How to configure content filters
The content filtering system integrated into Azure AI Foundry runs alongside the core models, including DALL-E image generation models. It uses an ensemble of multi-class classification models to detect four categories of harmful content (violence, hate, sexual, and self-harm) at four severity levels respectively (safe, low, medium, and high), and optional binary classifiers for detecting jailbreak risk, existing text, and code in public repositories.
The default content filtering configuration is set to filter at the medium severity threshold for all four content harms categories for both prompts and completions. That means that content that is detected at severity level medium or high is filtered, while content detected at severity level low or safe is not filtered by the content filters. Learn more about content categories, severity levels, and the behavior of the content filtering system here.
Jailbreak risk detection and protected text and code models are optional and on by default. For jailbreak and protected material text and code models, the configurability feature allows all customers to turn the models on and off. The models are by default on and can be turned off per your scenario. Some models are required to be on for certain scenarios to retain coverage under the Customer Copyright Commitment.
Note
All customers have the ability to modify the content filters and configure the severity thresholds (low, medium, high). Approval is required for turning the content filters partially or fully off. Managed customers only may apply for full content filtering control via this form: Azure OpenAI Limited Access Review: Modified Content Filters. At this time, it is not possible to become a managed customer.
Content filters can be configured at the resource level. Once a new configuration is created, it can be associated with one or more deployments. For more information about model deployment, see the resource deployment guide.
Prerequisites
- You must have an Azure OpenAI resource and a large language model (LLM) deployment to configure content filters. Follow a quickstart to get started.
Understand content filter configurability
Azure OpenAI Service includes default safety settings applied to all models, excluding Azure OpenAI Whisper. These configurations provide you with a responsible experience by default, including content filtering models, blocklists, prompt transformation, content credentials, and others. Read more about it here.
All customers can also configure content filters and create custom safety policies that are tailored to their use case requirements. The configurability feature allows customers to adjust the settings, separately for prompts and completions, to filter content for each content category at different severity levels as described in the table below. Content detected at the 'safe' severity level is labeled in annotations but is not subject to filtering and isn't configurable.
| Severity filtered | Configurable for prompts | Configurable for completions | Descriptions |
|---|---|---|---|
| Low, medium, high | Yes | Yes | Strictest filtering configuration. Content detected at severity levels low, medium, and high is filtered. |
| Medium, high | Yes | Yes | Content detected at severity level low isn't filtered, content at medium and high is filtered. |
| High | Yes | Yes | Content detected at severity levels low and medium isn't filtered. Only content at severity level high is filtered. |
| No filters | If approved1 | If approved1 | No content is filtered regardless of severity level detected. Requires approval1. |
| Annotate only | If approved1 | If approved1 | Disables the filter functionality, so content will not be blocked, but annotations are returned via API response. Requires approval1. |
1 For Azure OpenAI models, only customers who have been approved for modified content filtering have full content filtering control and can turn off content filters. Apply for modified content filters via this form: Azure OpenAI Limited Access Review: Modified Content Filters. For Azure Government customers, apply for modified content filters via this form: Azure Government - Request Modified Content Filtering for Azure OpenAI Service.
Configurable content filters for inputs (prompts) and outputs (completions) are available for all Azure OpenAI models.
Content filtering configurations are created within a Resource in Azure AI Foundry portal, and can be associated with Deployments. Learn more about configurability here.
Customers are responsible for ensuring that applications integrating Azure OpenAI comply with the Code of Conduct.
Understand other filters
You can configure the following filter categories in addition to the default harm category filters.
| Filter category | Status | Default setting | Applied to prompt or completion? | Description |
|---|---|---|---|---|
| Prompt Shields for direct attacks (jailbreak) | GA | On | User prompt | Filters / annotates user prompts that might present a Jailbreak Risk. For more information about annotations, visit Azure AI Foundry content filtering. |
| Prompt Shields for indirect attacks | GA | Off | User prompt | Filter / annotate Indirect Attacks, also referred to as Indirect Prompt Attacks or Cross-Domain Prompt Injection Attacks, a potential vulnerability where third parties place malicious instructions inside of documents that the generative AI system can access and process. Requires: Document embedding and formatting. |
| Protected material - code | GA | On | Completion | Filters protected code or gets the example citation and license information in annotations for code snippets that match any public code sources, powered by GitHub Copilot. For more information about consuming annotations, see the content filtering concepts guide |
| Protected material - text | GA | On | Completion | Identifies and blocks known text content from being displayed in the model output (for example, song lyrics, recipes, and selected web content). |
| Groundedness | Preview | Off | Completion | Detects whether the text responses of large language models (LLMs) are grounded in the source materials provided by the users. Ungroundedness refers to instances where the LLMs produce information that is non-factual or inaccurate from what was present in the source materials. Requires: Document embedding and formatting. |
Create a content filter in Azure AI Foundry
For any model deployment in Azure AI Foundry, you can directly use the default content filter, but you might want to have more control. For example, you could make a filter stricter or more lenient, or enable more advanced capabilities like prompt shields and protected material detection.
