デプロイされたプロンプト フロー アプリケーションの品質とトークンの使用量をモニターする
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
運用環境にデプロイされるアプリケーションのモニターは、生成 AI アプリケーションのライフサイクルの不可欠な部分です。 データやコンシューマーの動作の変化は、時間の経過と共にアプリケーションに影響を与える可能性があり、その結果、システムが時代遅れになり、ビジネス成果に悪影響を及ぼし、組織をコンプライアンス、経済、風評のリスクにさらすことになります。
Note
展開済みアプリケーション (プロンプト フロー以外) の継続的な監視を実行する改善された方法については、Azure AI オンライン評価の使用を検討してください。
生成 AI アプリケーションに対して Azure AI モニターを使用すると、運用環境のアプリケーションでトークンの使用量、生成品質、運用メトリックをモニターできます。
プロンプト フローのデプロイをモニターする統合を使用すると、次のことが可能になります。
- デプロイされたプロンプト フロー アプリケーションから運用環境の推論データを収集します。
- 現実性、一貫性、流暢性、関連性などの責任ある AI 評価メトリックを適用します。これらは、プロンプト フロー評価メトリックと相互運用可能です。
- プロンプト フロー内の各モデル デプロイ全体にわたって、プロンプト、入力候補、およびトークンの使用量合計をモニターします。
- 要求数、待機時間、エラー率などの運用メトリックをモニターします。
- 構成済みのアラートと既定値を使用して、定期的にモニターを実行します。
- Azure AI Foundry ポータルでデータの可視化を使用し、高度な動作を構成します。
前提条件
-
[ スタジオ](#tab/azure-studio) - Python SDK
この記事の手順に従う前に、次の前提条件が満たされていることをご確認ください。
有効な支払い方法を持つ Azure サブスクリプション。 このシナリオでは、無料や試用版の Azure サブスクリプションはサポートされていません。 Azure サブスクリプションを持っていない場合は、始めるために有料の Azure アカウントを作成してください。
