Azure AI Studio でのコンテンツのフィルター処理
Azure AI Studio には、コア モデルと DALL-E 画像生成モデルと共に動作するコンテンツ フィルタリング システムが含まれています。
重要
コンテンツ フィルタリング システムは、Azure OpenAI Service の Whisper モデルによって処理されるプロンプトと入力候補には適用されません。 Azure OpenAI の Whisper モデルの詳細を確認してください。
しくみ
このコンテンツ フィルタリング システムは Azure AI Content Safety を利用しており、有害なコンテンツの出力を検出して阻止することを目的とした分類モデルのアンサンブルを通してプロンプト入力と補完出力の両方を実行することで機能します。 API 構成とアプリケーション設計のバリエーションは、入力候補に影響を与え、したがってフィルター処理の動作にも影響を与える場合があります。
Azure OpenAI モデル デプロイでは、既定のコンテンツ フィルターを使用することも、(後述の) 独自のコンテンツ フィルターを作成することもできます。 既定のコンテンツ フィルターは、モデル カタログ内の Azure AI によってキュレーションされた他のテキスト モデルでも利用できますが、カスタム コンテンツ フィルターはこれらのモデルではまだ利用できません。 サービスとしてのモデルを通して利用できるモデルでは、コンテンツ フィルターが既定で有効になっており、構成は不可能です。
言語のサポート
コンテンツ フィルター処理モデルは、英語、ドイツ語、日本語、スペイン語、フランス語、イタリア語、ポルトガル語、中国語でトレーニングおよびテストされています。 ただし、このサービスは他の多くの言語でも動作しますが、品質は異なる場合があります。 いずれの場合も、独自のテストを実行して、アプリケーションに対して動作することを確認する必要があります。
コンテンツ リスク フィルター (入力と出力のフィルター)
次の特殊なフィルターは、生成 AI モデルの入力と出力の両方で機能します。
カテゴリ
| カテゴリ | 説明 |
|---|---|
| 増悪 | 憎悪カテゴリは、人種、民族、国籍、性同一性と性表現、性的指向、宗教、在留資格、能力状態、容姿、体格などを含む (ただし、これらに限定しない) これらのグループ特有の識別属性に基づいて、個人またはアイデンティティ グループに関連した、軽蔑的または差別的な言葉などの言葉による攻撃または言葉の使用を表します。 |
