クイックスタート: カスタム キーワードを作成する
リファレンス ドキュメント | パッケージ (NuGet) | GitHub 上のその他のサンプル
このクイックスタートでは、カスタム キーワードの操作の基本について学びます。 キーワードは、音声で製品をアクティブにするための単語または短い語句です。 キーワード モデルは、Speech Studio 内で作成します。 次に、アプリケーション内の Speech SDK で使用するモデル ファイルをエクスポートします。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
Speech Studio でキーワードを作成する
カスタム キーワードを使用する前に、Speech Studio の [Custom Keyword](カスタム キーワード) ページを使用してキーワードを作成する必要があります。 キーワードを指定すると、Speech SDK で使用できる .table ファイルが生成されます。
重要
カスタム キーワード モデルと、生成される .table ファイルは、Speech Studio でのみ作成できます。
SDK または REST 呼び出しを使用してカスタム キーワードを作成することはできません。
Speech Studio に移動して [サインイン] します。 Speech サブスクリプションをお持ちでない場合には、音声サービスの作成に移動します。
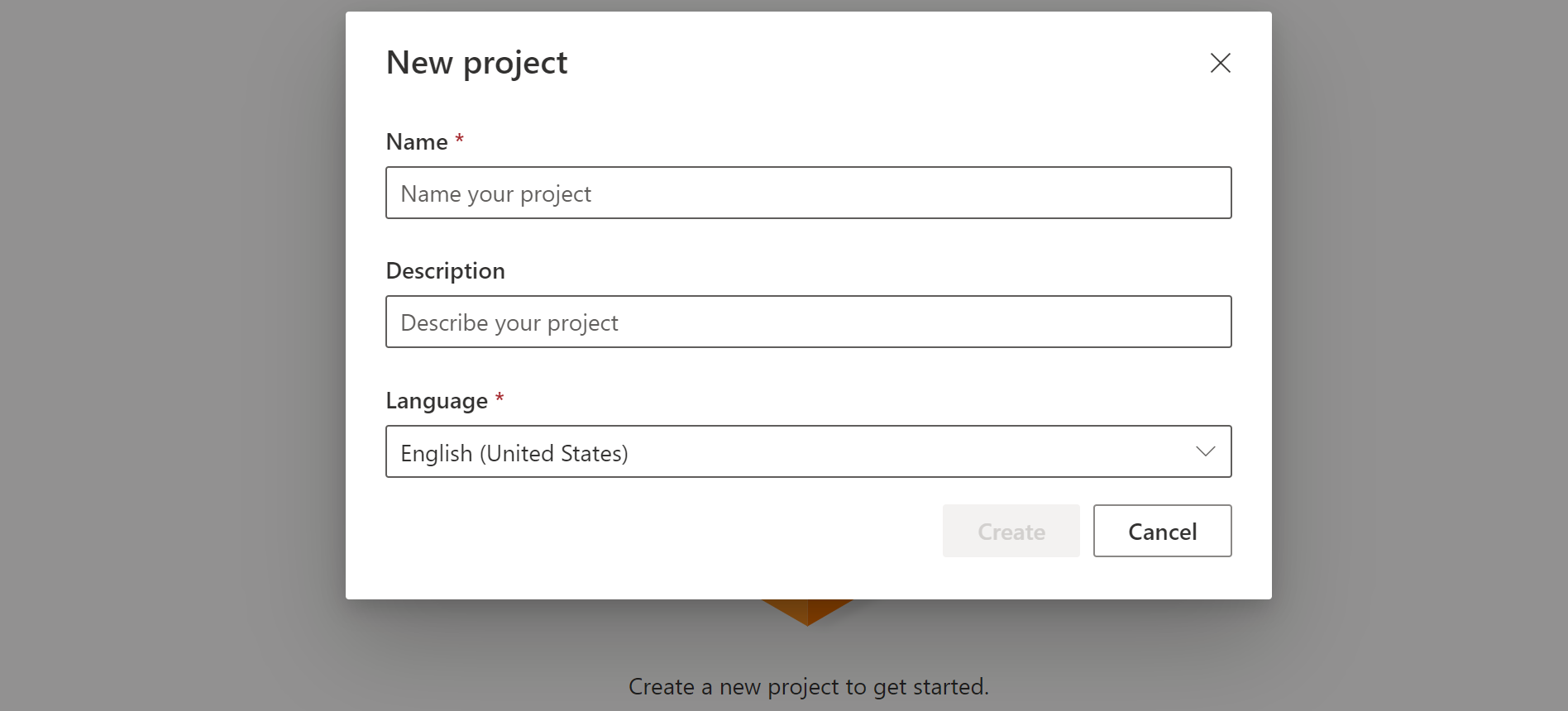
[カスタム キーワード] ページで [新しいプロジェクトの作成] を選択します。
カスタム キーワード プロジェクトの [名前] 、 [説明] 、 [言語] を入力します。 言語は 1 プロジェクトにつき 1 つのみ選択できます。現在、サポートは英語 (米国) と中国語 (標準、簡体字) に制限されています。
一覧からプロジェクト名を選択します。
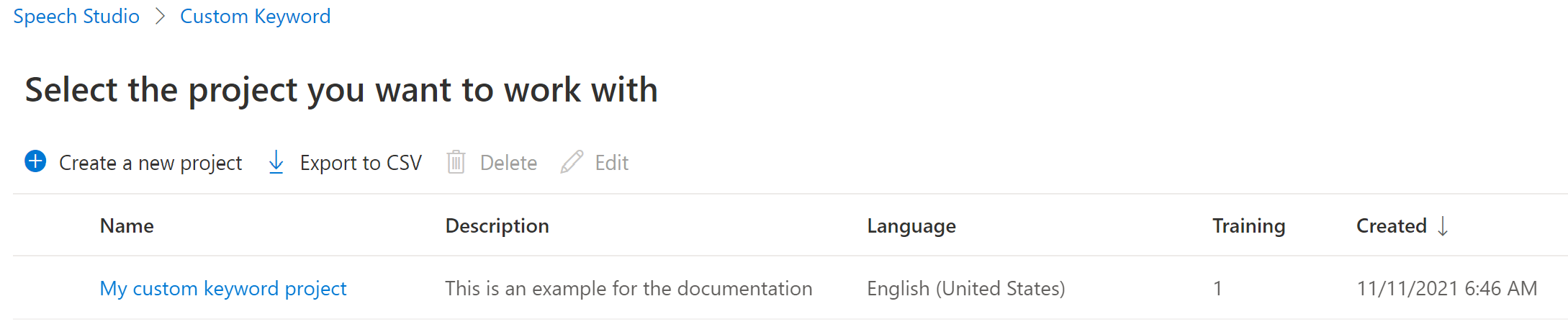
仮想アシスタントのカスタム キーワードを作成して、 [新しいモデルを作成する] を選択します。
モデルの [名前] 、 [説明] 、 [キーワード] を自由に入力して、 [次へ] を選択します。 効果的なキーワードを選択する方法については、ガイドラインを参照してください。
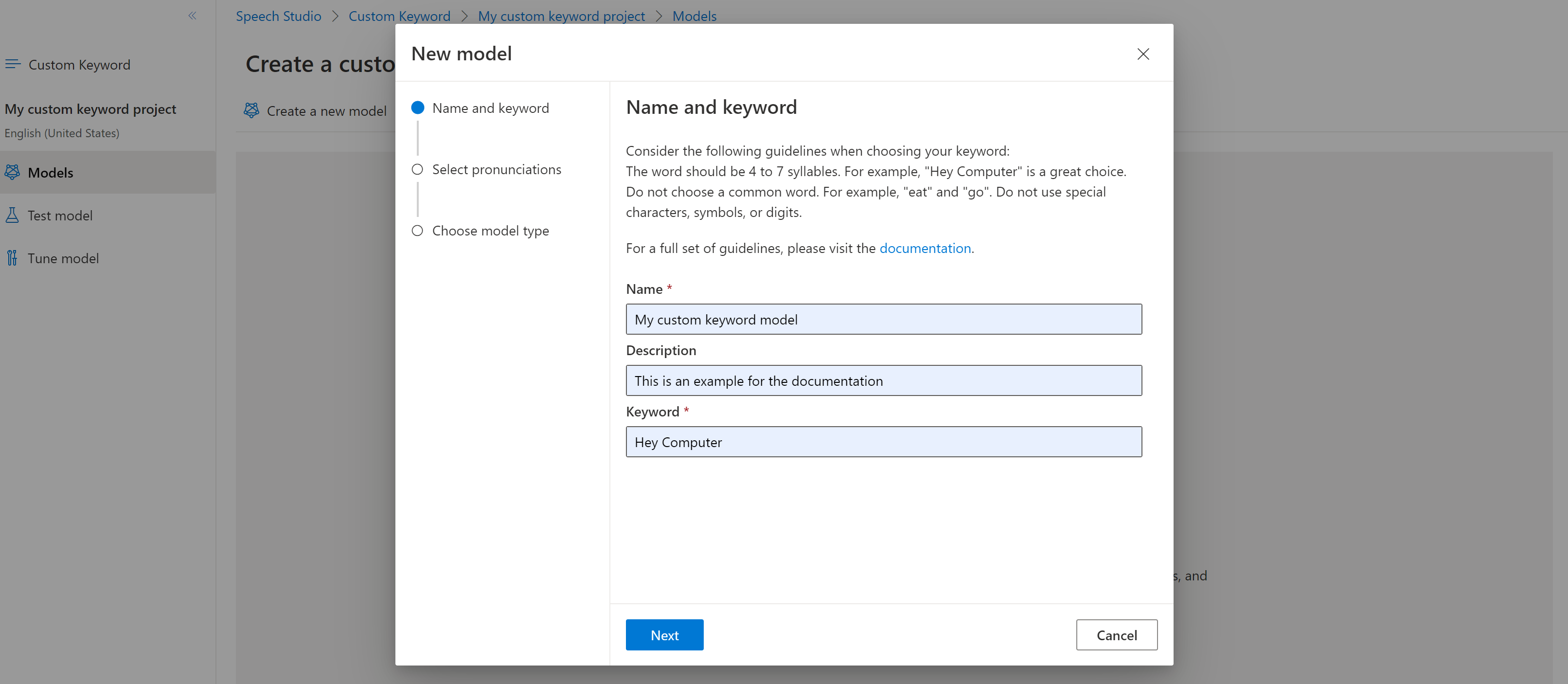
ポータルで、キーワードの発音候補が作成されます。 再生ボタンを選択して各候補の音声を聞き、正しくない発音があれば横にあるチェックを削除します。ユーザーによるキーワードの読み方として想定されるものに対応するすべての発音を選択し、 [次へ] を選択すると、キーワード モデルの生成が始まります。

モデルの種類を選択し、 [作成] を選択します。 モデルタイプ [高度] をサポートしているリージョンの一覧は、「キーワード認識がサポートされているリージョン」ドキュメントで確認できます。
