クイック スタート: 会話言語理解を使用して意図を認識する
リファレンス ドキュメント | パッケージ (NuGet) | GitHub のその他のサンプル
このクイックスタートでは、Speech および Language サービスを使用して、マイクでキャプチャされたオーディオ データから意図を認識します。 具体的には、Speech サービスを使用して音声を認識し、会話言語理解 (CLU) モデルを使用して意図を識別します。
重要
会話言語理解 (CLU) は、Speech SDK バージョン 1.25 以降の C# と C++ で使用できます。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure portal で言語リソースを作成します。
- Language リソース キーとエンドポイントを取得します。 言語リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
Speech SDK は NuGet パッケージとして提供されていて、.NET Standard 2.0 が実装されています。 Azure Cognitive Service for Speech SDK は、このガイドで後でインストールしますが、まず、これ以上要件がないか SDK のインストール ガイドを確認してください。
環境変数の設定
この例では、LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY、SPEECH_REGION という名前の環境変数が必要です。
Azure AI サービス リソースにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を保存する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。
LANGUAGE_KEY環境変数を設定するには、your-language-keyをリソースのキーの 1 つに置き換えます。LANGUAGE_ENDPOINT環境変数を設定するには、your-language-endpointをリソースのリージョンの 1 つに置き換えます。SPEECH_KEY環境変数を設定するには、your-speech-keyをリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-speech-regionをリソースのリージョンの 1 つに置き換えます。
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Note
現在実行中のコンソール内の環境変数にのみアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、環境変数の読み取りを必要とする実行中のプログラム (コンソール ウィンドウを含む) については、再起動が必要となる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
会話言語理解プロジェクトを作成する
言語リソースを作成したら、Language Studio で会話言語理解プロジェクトを作成します。 プロジェクトは、データに基づいてカスタム ML モデルを構築するための作業領域です。 ご自分のプロジェクトにアクセスできるのは、本人と、使用されている言語リソースへのアクセス権を持つ方のみです。
Language Studio にアクセスし、Azure アカウントでサインインします。
