Azure AI Foundry ポータルで評価結果を表示する方法
Azure AI Foundry ポータルの評価ページは、結果を視覚化して評価できるだけでなく、デプロイのニーズに合わせた最適な AI モデルの最適化、トラブルシューティング、選択を行うためのコントロール センターとしても機能する汎用性の高いハブです。 これは、Azure AI Foundry プロジェクトでデータ主導の意思決定を行い、パフォーマンスを向上させるためのワンストップ ソリューションです。 フロー、プレイグラウンドのクイック テスト セッション、評価送信 UI、SDK などのさまざまなソースからの結果にシームレスにアクセスして解釈できます。 この柔軟性により、ワークフローやユーザー設定に最も適した方法で結果を操作できます。
評価結果を視覚化したら、結果を詳細に調べることができます。 個々の結果を表示できるだけでなく、複数の評価実行全体でこれらの結果を比較することもできます。 これにより、傾向、パターン、不一致を特定し、さまざまな条件下での AI システムのパフォーマンスに関する非常に有益な分析情報を得ることができます。
この記事では、次の内容について説明します。
- 評価結果とメトリックを表示します。
- 評価結果を比較します。
- 組み込みの評価メトリックを理解します。
- パフォーマンスを向上します。
- 評価結果とメトリックを表示します。
評価結果を見つける
評価を送信すると、「評価」タブに移動して、実行リスト内で送信された評価実行を見つけることができます。
実行リスト内で評価実行を監視および管理できます。 列エディターを使用して列を柔軟に変更し、フィルターを実装できるため、実行リストをカスタマイズして独自のバージョンのリストを作成できます。 さらに、複数の実行全体で集計された評価メトリクスを迅速に確認できるため、比較をすばやく実行できます。

ヒント
任意のバージョンの promptflow-evals SDK または azure-ai-evaluation バージョン 1.0.0b1、1.0.0b2、1.0.0b3 で評価の実行を表示するには、[すべての実行を表示] トグルを有効にして実行を見つけます。
評価メトリックの導き出す方法をより深く理解するには、[メトリックの詳細] オプションを選択すると、包括的な説明にアクセスできます。 この詳細なリソースでは、評価プロセスで使用される計算と解釈に関する有益な分析情報が提供されます。