モデルが生成されるまでに最大で 30 分かかる場合があります。 モデルが完了すると、キーワードの一覧が [処理中] から [成功] に変わります。
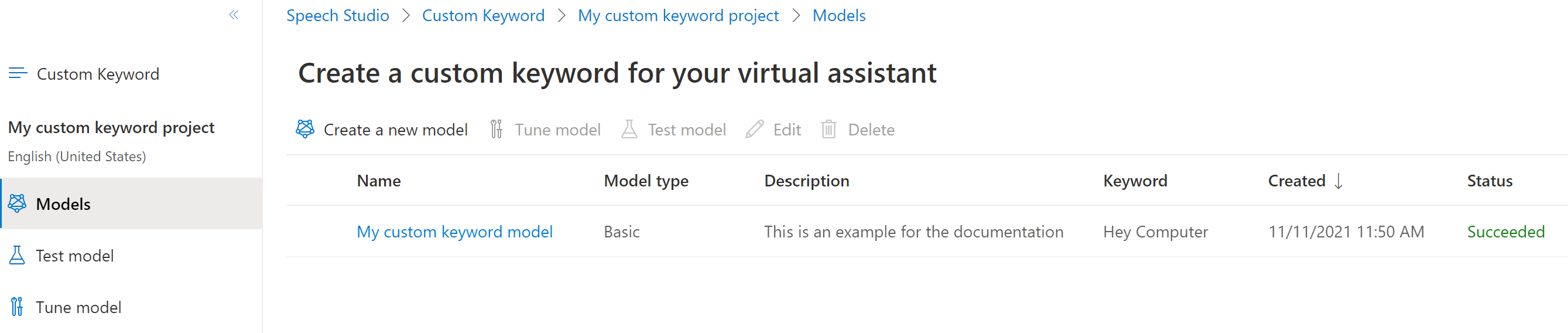
左側の折りたたみ可能なメニューから [Tune](チューニング) を選択してモデルのチューニング オプションを選択したら、モデルをダウンロードします。 ダウンロードしたファイルは
.zipアーカイブです。 アーカイブを抽出すると、.table拡張子を持つファイルが表示されます。 SDK では.tableファイルを使用するので、パスをメモしておいてください。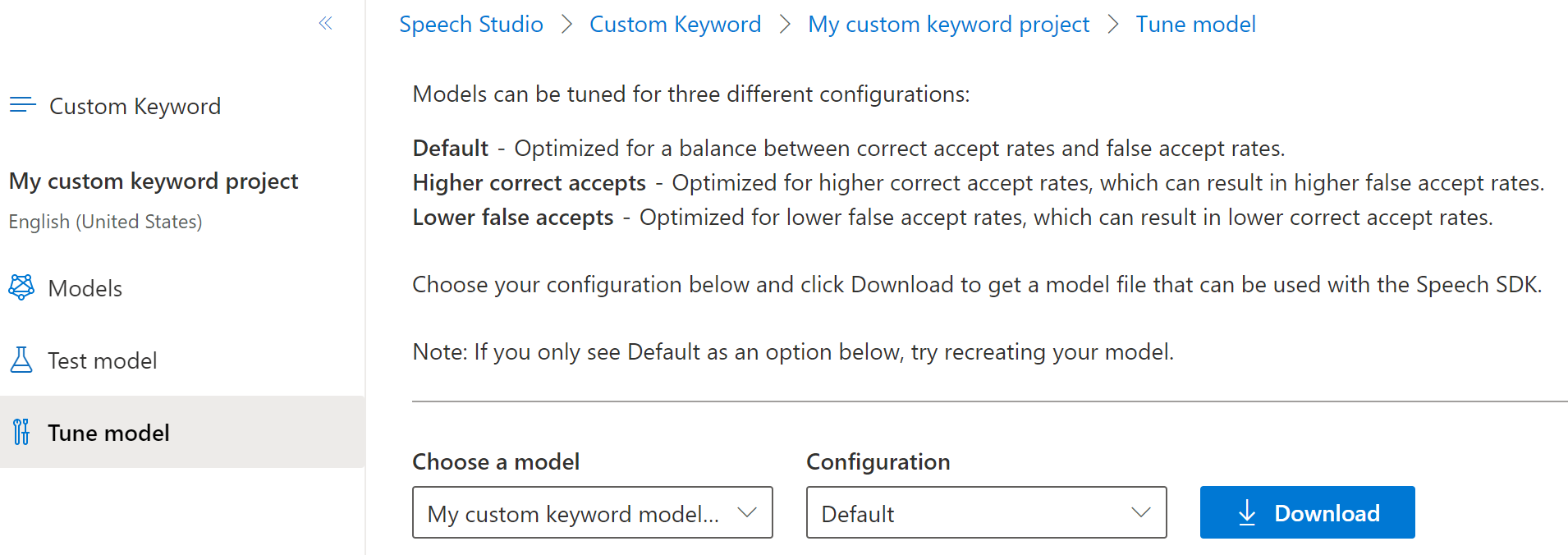
Speech SDK でのキーワード モデルの使用
まず、KeywordRecognitionModel を返す FromFile() 静的関数を使用して、キーワード モデル ファイルを読み込みます。 Speech Studio からダウンロードした .table ファイルへのパスを使用します。 また、既定のマイクを使用して AudioConfig を作成し、オーディオ構成を使用して新しい KeywordRecognizer をインスタンス化します。
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
var keywordModel = KeywordRecognitionModel.FromFile("your/path/to/Activate_device.table");
using var audioConfig = AudioConfig.FromDefaultMicrophoneInput();
using var keywordRecognizer = new KeywordRecognizer(audioConfig);
重要
AudioConfig.fromStreamInput() メソッドを経由してオーディオ サンプルを使用し、キーワード モデルを直接テストする場合は、最初のキーワードの前に少なくとも 1.5 秒の無音のサンプルを使用してください。 これは、キーワード認識エンジンが最初のキーワードを検出する前に、初期化してリッスン状態に到達するのに十分な時間を確保するためです。
次に、モデル オブジェクトを渡すことによって、RecognizeOnceAsync() を 1 回呼び出すだけでキーワード認識が実行されます。 このメソッドにより、キーワードが認識されるまで継続されるキーワード認識セッションが開始されます。 そのため、このデザイン パターンは、一般的にはマルチスレッド アプリケーションや、ウェイクワードを無期限に待ち続けるような場合に使用します。
KeywordRecognitionResult result = await keywordRecognizer.RecognizeOnceAsync(keywordModel);