会話言語理解プロジェクトを作成する
このクイックスタートでは、このサンプルのホーム オートメーション プロジェクトをダウンロードしてインポートできます。 このプロジェクトでは、電灯のオンとオフの切り替えなど、ユーザー入力から目的のコマンドを予測できます。
Language Studio で、[Understand questions and conversational language](質問と会話言語を理解する) セクションで、[会話言語理解] を選びます。
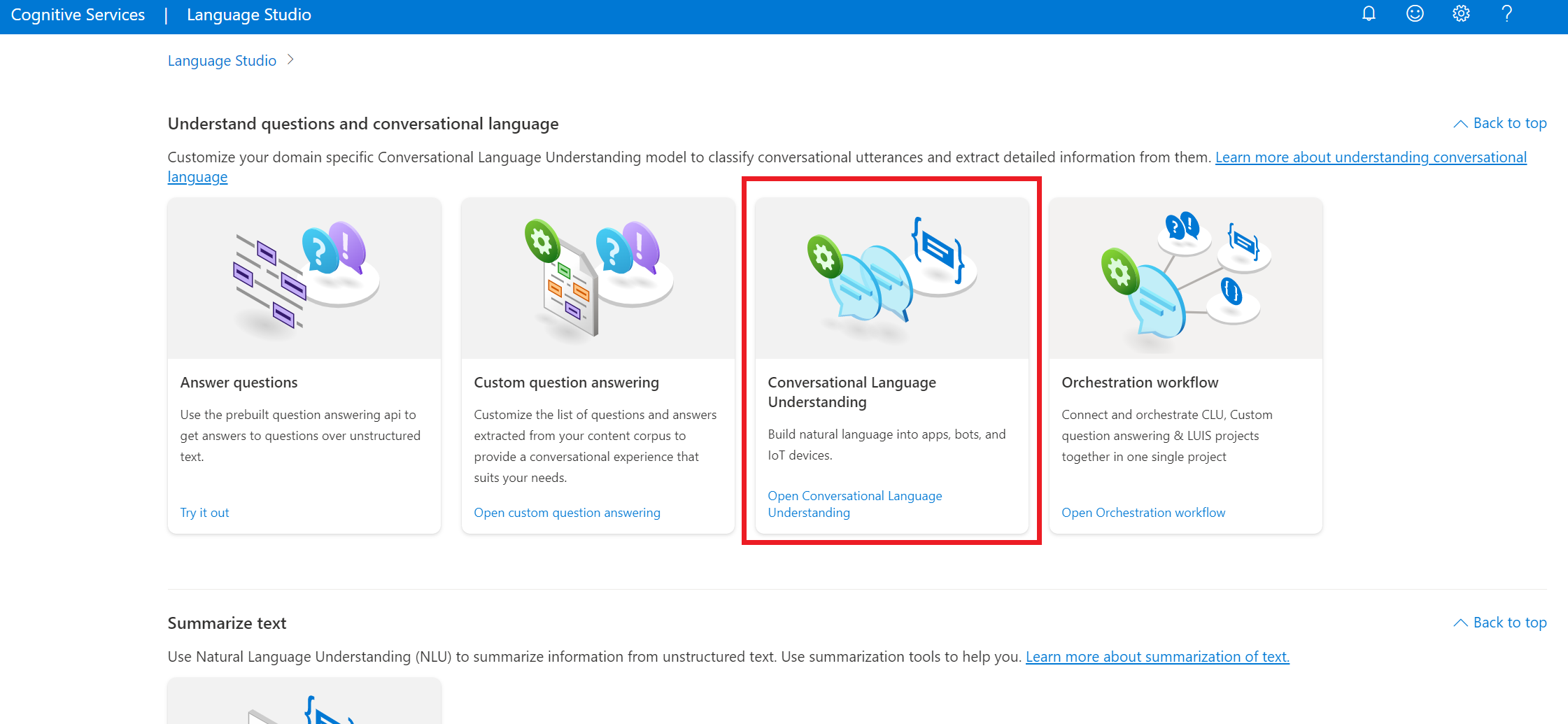
これにより、[会話言語理解プロジェクト] ページが表示されます。 [新しいプロジェクトの作成] ボタンの横で、[インポート] を選択します。
![Language Studio の [Conversations project]\(会話プロジェクト\) ページのスクリーンショット。](../language-service/conversational-language-understanding/media/projects-page.png)
表示されたウィンドウで、インポートする JSON ファイルをアップロードします。 ファイルが サポートされている JSON 形式に従っていることを確認します。

![Language Studio の [Conversations project]\(会話プロジェクト\) ページのスクリーンショット。](../language-service/conversational-language-understanding/media/projects-page.png#lightbox)
アップロードが完了すると、[Schema definition] (スキーマ定義) ページに移動します。 このクイックスタートでは、スキーマが既にビルドされており、発話には既に意図とエンティティのラベルが付けられています。
モデルをトレーニングする
通常は、プロジェクトを作成した後、スキーマをビルドし、発話にラベルを付ける必要があります。 このクイックスタートでは、準備が完了したプロジェクトが既にインポートされており、スキーマはビルドされ、発話にはラベルが付けられています。
モデルをトレーニングするには、トレーニング ジョブを開始する必要があります。 成功したトレーニング ジョブの出力は、トレーニング済みのモデルです。
Language Studio 内からモデルのトレーニングを開始するには:
左側のメニューから [モデルのトレーニング] を選択します。
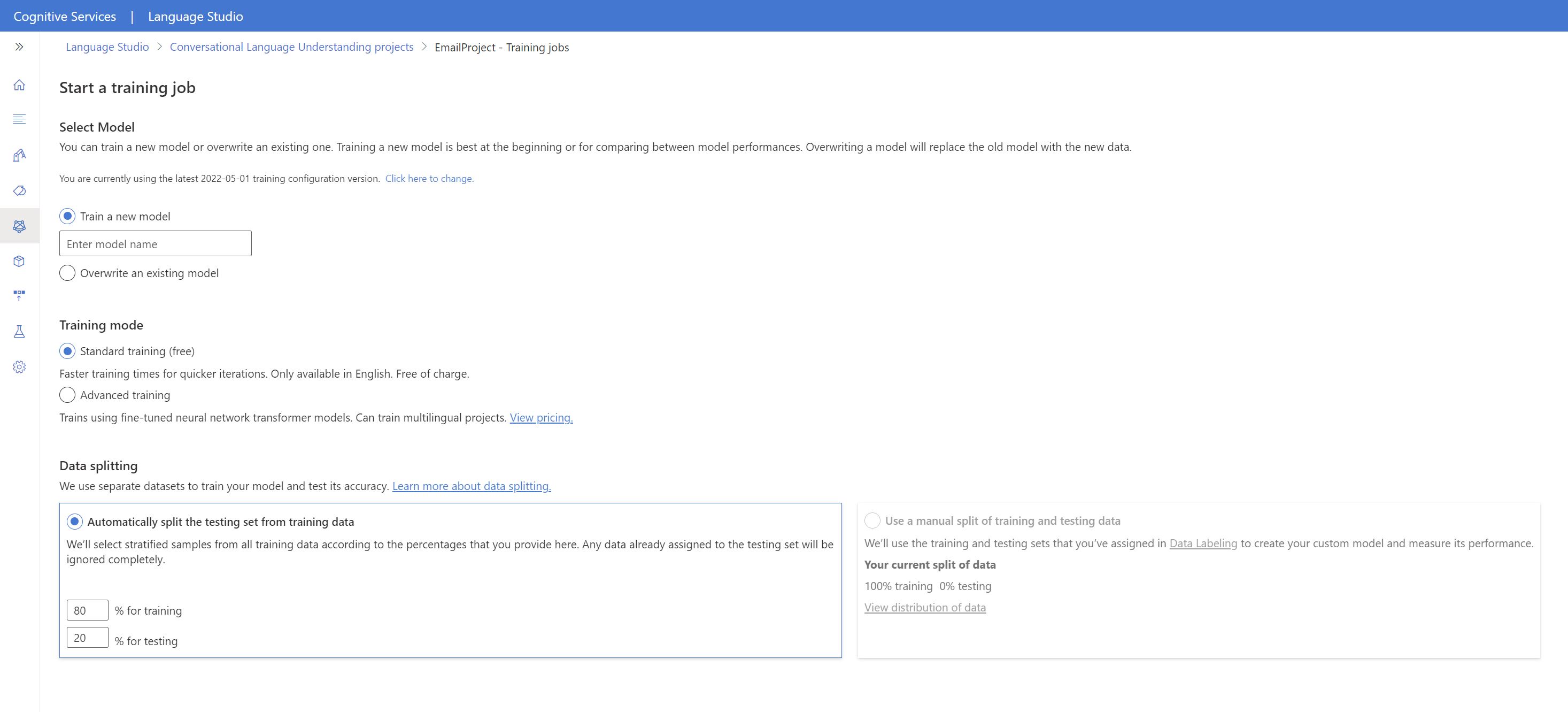
上部のメニューから [Start a training job] (トレーニング ジョブの開始) を選択します。
[新しいモデルのトレーニング] を選択し、テキスト ボックスに新しいモデル名を入力します。 それ以外の場合、既存のモデルを新しいデータでトレーニングされたモデルに置き換えるには、[既存のモデルを上書きする](Overwrite an existing model) を選択し、既存のモデルを選択します。 トレーニング済みモデルを上書きすると、元に戻すことはできません。ただし、新しいモデルをデプロイするまで、デプロイされているモデルには影響しません。