Tip
For guidance with content filters in your Azure AI Foundry project, you can read more at Azure AI Foundry content filtering.
Follow these steps to create a content filter:
Go to Azure AI Foundry and navigate to your project. Then select the Safety + security page from the left menu and select the Content filters tab.

Select + Create content filter.
On the Basic information page, enter a name for your content filtering configuration. Select a connection to associate with the content filter. Then select Next.
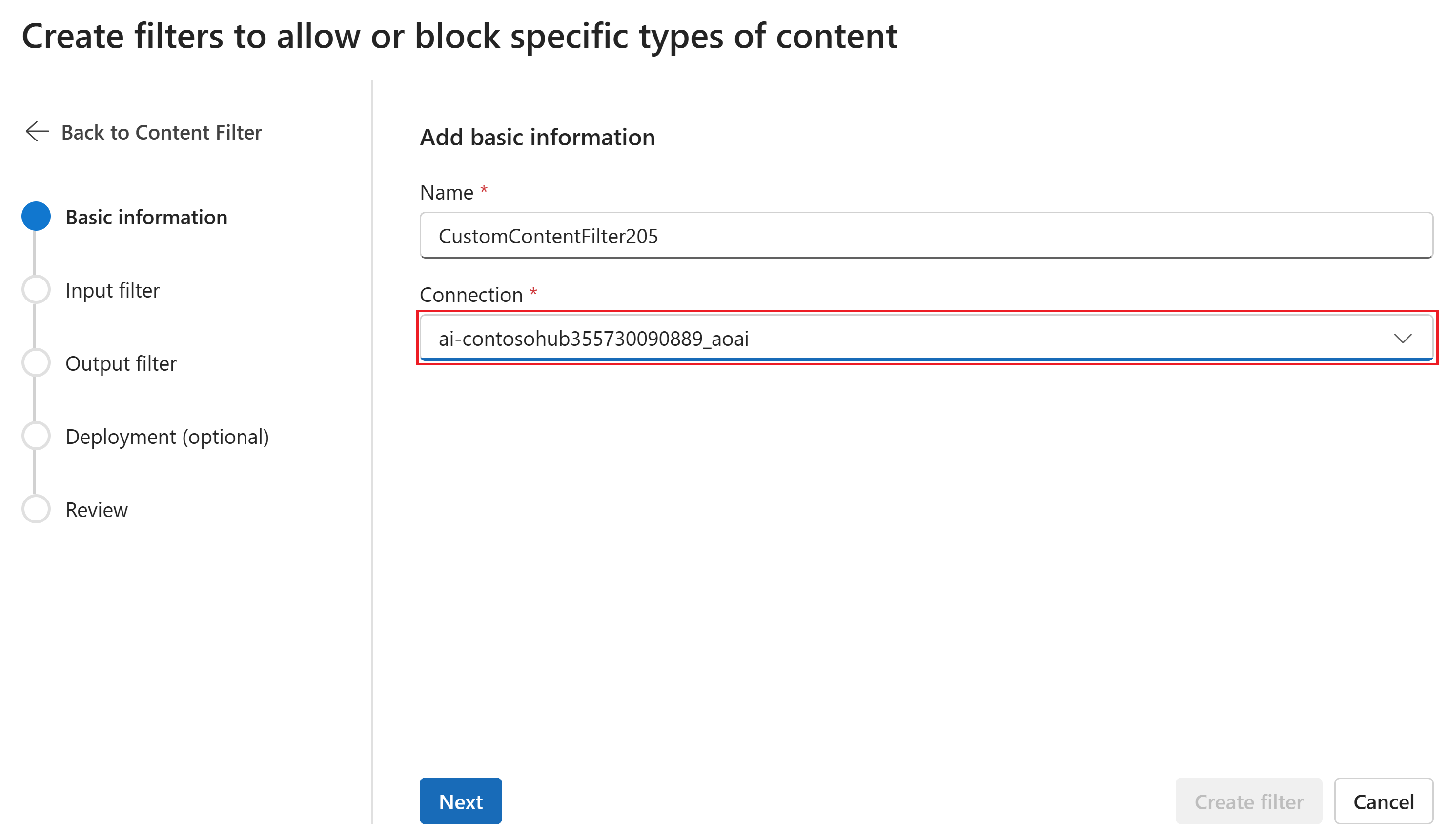
Now you can configure the input filters (for user prompts) and output filters (for model completion).
