データ ストア モデルを理解する
最新のビジネス システムでは、ますます大量の異種データが管理されます。 この異種性は、通常、1 つのデータ ストアが最適なアプローチではないことを意味します。 代わりに、さまざまな種類のデータを異なるデータ ストアに格納し、それぞれが特定のワークロードまたは使用パターンに重点を置くことをお勧めします。 ポリグロット永続化
要件に適したデータ ストアを選択することは、設計上の重要な決定事項です。 SQL データベースと NoSQL データベースの中から何百もの実装を選択できます。 データ ストアは、多くの場合、データの構造とサポートする操作の種類によって分類されます。 この記事では、最も一般的なストレージ モデルのいくつかについて説明します。 特定のデータ ストア テクノロジでは、複数のストレージ モデルがサポートされる場合があることに注意してください。 たとえば、リレーショナル データベース管理システム (RDBMS) では、キー/値またはグラフ ストレージもサポートされる場合があります。 実際には、1 つのデータベース システムが複数のモデルをサポートする、いわゆる マルチモデル サポートの一般的な傾向があります。 ただし、さまざまなモデルを大まかに理解することは、依然として役立ちます。
特定のカテゴリ内のすべてのデータ ストアが同じ機能セットを提供するわけではありません。 ほとんどのデータ ストアには、データのクエリと処理を行うサーバー側の機能が用意されています。 この機能がデータ ストレージ エンジンに組み込まれている場合があります。 それ以外の場合は、データストレージと処理機能が分離され、処理と分析のためのオプションがいくつか存在する場合があります。 データ ストアでは、さまざまなプログラムインターフェイスと管理インターフェイスもサポートされています。
一般に、要件に最も適したストレージ モデルを検討することから始める必要があります。 次に、機能セット、コスト、管理の容易さなどの要因に基づいて、そのカテゴリ内の特定のデータ ストアを検討します。
手記
クラウド導入に関するデータ サービス要件の特定と確認の詳細については、Azure用の
リレーショナル データベース管理システム
リレーショナル データベースは、行と列を含む一連の 2 次元テーブルとしてデータを整理します。 ほとんどのベンダーは、データを取得および管理するための構造化クエリ言語 (SQL) の方言を提供しています。 通常、RDBMS は、情報を更新するための ACID (Atomic、Consistent、Isolated、Durable) モデルに準拠するトランザクション整合性メカニズムを実装します。
通常、RDBMS では、データ構造が事前に定義され、すべての読み取り操作または書き込み操作でスキーマを使用する必要がある、書き込み時スキーマ モデルがサポートされます。
このモデルは、強力な整合性の保証が重要であり、すべての変更がアトミックであり、トランザクションが常にデータを一貫した状態に保つ場合に非常に便利です。 ただし、RDBMS は通常、何らかの方法でデータをシャーディングしないと水平方向にスケールアウトできません。 また、RDBMS 内のデータは正規化する必要があります。これは、すべてのデータ セットに適しているわけではありません。
Azure サービス
- Azure SQL Database | (セキュリティ ベースライン)
- Azure Database for MySQL | (セキュリティ ベースライン)
- Azure Database for PostgreSQL | (セキュリティ ベースライン)
- Azure Database for MariaDB | (セキュリティ ベースライン)
ワークロード
- レコードは頻繁に作成および更新されます。
- 1 つのトランザクションで複数の操作を完了する必要があります。
- リレーションシップは、データベース制約を使用して適用されます。
- インデックスは、クエリのパフォーマンスを最適化するために使用されます。
データ型
- データは高度に正規化されます。
- データベース スキーマは必須であり、適用されます。
- データベース内のデータ エンティティ間の多対多リレーションシップ。
- 制約はスキーマで定義され、データベース内のすべてのデータに適用されます。
- データには高い整合性が必要です。 インデックスとリレーションシップを正確に維持する必要があります。
- データには強力な一貫性が必要です。 トランザクションは、すべてのユーザーとプロセスに対して、すべてのデータが 100% 一貫していることを保証する方法で動作します。
- 個々のデータ エントリのサイズは、小規模から中規模です。
使用例
- 在庫管理
- 注文管理
- レポート データベース
- 会計
キー/値のストア
