Azure AI Foundry ポータルで Phi-3 モデルを微調整する
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
Azure AI Foundry では、微調整と呼ばれるプロセスを使用して、大規模な言語モデルを個人用データセットに合わせて調整できます。 微調整では、特定のタスクとアプリケーションのカスタマイズと最適化を可能にすることで、大きな価値が得られます。 これにより、パフォーマンスの向上、コスト効率、待機時間の短縮、および調整された出力が実現されます。
この記事では、従量課金制を使用するサービスとして Azure AI Foundry ポータルで小規模言語モデル (SLB) の Phi-3 ファミリを微調整する方法を学習します。
SLM の Phi-3 ファミリは、命令でチューニングされた生成テキスト モデルのコレクションです。 Phi-3 モデルは、利用可能な小規模言語モデルの中で、さまざまな言語、推論、コーディング、数学ベンチマークで同等のサイズと次段階のサイズのモデルを上回る、最高レベルの能力とコスト効率を発揮する小規模言語モデル (SLM) です。
重要
プレビュー段階のモデルは、モデルカタログ内のモデル カードで "プレビュー" のマークが付けられます。
Phi-3 Mini は、高品質で推論密度の高いデータに焦点を当て、Phi-2 に使用されているデータセット (合成データとフィルター処理された Web サイト) に基づいて構築された 38 億個のパラメーターを持つ軽量かつ最先端のオープン モデルです。 このモデルは Phi-3 モデル ファミリに属し、Mini バージョンには 4K と 128K の 2 つのバリエーションがあります。これは、モデルがサポートできるコンテキストの長さ (トークン単位) を表します。
- Phi-3-mini-4k-Instruct (プレビュー)
- Phi-3-mini-128k-Instruct (プレビュー)
このモデルは厳格な強化プロセスを経て、監督された微調整と直接の優先設定の両方を組み込むことで、正確な指示の遵守と堅牢な安全対策を保証します。 常識、言語理解、数学、コード、コンテキストの長い論理的な推論をテストするベンチマークでの評価では、Phi-3 Mini-4K-Instruct と Phi-3 Mini-128K-Instruct は、パラメーター数が 130 億未満のモデルとして信頼性の高い最先端のパフォーマンスを示しました。
前提条件
Azure サブスクリプション。 Azure サブスクリプションを持っていない場合は、始めるために有料の Azure アカウントを作成してください。
-
重要
Phi-3 ファミリ モデルに関して従量課金制モデル微調整オファリングが利用できるのは、米国東部 2 リージョン内に作成されたハブにおいてだけです。
Azure AI Foundry ポータルでの操作に対するアクセス権を付与するには、Azure ロールベースのアクセス制御 (Azure RBAC) を使用します。 この記事の手順を実行するには、ご自分のユーザー アカウントに、リソース グループの Azure AI 開発者ロールを割り当てる必要があります。
アクセス許可について詳しくは、「Azure AI Foundry ポータルでのロールベースのアクセス制御」をご覧ください。
サブスクリプション プロバイダーの登録
Azure サブスクリプションが Microsoft.Network リソース プロバイダーに登録されていることを確認してください。
- Azure portal にサインインします。
- 左側のメニューで、[サブスクリプション] を選択します。
- 使用するサブスクリプションを選択します。
- 左側のメニューから [設定]>[リソース プロバイダー] を選択します。
- Microsoft.Network がリソース プロバイダーの一覧にあることを確認します。 ない場合は追加してください。
データ準備
トレーニングデータと検証データを準備して、モデルを微調整します。 トレーニング データと検証データのセットは、モデルの実行方法に関する入力と出力の例で構成されます。
すべてのトレーニング例が、推論に必要な形式に従っていることを確認します。 モデルを効果的に微調整するには、バランスのとれた多様なデータセットを確保してください。
つまり、データバランスを維持し、さまざまなシナリオを含み、社会の実情に合わせてトレーニング データを定期的に調整することで、最終的にはより正確でバランスの取れたモデル応答が得られます。
モデルの種類が異なると、異なる形式のトレーニング データが必要になります。
チャット入力候補
使用するトレーニングおよび検証データは、JSON Lines (JSONL) ドキュメントの形式である必要があります。 Phi-3-mini-128k-instruct の場合、微調整データセットの形式は、チャット入力候補 API で使用される会話形式でである必要があります。
ファイル形式の例
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
サポートされているファイルの種類は、JSON Lines です。 ファイルは既定のデータストアにアップロードされ、プロジェクトで使用できるようになります。
Phi-3 モデルを微調整する
Phi-3 モデルを微調整するには:
Azure AI Foundry のモデル カタログから、微調整するモデルを選びます。
モデルの [詳細] ページで、fine-tune を選びます。
モデルを微調整するプロジェクトを選びます。 従量課金制モデル微調整オファリングを使用するには、ワークスペースが米国東部 2 リージョンに属している必要があります。
微調整ウィザードで、Azure AI Foundry の使用条件へのリンクを選択して、使用条件の詳細を確認します。 また、[Azure AI Foundry オファーの詳細] タブを選択すると、選択したモデルの価格を確認することもできます。
プロジェクトでモデルを初めて微調整する場合は、Azure AI Foundry から特定のオファリング (たとえば、Phi-3-mini-128k-instruct) にプロジェクトをサブスクライブする必要があります。 この手順は、前提条件に記載されている Azure サブスクリプションのアクセス許可とリソース グループのアクセス許可がアカウントに付与されていることを必要とします。 各プロジェクトには、特定の Azure AI Foundry オファリングへの独自のサブスクリプションがあり、これにより支出を制御および監視できます。 [サブスクライブして微調整] を選択します。