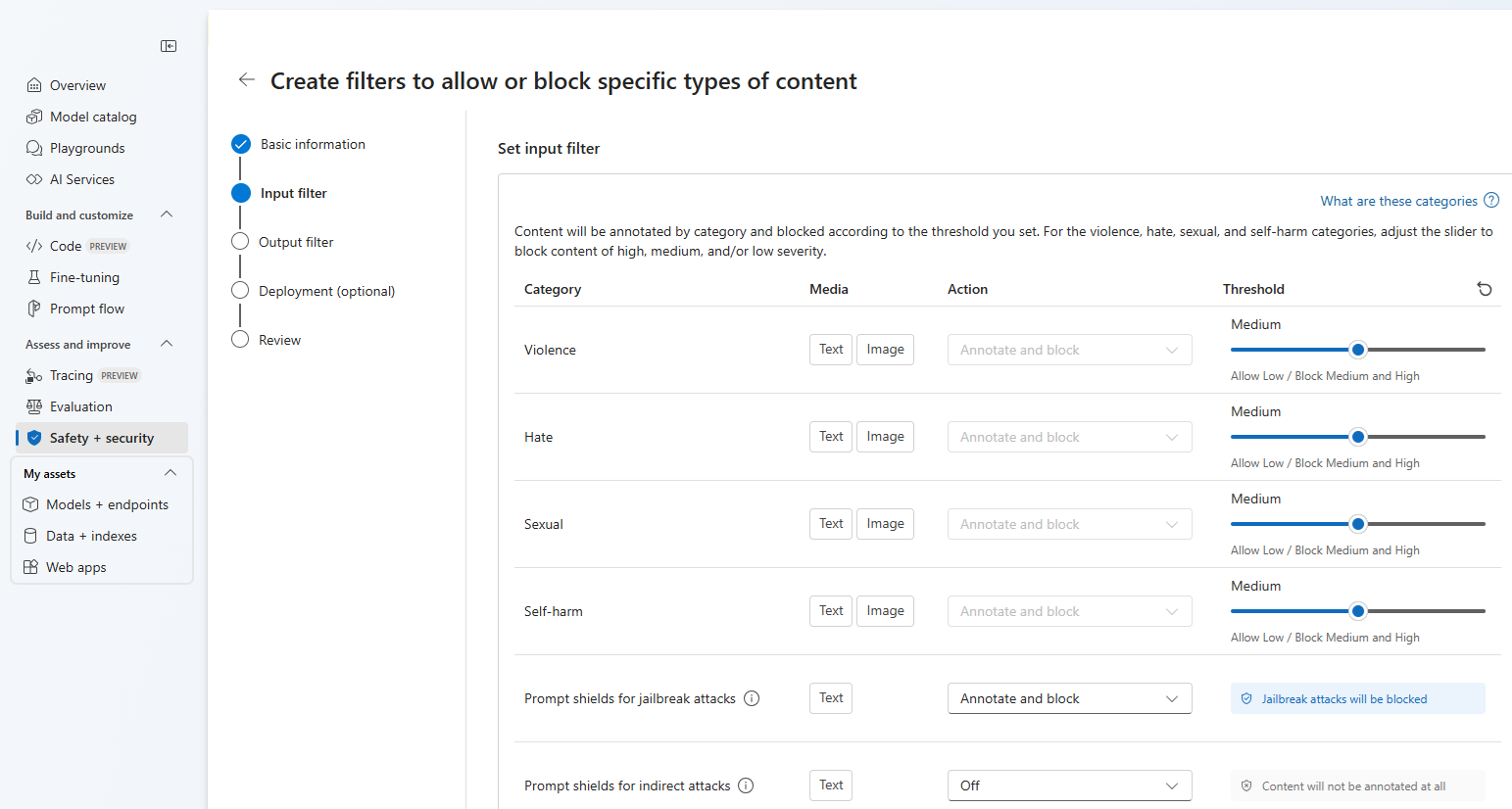
On the Input filters page, you can set the filter for the input prompt. For the first four content categories there are three severity levels that are configurable: Low, medium, and high. You can use the sliders to set the severity threshold if you determine that your application or usage scenario requires different filtering than the default values. Some filters, such as Prompt Shields and Protected material detection, enable you to determine if the model should annotate and/or block content. Selecting Annotate only runs the respective model and return annotations via API response, but it will not filter content. In addition to annotate, you can also choose to block content.