| 性的 | 性的カテゴリは、解剖学的臓器や生殖器、恋愛関係、性愛的または情愛的な用語で描写された行為、物理的な性的行為 (暴行または意志に反した強制的な性的暴力行為として描写されたものを含む)、売春、ポルノ、虐待に関連する言葉を表します。 |
| 暴力 | 暴力カテゴリは、人や何かに苦痛を与える、傷つける、損傷を与える、殺害することを意図した物理的行為に関連する言葉、武器などを表します。 |
| 自傷行為 | 自傷行為カテゴリは、故意に自分の体に苦痛を与える、傷つける、損傷を与える、自死を意図した物理的行為に関連する言葉を表します。 |
セキュリティ レベル
| カテゴリ | 説明 |
|---|---|
| Safe | コンテンツは、暴力、自傷行為、性的、または憎悪カテゴリに関連している場合がありますが、用語は一般的に、報道、科学、医療、および同様の専門的なコンテキストで使用され、ほとんどの対象ユーザーに対して適切なものです。 |
| 低 | 偏見的、批判的、または独断的な見解を表明するコンテンツには、(小程度の) 不快な言葉の使用、定型化、架空の世界を彷徨うユース ケース (ゲーム、文学など) や描写が含まれます。 |
| Medium | 特有のアイデンティティ グループに対して、不快、侮辱的、嘲笑、威圧的、または屈辱的な言葉を使用するコンテンツには、(中程度の) 有害な指示、妄想、賛美、害悪の助長を求めて実行する描写が含まれます。 |
| 高 | 明示的で重大な害をもたらす指示、行為、ダメージ、または虐待を表示するコンテンツ。重大かつ有害な行為、極端または違法な形態の危害、急進化、または合意のない権力の交換や虐待の承認、賛美、促進が含まれます。 |
その他の入力フィルター
以下の生成 AI のシナリオに対しては、特別なフィルターを有効にすることもできます。
- ジェイルブレイク攻撃: ジェイルブレイク攻撃とは、生成 AI モデルが回避するようにトレーニングされた振舞いを示すように誘導したり、システム メッセージ内に設定されたルールを破ることを目的としたユーザー プロンプトのことです。
- 間接攻撃: 間接プロンプト攻撃またはクロスドメイン プロンプト インジェクション攻撃とも呼ばれる間接攻撃とは、生成 AI システムがアクセスして処理できるドキュメント内に、第三者が悪意のある命令を配置するという潜在的な脆弱性のことです。
その他の出力フィルター
以下の特殊な出力フィルターを有効にすることもできます。
- テキストに関する保護されたマテリアル: 保護されたマテリアル テキストとは、大規模言語モデルによって出力される可能性のある既知のテキスト コンテンツ (たとえば、曲の歌詞、記事、レシピ、一部の Web コンテンツなど) のことを指します。