トレーニング モードを選択します。 [標準トレーニング] を選択すると、高速でトレーニングできますが、これを使用できるのは英語に限られます。 または、[高度なトレーニング] を選択できます。これは、他の言語や多言語プロジェクトでもサポートされていますが、トレーニング時間が長くなります。 トレーニング モードの詳細を参照してください。
[データ分割] 方法を選択します。 [トレーニング用データからテスト用セットを自動分割] を選択できます。その場合、システムにより、指定した割合に従って、発話がトレーニング用セットとテスト用セットに分割されます。 または、[トレーニング用データとテスト用データの手動分割を使用] を選択することもできます。このオプションは、発話にラベルを付ける際に発話をテスト用セットに追加した場合にのみ有効になります。
[トレーニング] ボタンを選択します。
リストからトレーニング ジョブ ID を選択します。 ウィンドウが表示され、そのジョブのトレーニングの進行状況、ジョブの状態、その他の詳細を確認できます。
注意
- 正常に完了したトレーニング ジョブでのみ、モデルが生成されます。
- トレーニングは、発話数に応じて、数分から数時間かかる場合があります。
- 一度に実行できるトレーニング ジョブは 1 つだけです。 実行中のジョブが完了しない限り、同じプロジェクト内で他のトレーニング ジョブを開始することはできません。
- モデルのトレーニングに使用される機械学習は定期的に更新されます。 以前の構成バージョンでトレーニングするには、[トレーニング ジョブの開始] ページから [変更するには、ここを選択してください] を選択し、以前のバージョンを選択します。

モデルをデプロイする
通常はモデルをトレーニングした後、その評価の詳細を確認します。 このクイックスタートでは、モデルをデプロイして Language Studio で試せるようにするところまで行いますが、予測 API を呼び出すこともできます。
Language Studio 内からモデルのデプロイを開始するには、次の手順を行います。
左側のメニューから [Deploying a model](モデルのデプロイ) を選びます。
[デプロイの追加] を選択して、[デプロイの追加] ウィザードを開始します。

[新しいデプロイ名を作成する] を選択して新しいデプロイを作成し、下のドロップダウンからトレーニング済みのモデルを割り当てます。 それ以外の場合は、[Overwrite an existing deployment name] (既存のデプロイ名を上書きする) を選択して、既存のデプロイで使用されているモデルを効果的に置き換えることができます。
注意
既存のデプロイを上書きしても、Prediction API の呼び出しを変更する必要はありませんが、その結果は、新しく割り当てたモデルに基づくものになります。
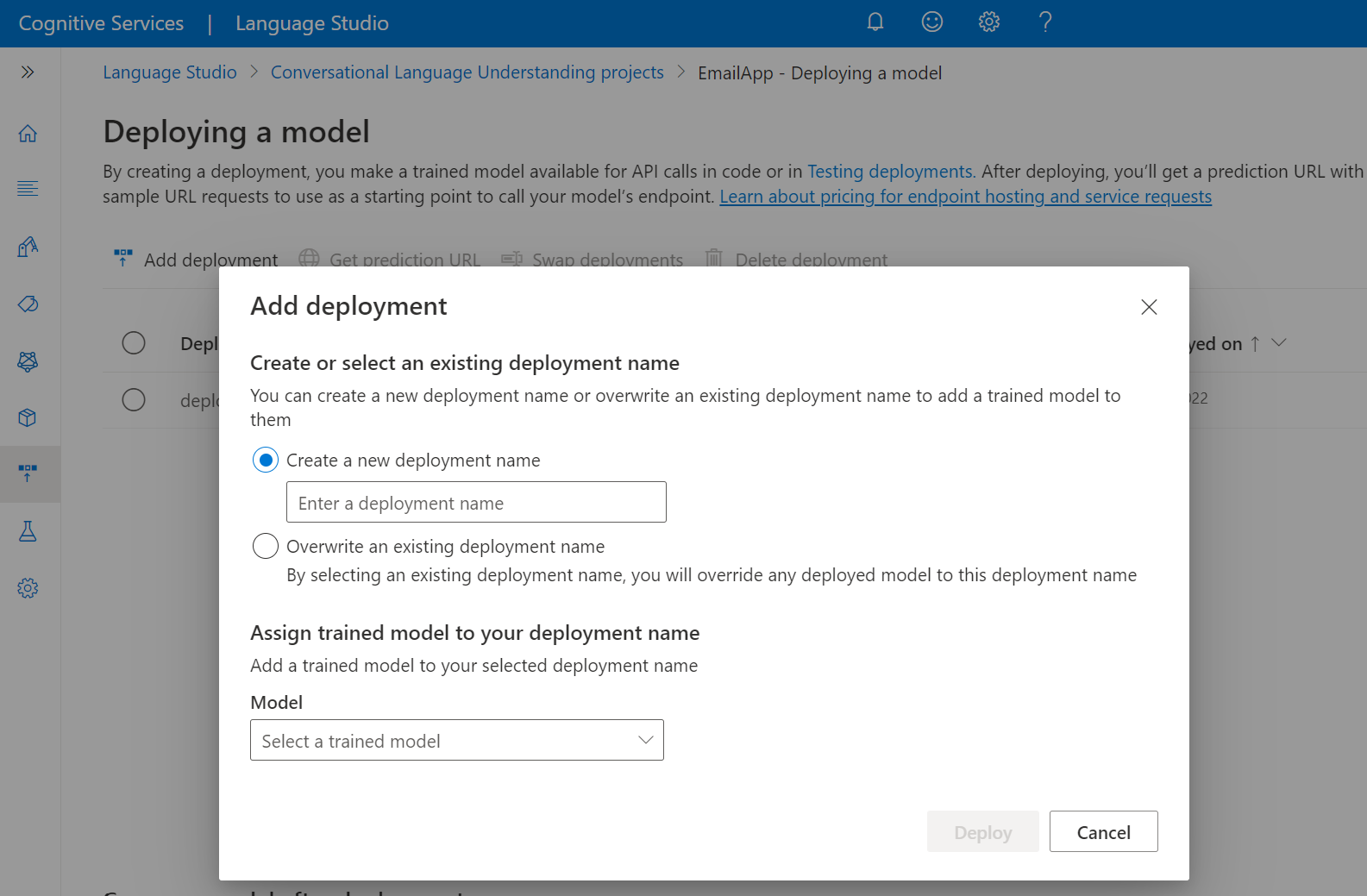
[モデル] ドロップダウンからトレーニング済みのモデルを選択します。
[デプロイ] を選択して、デプロイ ジョブを開始します。
デプロイが成功すると、その横に有効期限が表示されます。 デプロイの有効期限は、デプロイされたモデルを予測に使用できなくなるときで、通常、トレーニング構成の有効期限が切れる 12 か月後に発生します。


次のセクションで、このプロジェクト名とデプロイ名を使用します。
マイクから意図を認識する
以下の手順に従って新しいコンソール アプリケーションを作成し、Speech SDK をインストールします。
新しいプロジェクトを作成するコマンド プロンプトを開き、.NET CLI を使用してコンソール アプリケーションを作成します。