デプロイ用に準備されたプロンプト フロー。 ない場合は、「プロンプト フローの開発」を参照してください。
Azure AI Foundry ポータルでの操作に対するアクセス権を付与するには、Azure ロールベースのアクセス制御 (Azure RBAC) を使用します。 この記事の手順を実行するには、ご自分のユーザー アカウントに、リソース グループの Azure AI 開発者ロールを割り当てる必要があります。 アクセス許可について詳しくは、「Azure AI Foundry ポータルでのロールベースのアクセス制御」をご覧ください。
メトリックをモニターするための要件
モニター メトリックは、特定の評価命令 (プロンプト テンプレート) で構成された特定の最新 GPT 言語モデルによって生成されます。 これらのモデルは、シーケンス間タスクの評価モデルとして機能します。 この手法を使用してモニター メトリックを生成すると、標準的な生成 AI 評価メトリックと比べて、強力な実証に基づく結果と、人間の判断との高い相関関係が示されます。 プロンプト フロー評価の詳細については、一括テストを送信してフローを評価する方法に関する記事と「生成 AI の評価と監視メトリック」を参照してください。
モニター メトリックを生成する GPT モデルは次のとおりです。 監視では次の GPT モデルがサポートされており、Azure OpenAI リソースとして構成されます。
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
モニターに対してサポートされるメトリック
監視では次のメトリックがサポートされます。
| メトリック | 説明 |
|---|---|
| 現実性 | モデルの生成された回答がソース データ (ユーザー定義のコンテキスト) からの情報とどの程度合致しているかを測定します。 |
| 関連性 | モデルの生成された応答が、与えられた質問に対してどの程度適切で、直接的な関連性があるかを測定します。 |