- コードに関する保護されたマテリアル: 保護されたマテリアル コードとは、大規模言語モデルによって適切なソース リポジトリの引用なしで出力される可能性があるパブリック リポジトリの一連のソース コードと一致するソース コードのことを指します。
- 根拠性: 根拠性検出フィルターは、大規模言語モデル (LLM) のテキスト応答が、ユーザーによって指定されたソース資料を根拠としているかどうかを検出します。
コンテンツ フィルターを作成する
Azure AI Studio 内のモデル デプロイに対しては、既定のコンテンツ フィルターを直接使用できますが、より詳細な制御が必要な場合があります。 たとえば、フィルターをより厳密にしたり、より緩やかにしたり、プロンプト シールドや保護されたマテリアルの検出などのより高度な機能を有効にしたりできます。
コンテンツ フィルターを作成するには、以下の手順に従います。
AI Studio にアクセスし、自分のプロジェクトまたはハブに移動します。 次に、左側のナビゲーションで [安全性とセキュリティ] タブを選択し、[コンテンツ フィルター] を選択します。

[基本情報] ページで、コンテンツ フィルターの名前を入力します。 コンテンツ フィルターに関連付ける接続を選択します。 [次へ] を選択します。
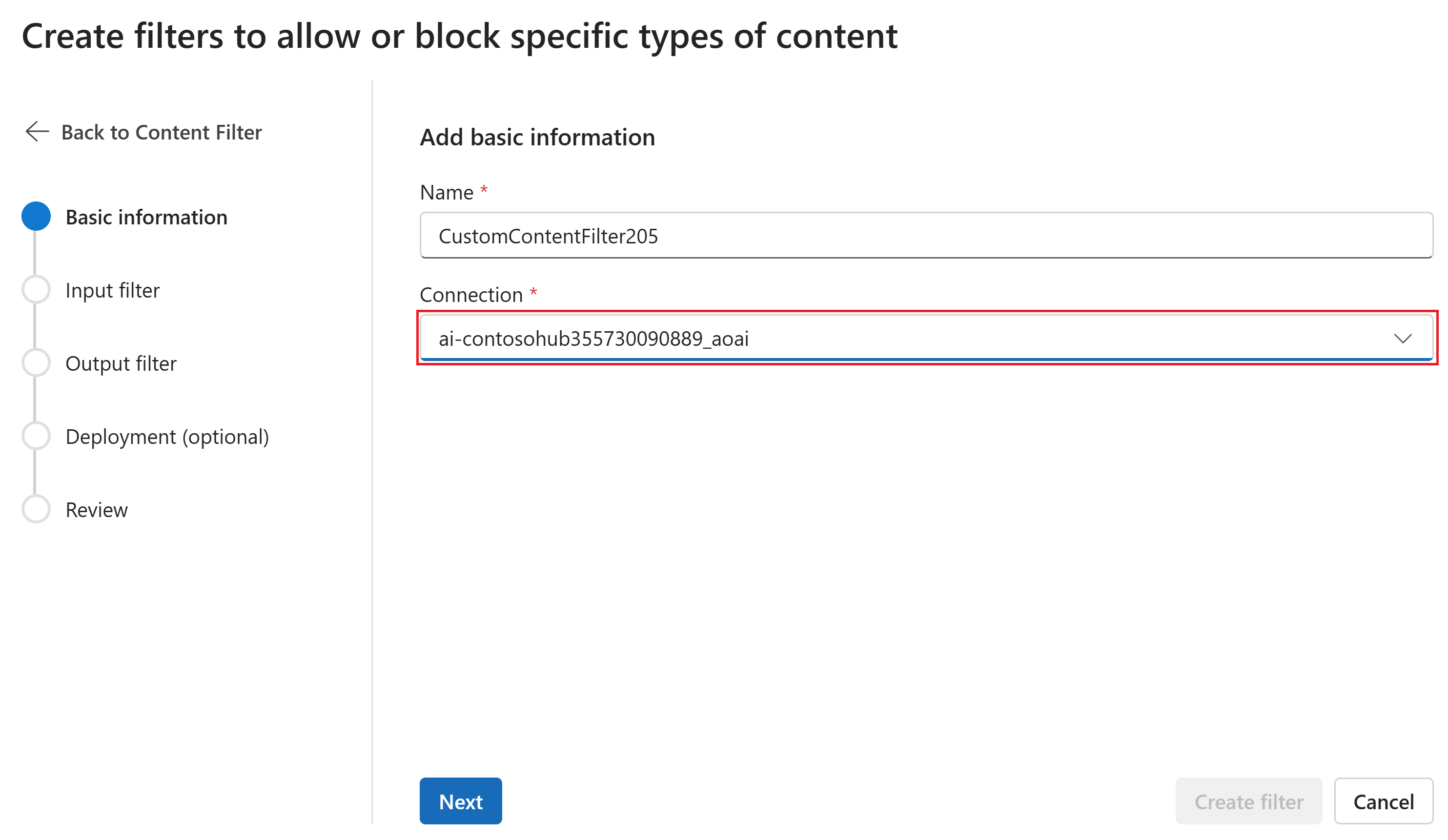
[コンテンツ フィルターの作成] を選択します。
[入力フィルター] ページでは、入力プロンプトのフィルターを設定できます。 フィルターの各種類のアクションと重大度レベルのしきい値を設定します。 このページでは、既定のフィルターとその他のフィルター (脱獄攻撃用の Prompt Shields など) の両方を構成します。 [次へ] を選択します。

コンテンツはカテゴリによって注釈付けされ、ユーザーが設定したしきい値に従ってブロックされます。 暴力、ヘイト、性的、自傷行為のカテゴリに関して、スライダーを調整して、重大度が高、中、または低のコンテンツをブロックします。
[出力フィルター] ページでは、出力フィルターを構成できます。このフィルターは、お使いのモデルによって生成されるあらゆる出力コンテンツに適用されます。 以前と同じように個々のフィルターを構成します。 このページには、ストリーミング モード オプションもあります。このオプションでは、モデルによって生成されるほぼリアルタイムのタイミングでコンテンツにフィルターを適用できます。待ち時間が短縮されます。 完了したら、[次へ] を選択します。