Note
ここで示す例では、ローカル キーワード認識を使用しています。これは、認証コンテキストに SpeechConfig オブジェクトを必要とせず、バックエンドに接続しないためです。 ただし、直接バックエンド接続を利用することで、キーワード認識と検証の両方を実行できます。
継続的認識
Speech SDK の他のクラスでは、キーワード認識を使用した継続的認識 (音声認識と意図認識の両方) がサポートされています。 SDK により、継続的認識に通常使用するものと同じコードを使用でき、キーワード モデルの .table ファイルを参照できます。
音声変換の場合、音声認識ガイドに示されているものと同じデザイン パターンに従って、継続的認識を設定します。 次に、recognizer.StartContinuousRecognitionAsync() の呼び出しを recognizer.StartKeywordRecognitionAsync(KeywordRecognitionModel) に置き換え、KeywordRecognitionModel オブジェクトを渡します。 キーワード認識を使用した継続的認識を停止するには、recognizer.StopContinuousRecognitionAsync() ではなく recognizer.StopKeywordRecognitionAsync() を使用します。
意図認識では、StartKeywordRecognitionAsync および StopKeywordRecognitionAsync 関数と同じパターンを使用します。
リファレンス ドキュメント | パッケージ (NuGet) | GitHub 上のその他のサンプル
Speech SDK for C++ では、キーワード認識がサポートされていますが、本書にはまだガイドが含まれていません。 作業を開始するには別のプログラミング言語を選択して概念について学ぶか、この記事の冒頭でリンクされている C++ のリファレンスとサンプルを参照してください。
author: eric-urban ms.service: azure-ai-speech ms.topic: include ms.date: 9/12/2024 ms.author: eur
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
Speech Studio でキーワードを作成する
カスタム キーワードを使用する前に、Speech Studio の [Custom Keyword](カスタム キーワード) ページを使用してキーワードを作成する必要があります。 キーワードを指定すると、Speech SDK で使用できる .table ファイルが生成されます。
重要
カスタム キーワード モデルと、生成される .table ファイルは、Speech Studio でのみ作成できます。
