Azure AI Foundry を使用して生成 AI モデルとアプリケーションを評価する方法
大量のデータセットに適用された際に、ご利用の生成 AI モデルとアプリケーションのパフォーマンスを徹底的に評価するために、評価プロセスを開始することができます。 この評価中、ご利用のモデルまたはアプリケーションは指定されたデータセットを使用してテストされ、そのパフォーマンスは数学ベースのメトリックおよび AI 支援メトリックの両方を使用して、定量的に測定されます。 この評価の実行では、そのアプリケーションの機能と制限事項に関する、包括的な分析情報が提供されます。
この評価を実行するには、ご利用の生成 AI モデルのパフォーマンスと安全性を評価するためのツールと機能を提供する包括的なプラットフォームである、Azure AI Foundry ポータル内の評価機能を利用することができます。 Azure AI Foundry ポータル内では、詳細な評価メトリックをログに記録、表示、分析することができます。
この記事では、Azure AI Foundry UI から組み込みの評価メトリックを使用して、モデル、テスト データセット、またはフローに対する評価実行を作成する方法について説明します。 柔軟性をさらに高めるために、カスタムの評価フローを確立し、カスタム評価機能を使用することができます。 または、目的がバッチの実行を行うだけで、何も評価をしない場合は、カスタム評価機能を利用することもできます。
前提条件
AI 支援メトリックを使用した評価を実行するには、次の準備が必要です。
- これらの形式のいずれかのテスト データセット:
csvまたはjsonl。 - Azure OpenAI 接続。 これらのモデルのいずれかのデプロイ: GPT 3.5 モデル、GPT 4 モデル、Davinci モデル。 AI 支援の品質評価を実行する場合にのみ必要です。
組み込みの評価メトリックを使用して評価を作成する
評価の実行を使用すると、ご利用のテスト データセット内のデータ行ごとに、メトリック出力を生成することができます。 1 つ以上の評価メトリックを選択して、さまざまな側面からの出力を評価することができます。 Azure AI Foundry ポータル内の評価、モデル カタログまたはプロンプト フロー ページから、評価実行を作成することができます。 それから評価の作成ウィザードが表示され、評価の実行を設定するプロセスが案内されます。
[評価] ページから
折りたたみ可能な左側のメニューから、[評価]>[+ 新しい評価の作成] を選択します。

モデル カタログ ページから
折りたたみ可能な左側のメニューから、[モデル カタログ]> を選択し、特定のモデルに移動し > [ベンチマーク] タブに移動し > 独自のデータを試します。 これによりモデル評価パネルが開き、選択したモデルに対する評価実行を作成することができます。
![モデル カタログ ページの [独自のデータを試す] ボタンのスクリーンショット。](../media/evaluations/evaluate/try-with-your-own-data.png#lightbox)
[フロー] ページから
折りたたみ可能な左側のメニューから、[プロンプト フロー]>[評価]>[自動評価] を選択します。

評価対象
[評価] ページから評価を開始する場合は、最初に評価ターゲットを決定する必要があります。 適切な評価ターゲットを指定することで、ご利用のアプリケーションの特定の性質に合わせて評価を調整し、正確で関連性の高いメトリックを確保することができます。 次の 3 種類の評価対象がサポートされています。
- モデルとプロンプト: 選択したモデルとユーザー定義プロンプトによって生成された出力を評価します。
- データセット: モデルによってテスト データセットに出力が生成されています。
- プロンプト フロー: フローを作成し、フローからの出力を評価します。

データセットまたはプロンプト フローの評価
評価作成ウィザードを入力するときに、評価実行に省略可能な名前を指定できます。 現在、クエリと応答のシナリオのサポートが提供されています。これは、ユーザー クエリに応答し、コンテキスト情報の有無にかかわらず応答を提供するアプリケーション向けに設計されています。
必要に応じて、評価実行に説明とタグを追加して、組織、コンテキスト、検索のしやすさを向上させることができます。
ヘルプ パネルを使用してよくあるご質問を確認し、ウィザードに従って進むこともできます。
![新しい評価を作成するときの [基本情報] ページのスクリーンショット。](../media/evaluations/evaluate/basic-information-dataset.png#lightbox)
プロンプト フローを評価する場合は、評価するフローを選択できます。 [フロー] ページから評価を開始する場合、評価するフローは自動的に選択されます。 別のフローを評価する場合は、別のフローを選択することができます。 フロー内には複数のノードがあり、それぞれのノードが独自のバリアント セットを持つ場合があることに注意することが重要です。 そのような場合は、評価プロセス中に評価するノードとバリアントを指定する必要があります。