Program.csファイルは、プロジェクト ディレクトリに作成する必要があります。dotnet new console.NET CLI を使用して、新しいプロジェクトに Speech SDK をインストールします。
dotnet add package Microsoft.CognitiveServices.SpeechProgram.csの内容を以下のコードに置き換えます。using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }Program.csで、cluProjectNameとcluDeploymentName変数をプロジェクトとデプロイの名前に設定します。 CLU プロジェクトとデプロイを作成する方法については、「会話言語理解プロジェクトを作成する」を参照してください。音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合は、es-ESを作成します。 言語を指定しない場合、既定の言語はen-USです。 話される可能性のある複数の言語の 1 つを識別する方法の詳細については、言語の識別に関するページを参照してください。
新しいコンソール アプリケーションを実行して、マイクからの音声認識を開始します。
dotnet run
重要
上記の説明に従って、LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY、SPEECH_REGION 環境変数を設定してください。 これらの変数を設定しない場合、サンプルはエラー メッセージが表示されて失敗します。
指示されたらマイクに向って話します。 話すことがテキストとして出力される必要があります。
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
注意
LanguageUnderstandingServiceResponse_JsonResult プロパティを使用した CLU の JSON 応答のサポートは、Speech SDK バージョン 1.26 で追加されました。
意図は可能性の高いものから低いものの順に返されます。 topIntent が HomeAutomation.TurnOn で、信頼度スコアが 0.97712576 (97.71%) である JSON 出力の書式設定されたバージョンを次に示します。 2 番目に可能性の高い意図は信頼度スコアが 0.8985081 (89.85%) のHomeAutomation.TurnOff である可能性があります。
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
解説
クイックスタートを完了したので、次にいくつか追加の考慮事項を示します。
- この例では、
RecognizeOnceAsync操作を使用して、最大 30 秒間、または無音が検出されるまでの発話を文字起こししています。 多言語での会話を含め、より長いオーディオの継続的認識については、「音声を認識する方法」を参照してください。 - オーディオ ファイルから音声を認識するには、
FromDefaultMicrophoneInputの代わりにFromWavFileInputを使用します。using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - MP4 などの圧縮されたオーディオ ファイルの場合は、GStreamer をインストールして、