SDK または REST 呼び出しを使用してカスタム キーワードを作成することはできません。
Speech Studio に移動して [サインイン] します。 Speech サブスクリプションをお持ちでない場合には、音声サービスの作成に移動します。
[カスタム キーワード] ページで [新しいプロジェクトの作成] を選択します。
カスタム キーワード プロジェクトの [名前] 、 [説明] 、 [言語] を入力します。 言語は 1 プロジェクトにつき 1 つのみ選択できます。現在、サポートは英語 (米国) と中国語 (標準、簡体字) に制限されています。
一覧からプロジェクト名を選択します。
仮想アシスタントのカスタム キーワードを作成して、 [新しいモデルを作成する] を選択します。
モデルの [名前] 、 [説明] 、 [キーワード] を自由に入力して、 [次へ] を選択します。 効果的なキーワードを選択する方法については、ガイドラインを参照してください。
ポータルで、キーワードの発音候補が作成されます。 再生ボタンを選択して各候補の音声を聞き、正しくない発音があれば横にあるチェックを削除します。ユーザーによるキーワードの読み方として想定されるものに対応するすべての発音を選択し、 [次へ] を選択すると、キーワード モデルの生成が始まります。
モデルの種類を選択し、 [作成] を選択します。 モデルタイプ [高度] をサポートしているリージョンの一覧は、「キーワード認識がサポートされているリージョン」ドキュメントで確認できます。
モデルが生成されるまでに最大で 30 分かかる場合があります。 モデルが完了すると、キーワードの一覧が [処理中] から [成功] に変わります。
左側の折りたたみ可能なメニューから [Tune](チューニング) を選択してモデルのチューニング オプションを選択したら、モデルをダウンロードします。 ダウンロードしたファイルは
.zipアーカイブです。 アーカイブを抽出すると、.table拡張子を持つファイルが表示されます。 SDK では.tableファイルを使用するので、パスをメモしておいてください。
Speech SDK でのキーワード モデルの使用
Go SDK で Custom Keyword モデルを使用する方法については、リファレンス ドキュメントを参照してください。
リファレンス ドキュメント | GitHub 上のその他のサンプル
Speech SDK for Java では、キーワード認識がサポートされていますが、本書にはまだガイドが含まれていません。 作業を開始するには、別のプログラミング言語を選択して概念について学ぶか、この記事の冒頭でリンクされている、Java のリファレンスとサンプルを参照してください。
リファレンスドキュメント | パッケージ (npm) | GitHub 上のその他のサンプル | ライブラリのソース コード