| 一貫性 | モデルの生成された応答がどの程度論理的に一貫しており接続されているかを測定します。 |
| 流暢性 | 生成 AI の予測した回答の文法的な熟練度を測定します。 |
列名のマッピング
フローを作成するときは、列名がマップされることを確認する必要があります。 生成の安全性と品質を測定するには、次の入力データ列名が使用されます。
| 入力列の名前 | Definition | 必須/任意 |
|---|---|---|
| 質問 | 指定された元のプロンプト ("入力" または "質問" とも呼ばれます) | 必須 |
| Answer | API 呼び出しから返される最終的な完了 ("出力" または"回答" とも呼ばれます) | 必須 |
| Context | 元のプロンプトと共に API 呼び出しに送信されるコンテキスト データ。 たとえば、特定の認定された情報ソースまたは Web サイトからのみ検索結果を取得したい場合、このコンテキストを評価ステップに定義できます。 | 省略可能 |
メトリックに必要なパラメーター
次の表に示すように、データ資産で構成されているパラメーターによって、生成できるメトリックが決まります。
| メトリック | Question | Answer | Context |
|---|---|---|---|
| 一貫性 | 必須 | 必須 | - |
| 流暢性 | 必須 | 必須 | - |
| 現実性 | 必須 | 必須 | 必須 |
| 関連性 | 必須 | 必須 | 必須 |
各メトリックの特定のデータ マッピング要件の詳細については、クエリと応答のメトリックの要件を参照してください。
プロンプト フローの監視を設定する
プロンプト フロー アプリケーションのモニターをセットアップするには、まず推論データ収集機能を持つプロンプト フロー アプリケーションをデプロイする必要があります。その後に、デプロイされたアプリケーションのモニターを構成できます。
推論データ収集機能を持つプロンプト フロー アプリケーションをデプロイする
このセクションでは、推論データ収集が有効なプロンプト フローをデプロイする方法について説明します。 プロンプト フローのデプロイの詳細については、「リアルタイム推論のフローをデプロイする」を参照してください。