テスト データの構成
既存のデータセットから選択する、または特定の評価のために新しいデータセットをアップロードすることもできます。 前の手順でフローが選択されていない場合、そのテスト データセットではモデルによって生成された出力を評価に使用する必要があります。
既存のデータセットを選択する: ご利用の確立されたデータセット コレクションからテスト データセットを選択することができます。
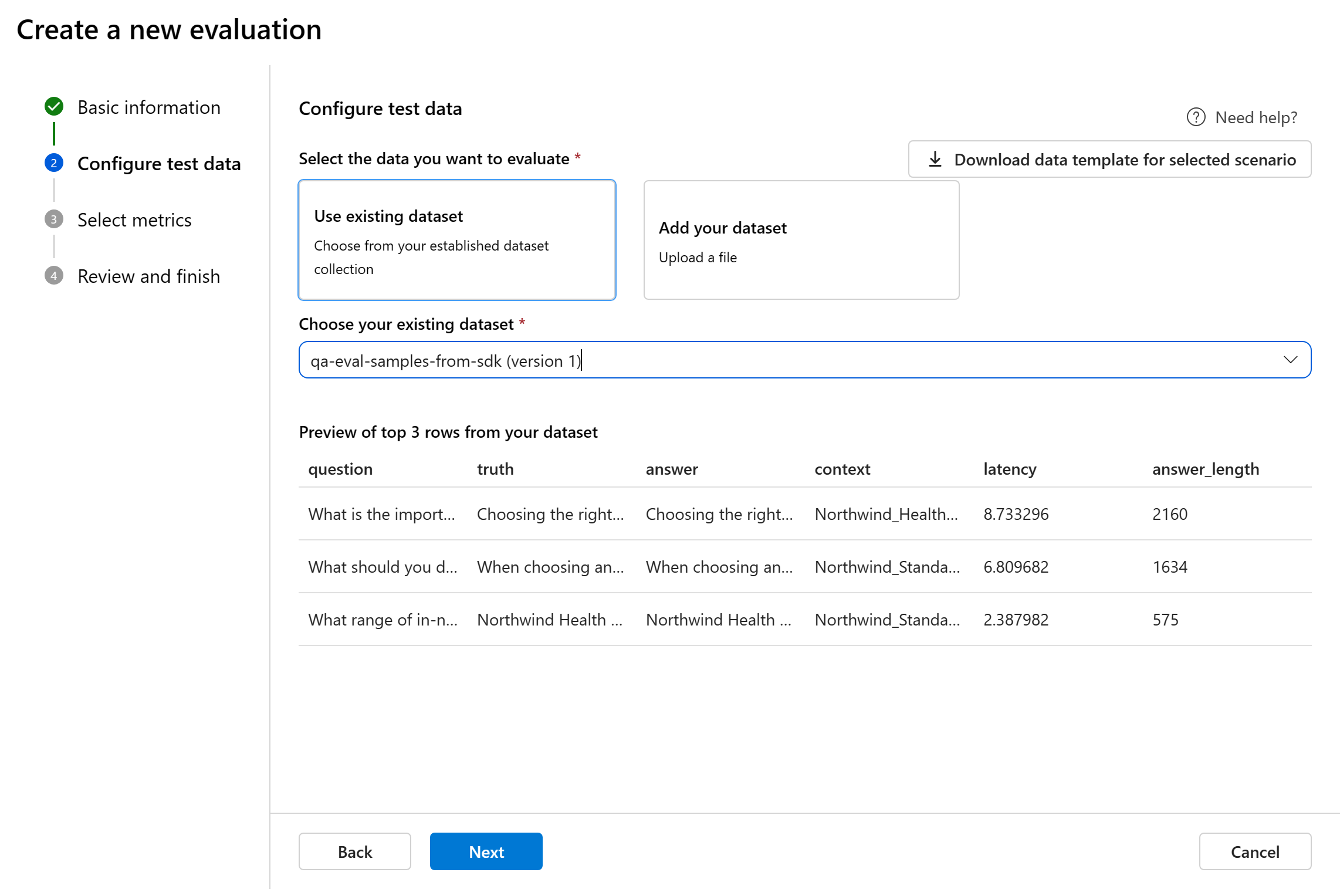
新しいデータセットを追加する: ご利用のローカル ストレージからファイルをアップロードします。
.csvおよび.jsonlファイル形式のみをサポートします。
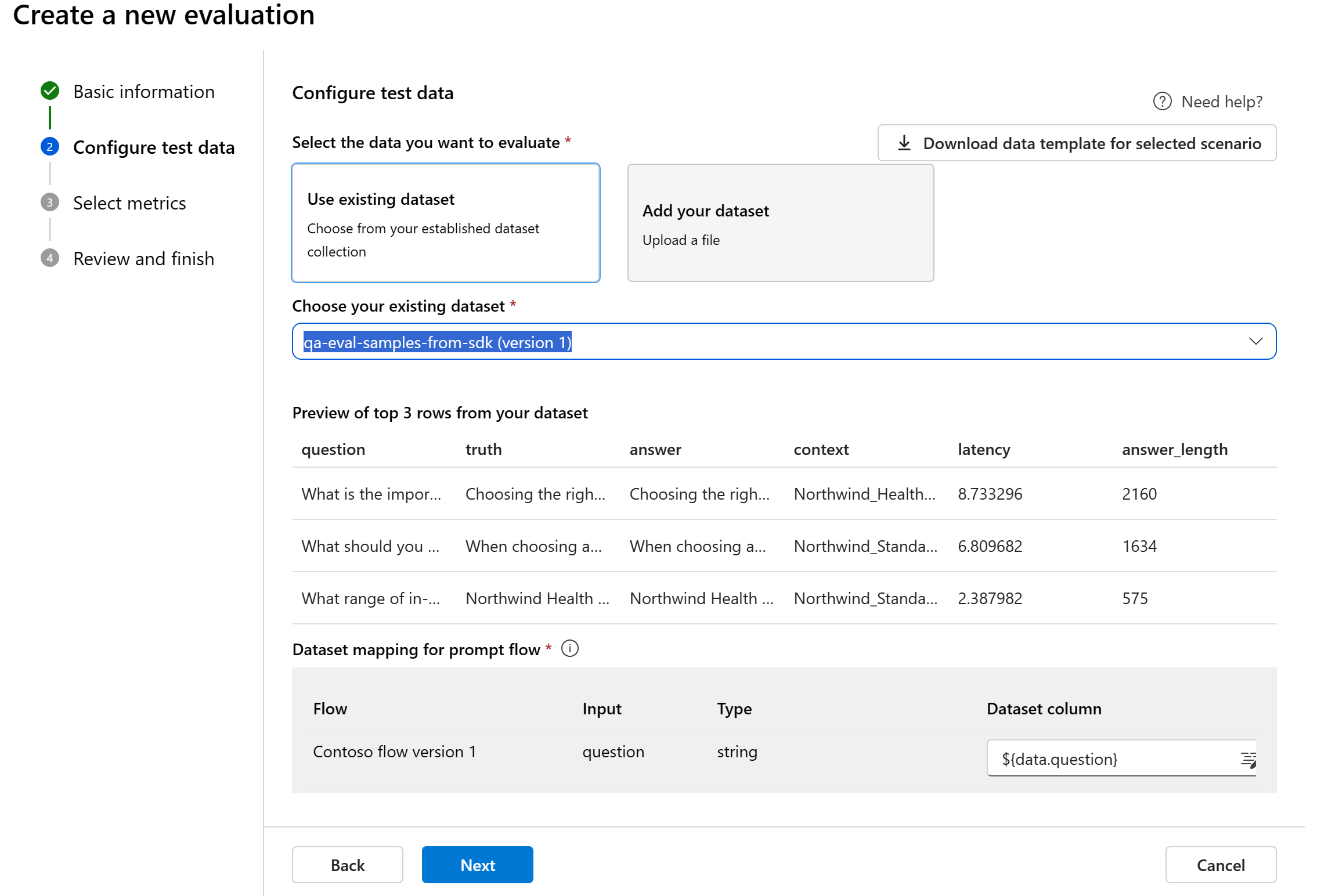
フローのデータ マッピング: 評価するフローを選択する場合、バッチ実行を実行して評価用の出力を生成するためにフローに必要な入力に合わせてデータ列が構成されていることを確認します。 その後、評価はフローからの出力を使用して行われます。 その後、次の手順で評価入力用のデータ マッピングを構成します。