Speech SDK for JavaScript では、キーワード認識がサポートされていません。 別のプログラミング言語か、この記事の冒頭でリンクされている JavaScript のリファレンスとサンプルを選択してください。
リファレンス ドキュメント | パッケージ (ダウンロード) | GitHub 上のその他のサンプル
このクイックスタートでは、カスタム キーワードの操作の基本について学びます。 キーワードは、音声で製品をアクティブにするための単語または短い語句です。 キーワード モデルは、Speech Studio 内で作成します。 次に、アプリケーション内の Speech SDK で使用するモデル ファイルをエクスポートします。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
Speech Studio でキーワードを作成する
カスタム キーワードを使用する前に、Speech Studio の [Custom Keyword](カスタム キーワード) ページを使用してキーワードを作成する必要があります。 キーワードを指定すると、Speech SDK で使用できる .table ファイルが生成されます。
重要
カスタム キーワード モデルと、生成される .table ファイルは、Speech Studio でのみ作成できます。
SDK または REST 呼び出しを使用してカスタム キーワードを作成することはできません。
Speech Studio に移動して [サインイン] します。 Speech サブスクリプションをお持ちでない場合には、音声サービスの作成に移動します。
[カスタム キーワード] ページで [新しいプロジェクトの作成] を選択します。
カスタム キーワード プロジェクトの [名前] 、 [説明] 、 [言語] を入力します。 言語は 1 プロジェクトにつき 1 つのみ選択できます。現在、サポートは英語 (米国) と中国語 (標準、簡体字) に制限されています。
一覧からプロジェクト名を選択します。
仮想アシスタントのカスタム キーワードを作成して、 [新しいモデルを作成する] を選択します。
モデルの [名前] 、 [説明] 、 [キーワード] を自由に入力して、 [次へ] を選択します。 効果的なキーワードを選択する方法については、ガイドラインを参照してください。
ポータルで、キーワードの発音候補が作成されます。 再生ボタンを選択して各候補の音声を聞き、正しくない発音があれば横にあるチェックを削除します。ユーザーによるキーワードの読み方として想定されるものに対応するすべての発音を選択し、 [次へ] を選択すると、キーワード モデルの生成が始まります。
モデルの種類を選択し、 [作成] を選択します。 モデルタイプ [高度] をサポートしているリージョンの一覧は、「キーワード認識がサポートされているリージョン」ドキュメントで確認できます。
モデルが生成されるまでに最大で 30 分かかる場合があります。 モデルが完了すると、キーワードの一覧が [処理中] から [成功] に変わります。