PullAudioInputStreamまたはPushAudioInputStreamを使います。 詳しくは、「圧縮された入力オーディオを使用する方法」をご覧ください。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した Language および Speech リソースを削除できます。
リファレンス ドキュメント | パッケージ (NuGet) | GitHub のその他のサンプル
このクイックスタートでは、Speech および Language サービスを使用して、マイクでキャプチャされたオーディオ データから意図を認識します。 具体的には、Speech サービスを使用して音声を認識し、会話言語理解 (CLU) モデルを使用して意図を識別します。
重要
会話言語理解 (CLU) は、Speech SDK バージョン 1.25 以降の C# と C++ で使用できます。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure portal で言語リソースを作成します。
- Language リソース キーとエンドポイントを取得します。 言語リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
Speech SDK は NuGet パッケージとして提供されていて、.NET Standard 2.0 が実装されています。 Azure Cognitive Service for Speech SDK は、このガイドで後でインストールしますが、まず、これ以上要件がないか SDK のインストール ガイドを確認してください。
環境変数の設定
この例では、LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY、SPEECH_REGION という名前の環境変数が必要です。
Azure AI サービス リソースにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を保存する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。
LANGUAGE_KEY環境変数を設定するには、your-language-keyをリソースのキーの 1 つに置き換えます。LANGUAGE_ENDPOINT環境変数を設定するには、your-language-endpointをリソースのリージョンの 1 つに置き換えます。SPEECH_KEY環境変数を設定するには、your-speech-keyをリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-speech-regionをリソースのリージョンの 1 つに置き換えます。
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Note
現在実行中のコンソール内の環境変数にのみアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、環境変数の読み取りを必要とする実行中のプログラム (コンソール ウィンドウを含む) については、再起動が必要となる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
会話言語理解プロジェクトを作成する