特定の実行を選択すると、実行の詳細ページに移動します。 ここでは、テスト データセット、タスクの種類、プロンプト、温度などの評価の詳細を含む包括的な情報にアクセスできます。 さらに、各データ サンプルに関連付けられたメトリックも表示できます。 メトリック スコア グラフには、各メトリックのスコアが、データセット全体でどのように分散しているかが視覚的に表示されます。
メトリック ダッシュボード グラフ
集計ビューを、AI 品質 (AI 支援)、リスクと安全性、AI 品質 (NLP)、カスタム (該当する場合) によって、さまざまな種類のメトリックで分割します。 評価されたデータセット全体のスコアの分布を表示し、各メトリックの集計スコアを確認できます。
- AI 品質 (AI 支援) の場合は、各メトリックのすべてのスコアの平均を計算して集計します。 Groundedness Pro を計算する場合、出力はバイナリであるため、集計スコアは合格率であり、(#trues/#instances) x 100 で計算されます。
![[AI 品質 (AI 支援) メトリック ダッシュボード] タブのスクリーンショット。](../media/evaluations/view-results/ai-quality-ai-assisted-chart.png)
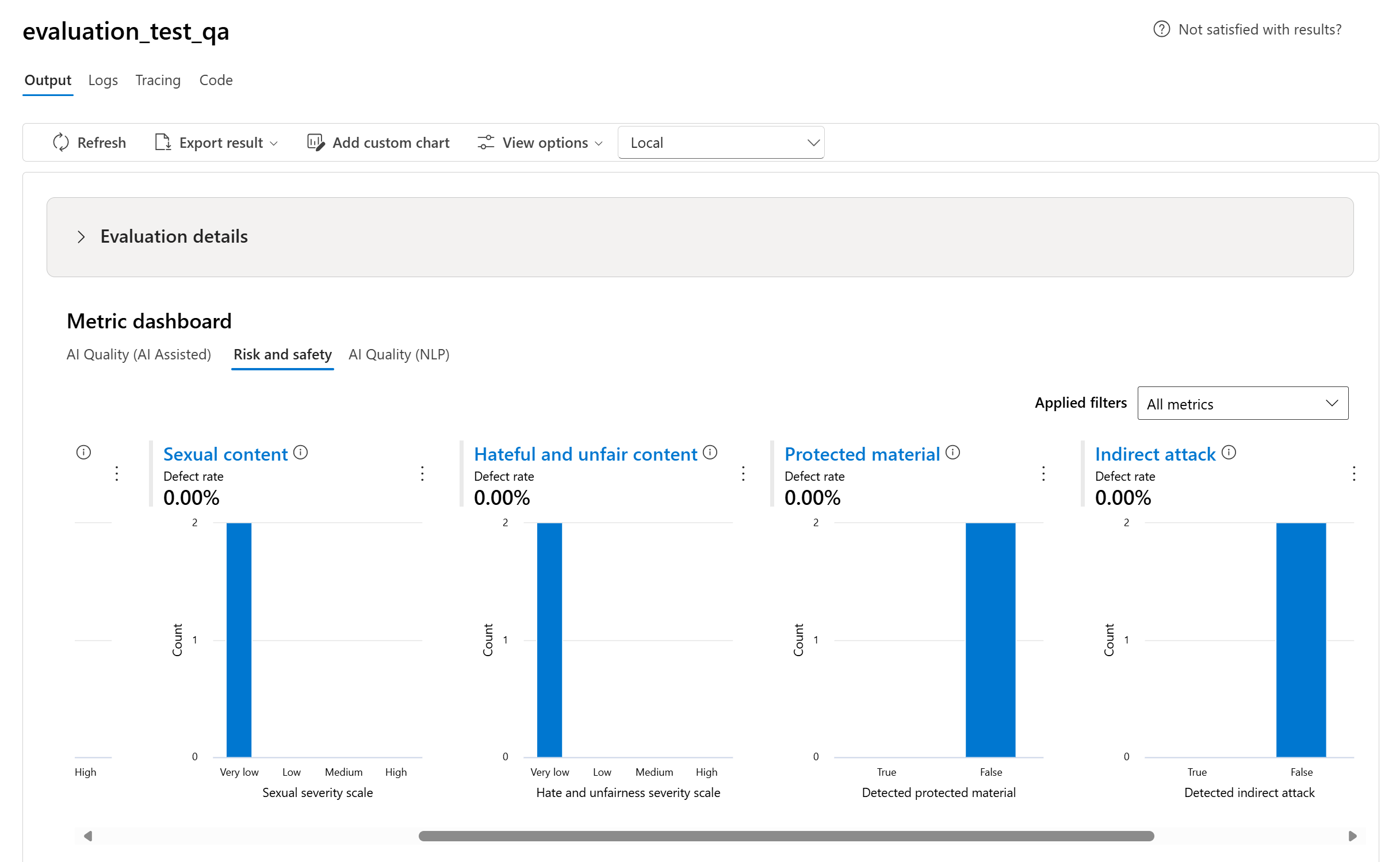
- リスクと安全性に関するメトリックについては、各メトリックの欠陥率を計算して集計します。
- コンテンツ危害メトリックの場合、欠陥率は、データセット全体のサイズに関する重大度スケールのしきい値を超えるテスト データセット内のインスタンスの割合として定義されています。 既定では、しきい値は "中" に設定されます。
- 保護されたマテリアルと間接攻撃の場合、欠陥率は、出力が "true" であるインスタンスの割合として計算されます (欠陥率 = (#trues/#instances) × 100)。
- AI 品質 (NLP) メトリックの場合、0 から 1 の間のメトリック分布のヒストグラムが表示されます。 各メトリックのすべてのスコアの平均を計算して集計します。
![[AI 品質 (NLP) ダッシュボード] タブのスクリーンショット。](../media/evaluations/view-results/ai-quality-nlp-chart.png)
- カスタム メトリックの場合は、[カスタム グラフの追加] を選択して、選択したメトリックを使用してカスタム グラフを作成したり、選択した入力パラメーターに対するメトリックを表示したりできます。
![[カスタム グラフの作成] ポップアップのスクリーンショット。](../media/evaluations/view-results/custom-chart-pop-up.png)
![[AI 品質 (AI 支援) メトリック ダッシュボード] タブのスクリーンショット。](../media/evaluations/view-results/ai-quality-ai-assisted-chart.png#lightbox)

![[AI 品質 (NLP) ダッシュボード] タブのスクリーンショット。](../media/evaluations/view-results/ai-quality-nlp-chart.png#lightbox)
![[カスタム グラフの作成] ポップアップのスクリーンショット。](../media/evaluations/view-results/custom-chart-pop-up.png#lightbox)
グラフの種類を変更して、組み込みのメトリックの既存のグラフをカスタマイズすることもできます。