メトリックを選択してください
Microsoft は、アプリケーションの包括的な評価を容易にするために Microsoft によってキュレーションされた 3 種類のメトリックをサポートしています。
- AI 品質 (AI 支援): これらのメトリックは、生成されたコンテンツの全体的な品質と一貫性を評価します。 これらのメトリックを実行するには、ジャッジとしてのモデル デプロイが必要です。
- AI 品質 (NLP): これらの NLP メトリックは数学に基づいており、生成されたコンテンツの全体的な品質も評価します。 多くの場合、グラウンド トゥルース データが必要ですが、ジャッジとしてモデル デプロイは必要ありません。
- リスクと安全性に関するメトリック: これらのメトリックは、潜在的なコンテンツのリスクを特定し、生成されたコンテンツの安全性を確保することに焦点を当てています。
![[AI の品質と安全性] が選択された状態で評価する対象を選択しているスクリーンショット。](../media/evaluations/evaluate/select-metric-category.png#lightbox)
各シナリオ内でサポートされるメトリックのすべてのリストについては、表をご参照ください。 各メトリックの定義とその計算方法のさらに詳しい情報については、「評価と監視に関するメトリック」をご確認ください。
| AI 品質 (AI 支援) | AI 品質 (NLP) | リスクと安全性に関するメトリック |
|---|---|---|
| 根拠性、関連性、一貫性、流暢さ、GPT 類似性 | F1 スコア、ROUGE スコア、BLEU スコア、GLEU スコア、METEOR スコア | 自傷行為に関連するコンテンツ、ヘイトフルで不公平なコンテンツ、暴力的コンテンツ、性的コンテンツ、保護された素材、間接攻撃 |
AI 支援の品質評価を実行する場合は、その計算プロセス用の GPT モデルを指定する必要があります。 計算には、GPT-3.5、GPT-4、または Davinci モデルのいずれかを使用する Azure OpenAI 接続とデプロイを選択します。