言語リソースを作成したら、Language Studio で会話言語理解プロジェクトを作成します。 プロジェクトは、データに基づいてカスタム ML モデルを構築するための作業領域です。 ご自分のプロジェクトにアクセスできるのは、本人と、使用されている言語リソースへのアクセス権を持つ方のみです。
Language Studio にアクセスし、Azure アカウントでサインインします。
会話言語理解プロジェクトを作成する
このクイックスタートでは、このサンプルのホーム オートメーション プロジェクトをダウンロードしてインポートできます。 このプロジェクトでは、電灯のオンとオフの切り替えなど、ユーザー入力から目的のコマンドを予測できます。
Language Studio で、[Understand questions and conversational language](質問と会話言語を理解する) セクションで、[会話言語理解] を選びます。
これにより、[会話言語理解プロジェクト] ページが表示されます。 [新しいプロジェクトの作成] ボタンの横で、[インポート] を選択します。
表示されたウィンドウで、インポートする JSON ファイルをアップロードします。 ファイルが サポートされている JSON 形式に従っていることを確認します。
アップロードが完了すると、[Schema definition] (スキーマ定義) ページに移動します。 このクイックスタートでは、スキーマが既にビルドされており、発話には既に意図とエンティティのラベルが付けられています。
モデルをトレーニングする
通常は、プロジェクトを作成した後、スキーマをビルドし、発話にラベルを付ける必要があります。 このクイックスタートでは、準備が完了したプロジェクトが既にインポートされており、スキーマはビルドされ、発話にはラベルが付けられています。
モデルをトレーニングするには、トレーニング ジョブを開始する必要があります。 成功したトレーニング ジョブの出力は、トレーニング済みのモデルです。
Language Studio 内からモデルのトレーニングを開始するには:
左側のメニューから [モデルのトレーニング] を選択します。
上部のメニューから [Start a training job] (トレーニング ジョブの開始) を選択します。
[新しいモデルのトレーニング] を選択し、テキスト ボックスに新しいモデル名を入力します。 それ以外の場合、既存のモデルを新しいデータでトレーニングされたモデルに置き換えるには、[既存のモデルを上書きする](Overwrite an existing model) を選択し、既存のモデルを選択します。 トレーニング済みモデルを上書きすると、元に戻すことはできません。ただし、新しいモデルをデプロイするまで、デプロイされているモデルには影響しません。
トレーニング モードを選択します。 [標準トレーニング] を選択すると、高速でトレーニングできますが、これを使用できるのは英語に限られます。 または、[高度なトレーニング] を選択できます。これは、他の言語や多言語プロジェクトでもサポートされていますが、トレーニング時間が長くなります。 トレーニング モードの詳細を参照してください。
[データ分割] 方法を選択します。 [トレーニング用データからテスト用セットを自動分割] を選択できます。その場合、システムにより、指定した割合に従って、発話がトレーニング用セットとテスト用セットに分割されます。 または、[トレーニング用データとテスト用データの手動分割を使用] を選択することもできます。このオプションは、発話にラベルを付ける際に発話をテスト用セットに追加した場合にのみ有効になります。