キー/値ストアは、各データ値を一意のキーに関連付けます。 ほとんどのキー/値ストアでは、単純なクエリ操作、挿入操作、および削除操作のみがサポートされます。 値を (部分的または完全に) 変更するには、アプリケーションが値全体の既存のデータを上書きする必要があります。 ほとんどの実装では、1 つの値の読み取りまたは書き込みはアトミック操作です。
アプリケーションは、任意のデータを値のセットとして格納できます。 スキーマ情報は、アプリケーションから提供する必要があります。 キー/値ストアは、単にキーによって値を取得または格納します。
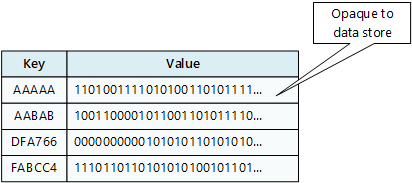
キー/値ストアは、単純な検索を実行するアプリケーション向けに高度に最適化されていますが、異なるキー/値ストア間でデータのクエリを実行する必要がある場合は適さなくなります。 キー/値ストアも、値によるクエリ用に最適化されていません。
単一のキー/値ストアは、データ ストアが別々のマシン上の複数のノードに簡単にデータを分散できるため、非常にスケーラブルです。
Azure サービス
- Azure Cosmos DB for Table と Azure Cosmos DB for NoSQL | (Azure Cosmos DB セキュリティ ベースライン)
- Azure Cache for Redis | (セキュリティ ベースライン)
- Azure Table Storage | (セキュリティ ベースライン)
ワークロード
- データには、ディクショナリなどの 1 つのキーを使用してアクセスされます。
- 結合、ロック、統合は必要ない。
- 集計メカニズムは使用されません。
- 一般に、セカンダリ インデックスは使用されません。
データ型
- 各キーは 1 つの値に関連付けられます。
- スキーマの適用は行われていません。
- エンティティ間のリレーションシップはありません。
使用例
- データ キャッシュ
- セッション管理
- ユーザー設定とプロファイルの管理
- 製品に関する推奨事項と広告配信
ドキュメント データベース
ドキュメント データベースには、
通常、ドキュメントには、顧客や注文などの 1 つのエンティティのデータが含まれます。 ドキュメントには、RDBMS 内の複数のリレーショナル テーブルに分散される情報が含まれている場合があります。 ドキュメントの構造は同じである必要はありません。 アプリケーションは、ビジネス要件の変化に応じて、さまざまなデータをドキュメントに格納できます。
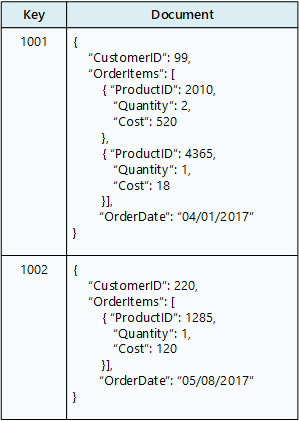
Azure サービス
ワークロード
- 挿入操作と更新操作は一般的です。
- オブジェクト リレーショナル インピーダンスの不一致はありません。 ドキュメントは、アプリケーション コードで使用されるオブジェクト構造とより一致させることができます。
- 個々のドキュメントは、1 つのブロックとして取得および書き込まれます。
- データには、複数のフィールドのインデックスが必要です。
データ型
- データは、非正規化された方法で管理できます。
- 個々のドキュメント データのサイズは比較的小さくなります。
- 各ドキュメントの種類では、独自のスキーマを使用できます。
- ドキュメントには省略可能なフィールドを含めることができます。
- ドキュメント データは半構造化されています。つまり、各フィールドのデータ型は厳密に定義されていません。
使用例
- 製品カタログ
- コンテンツ管理
- 在庫管理
グラフ データベース
グラフ データベースには、ノードとエッジの 2 種類の情報が格納されます。 エッジは、ノード間のリレーションシップを指定します。 ノードとエッジには、テーブル内の列と同様に、そのノードまたはエッジに関する情報を提供するプロパティを持つことができます。 エッジには、リレーションシップの性質を示す方向を含めることもできます。
グラフ データベースは、ノードとエッジのネットワーク全体でクエリを効率的に実行し、エンティティ間のリレーションシップを分析できます。 次の図は、グラフとして構成された組織の人事データベースを示しています。 エンティティは従業員と部門であり、エッジはレポート関係と従業員が働く部門を示します。
ドキュメント データベース の
この構造により、"直接または間接的に Sarah に報告するすべての従業員を検索する" や "John と同じ部署で働いているユーザー" などのクエリを簡単に実行できます。多数のエンティティとリレーションシップを持つ大規模なグラフの場合、非常に複雑な分析を非常に迅速に実行できます。 多くのグラフ データベースには、リレーションシップのネットワークを効率的に走査するために使用できるクエリ言語が用意されています。
Azure サービス
ワークロード
- 関連するデータ項目間のホップ数が多いデータ項目間の複雑なリレーションシップ。
- データ項目間の関係は動的であり、時間の経過と伴って変化します。
- オブジェクト間のリレーションシップは最上位の扱いになり、外部キーと走査のための結合は必要ない。
データ型
- ノードとリレーションシップ。