If your use case was approved for modified content filters, you receive full control over content filtering configurations and can choose to turn filtering partially or fully off, or enable annotate only for the content harms categories (violence, hate, sexual and self-harm).
Content will be annotated by category and blocked according to the threshold you set. For the violence, hate, sexual, and self-harm categories, adjust the slider to block content of high, medium, or low severity.
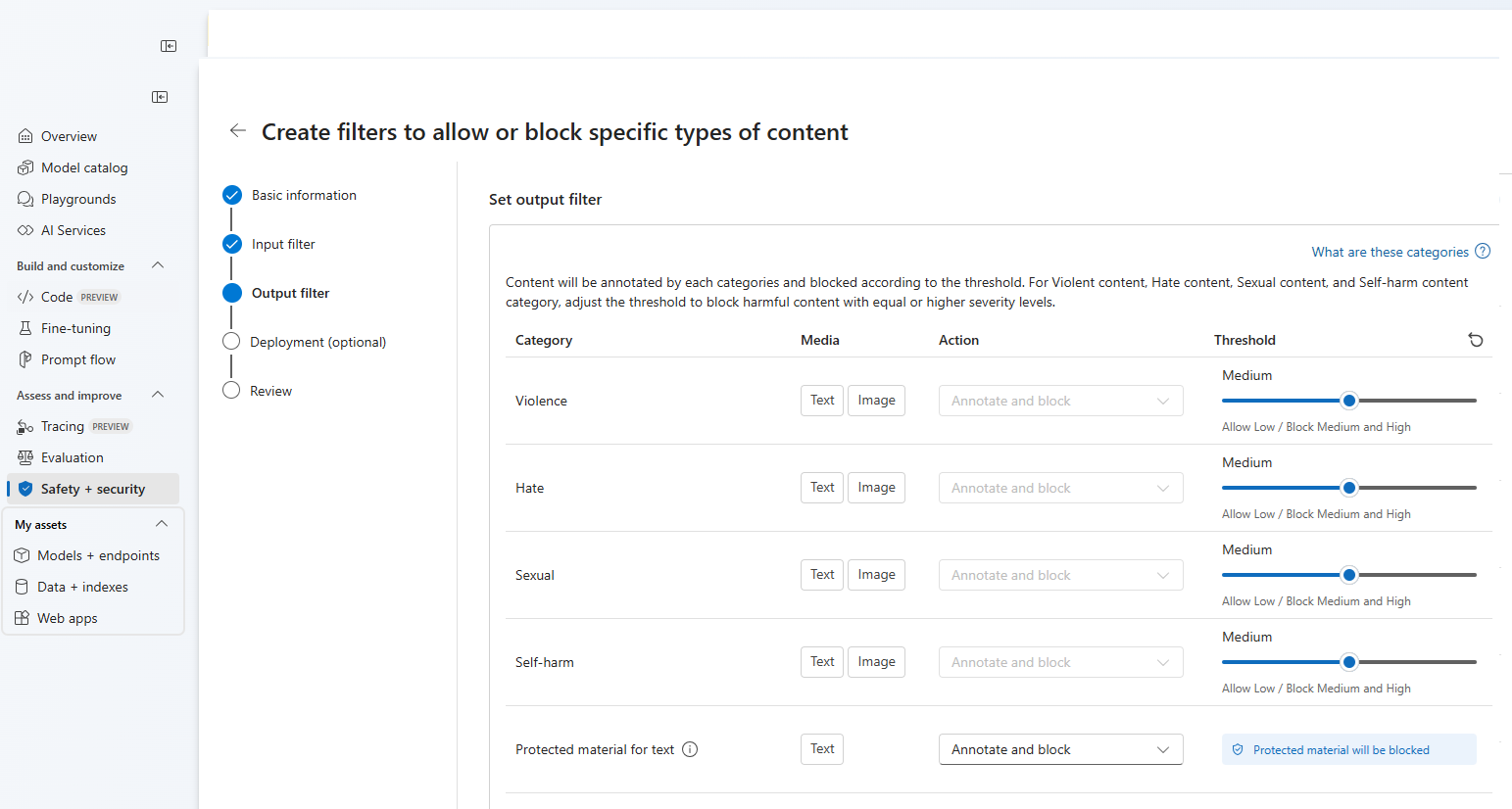
On the Output filters page, you can configure the output filter, which will be applied to all output content generated by your model. Configure the individual filters as before. This page also provides the Streaming mode option, which lets you filter content in near-real-time as it's generated by the model, reducing latency. When you're finished select Next.