[トレーニング] ボタンを選択します。
リストからトレーニング ジョブ ID を選択します。 ウィンドウが表示され、そのジョブのトレーニングの進行状況、ジョブの状態、その他の詳細を確認できます。
注意
- 正常に完了したトレーニング ジョブでのみ、モデルが生成されます。
- トレーニングは、発話数に応じて、数分から数時間かかる場合があります。
- 一度に実行できるトレーニング ジョブは 1 つだけです。 実行中のジョブが完了しない限り、同じプロジェクト内で他のトレーニング ジョブを開始することはできません。
- モデルのトレーニングに使用される機械学習は定期的に更新されます。 以前の構成バージョンでトレーニングするには、[トレーニング ジョブの開始] ページから [変更するには、ここを選択してください] を選択し、以前のバージョンを選択します。
モデルをデプロイする
通常はモデルをトレーニングした後、その評価の詳細を確認します。 このクイックスタートでは、モデルをデプロイして Language Studio で試せるようにするところまで行いますが、予測 API を呼び出すこともできます。
Language Studio 内からモデルのデプロイを開始するには、次の手順を行います。
左側のメニューから [Deploying a model](モデルのデプロイ) を選びます。
[デプロイの追加] を選択して、[デプロイの追加] ウィザードを開始します。
[新しいデプロイ名を作成する] を選択して新しいデプロイを作成し、下のドロップダウンからトレーニング済みのモデルを割り当てます。 それ以外の場合は、[Overwrite an existing deployment name] (既存のデプロイ名を上書きする) を選択して、既存のデプロイで使用されているモデルを効果的に置き換えることができます。
注意
既存のデプロイを上書きしても、Prediction API の呼び出しを変更する必要はありませんが、その結果は、新しく割り当てたモデルに基づくものになります。
[モデル] ドロップダウンからトレーニング済みのモデルを選択します。
[デプロイ] を選択して、デプロイ ジョブを開始します。
デプロイが成功すると、その横に有効期限が表示されます。 デプロイの有効期限は、デプロイされたモデルを予測に使用できなくなるときで、通常、トレーニング構成の有効期限が切れる 12 か月後に発生します。
次のセクションで、このプロジェクト名とデプロイ名を使用します。
マイクから意図を認識する
以下の手順に従って新しいコンソール アプリケーションを作成し、Speech SDK をインストールします。
Visual Studio Community 2022 で、
SpeechRecognitionという新しい C++ コンソール プロジェクトを作成します。NuGet パッケージ マネージャーを使用して、新しいプロジェクトに Speech SDK をインストールします。