コンテンツは各カテゴリによって注釈付けされ、しきい値に従ってブロックされます。 暴力コンテンツ、ヘイト コンテンツ、性的コンテンツ、自傷行為コンテンツ カテゴリに関して、しきい値を調整して、重大度レベルがそれ以上の有害なコンテンツをブロックします。
必要に応じて、[デプロイ] ページで、コンテンツ フィルターをデプロイに関連付けることができます。 選択されたデプロイにフィルターが既にアタッチされている場合、その置換を望むことを確定する必要があります。 コンテンツ フィルターを後でデプロイに関連付けることもできます。 [作成] を選択します
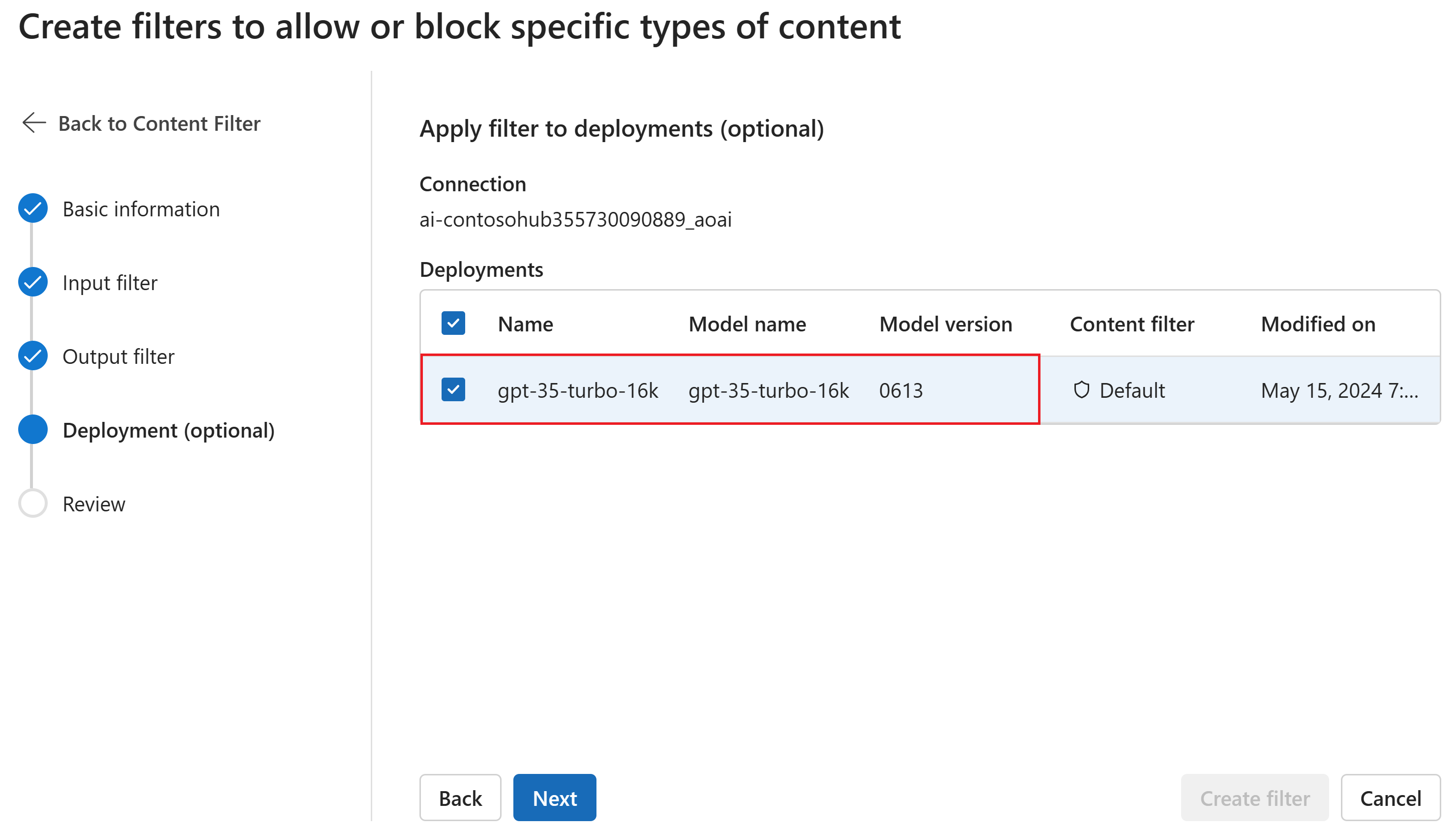
コンテンツ フィルタリングの構成は、AI Studio のハブ レベルで作成されます。 可能な構成の詳細については、「Azure OpenAI ドキュメント」で確認してください。
[確認] ページで、設定を確認した後、[フィルターの作成] を選択します。




ブロックリストをフィルターとして使用する
ブロックリストは、入力フィルター、出力フィルター、またはその両方として適用できます。 [入力フィルター] または [出力フィルター] ページ、あるいはその両方で [ブロックリスト] オプションを有効にします。 ドロップダウンから 1 つ以上のブロックリストを選択するか、組み込みの不適切表現のブロックリストを使用します。 複数のブロックリストを同じフィルターに結合することができます。
コンテンツ フィルターを適用する
フィルター作成プロセスには、必要なデプロイにフィルターを適用するオプションがあります。 デプロイのコンテンツ フィルターはいつでも変更または削除することもできます。
コンテンツ フィルターをデプロイに適用するには、以下の手順に従います。
AI Studio に移動し、ハブとプロジェクトを選択します。
左側のペインで [モデルとエンドポイント] を選択し、いずれかのデプロイを選択してから、[編集] を選択します。

[デプロイの更新] ウィンドウで、デプロイに対して適用したいコンテンツ フィルターを選択します。



これで、プレイグラウンドに移動して、コンテンツ フィルターが想定どおりに動作するかどうかをテストできます。
構成可能性 (プレビュー)
GPT モデル シリーズの既定のコンテンツ フィルタリング構成は、4 つの有害コンテンツ カテゴリ (ヘイト、暴力、性的、自傷行為) のすべてで中の重大度しきい値でフィルター処理を行うように設定されており、プロンプト (テキスト、マルチモーダル テキスト/画像) と補完 (テキスト) の両方に適用されます。 つまり、重大度レベルが中または高として検出されたコンテンツはコンテンツ フィルターによってフィルター処理されますが、重大度レベルが低として検出されたコンテンツはフィルター処理されません。 DALL-E の場合、既定の重大度しきい値がプロンプト (テキスト) と補完 (画像) の両方に対して低に設定されるため、重大度レベルが低、中、または高として検出されたコンテンツがフィルター処理されます。