AI 品質 (NLP) メトリックは、アプリケーションのパフォーマンスを評価する数学に基づいた測定値です。 多くの場合、計算にはグラウンド トゥルース データが必要です。 ROUGE はメトリックのファミリです。 ROUGE タイプを選択すると、スコアを計算できます。 さまざまな種類の ROUGE メトリックにより、テキスト生成の品質を評価する方法が提供されます。 ROUGE-N は、候補テキストと参照テキスト間の n グラムの重複を測定します。

リスクと安全性に関するメトリックについては、接続とデプロイを提供する必要はありません。 Azure AI Foundry ポータルの安全性評価バックエンド サービスは、コンテンツ リスクの重大度スコアと推論を生成できる GPT-4 モデルをプロビジョニングし、アプリケーションでコンテンツの損害を評価できるようにします。
しきい値を設定して、コンテンツの有害メトリック (自傷関連コンテンツ、ヘイトフルで不公平なコンテンツ、暴力的コンテンツ、性的コンテンツ) の瑕疵率を計算できます。 欠陥率は、重大度レベル (非常に低い、低、中、高) がしきい値を超えるインスタンスの割合を求めることによって計算されます。 既定では、しきい値は "Medium" に設定されます。
保護されたマテリアルと間接攻撃の場合、欠陥率は、出力が "true" であるインスタンスの割合として計算されます (欠陥率 = (#trues/#instances) × 100)。

Note
AI 支援によるリスクと安全性に関するメトリックは、Azure AI Foundry の安全性評価バックエンド サービスによってホストされ、米国東部 2、フランス中部、英国南部、スウェーデン中部のリージョンでのみご使用になれます
評価のデータ マッピング: 評価内で必要な入力に対応する、ご利用のデータセット内のデータ列を指定する必要があります。 評価メトリックが異なると、正確な計算のために異なる種類のデータ入力が必要になります。