Azure AI Foundry にサインインします。
プロジェクトを開いていない場合、プロジェクトを選択します。
左側のナビゲーション バーから [プロンプト フロー] を選択します。
前に作成したプロンプト フローを選びます。
Note
この記事では、デプロイの準備ができているプロンプト フローを既に作成していることを想定しています。 ない場合は、「プロンプト フローの開発」を参照してください。
フローが正常に実行されることと、評価対象のメトリックに必要な入力と出力が構成されていることを確認します。
必要最低限のパラメーター (質問/入力と回答/出力) を指定すると、"一貫性" と "流暢性" の 2 つのメトリックのみが提供されます。 「メトリックをモニターするための要件」セクションの説明どおりにフローを構成する必要があります。 この例では、フロー入力として
question(質問) とchat_history(コンテキスト) を使用し、フロー出力としてanswer(回答) を使用します。[デプロイ] を選択して、フローのデプロイを開始します。
![[デプロイ] ボタンがあるプロンプト フロー エディターのスクリーンショット。](../media/deploy-monitor/monitor/user-experience.png)
デプロイ ウィンドウで、[Inferencing data collection] (推論データ収集) が有効になっていることを確認します。これにより、アプリケーションの推論データが Blob Storage にシームレスに収集されます。 このデータ収集はモニターに必須です。

デプロイ ウィンドウの手順を進めて、[詳細設定] を完了します。
[レビュー] ページで、デプロイ構成を確認し、[作成] を選択してフローをデプロイします。
![すべての設定が完了したデプロイ ウィザードの [レビュー] ページのスクリーンショット。](../media/deploy-monitor/monitor/deployment-with-data-collection-enabled.png)