左側の折りたたみ可能なメニューから [Tune](チューニング) を選択してモデルのチューニング オプションを選択したら、モデルをダウンロードします。 ダウンロードしたファイルは
.zipアーカイブです。 アーカイブを抽出すると、.table拡張子を持つファイルが表示されます。 SDK では.tableファイルを使用するので、パスをメモしておいてください。
Speech SDK でのキーワード モデルの使用
Custom Keyword モデルと共に Objective C SDK を使用する方法については GitHub のサンプルをご覧ください。
リファレンス ドキュメント | パッケージ (ダウンロード) | GitHub 上のその他のサンプル
このクイックスタートでは、カスタム キーワードの操作の基本について学びます。 キーワードは、音声で製品をアクティブにするための単語または短い語句です。 キーワード モデルは、Speech Studio 内で作成します。 次に、アプリケーション内の Speech SDK で使用するモデル ファイルをエクスポートします。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
Speech Studio でキーワードを作成する
カスタム キーワードを使用する前に、Speech Studio の [Custom Keyword](カスタム キーワード) ページを使用してキーワードを作成する必要があります。 キーワードを指定すると、Speech SDK で使用できる .table ファイルが生成されます。
重要
カスタム キーワード モデルと、生成される .table ファイルは、Speech Studio でのみ作成できます。
SDK または REST 呼び出しを使用してカスタム キーワードを作成することはできません。
Speech Studio に移動して [サインイン] します。 Speech サブスクリプションをお持ちでない場合には、音声サービスの作成に移動します。
[カスタム キーワード] ページで [新しいプロジェクトの作成] を選択します。
カスタム キーワード プロジェクトの [名前] 、 [説明] 、 [言語] を入力します。 言語は 1 プロジェクトにつき 1 つのみ選択できます。現在、サポートは英語 (米国) と中国語 (標準、簡体字) に制限されています。
一覧からプロジェクト名を選択します。
仮想アシスタントのカスタム キーワードを作成して、 [新しいモデルを作成する] を選択します。
モデルの [名前] 、 [説明] 、 [キーワード] を自由に入力して、 [次へ] を選択します。 効果的なキーワードを選択する方法については、ガイドラインを参照してください。
ポータルで、キーワードの発音候補が作成されます。 再生ボタンを選択して各候補の音声を聞き、正しくない発音があれば横にあるチェックを削除します。ユーザーによるキーワードの読み方として想定されるものに対応するすべての発音を選択し、 [次へ] を選択すると、キーワード モデルの生成が始まります。