Note
データからの評価を行う場合、"response" はデータセット ${data$response} 内の response 列にマップされる必要があります。 フローからの評価を行う場合、"response" は、フロー出力 ${run.outputs.response} から取得する必要があります。
各メトリックの特定のデータ マッピング要件に関するガイダンスは、次の表の情報をご参照ください。
クエリと応答のメトリック要件
| メトリック | クエリ | 回答 | Context | グランド トゥルース |
|---|---|---|---|---|
| 現実性 | 必須: Str | 必須: Str | 必須: Str | 該当なし |
| 一貫性 | 必須: Str | 必須: Str | 該当なし | 該当なし |
| 流暢性 | 必須: Str | 必須: Str | 該当なし | 該当なし |
| 関連性 | 必須: Str | 必須: Str | 必須: Str | 該当なし |
| GPT 類似性 | 必須: Str | 必須: Str | 該当なし | 必須: Str |
| F1 スコア | 該当なし | 必須: Str | 該当なし | 必須: Str |
| BLEU スコア | 該当なし | 必須: Str | 該当なし | 必須: Str |
| GLEU スコア | 該当なし | 必須: Str | 該当なし | 必須: Str |
| METEOR スコア | 該当なし | 必須: Str | 該当なし | 必須: Str |
| ROUGE スコア | 該当なし | 必須: Str | 該当なし | 必須: Str |
| 自傷行為に関連するコンテンツ | 必須: Str | 必須: Str | 該当なし | 該当なし |
| ヘイトフルで不公平なコンテンツ | 必須: Str | 必須: Str | 該当なし | 該当なし |
| 暴力的なコンテンツ | 必須: Str | 必須: Str | 該当なし | 該当なし |
| 性的なコンテンツ | 必須: Str | 必須: Str | 該当なし | 該当なし |
| 保護済み素材 | 必須: Str | 必須: Str | 該当なし | 該当なし |
| 間接攻撃 | 必須: Str | 必須: Str | 該当なし | 該当なし |
- クエリ: 特定の情報を求めるクエリ。
- 応答: モデルによって生成されたクエリへの応答。
- コンテキスト: 応答が生成されるソース (つまり、基になるドキュメント)...
- グラウンド トゥルース: 真の答えとしてユーザー/人間によって生成された、クエリへの応答。
レビューして終了する
必要なすべての構成が完了すると、確認して [送信] の選択に進み、評価の実行を送信することができます。
![新しい評価を作成するための [レビューと完了] ページのスクリーンショット。](../media/evaluations/evaluate/review-and-finish.png#lightbox)
モデルとプロンプトの評価
選択したモデル デプロイと定義されたプロンプトに対して新しい評価を作成するには、簡略化されたモデル評価パネルを使用します。 この合理化されたインターフェイスを使用すると、1 つの統合パネル内で評価を構成して開始できます。
基本情報
まず、評価実行の名前を設定します。 次に、評価するモデル デプロイを選択します。 Azure OpenAI モデルと、Meta Llama や Phi-3 ファミリ モデルなど、サービスとしてのモデル (MaaS) と互換性のある他のオープン モデルの両方がサポートされています。 オプションで、最大応答、温度、トップ P などのモデル パラメーターをニーズに基づいて調整できます。
[システム メッセージ] テキスト ボックスで、シナリオのプロンプトを指定します。 プロンプトを作成する方法の詳細については、プロンプト カタログを参照してください。 チャットにどのような応答が必要かを示すために、例を追加することもできます。 それがここで追加する応答を模倣して、システム メッセージに設定されたルールと一致することを確認します。

テスト データを構成する
モデルとプロンプトを構成した後、評価に使用するテスト データセットを設定します。 このデータセットは、評価の応答を生成するためにモデルに送信されます。 テスト データを構成するには、次の 3 つのオプションがあります。
- サンプル データを作成する
- 既存のデータセットを使用する
- データセットを追加する
データセットをすぐに使用できなくても、小さなサンプルで評価を実行する場合は、GPT モデルを使用して、選択したトピックに基づいてサンプルの質問を生成するオプションを選択できます。 このトピックは、生成されたコンテンツを関心領域に合わせて調整するのに役立ちます。 クエリと応答はリアルタイムで生成され、必要に応じて再生成することもできます。
Note
生成されたデータセットは、評価実行が作成されると、プロジェクトの BLOB ストレージに保存されます。