Content will be annotated by each category and blocked according to the threshold. For violent content, hate content, sexual content, and self-harm content category, adjust the threshold to block harmful content with equal or higher severity levels.
Optionally, on the Deployment page, you can associate the content filter with a deployment. If a selected deployment already has a filter attached, you must confirm that you want to replace it. You can also associate the content filter with a deployment later. Select Create.
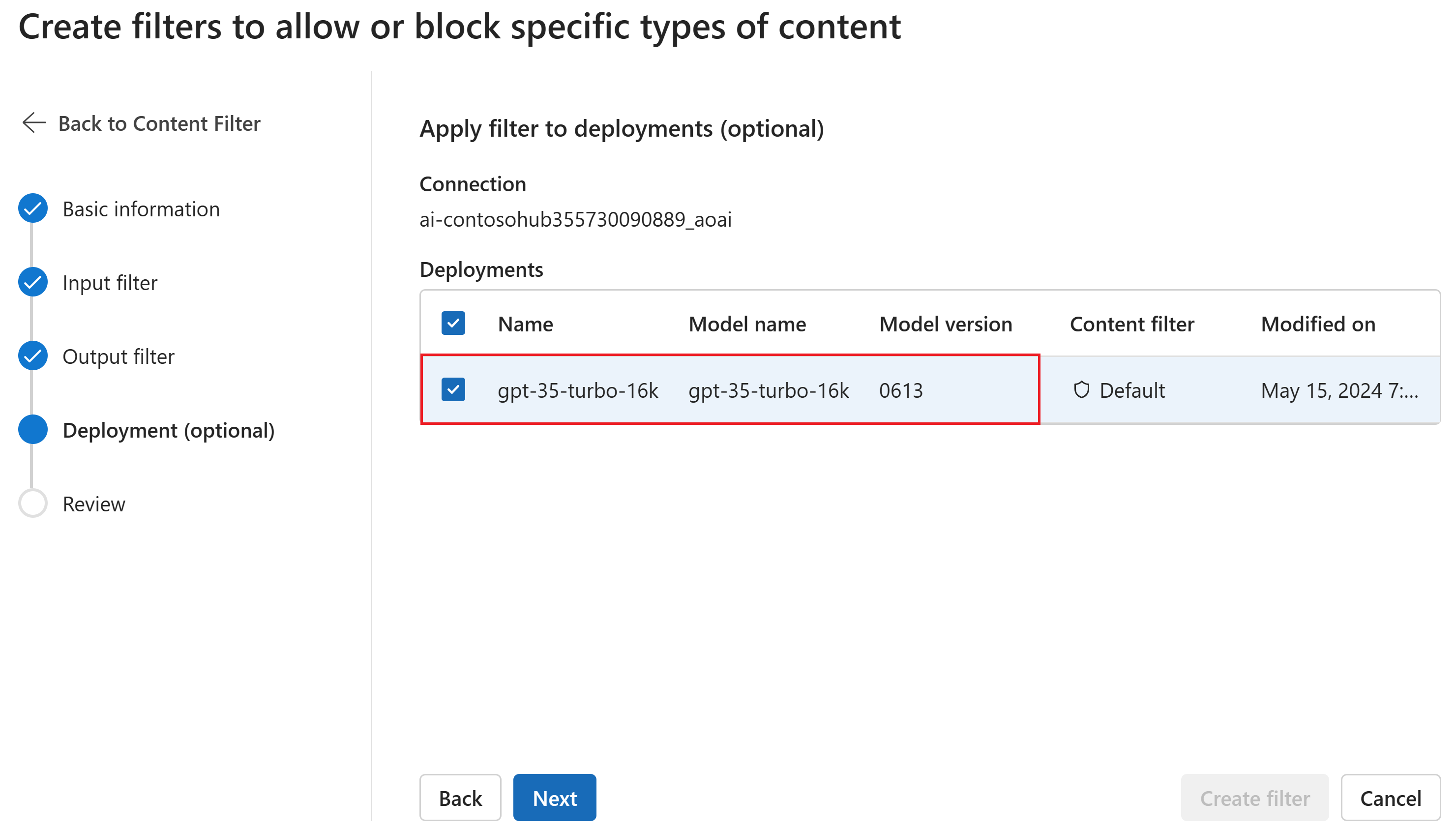
Content filtering configurations are created at the hub level in the Azure AI Foundry portal. Learn more about configurability in the Azure OpenAI Service documentation.