- ノードは、テーブル行または JSON ドキュメントに似ています。
- リレーションシップはノードと同じくらい重要であり、クエリ言語で直接公開されます。
- 複数の電話番号を持つユーザーなどの複合オブジェクトは、走査可能なリレーションシップと組み合わせて、個別の小さなノードに分割される傾向があります
使用例
- 組織図
- ソーシャル グラフ
- 不正行為の検出
- 推奨エンジン
データ分析
データ分析ストアには、データの取り込み、格納、分析のための超並列ソリューションが用意されています。 データは、スケーラビリティを最大化するために複数のサーバーに分散されます。 区切り記号ファイル (CSV)、parquet、ORC などの大きなデータ ファイル形式は、データ分析で広く使用されています。 履歴データは通常、BLOB ストレージや Azure Data Lake Storage Gen2
Azure サービス
- Azure Synapse Analytics | (セキュリティ ベースライン)
- Azure Data Lake | (セキュリティ ベースライン)
- Azure Data Explorer | (セキュリティ ベースライン)
- Azure Analysis Services
- HDInsight | (セキュリティ ベースライン)
- Azure Databricks | (セキュリティ ベースライン)
ワークロード
- データ分析
- エンタープライズビジネスインテリジェンス
データ型
- 複数のソースからの履歴データ。
- 通常、ファクト テーブルとディメンション テーブルで構成される "スター" スキーマまたは "snowflake" スキーマで非正規化されます。
- 通常、スケジュールに基づいて新しいデータが読み込まれます。
- ディメンション テーブルには、多くの場合、エンティティの複数の履歴バージョンが含まれています。これは、緩やかに変化するディメンション
と呼ばれます。
使用例
- エンタープライズ データ ウェアハウス
列ファミリのデータベース
列ファミリ データベースは、データを行と列に整理します。 最も単純な形式では、列ファミリ データベースは、少なくとも概念的にはリレーショナル データベースによく似ています。 列ファミリ データベースの真の力は、スパース データを構造化するための非正規化アプローチにあります。
列ファミリ データベースは、行と列を含む表形式データを保持していると考えることができますが、列は 列ファミリと呼ばれるグループに分割。 各列ファミリには、論理的に関連し、通常は 1 つの単位として取得または操作される一連の列が保持されます。 個別にアクセスされるその他のデータは、個別の列ファミリに格納できます。 列ファミリ内では、新しい列を動的に追加でき、行をスパースにすることができます (つまり、行がすべての列に値を持つ必要はありません)。
次の図は、Identity と Contact Infoの 2 つの列ファミリを持つ例を示しています。 1 つのエンティティのデータは、各列ファミリで同じ行キーを持ちます。 列ファミリ内の特定のオブジェクトの行が動的に変化する可能性があるこの構造は、列ファミリアプローチの重要な利点であり、この形式のデータ ストアは構造化された揮発性データを格納するのに非常に適しています。
列ファミリ データベース の
キー/値ストアやドキュメント データベースとは異なり、ほとんどの列ファミリ データベースでは、ハッシュを計算するのではなく、キーの順序でデータが格納されます。 多くの実装では、列ファミリ内の特定の列に対してインデックスを作成できます。 インデックスを使用すると、行キーではなく列値でデータを取得できます。
行の読み取り操作と書き込み操作は通常、1 つの列ファミリでアトミックですが、一部の実装では複数の列ファミリにまたがる行全体にアトミック性が提供されます。
Azure サービス
- Azure Cosmos DB for Apache Cassandra | (セキュリティ ベースライン)
- HBase が HDInsight | (セキュリティ ベースライン) にあります。
ワークロード
- ほとんどの列ファミリ データベースでは、書き込み操作が非常に迅速に実行されます。
- 更新操作と削除操作はまれです。
- 高スループットで待機時間の短いアクセスを提供するように設計されています。
- はるかに大きなレコード内の特定のフィールド セットへの簡単なクエリ アクセスをサポートします。
- 非常にスケーラブルです。
データ型
- データは、キー列と 1 つ以上の列ファミリで構成されるテーブルに格納されます。
- 特定の列は、個々の行によって異なる場合があります。
- 個々のセルには、get コマンドと put コマンドを使用してアクセスします。
- スキャン コマンドを使用して複数の行が返されます。
例一覧
- 推奨 事項
- パーソナル 化
- センサー データ
- テレメトリー
- メッセージング