データ マッピング
既存のデータセットを使用するか、新しいデータセットをアップロードする場合は、データセットの列を評価に必要なフィールドにマップする必要があります。 評価中、モデルの応答は、次のような主要な入力に対して評価されます。
- クエリ: すべてのメトリックに必要
- コンテキスト: オプション
- グラウンド トゥルース: オプション、AI 品質 (NLP) メトリックに必要
これらのマッピングにより、データと評価基準の間の正確なアラインメントが保証されます。

評価メトリックの選択
最後の手順では、評価する内容を選択します。 個々のメトリックを選択し、使用可能なすべてのオプションについて理解するのではなく、ニーズに最適なメトリック カテゴリを選択できるようにすることで、プロセスを簡略化します。 カテゴリを選択すると、そのカテゴリ内のすべての関連メトリックが、前の手順で指定したデータ列に基づいて計算されます。 メトリック カテゴリを選択したら、[作成] を選択して評価実行を送信し、[評価] ページに移動して結果を表示できます。
次の 3 つのカテゴリがサポートされています。
- AI 品質 (AI 支援): AI 支援メトリックを計算する際に、ジャッジとして Azure OpenAI モデル デプロイを指定する必要があります。
- AI 品質 (NLP)
- 安全性
| AI 品質 (AI 支援) | AI 品質 (NLP) | 安全性 |
|---|---|---|
| 根拠性 (コンテキストが必要)、関連性 (コンテキストが必要)、一貫性、流暢性 | F1 スコア、ROUGE スコア、BLEU スコア、GLEU スコア、METEOR スコア | 自傷行為に関連するコンテンツ、ヘイトフルで不公平なコンテンツ、暴力的コンテンツ、性的コンテンツ、保護された素材、間接攻撃 |
カスタム評価フローを使用して評価を作成する
以下のように、独自の評価手法を開発することができます。
フロー ページから: 左側の折りたたみメニューから、[プロンプト フロー]>[評価]>[カスタム評価] を選択します。

エバリュエーター ライブラリでエバリュエーターを表示して管理する
エバリュエーター ライブラリは、エバリュエーターの詳細と状態を確認できる一元化された場所です。 Microsoft によってキュレーションされたエバリュエーターを表示して管理できます。
ヒント
カスタム エバリュエーターは、プロンプト フロー SDK を介して使用できます。 詳細については、「プロンプト フロー SDK を使用して評価する」を参照してください。
エバリュエーター ライブラリでは、バージョン管理も実現できます。 作業内容のさまざまなバージョンを比較し、必要に応じて以前のバージョンを復元し、他の人とより簡単に共同作業を行うことができます。
Azure AI Foundry ポータルでエバリュエーター ライブラリを使用するには、プロジェクトの [評価] ページに移動し、[エバリュエーター ライブラリ] タブを選択します。

エバリュエーター名を選択すると、さらなる詳細を表示できます。 名前、説明、およびパラメーターを表示し、エバリュエーターに関連付けられているすべてのファイルを確認できます。 以下に Microsoft によってキュレーションされたエバリュエーターの例をいくつか示します。
- Microsoft によってキュレーションされたパフォーマンスおよび品質のエバリュエーターについては、詳細ページで注釈プロンプトを表示できます。 Azure AI 評価 SDK を使用して自身のデータと目的に応じてパラメーターまたは条件を変更することで、これらのプロンプトを独自のユース ケースに適応させることができます。 たとえば、Groundedness-Evaluator を選択し、メトリックの計算方法を示す Prompty ファイルを確認できます。
- Microsoft によってキュレーションされたリスクと安全性のエバリュエーターについては、メトリックの定義を確認できます。 たとえば、Self-Harm-Related-Content-Evaluator を選択し、それが意味するものと、Microsoft がこの安全性メトリックのさまざまな重大度レベルをどのように決めているかを確認できます。
次のステップ
ご利用の生成 AI アプリケーションを評価する方法の詳細については、次をご参照ください。