Note
既定では、デプロイされたプロンプト フロー アプリケーションのすべての入力と出力が Blob Storage に収集されます。 ユーザーによってデプロイが呼び出されると、モニターが使用するためのデータが収集されます。
デプロイ ページの [テスト] タブを選び、デプロイをテストして、正しく動作していることを確認します。
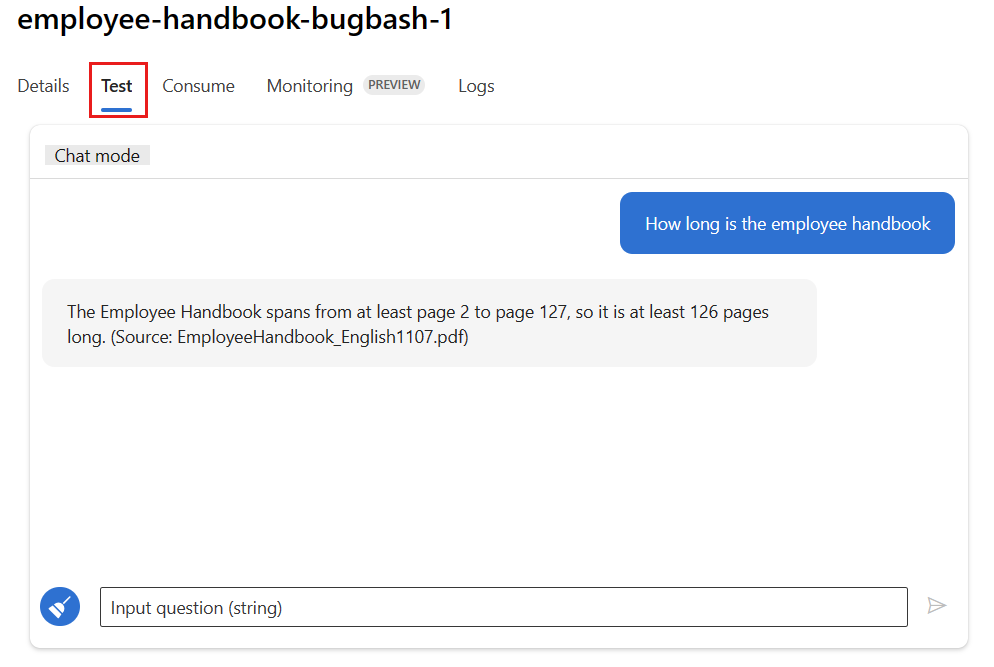
Note
モニターするには、デプロイの [テスト] タブ以外のソースから 1 つ以上のデータ ポイントを取得する必要があります。 [使用] タブで選択できる REST API を使用して、サンプル要求をデプロイに送信することをお勧めします。 デプロイにサンプル要求を送信する方法の詳細については、「オンライン デプロイを作成する」を参照してください。
![[デプロイ] ボタンがあるプロンプト フロー エディターのスクリーンショット。](../media/deploy-monitor/monitor/user-experience.png#lightbox)

![すべての設定が完了したデプロイ ウィザードの [レビュー] ページのスクリーンショット。](../media/deploy-monitor/monitor/deployment-with-data-collection-enabled.png#lightbox)

監視の構成
このセクションでは、デプロイされたプロンプト フロー アプリケーションのモニターを構成する方法について説明します。
-
[ スタジオ](#tab/azure-studio) - Python SDK
左側のナビゲーション バーから、[マイ アセット]>[モデル + エンドポイント] に移動します。
作成したプロンプト フローのデプロイを選びます。
[Enable generation quality monitoring] (生成品質モニタリングを有効にする) ボックスで [有効にする] を選びます。
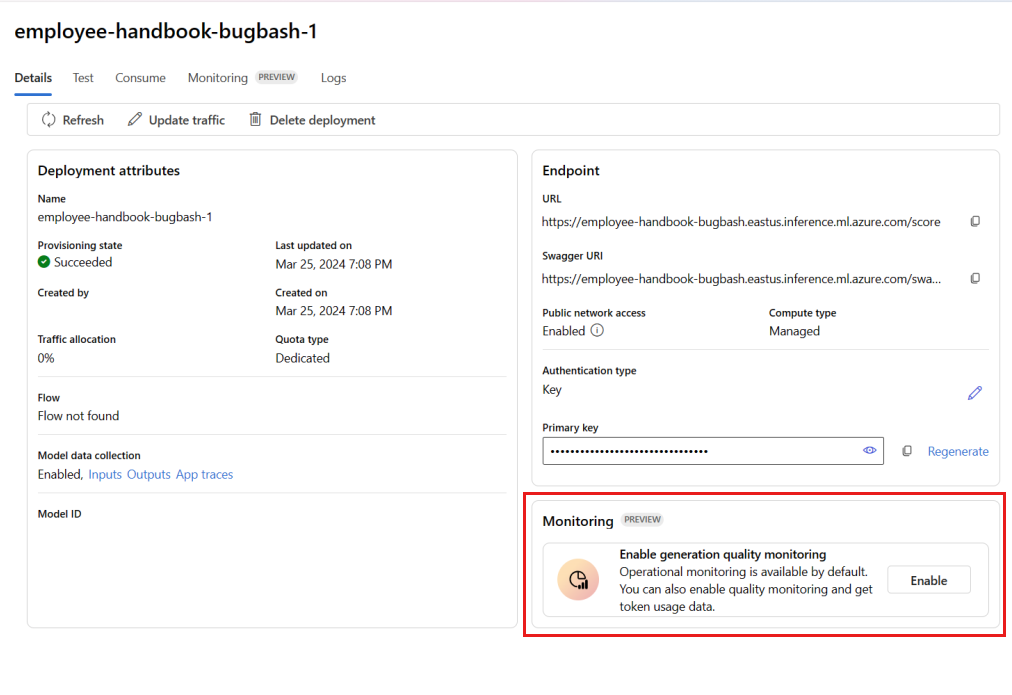
目的のメトリックを選択して、モニターの構成を開始します。