モデルの種類を選択し、 [作成] を選択します。 モデルタイプ [高度] をサポートしているリージョンの一覧は、「キーワード認識がサポートされているリージョン」ドキュメントで確認できます。
モデルが生成されるまでに最大で 30 分かかる場合があります。 モデルが完了すると、キーワードの一覧が [処理中] から [成功] に変わります。
左側の折りたたみ可能なメニューから [Tune](チューニング) を選択してモデルのチューニング オプションを選択したら、モデルをダウンロードします。 ダウンロードしたファイルは
.zipアーカイブです。 アーカイブを抽出すると、.table拡張子を持つファイルが表示されます。 SDK では.tableファイルを使用するので、パスをメモしておいてください。
Speech SDK でのキーワード モデルの使用
Custom Keyword モデルと共に Objective C SDK を使用する方法については GitHub のサンプルをご覧ください。 現在、パリティ用の Swift サンプルはありませんが、概念は似ています。
Note
iOS 上の Swift アプリケーションでキーワード認識を使用する場合、Speech Studio で作成した新しいキーワード モデルを使用するには、プロジェクトで Speech SDK xcframework バンドル (https://aka.ms/csspeech/iosbinaryembedded) または MicrosoftCognitiveServicesSpeechEmbedded-iOS ポッドのいずれかを使用する必要があることに注意してください。
リファレンス ドキュメント | パッケージ (PyPi) | GitHub 上のその他のサンプル
このクイックスタートでは、カスタム キーワードの操作の基本について学びます。 キーワードは、音声で製品をアクティブにするための単語または短い語句です。 キーワード モデルは、Speech Studio 内で作成します。 次に、アプリケーション内の Speech SDK で使用するモデル ファイルをエクスポートします。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
Speech Studio でキーワードを作成する
カスタム キーワードを使用する前に、Speech Studio の [Custom Keyword](カスタム キーワード) ページを使用してキーワードを作成する必要があります。 キーワードを指定すると、Speech SDK で使用できる .table ファイルが生成されます。
重要
カスタム キーワード モデルと、生成される .table ファイルは、Speech Studio でのみ作成できます。