詳細メトリックの結果テーブル
メトリックの詳細テーブルでは、個々のデータ サンプルを包括的に調べることができます。 ここでは、生成された出力とそれに対応する評価メトリック スコアを詳細に調べることができます。 この詳細レベルを使用すると、データドリブンの意思決定を行い、モデルのパフォーマンスを向上するための特定のアクションを実行したりすることができます。
評価メトリックに基づいて実行される可能性のあるアクション項目としては、次のようなものがあります。
- パターン認識: 数値とメトリックをフィルター処理して、スコアの低いサンプルをドリルダウンできます。 これらのサンプルを調査して、モデルの応答で繰り返し発生するパターンや問題を特定します。 たとえば、モデルで特定のトピックに関するコンテンツを生成するときにスコアが低くなる場合が多いことに気付く可能性があります。
- モデルの微調整: スコアの低いサンプルの分析情報を使用して、システム プロンプトの指示の改善や、モデルの微調整を行います。 一貫性や関連性などの一貫した問題が観察された場合、それに応じてモデルのトレーニング データやパラメーターを調整することもできます。
- 列のカスタマイズ: 列エディターを使用すると、評価目標に最も関連するメトリクスとデータに焦点を当てて、テーブルのカスタマイズされたビューを作成できます。 これにより、分析が効率化され、傾向をより効果的に特定できるようになります。
- キーワード検索: 検索ボックスを使用すると、生成された出力で特定の単語やフレーズを検索できます。 これは、特定のトピックやキーワードに関連する問題やパターンを特定し、それらに具体的に対処する場合に役立ちます。
メトリクスの詳細テーブルでは、パターンの認識から、効率的な分析のためのビューのカスタマイズ、特定された問題に基づいたモデルの微調整まで、モデルの改善作業をガイドできる豊富なデータが提供されます。
以下に、質問に対する回答シナリオのメトリック結果の例をいくつか示します。

また、会話シナリオのメトリック結果の例もいくつか示します。

マルチターン会話のシナリオでは、[View evaluation results per turn] (ターンごとの評価結果の表示) を選択して、会話内の各ターンの評価メトリックを確認できます。
![入力メッセージの [View evaluation results per turn] (ターンごとの評価結果の表示) リンクを示すスクリーンショット。](../media/evaluations/view-results/multi-turn-chat.png#lightbox)

マルチモーダル シナリオ (テキスト + 画像) での安全性評価の場合は、詳細なメトリックの結果テーブルの入力と出力の両方の画像を確認して、評価結果をより深く理解できます。 マルチモーダル評価は現在、会話シナリオでのみサポートされているため、[ターンごとの評価結果の表示] を選択して、各ターンの入力と出力を調べることができます。


画像を選択して展開し、表示します。 既定では、すべての画像はぼかして表示され、有害なコンテンツから保護されます。 画像をはっきりと表示するには、[ぼやけた画像を確認] トグルをオンにします。

リスクと安全性に関するメトリックについては、評価によって重大度スコアと各スコアの推論が提供されます。 以下に、質問応答シナリオのリスクと安全性に関するメトリック結果の例をいくつか示します。

評価結果は、異なる対象ユーザーに対して異なる意味を持つ場合があります。 たとえば、セーフティ評価で、重大度が "低" である暴力的コンテンツのラベルが生成される可能性があり、これが、この特定の暴力的コンテンツの重大度に関する人間のレビュー担当者の定義と一致しない場合があります。 評価結果をレビューするときに人間のフィードバック列にサムズアップとサムズダウンが用意されており、人間のレビュー担当者によってどのインスタンスが承認されたか不適切としてフラグ設定されたかが示されます。

各コンテンツ リスク メトリックを理解する場合、グラフの上にあるメトリック名を選択してポップアップに詳細な説明を表示することで、各メトリック定義と重大度スケールを簡単に表示できます。