列名が、「列名のマッピング」の定義どおりにフローからマップされていることを確認します。
プロンプト フロー アプリケーションのモニターを実行するために使用する [Azure OpenAI 接続] と [デプロイ] を選びます。
[詳細オプション] を選ぶと、構成するその他のオプションが表示されます。
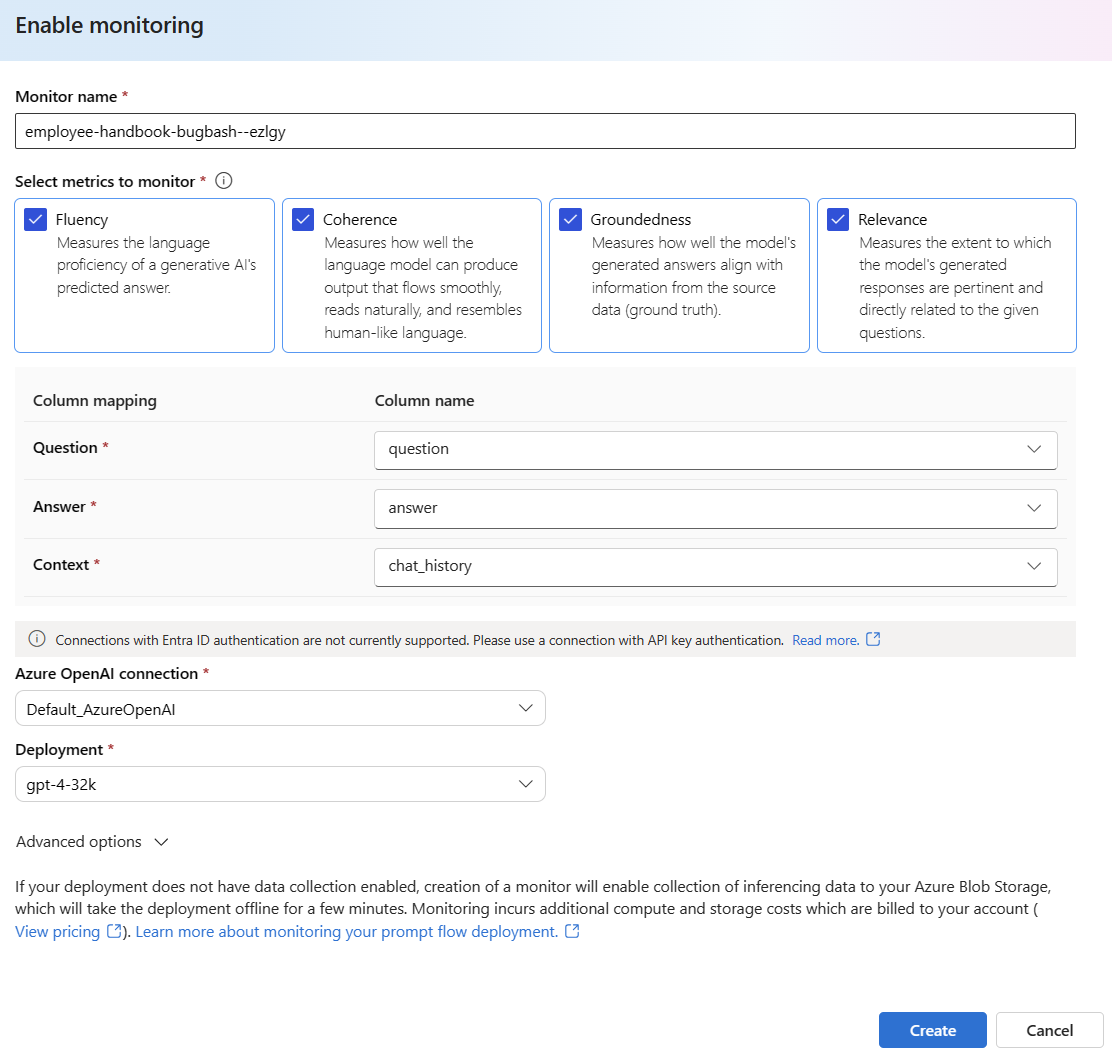
サンプリング レート、構成されたメトリックのしきい値を調整し、特定のメトリックの平均スコアがしきい値を下回ったときにアラートを受信するメール アドレスを指定します。
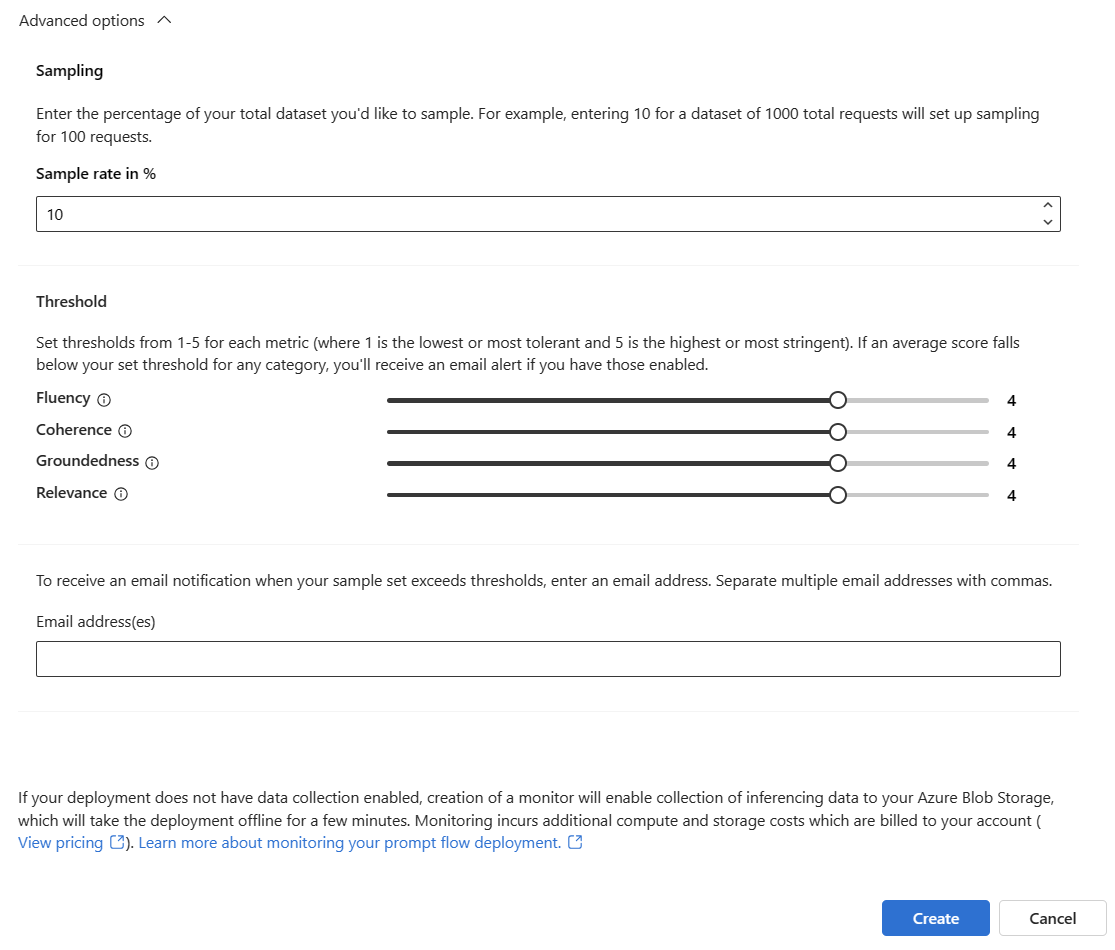
Note
デプロイでデータ収集が有効になっていない場合、モニターを作成すると、Azure Blob Storage への推論データの収集が有効になり、そのためにデプロイが数分間オフラインになります。
[作成] を選択してモニターを作成します。



監視結果を使用する
モニターの作成後は、それが毎日実行されて、トークンの使用量と生成品質メトリックが計算されます。
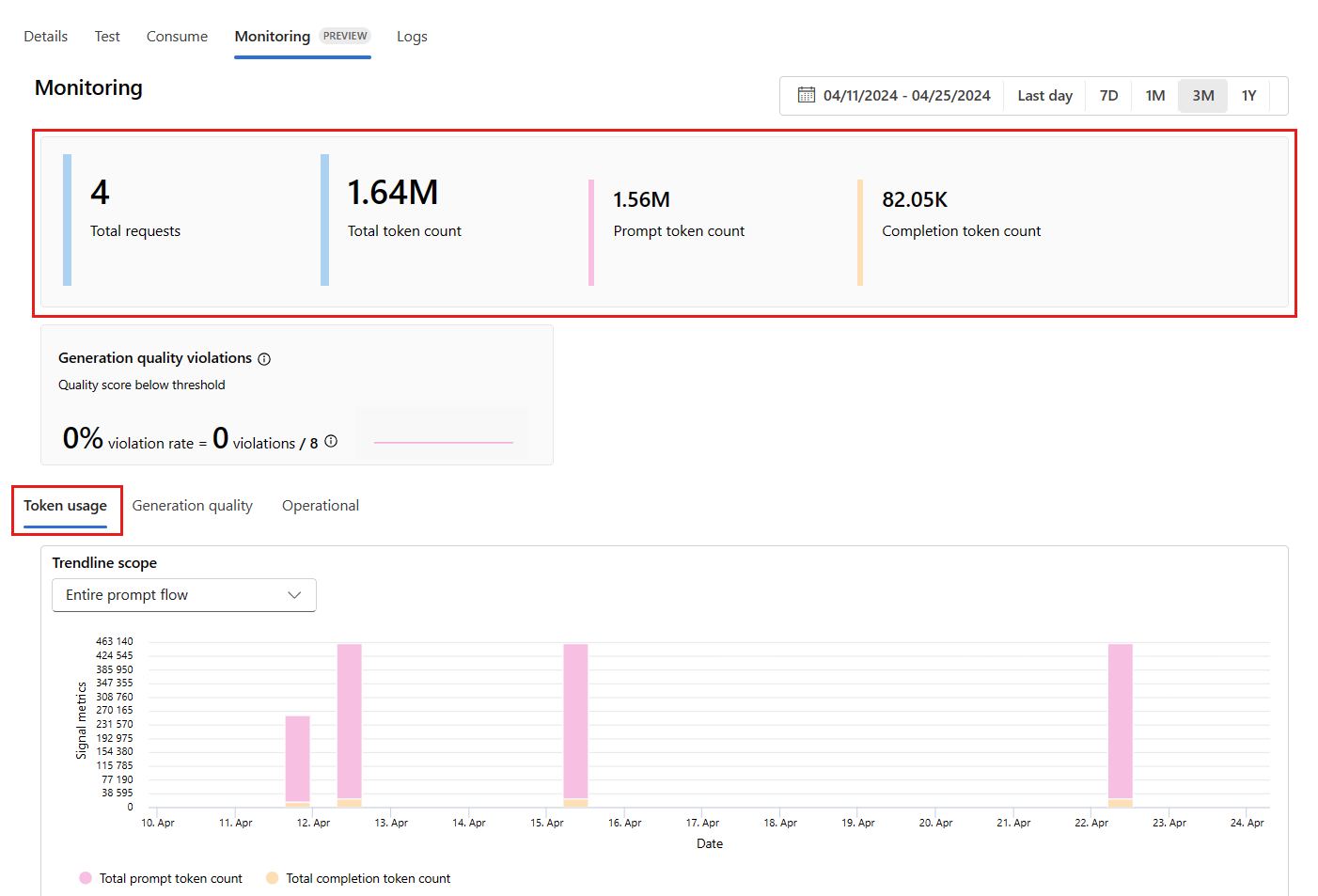
デプロイ内から [監視 (プレビュー)] タブに移動して、モニター結果を確認します。 ここに、選択した時間枠内のモニター結果の概要が表示されます。 日付ピッカーを使用して、モニターしているデータの時間枠を変更できます。 この概要では、次のメトリックを入手できます。
- 合計要求数: 選択した時間枠内にデプロイに送信された要求の合計数。
- 合計トークン数: 選択した時間枠内にデプロイによって使用されたトークンの合計数。
- プロンプト トークン数: 選択した時間枠内にデプロイによって使用されたプロンプト トークンの合計数。
- 入力候補トークン数: 選択した時間枠内にデプロイによって使用された入力候補トークンの合計数。