On the Review page, review the settings and then select Create filter.



Use a blocklist as a filter
You can apply a blocklist as either an input or output filter, or both. Enable the Blocklist option on the Input filter and/or Output filter page. Select one or more blocklists from the dropdown, or use the built-in profanity blocklist. You can combine multiple blocklists into the same filter.
Apply a content filter
The filter creation process gives you the option to apply the filter to the deployments you want. You can also change or remove content filters from your deployments at any time.
Follow these steps to apply a content filter to a deployment:
Go to Azure AI Foundry and select a project.
Select Models + endpoints on the left pane and choose one of your deployments, then select Edit.
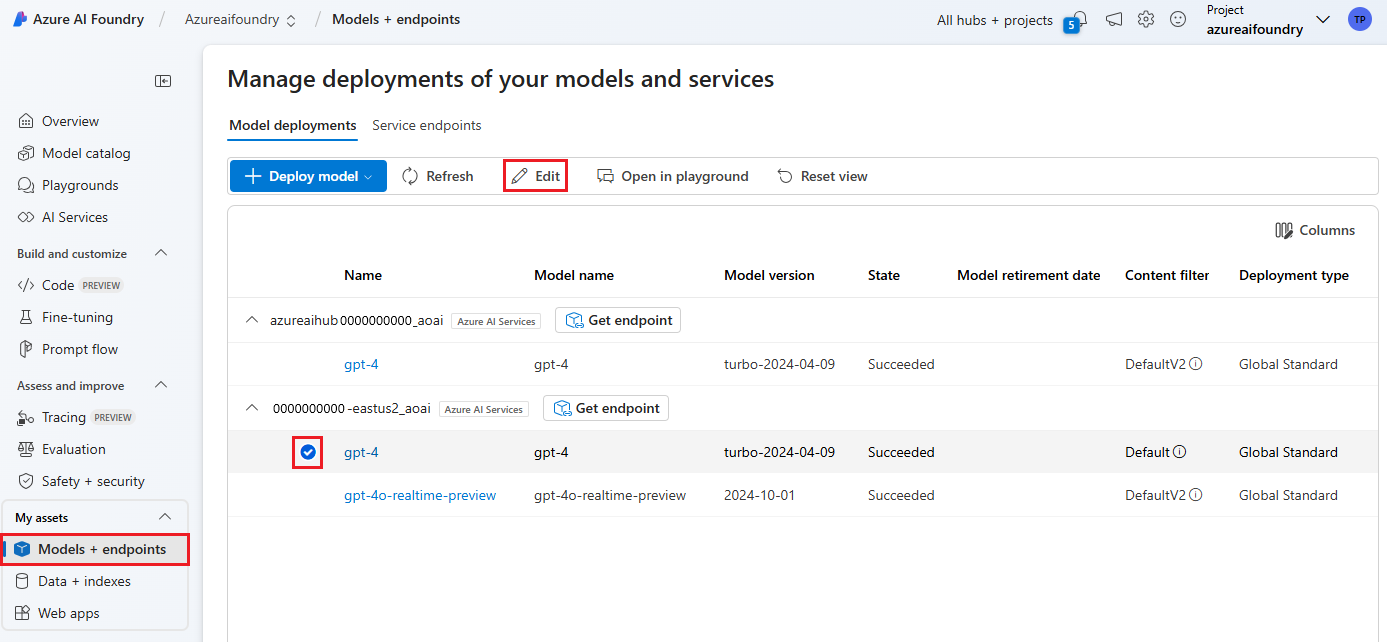
In the Update deployment window, select the content filter you want to apply to the deployment. Then select Save and close.