実行に問題がある場合、ログを使用して評価実行をデバッグすることもできます。
以下に、評価実行に使用できるログの例をいくつか示します。

プロンプト フローを評価する場合は、[View in flow] (フローで表示) ボタンを選択し、評価されたフロー ページに移動してフローを更新できます。 たとえば、メタ プロンプトの指示を追加したり、いくつかのパラメーターを変更して再評価したりできます。
ビュー オプションを使用してビューを管理および共有する
[評価の詳細] ページでは、カスタム グラフを追加したり、列を編集したりして、ビューをカスタマイズできます。 カスタマイズすると、ビューを保存したり、ビュー オプションを使用して他のユーザーと共有したりできます。 これにより、好みに合わせて調整された形式で評価結果を確認でき、同僚との共同作業が容易になります。
![[表示オプション] ボタンのドロップダウンのスクリーンショット。](../media/evaluations/view-results/view-options-evaluation-details.png#lightbox)
評価結果を比較する
2 つ以上の実行間の包括的な比較を容易にするために、目的の実行を選択し、[比較] ボタンを選択するか、一般的な詳細なダッシュボード ビューの場合は [ダッシュボード ビューに切り替える] ボタンを選択してプロセスを開始することができます。 この機能により、複数の実行のパフォーマンスと結果を分析して比較し、より多くの情報に基づいて意思決定を行い、ターゲットを絞った改善を行うことができます。

ダッシュボード ビューでは、メトリック分散比較グラフと比較テーブルの 2 つの重要なコンポーネントにアクセスできます。 これらのツールを使用すると、選択した評価実行を並べて分析できるため、各データ サンプルのさまざまな側面を簡単かつ正確に比較できます。

比較テーブル内では、基準点として使用し、ベースラインとして設定する特定の実行の上にマウス ポインターを合わせると、比較のベースラインを確立できます。 さらに、[デルタの表示] トグルをアクティブにすると、ベースライン実行と他の実行の数値の差異を簡単に視覚化できます。 また、[差異のみを表示] トグルを有効にすると、選択した実行間で異なる行のみがテーブルに表示され、明確な変動の識別に役立ちます。
これらの比較機能を使用すると、情報に基づいた意思決定を行い、最適なバージョンを選択できます。
- ベースライン比較: ベースライン実行を設定すると、他の実行を比較する基準点を特定できます。 これにより、各実行が、選択した標準とどの程度逸脱しているかを確認できます。
- 数値評価: [デルタの表示] オプションを有効にすると、ベースラインと他の実行の差異の程度を把握するのに役立ちます。 これは、特定の評価メトリックに関して、さまざまな実行がどのように実行されるかを評価する場合に役立ちます。
- 差異の分離: [差異のみ表示] 機能を使用すると、実行間で一致しない領域のみが強調表示され、分析が効率化されます。 改善や調整が必要な領域を特定するのに役立ちます。
これらの比較ツールを効果的に使用すると、定義された基準やメトリックに関して最適に実行されるモデルまたはシステムのバージョンを特定でき、最終的に、アプリケーションに最適なオプションを選択するのに役立ちます。

ジェイルブレイクの脆弱性の測定
ジェイルブレイクの評価は、AI 支援メトリックではなく、比較測定です。 2 つの異なるレッドチーミングされたデータセットに対して評価を実行します。つまり、ベースラインの敵対的テスト データセットと、最初のターンにジェイルブレイク インジェクションがある同じ敵対的テスト データセットです。 敵対的データ シミュレーターを使用して、ジェイルブレイク インジェクションの有無にかかわらずデータセットを生成できます。
アプリケーションがジェイルブレイクに対して脆弱かどうかを理解するには、ベースラインを指定して、比較テーブルの [Jailbreak defect rates] (ジェイルブレイクの欠陥率) トグルをオンにします。 ジェイルブレイクの欠陥率は、ジェイルブレイク インジェクションにより、データセット全体のサイズに対するベースラインに関する任意のコンテンツ リスク メトリックに対してより高い重大度スコアが生成される、テスト データセット内のインスタンスの割合として定義されます。 比較ダッシュボードで複数の評価を選択して、欠陥率の差を表示できます。

ヒント
ジェイルブレイクの欠陥率は、同じサイズのデータセットに関してのみ、それらを比較することで計算され、また、すべての実行にコンテンツ リスクと安全性に関するメトリックが含まれている場合にのみ計算されます。
組み込みの評価メトリックを理解する
組み込みのメトリックについて理解することは、AI アプリケーションのパフォーマンスと有効性を評価するために不可欠です。 これらの主要な測定ツールに関する分析情報を取得すると、結果を解釈し、情報に基づいた意思決定を行い、アプリケーションを微調整して、最適な結果を達成する態勢が整います。 各メトリクスの重要性、その計算方法、モデルのさまざまな側面を評価する際の各メトリックの役割、データドリブンの改善を行うために結果を解釈する方法の詳細については、「評価および監視メトリック」を参照してください。
次のステップ
ご利用の生成 AI アプリケーションを評価する方法の詳細については、次をご参照ください。
損害の軽減手法についての詳細情報。