- ソーシャル メディア分析
- Web 分析
- アクティビティの監視
- 天気やその他の時系列データ
検索エンジン データベース
検索エンジン データベースを使用すると、アプリケーションは外部データ ストアに保持されている情報を検索できます。 検索エンジン データベースでは、大量のデータにインデックスを作成し、これらのインデックスにほぼリアルタイムでアクセスできます。
インデックスは多次元であり、大量のテキスト データにわたるフリー テキスト検索をサポートする場合があります。 インデックス作成は、検索エンジン データベースによってトリガーされるプル モデルを使用するか、外部アプリケーション コードによって開始されるプッシュ モデルを使用して実行できます。
検索は、正確またはあいまいにすることができます。 あいまい検索は、一連の用語に一致するドキュメントを検索し、それらがどの程度一致するかを計算します。 また、一部の検索エンジンでは、シノニム、ジャンルの拡張 (たとえば、dogs を petsに一致させる)、ステミング (同じルートを持つ単語の照合) に基づいて一致を返すことができる言語分析もサポートされています。
Azure サービス
ワークロード
- 複数のソースとサービスからのデータ インデックス。
- クエリはアドホックであり、複雑になる可能性があります。
- フルテキスト検索が必要です。
- アドホック セルフサービス クエリが必要です。
データ型
- 半構造化テキストまたは非構造化テキスト
- 構造化データを参照するテキスト
例題
- 製品カタログ
- サイト検索
- ログの記録
時系列データベース
時系列データは、時間別に整理された値のセットです。 時系列データベースは、通常、大量のソースから大量のデータをリアルタイムで収集します。 更新はまれであり、削除は一括操作として実行されることがよくあります。 時系列データベースに書き込まれるレコードは通常は小さくなりますが、多くの場合、多数のレコードが存在し、合計データ サイズが急速に大きくなる可能性があります。
Azure サービス
ワークロード
- 通常、レコードは時間順に順番に追加されます。
- 操作の圧倒的な割合 (95 から 99%) は書き込みです。
- 更新プログラムはまれです。
- 削除は一括で行われ、連続したブロックまたはレコードに対して行われます。
- データは、昇順または降順で順番に読み取られます。多くの場合、並列で読み取られます。
データ型
- タイムスタンプは、主キーおよびソートメカニズムとして使用されます。
- タグは、エントリの種類、配信元、およびその他の情報に関する追加情報を定義できます。
使用例
- 監視とイベント テレメトリ。
- センサーまたはその他の IoT データ。
オブジェクト ストレージ
オブジェクト ストレージは、大きなバイナリ オブジェクト (イメージ、ファイル、ビデオおよびオーディオ ストリーム、大規模なアプリケーション データ オブジェクトとドキュメント、仮想マシン ディスク イメージ) の格納と取得に最適化されています。 このモデルでは、区切り記号ファイル (CSV)、
Azure サービス
- Azure Blob Storage
(セキュリティ ベースライン) - Azure Data Lake Storage Gen2 | (セキュリティ ベースライン)
ワークロード
- キーによって識別されます。
- コンテンツは通常、区切り記号、画像、ビデオ ファイルなどのアセットです。
- コンテンツは永続的で、任意のアプリケーション層の外部である必要があります。
データ型
- データ サイズが大きい。
- 値は不透明です。
使用例
- 画像、ビデオ、オフィス ドキュメント、PDF
- 静的 HTML、JSON、CSS
- ログ ファイルと監査ファイル
- データベース バックアップ
共有ファイル
場合によっては、単純なフラット ファイルを使用することが、情報の格納と取得に最も効果的な手段となる場合があります。 ファイル共有を使用すると、ネットワーク経由でファイルにアクセスできます。 適切なセキュリティと同時アクセス制御メカニズムにより、この方法でデータを共有することで、分散サービスは、単純な読み取り要求や書き込み要求などの基本的で低レベルの操作を実行するための高度にスケーラブルなデータ アクセスを提供できます。
Azure サービス
ワークロード
- ファイル システムと対話する既存のアプリからの移行。
- SMB インターフェイスが必要です。
データ型
- フォルダーの階層セット内のファイル。
- 標準の I/O ライブラリを使用してアクセスできます。
使用例
- レガシ ファイル
- 多数の VM またはアプリ インスタンス間でアクセスできる共有コンテンツ
さまざまなデータ ストレージ モデルの理解に役立つ次の手順は、ワークロードとアプリケーションを評価し、特定のニーズを満たすデータ ストアを決定することです。 このプロセスを支援するには、データ ストレージデシジョン ツリー を使用します。