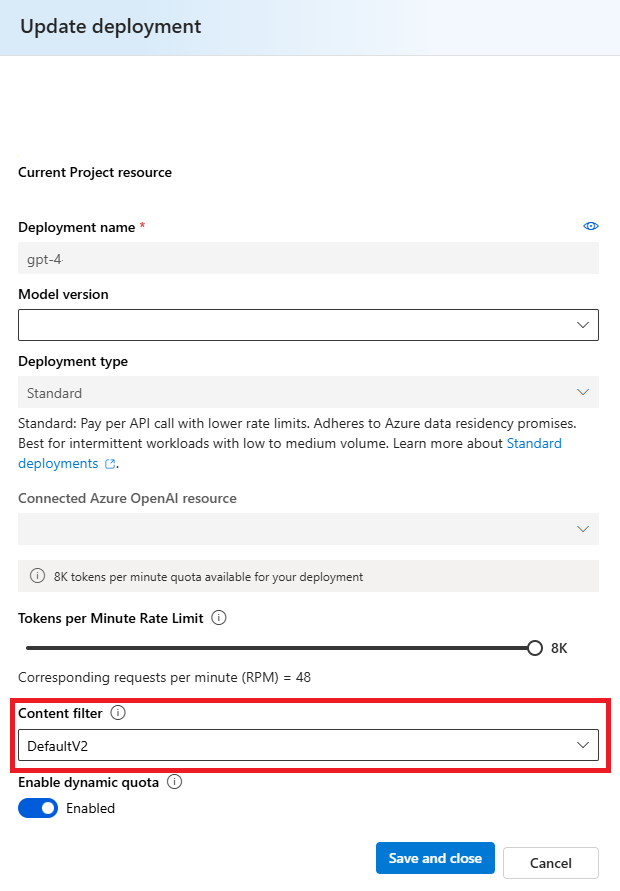
You can also edit and delete a content filter configuration if required. Before you delete a content filtering configuration, you will need to unassign and replace it from any deployment in the Deployments tab.


Now, you can go to the playground to test whether the content filter works as expected.
Tip
You can also create and update content filters using the REST APIs. For more information, see the API reference. Content filters can be configured at the resource level. Once a new configuration is created, it can be associated with one or more deployments. For more information about model deployment, see the resource deployment guide.
Specify a content filtering configuration at request time (preview)
In addition to the deployment-level content filtering configuration, we also provide a request header that allows you specify your custom configuration at request time for every API call.
curl --request POST \
--url 'URL' \
--header 'Content-Type: application/json' \
--header 'api-key: API_KEY' \
--header 'x-policy-id: CUSTOM_CONTENT_FILTER_NAME' \
--data '{
"messages": [
{
"role": "system",
"content": "You are a creative assistant."
},
{
"role": "user",
"content": "Write a poem about the beauty of nature."
}
]
}'
The request-level content filtering configuration will override the deployment-level configuration, for the specific API call. If a configuration is specified that does not exist, the following error message will be returned.
{
"error":
{
"code": "InvalidContentFilterPolicy",
"message": "Your request contains invalid content filter policy. Please provide a valid policy."
}
}
Report content filtering feedback
If you are encountering a content filtering issue, select the Filters Feedback button at the top of the playground. This is enabled in the Images, Chat, and Completions playground once you submit a prompt.
When the dialog appears, select the appropriate content filtering issue. Include as much detail as possible relating to your content filtering issue, such as the specific prompt and content filtering error you encountered. Do not include any private or sensitive information.
For support, please submit a support ticket.
Follow best practices
We recommend informing your content filtering configuration decisions through an iterative identification (for example, red team testing, stress-testing, and analysis) and measurement process to address the potential harms that are relevant for a specific model, application, and deployment scenario. After you implement mitigations such as content filtering, repeat measurement to test effectiveness. Recommendations and best practices for Responsible AI for Azure OpenAI, grounded in the Microsoft Responsible AI Standard can be found in the Responsible AI Overview for Azure OpenAI.
Related content
- Learn more about Responsible AI practices for Azure OpenAI: Overview of Responsible AI practices for Azure OpenAI models.
- Read more about content filtering categories and severity levels with Azure AI Foundry.
- Learn more about red teaming from our: Introduction to red teaming large language models (LLMs) article.
- Learn how to configure content filters using the API