SDK または REST 呼び出しを使用してカスタム キーワードを作成することはできません。
Speech Studio に移動して [サインイン] します。 Speech サブスクリプションをお持ちでない場合には、音声サービスの作成に移動します。
[カスタム キーワード] ページで [新しいプロジェクトの作成] を選択します。
カスタム キーワード プロジェクトの [名前] 、 [説明] 、 [言語] を入力します。 言語は 1 プロジェクトにつき 1 つのみ選択できます。現在、サポートは英語 (米国) と中国語 (標準、簡体字) に制限されています。
一覧からプロジェクト名を選択します。
仮想アシスタントのカスタム キーワードを作成して、 [新しいモデルを作成する] を選択します。
モデルの [名前] 、 [説明] 、 [キーワード] を自由に入力して、 [次へ] を選択します。 効果的なキーワードを選択する方法については、ガイドラインを参照してください。
ポータルで、キーワードの発音候補が作成されます。 再生ボタンを選択して各候補の音声を聞き、正しくない発音があれば横にあるチェックを削除します。ユーザーによるキーワードの読み方として想定されるものに対応するすべての発音を選択し、 [次へ] を選択すると、キーワード モデルの生成が始まります。
モデルの種類を選択し、 [作成] を選択します。 モデルタイプ [高度] をサポートしているリージョンの一覧は、「キーワード認識がサポートされているリージョン」ドキュメントで確認できます。
モデルが生成されるまでに最大で 30 分かかる場合があります。 モデルが完了すると、キーワードの一覧が [処理中] から [成功] に変わります。
左側の折りたたみ可能なメニューから [Tune](チューニング) を選択してモデルのチューニング オプションを選択したら、モデルをダウンロードします。 ダウンロードしたファイルは
.zipアーカイブです。 アーカイブを抽出すると、.table拡張子を持つファイルが表示されます。 SDK では.tableファイルを使用するので、パスをメモしておいてください。
Speech SDK でのキーワード モデルの使用
Custom Keyword モデルと共に Python SDK を使用する方法については GitHub のサンプルをご覧ください。
Speech to Text REST API リファレンス | Speech to Text REST API for short audio リファレンス | GitHub 上のその他のサンプル
Speech to text REST API では、キーワード認識がサポートされていません。 別のプログラミング言語か、この記事の冒頭でリンクされているリファレンスとサンプルを選択してください。
Speech CLI では、キーワード認識がサポートされていますが、本書にはまだガイドが含まれていません。 使用を開始して概念について学ぶには、別のプログラミング言語を選択してください。