Install-Package Microsoft.CognitiveServices.SpeechSpeechRecognition.cppの内容を次のコードに置き換えます。#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }SpeechRecognition.cppで、cluProjectNameとcluDeploymentName変数をプロジェクトとデプロイの名前に設定します。 CLU プロジェクトとデプロイを作成する方法については、「会話言語理解プロジェクトを作成する」を参照してください。音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合は、es-ESを作成します。 言語を指定しない場合、既定の言語はen-USです。 話される可能性のある複数の言語の 1 つを識別する方法の詳細については、言語の識別に関するページを参照してください。
新しいコンソール アプリケーションをビルドして実行し、マイクからの音声認識を開始します。
重要
上記の説明に従って、LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY、SPEECH_REGION 環境変数を設定してください。 これらの変数を設定しない場合、サンプルはエラー メッセージが表示されて失敗します。
指示されたらマイクに向って話します。 話すことがテキストとして出力される必要があります。
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
注意
LanguageUnderstandingServiceResponse_JsonResult プロパティを使用した CLU の JSON 応答のサポートは、Speech SDK バージョン 1.26 で追加されました。
意図は可能性の高いものから低いものの順に返されます。 topIntent が HomeAutomation.TurnOn で、信頼度スコアが 0.97712576 (97.71%) である JSON 出力の書式設定されたバージョンを次に示します。 2 番目に可能性の高い意図は信頼度スコアが 0.8985081 (89.85%) のHomeAutomation.TurnOff である可能性があります。
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
解説
クイックスタートを完了したので、次にいくつか追加の考慮事項を示します。
- この例では、
RecognizeOnceAsync操作を使用して、最大 30 秒間、または無音が検出されるまでの発話を文字起こししています。 多言語での会話を含め、より長いオーディオの継続的認識については、「音声を認識する方法」を参照してください。 - オーディオ ファイルから音声を認識するには、
FromDefaultMicrophoneInputの代わりにFromWavFileInputを使用します。auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - MP4 などの圧縮されたオーディオ ファイルの場合は、GStreamer をインストールして、
PullAudioInputStreamまたはPushAudioInputStreamを使います。 詳しくは、「圧縮された入力オーディオを使用する方法」をご覧ください。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した Language および Speech リソースを削除できます。
リファレンス ドキュメント | GitHub のその他のサンプル
Speech SDK for Java では、会話言語理解 (CLU) による意図認識はサポートされていません。 別のプログラミング言語を選択するか、この記事の冒頭でリンクされている、Java のリファレンスとサンプルを使用してください。