クイック スタート: 独自のデータを使用して Azure OpenAI モデルとチャットする
このクイックスタートでは、Azure OpenAI モデルで独自のデータを使用できます。 データに Azure OpenAI のモデルを使用すると、より高速で正確なコミュニケーションを可能にする強力な会話型 AI プラットフォームが使用できます。
前提条件
次のリソース:
- Azure OpenAI
- Azure Blob Storage
- Azure AI Search
- サポート対象のリージョンに、サポートされているモデルでデプロイされた Azure OpenAI リソース。
- 少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
- 独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。

[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。



チャット プレイグラウンド
チャット プレイグラウンドを使用すると、コードなしのアプローチで Azure OpenAI 機能の探索を開始できます。 これは単に、入力候補を生成するためのプロンプトを送信できるテキスト ボックスです。 このページから、機能をすばやく反復して実験することができます。

プレイグラウンドは、チャットエクスペリエンスを調整するためのオプションを提供します。 上部のメニューの [デプロイ] を選択して、インデックスからの検索結果を使用して応答を生成するモデルを決定できます。 今後の応答生成のために会話履歴として含める、過去のメッセージの数を選択します。 会話履歴 は、関連する応答を生成するためのコンテキストを提供しますが、トークンの使用状況も利用します。 入力トークンの進行状況インジケーターは、送信した質問のトークン数を追跡します。
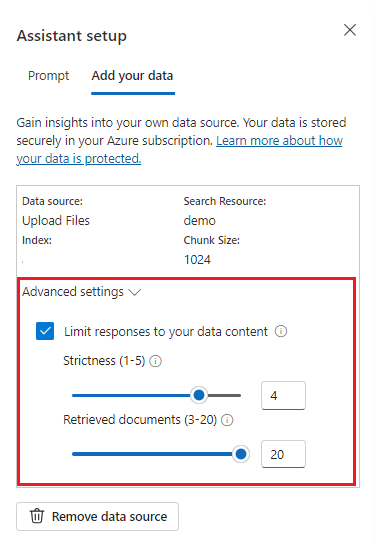
左側にある [詳細設定] は、データからの関連情報の取得と検索を制御するための ランタイム パラメータです。 この適切なユース ケースとしては、確実にデータのみに基づいて応答が生成されるようにしたい場合、またはデータ上の既存の情報に基づいた応答を、モデルが生成できていないという場合が挙げられます。
[厳密性]では、類似性スコアに基づいて検索ドキュメントをフィルタリングする際の、システムの積極度を決定します。 厳密性を 5 に設定することは、システムが類似性について非常に高いしきい値を適用し、ドキュメントを積極的に除外することを表します。 このシナリオではセマンティック検索が役立ちます。ランク付けモデルがクエリの意図をより適切に推測できるようになるからです。 厳密度のレベルを低くするほど、より詳細な回答が生成されますが、インデックスにない情報が含まれる可能性もあります。 これは、既定で 3 に設定されています。
取得されるドキュメントは、3、5、10、または 20 に設定できる整数であり、最終的な応答を生成するために大規模言語モデルに提供されるドキュメント チャンクの数を制御します。 既定では、5 に設定されます。
[データに応答を制限する]を有効にすると、モデルは応答にユーザーのドキュメントのみを利用しようとします。 これは既定で true に設定されます。
最初のクエリを送信します。 チャット モデルは、質問と回答の演習で最も優れたパフォーマンスを発揮します。 "利用可能なヘルス プランは何ですか?" や "ヘルス プラス オプションとは何ですか?" などがこの例です。
"どのヘルス プランが最も人気がありますか?" など、データ分析を必要とするクエリは失敗する可能性があります。 "これまでアップロードしたドキュメントの数は?" など、すべてのデータに関する情報を必要とするクエリも、失敗する可能性があります。 検索エンジンは、クエリに対して完全または類似の用語、語句、または構築を持つチャンクを検索することに注意してください。 また、モデルは質問を理解しているかもしれませんが、検索結果がデータセットからのチャンクである場合、この情報は、前のような種類の質問に答えるのに適切とは言えません。
チャットは、応答で返されるドキュメント (チャンク) 数によって制限されます (Azure OpenAI Studio プレイグラウンドでは 3 個から 20 個に制限されます)。 ご想像のとおり、"すべてのタイトル" に関する質問をするには、ベクター ストア全体をフル スキャンする必要があります。
モデルをデプロイする
Azure OpenAI Studio でのエクスペリエンスに納得していただけたら、[デプロイ先] ボタンを選び、Studio から直接 Web アプリをデプロイできます。