[トークンの使用状況] タブでメトリックを確認します (このタブは既定で選択されています)。 ここで、時間の経過に伴うアプリケーションのトークンの使用量を確認できます。 時間の経過に伴うプロンプト トークンと入力候補トークンの分布も確認できます。 [近似曲線スコープ] を変更して、アプリケーション内で使用される特定のデプロイ (gpt-4 など) について、アプリケーション全体のすべてのトークンまたはトークンの使用量をモニターできます。
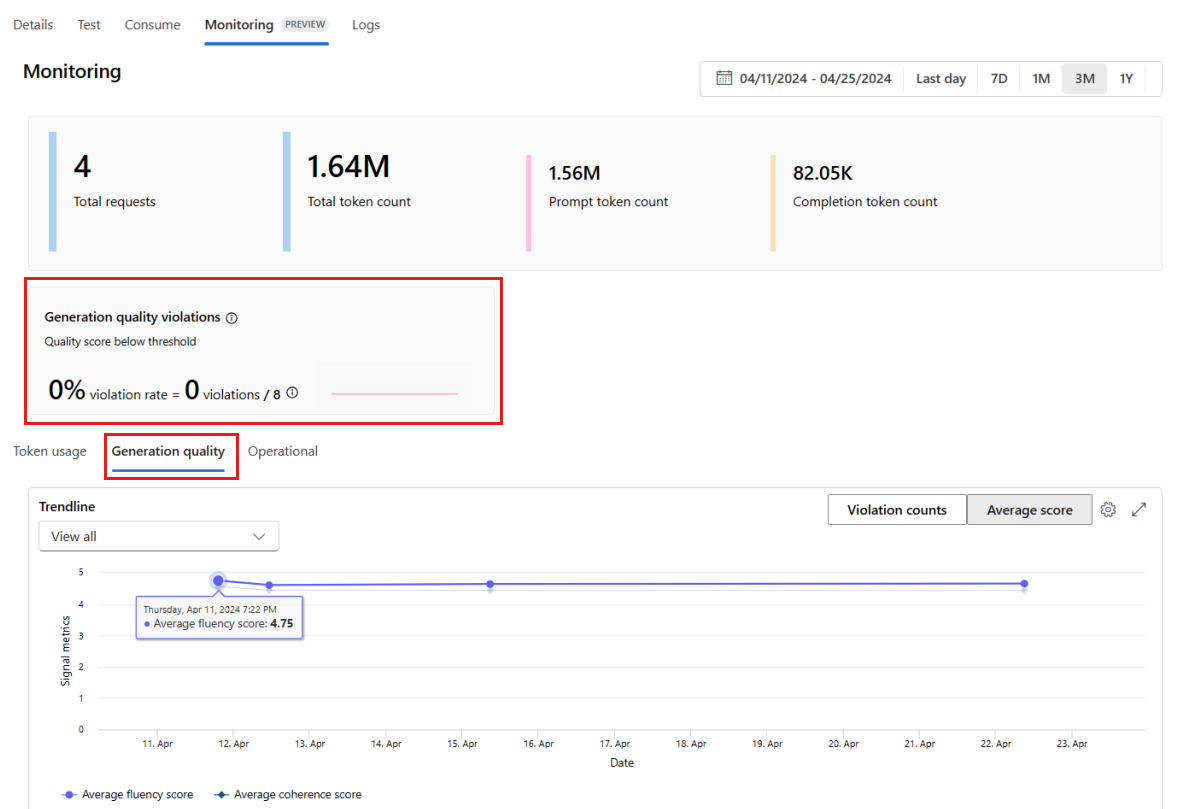
[Generation quality] (生成品質) タブに移動して、時間の経過に伴うアプリケーションの品質をモニターします。 次のメトリックが時間グラフに表示されます。
- 違反カウント: 特定のメトリック (流暢性など) の違反カウントは、選択した時間枠での違反の合計です。 "違反" は、メトリックが計算されたとき (既定では毎日) にメトリックに対して計算された値が設定されたしきい値を下回った場合に、そのメトリックに対して発生します。
- 平均スコア: 特定のメトリック (流暢性など) の平均スコアは、すべてのインスタンス (または要求) のスコアの合計を、選択した時間枠のインスタンス (または要求) の数で割った値です。
[Generation quality violations] (生成品質違反) カードに、選択した時間枠の [violation rate] (違反率) が表示されます。 [violation rate] (違反率) は、違反の数を、可能性がある違反の合計数で割った値です。 設定でメトリックのしきい値を調整できます。 既定では、メトリックは毎日計算されます。この頻度も、設定で調整できます。
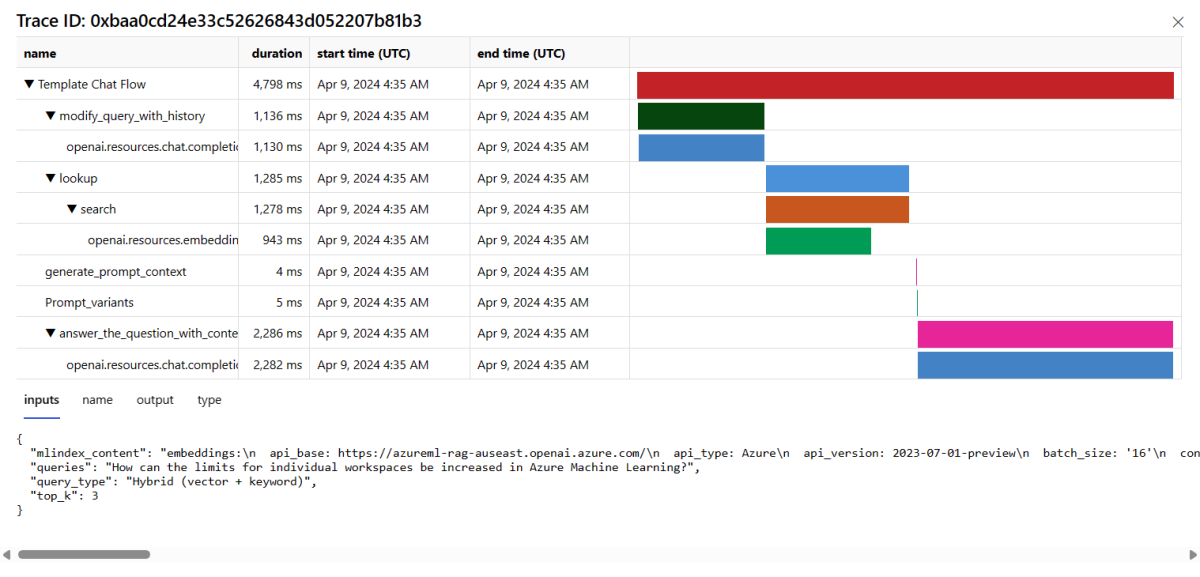
[監視 (プレビュー)] タブで、選択した時間枠内にデプロイに送信されたすべてのサンプリングされた要求の包括的な表を確認することもできます。
Note
モニターは、既定のサンプリング レートを 10% に設定します。 つまり、100 件の要求がデプロイに送信されると、10 件がサンプリングされ、生成品質メトリックの計算に使用されます。 設定で、サンプリング レートを調整できます。

テーブル内の行の右側にある [トレース] ボタンを選択すると、特定の要求のトレースの詳細が表示されます。 このビューには、アプリケーションへの要求に関する包括的なトレースの詳細が表示されます。