Note
特定の Azure AI Foundry オファリング (この場合は Phi-3-mini-128k-instruct) にプロジェクトをサブスクライブするには、アカウントに、プロジェクトが作成されるサブスクリプション レベルの共同作成者または所有者のアクセス権が必要です。 別の方法として、「前提条件」に記載されている Azure サブスクリプションのアクセス許可とリソース グループのアクセス許可を持つカスタム ロールをユーザー アカウントに割り当てることもできます。
特定の Azure AI Foundry オファリングにプロジェクトをサインアップすると、"同じ" プロジェクト内の "同じ" オファリングの以降の微調整で再度サブスクライブする必要はありません。 そのため、以降の微調整ジョブに対するサブスクリプション レベルのアクセス許可を持つ必要はありません。 このシナリオが該当する場合は、[微調整を続行] を選びます。
微調整されたモデルの名前と、省略可能なタグと説明を入力します。
トレーニング データを選択して、モデルを微調整します。 詳細については、「データ準備」を参照してください。
Note
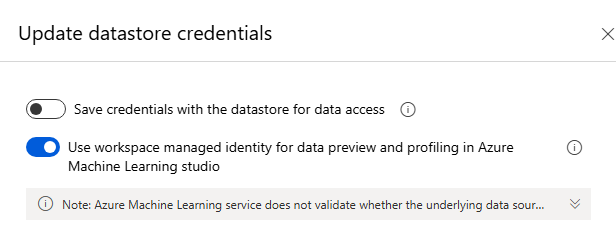
資格情報なしのデータストア内にトレーニング/検証ファイルを置いている場合は、資格情報なしのストレージで MaaS の微調整を進めるために、ワークスペース マネージド ID がデータストアにアクセスすることを許可する必要があります。 "データストア" ページで、"認証の更新" をクリック > 以下のオプションを選択します。
すべてのトレーニング例が、推論に必要な形式に従っていることを確認します。 モデルを効果的に微調整するには、バランスのとれた多様なデータセットを確保してください。 つまり、データバランスを維持し、さまざまなシナリオを含み、社会の実情に合わせてトレーニング データを定期的に調整することで、最終的にはより正確でバランスの取れたモデル応答が得られます。
- トレーニングに使用するバッチ サイズ。 -1 に設定すると、batch_size はトレーニング セットの例の 0.2% として計算されます。最大値は 256 です。
- 微調整の学習率は、事前トレーニングに使用された元の学習率にこの乗数を掛けた値です。 0.5 ~ 2 の値を使用して実験することをお勧めします。 経験的に、多くの場合、より大きなバッチ サイズでは、学習率が高いほどパフォーマンスが向上することがわかっています。 0.0 から 5.0 の間である必要があります。
- トレーニング エポックの数。 エポックとは、データ セットを 1 回完全に循環することを指します。
タスク パラメーターは省略可能な手順であり、高度なオプションです。ハイパーパラメーターの調整は、実際のアプリケーションにおいて大規模な言語モデル (LLM) を最適化するために不可欠です。 これにより、パフォーマンスが向上し、リソースの効率的な使用が可能になります。 ユーザーは既定の設定をそのまま使用することを選択でき、上級ユーザーはエポックや学習率などのパラメーターをカスタマイズすることができます。
選択内容を確認し、モデルのトレーニングに進みます。
モデルを微調整したら、モデルをデプロイし、独自のアプリケーション、プレイグラウンド、またはプロンプト フローで使用できます。 詳細については、「Azure AI Foundry を使用して大規模言語モデルの Phi-3 ファミリをデプロイする方法」を参照してください。
微調整されたモデルのクリーンアップ
微調整されたモデルは、Azure AI Foundry の微調整モデルの一覧、またはモデルの詳細ページから削除できます。 [微調整] ページから削除する微調整されたモデルを選択し、[削除] ボタンを選択して微調整されたモデルを削除します。
Note
既存のデプロイがある場合は、カスタム モデルを削除できません。 カスタム モデルを削除する前に、まずモデル デプロイを削除する必要があります。
コストとクォータ
サービスとして微調整される Phi モデルのコストとクォータに関する考慮事項
サービスとして微調整された Phi モデルは、Microsoft によって提供され、Azure AI Foundry と統合されて使用されます。 デプロイ ウィザードの [価格と使用条件] タブで、モデルのデプロイまたは微調整を行う場合の価格を確認できます。
サンプル ノートブック
このサンプル ノートブックを使ってスタンドアロンの微調整ジョブを作成すると、Samsum データセットを使って 2 人のユーザー間のやり取りを要約するモデルの機能を強化できます。 使用されるトレーニング データは、ultrachat_200k データセットです。これは、監視対象の微調整 (sft) と生成ランク付け (gen) に適した 4 つの分割に分かれています。 ノートブックでは、チャット完了タスクに使用できる Azure AI モデルが採用されています (ノートブックで使用されているものとは異なるモデルを使用する場合は、モデル名を置き換えることができます)。 ノートブックには、前提条件の設定、微調整するモデルの選択、トレーニングと検証のデータセットの作成、微調整ジョブの構成と送信、最後に、サンプル推論用に微調整されたモデルを使用したサーバーレス デプロイの作成が含まれます。
コンテンツのフィルター処理
従量課金制でサービスとしてデプロイされたモデルは、Azure AI Content Safety によって保護されます。 リアルタイム エンドポイントにデプロイするときは、この機能をオプトアウトできます。 Azure AI Content Safety を有効にすると、プロンプトと入力候補の両方が、有害なコンテンツ出力の検出と防止を目的とした一連の分類モデルを通過します。 コンテンツ フィルタリング (プレビュー) システムは、入力プロンプトと出力される入力候補の両方で、有害な可能性があるコンテンツ特有のカテゴリを検出し、アクションを実行します。 Azure AI Content Safety の詳細を確認します。