションの性質上、フェールオーバーの結果、最近変更されたデータが失われる可能性があります。
ビジネス継続性計画を開発するときは、破壊的なイベントが発生してから、アプリケーションが完全に復旧するまでの最大許容時間について理解する必要があります。 アプリケーションを完全に復旧するために必要な時間は、目標復旧時間 (RTO) と呼ばれます。 さらに、予期しない破壊的なイベントからの復旧中にアプリケーションが損失を許容できる最大データ更新 (期間) 量についても理解しなければなりません。 潜在的なデータ損失は、目標復旧時点 (RPO) と呼ばれます。
復旧方法によって、提供される RPO と RTO のレベルは異なります。 完全なアプリケーション復旧を達成するために、特定の復旧方法を選択することも、複数の方法を組み合わせて使用することもできます。
フェールオーバー グループは、アプリケーションが次のいずれかの条件を満たす場合に使用します。
- ミッション クリティカルである。
- サービス レベル アグリーメント (SLA) で 12 時間以上のダウンタイムが許されない。
- ダウンタイムによって財務責任が発生する。
- データの変更頻度が高く、1 時間分のデータが失われることも許されない。
- アクティブ geo レプリケーションの追加コストが、潜在的な財務責任と関連するビジネス損失を下回る。
アプリケーションの要件に応じて、データベース バックアップとフェールオーバー グループを組み合わせて使用できます。
以下のセクションでは、データベース バックアップまたはフェールオーバー グループを使って復旧する手順の概要について説明します。
障害に備える
使用するビジネス継続性機能に関係なく、次の操作を行う必要があります。
- ターゲット インスタンスを特定して準備します (ネットワーク IP ファイアウォール規則、ログイン、
masterデータベース レベルのアクセス許可など)。 - クライアントとクライアント アプリケーションを、新しいインスタンスにリダイレクトする方法を決めます
- 監査の設定、アラートなど、他の依存関係を文書化します
準備が不十分な状態で、フェールオーバーまたはデータベースの復旧後にアプリケーションをオンラインにすると、余計な時間がかかり、負荷がかかったときにトラブルシューティングが必要になる場合があります。良くない組み合わせです。
geo レプリケートされたセカンダリ インスタンスにフェールオーバーする
復旧メカニズムとしてフェールオーバー グループを使っている場合は、自動フェールオーバー ポリシーを構成できます。 いったん開始すると、フェールオーバーによってセカンダリ インスタンスが新しいプライマリになり、新しいトランザクションを記録してクエリに応答できるようになります。失われるのは、まだレプリケートされていない最小限のデータだけです。
Note
データセンターがオンラインに戻ると、古いプライマリは自動的に新しいプライマリに再接続して、セカンダリ インスタンスになります。 プライマリを元のリージョンに再配置する場合は、計画されたフェールオーバーを手動で開始することができます (フェールバック)。
geo リストアを実行する
geo 冗長ストレージ (インスタンス作成時の既定のストレージ オプション) で自動バックアップを使っている場合は、geo リストアを使ってデータベースを復旧できます。 通常、復旧は 12 時間以内に実行され、最大 1 時間分のデータ損失が発生します。これは、最後のログ バックアップが実行およびレプリケートされたタイミングによって決まります。 復旧処理が完了するまで、データベースは、トランザクションを記録したり、クエリに応答したりすることはできません。 なお、geo リストアでは最後の使用可能な一時点までしかデータベースを復元できません。