[トレース] ビューを閉じます。
[操作] タブに移動して、デプロイの運用メトリックをほぼリアルタイムで確認します。 次の運用メトリックがサポートされています。
- 要求数
- Latency
- エラー率
![デプロイの [操作] タブのスクリーンショット。](../media/deploy-monitor/monitor/deployment-operational-tab.png)




![デプロイの [操作] タブのスクリーンショット。](../media/deploy-monitor/monitor/deployment-operational-tab.png#lightbox)
デプロイの [監視 (プレビュー)] タブに表示される結果は、プロンプト フロー アプリケーションのパフォーマンスを積極的に向上させるために役立つ分析情報を提供します。
SDK v2 を使用した高度なモニター構成
モニターは、SDK v2 を使用した高度な構成オプションもサポートします。 次のシナリオがサポートされます。
トークンの使用量のモニターを有効にする
デプロイされたプロンプト フロー アプリケーションのトークンの使用量のモニターを有効にすることのみが必要な場合は、次のスクリプトをシナリオに合わせて調整できます。
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
生成品質のモニターを有効にする
デプロイされたプロンプト フロー アプリケーションの生成品質のモニターを有効にすることにのみが必要な場合は、次のスクリプトをシナリオに合わせて調整できます。
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
SDK からモニターを作成した後、Azure AI Foundry ポータルで監視結果を確認できます。
関連するコンテンツ
- Azure AI Foundry でできることについて、詳細を確認します。
- Azure AI に関する FAQ の記事で、よく寄せられる質問の回答を紹介しています。