この構成機能を使用すると、利用者はプロンプトと補完とは独立して設定を調整し、次のテーブルに示された異なる重大度レベルで各コンテンツ カテゴリのコンテンツをフィルター処理できます。
| フィルタリングされた重大度 | プロンプト用に構成可能 | 入力候補用に構成可能 | 説明 |
|---|---|---|---|
| [低]、[中]、[高] | はい | はい | 最も厳密なフィルタリング構成。 重大度レベルが低、中、高で検出されたコンテンツがフィルタリングされます。 |
| 中、高 | はい | はい | 低い重大度レベルの検出されたコンテンツはフィルター処理されず、中および高のコンテンツはフィルター処理されます。 |
| 高 | はい | はい | 重大度レベルが低および中で検出されたコンテンツはフィルター処理されません。 重大度レベルが高のコンテンツのみがフィルタリングされます。 承認が必要1. |
| フィルターなし | 承認された場合 1 | 承認された場合 1 | 重大度レベルの検出に関係なく、コンテンツはフィルタリングされません。 承認が必要1. |
1 Azure OpenAI モデルの場合、変更されたコンテンツのフィルター処理の承認を受けたお客様のみが、コンテンツ フィルターの重大度レベル高のみでの構成やコンテンツ フィルターの無効化など、コンテンツ フィルターを完全に制御できます。 このフォームを使用して変更されたコンテンツ フィルターを申請してください: 「Azure OpenAI 制限付きアクセス レビュー: 変更されたコンテンツ フィルターと不正使用の監視 (microsoft.com)」
Azure OpenAI を統合するアプリケーションが倫理規定に準拠していることを確認する責任は、お客様にあります。
次のステップ
- Azure OpenAI をサポートする基となるモデルに関する記事を確認します。
- Azure AI Studio のコンテンツのフィルター処理では、Azure AI Content Safety を利用します。
- アプリケーションに関連するリスクの理解と軽減策について詳しくは、「Azure OpenAI モデルの責任ある AI プラクティスの概要」をご覧ください。
- Azure AI 評価を使用した生成 AI モデルと AI システム評価の詳細について確認します。