Note
復旧されたデータベースにアプリケーションを切り替える前にデータセンターがオンラインに戻った場合は、復旧をキャンセルすることができます。
フェールオーバー後のタスク/復旧タスクを実行する
復旧にどちらのメカニズムを使ったとしても、ユーザーおよびアプリケーションの動作を元に戻す前に、次の追加タスクを実行する必要があります。
- クライアントとクライアント アプリケーションを、新しいインスタンスおよび復元されたデータベースにリダイレクトする。
- ユーザーが接続できるように、適切なネットワーク IP ファイアウォール規則が適用されていることを確認する。
- 適切なログインと
masterデータベース レベルのアクセス許可が指定されていることを確認する (または包含ユーザーを使用する)。 - 必要に応じて、監査を構成する。
- 必要に応じて、アラートを構成する。
Note
フェールオーバー グループを使用している場合で、かつ読み取り/書き込みリスナーを使用してインスタンスに接続している場合、フェールオーバー後のリダイレクトは、自動的かつアプリケーションに対して透過的に実行されます。
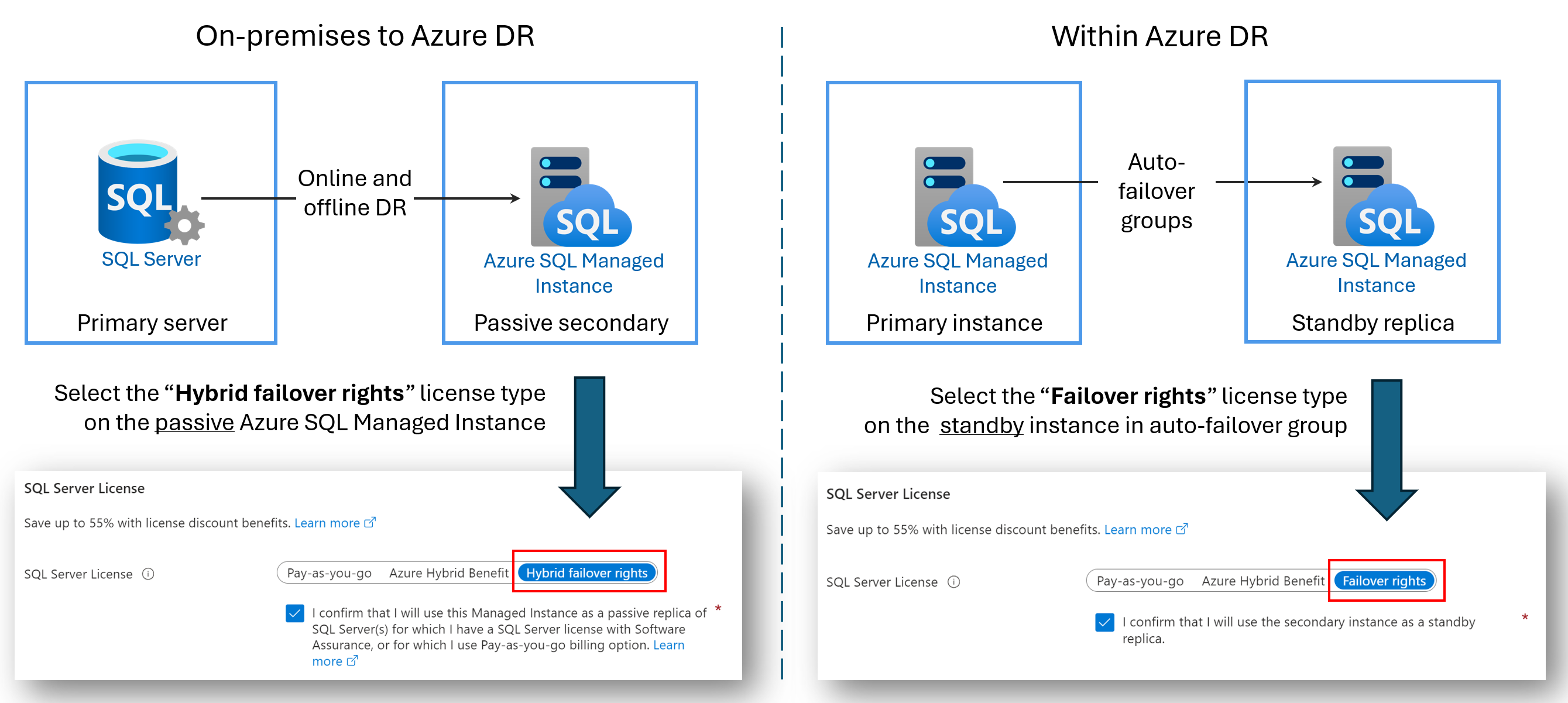
ライセンス不要の DR レプリカ
セカンダリ Azure SQL Managed Instance をディザスター リカバリー (DR) 専用に構成することで、ライセンス コストを節約できます。 この特典は、2 つの SQL managed instance 間でフェールオーバー グループを使用している場合、または SQL Server と Azure SQL Managed Instance の間にハイブリッド リンクを構成している場合に利用できます。 セカンダリ インスタンスに読み取りまたは書き込みのワークロードが存在せず、パッシブ DR スタンバイである限り、セカンダリ インスタンスが使用する仮想コア ライセンス コストには課金されません。
ディザスター リカバリーのみにセカンダリ インスタンスを指定し、且つそのインスタンスで読み取りまたは書き込みのワークロードが実行されていない場合、Microsoft は、フェールオーバー権利特典に基づき、プライマリ インスタンスにライセンスされた仮想コア数を追加料金なしで提供します。 セカンダリ インスタンスで使われるコンピューティングとストレージに対しては、引き続き課金されます。 ハイブリッド フェールオーバー権限特典の正確なご契約条件については、「SQL Server – フェールオーバー権限」セクションの SQL Server ライセンス条項をオンラインで参照してください。
特典の名前は、シナリオによって異なります。
- パッシブ レプリカのハイブリッド フェールオーバー権限: SQL Server と Azure SQL Managed Instance の間のリンクを構成する場合は、ハイブリッド フェールオーバー権限特典を使用して、パッシブ セカンダリ レプリカの仮想コア ライセンス コストを節約できます。
- スタンバイ レプリカのフェールオーバー権限: 2 つのマネージド インスタンス間でフェールオーバー グループを構成する場合は、フェールオーバー権限特典を使用して、スタンバイ セカンダリ レプリカの仮想コア ライセンス コストを節約できます。
次の図は、各シナリオの利点を示しています。
次のステップ
事業継続機能について詳しくは、自動バックアップとフェールオーバー グループに関する記事をご覧ください。 ディザスター リカバリーについては、Azure SQL Managed Instance の「データベースの復旧」および「ゾーン冗長性を有効にする」を参照してください。