これにより、スタンドアロン Web アプリにデプロイするか、Copilot Studio (プレビュー) のコパイロットにデプロイするか (モデルで独自のデータを使用している場合) を選択するオプションが表示されます。
たとえば、Web アプリをデプロイすることを選択した場合は、次のようになります:
初めて Web アプリをデプロイする場合は、[新しい Web アプリを作成する] を選ぶ必要があります。 アプリの URL の一部となるアプリ名を決めます。 たとえば、「 https://<appname>.azurewebsites.net 」のように入力します。
発行されたアプリのサブスクリプション、リソース グループ、場所、価格プランを選びます。 既存のアプリを更新するには、[Publish to an existing web app](既存の Web アプリに発行する) を選び、ドロップダウン メニューから従来のアプリの名前を選びます。
Web アプリをデプロイする場合は、その使用に関する重要な考慮事項を参照してください。
前提条件
次のリソース:
- Azure OpenAI
- Azure Blob Storage
- Azure AI Search
- サポート対象のリージョンに、サポートされているモデルでデプロイされた Azure OpenAI リソース。
- 少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
- 独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
- .NET 8 SDK
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。
[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。
必要な変数を取得する
Azure OpenAI の呼び出しを正しく行うには、次の変数が必要です。 このクイックスタートでは、Azure Blob Storage アカウントにデータをアップロードし、Azure AI Search インデックスを作成していることを前提としています。 Azure AI Studio を使用したデータの追加に関するページを参照してください。
| 変数名 | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 または、Azure AI Studio>[チャット プレイグラウンド]>[コード ビュー] で値を確認することもできます。 エンドポイントの例: https://my-resoruce.openai.azure.com。 |
AZURE_OPENAI_API_KEY |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[リソース管理]>[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 KEY1 または KEY2 を使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_OPENAI_DEPLOYMENT_ID |
この値は、モデルのデプロイ時にデプロイに対して選択したカスタム名に対応します。 この値は、Azure portal の [リソース管理]>[デプロイ] または Azure AI Studio の [管理]>[デプロイ] で確認できます。 |
AZURE_AI_SEARCH_ENDPOINT |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[概要]セクションで確認することができます。 |
AZURE_AI_SEARCH_API_KEY |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[設定]>[キー] セクションで確認することができます。 プライマリ管理者キーまたはセカンダリ管理者キーのいずれかを使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_AI_SEARCH_INDEX |
この値は、データを格納するために作成したインデックスの名前に対応します。 Azure portal から Azure AI Search リソースを調べる場合は、[概要] セクションで確認できます。 |
環境変数
キーとエンドポイントの永続的な環境変数を作成して割り当てます。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
setx AZURE_OPENAI_ENDPOINT REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
setx AZURE_OPENAI_API_KEY REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
setx AZURE_OPENAI_DEPLOYMENT_ID REPLACE_WITH_YOUR_AOAI_DEPLOYMENT_VALUE_HERE
setx AZURE_AI_SEARCH_ENDPOINT REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
setx AZURE_AI_SEARCH_API_KEY REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
setx AZURE_AI_SEARCH_INDEX REPLACE_WITH_YOUR_INDEX_NAME_HERE
新しい .NET Core アプリを作成する
コンソール ウィンドウ (cmd、PowerShell、Bash など) で、dotnet new コマンドを使用し、azure-openai-quickstart という名前で新しいコンソール アプリを作成します。 このコマンドにより、次の C# ソース ファイルを 1 つ使用する単純な "Hello World" プロジェクトが作成されます: Program.cs。
dotnet new console -n azure-openai-quickstart
新しく作成されたアプリ フォルダーにディレクトリを変更します。 次を使用してアプリケーションをビルドできます。
dotnet build
ビルドの出力に警告やエラーが含まれないようにする必要があります。
...
Build succeeded.
0 Warning(s)
0 Error(s)
...
以下を使って、OpenAI .NET クライアント ライブラリをインストールします。
dotnet add package Azure.AI.OpenAI --prerelease
プロジェクト ディレクトリから Program.cs ファイルを開いて、そのコンテンツを以下のコードに置き換えます。
応答ストリーミングなし
using Azure;
using Azure.AI.OpenAI;
using Azure.AI.OpenAI.Chat;
using OpenAI.Chat;
using System.Text.Json;
using static System.Environment;
string azureOpenAIEndpoint = GetEnvironmentVariable("AZURE_OPENAI_ENDPOINT");
string azureOpenAIKey = GetEnvironmentVariable("AZURE_OPENAI_API_KEY");
string deploymentName = GetEnvironmentVariable("AZURE_OPENAI_DEPLOYMENT_ID");
string searchEndpoint = GetEnvironmentVariable("AZURE_AI_SEARCH_ENDPOINT");
string searchKey = GetEnvironmentVariable("AZURE_AI_SEARCH_API_KEY");
string searchIndex = GetEnvironmentVariable("AZURE_AI_SEARCH_INDEX");
#pragma warning disable AOAI001
AzureOpenAIClient azureClient = new(
new Uri(azureOpenAIEndpoint),
new AzureKeyCredential(azureOpenAIKey));
ChatClient chatClient = azureClient.GetChatClient(deploymentName);
ChatCompletionOptions options = new();
options.AddDataSource(new AzureSearchChatDataSource()
{
Endpoint = new Uri(searchEndpoint),
IndexName = searchIndex,
Authentication = DataSourceAuthentication.FromApiKey(searchKey),
});
ChatCompletion completion = chatClient.CompleteChat(
[
new UserChatMessage("What are my available health plans?"),
], options);
Console.WriteLine(completion.Content[0].Text);
AzureChatMessageContext onYourDataContext = completion.GetAzureMessageContext();
if (onYourDataContext?.Intent is not null)
{
Console.WriteLine($"Intent: {onYourDataContext.Intent}");
}
foreach (AzureChatCitation citation in onYourDataContext?.Citations ?? [])
{
Console.WriteLine($"Citation: {citation.Content}");
}
重要
運用環境では、Azure Key Vault などの資格情報を格納してアクセスする安全な方法を使用します。 資格情報のセキュリティについて詳しくは、Azure AI サービスのセキュリティに関する記事をご覧ください。
dotnet run program.cs
出力
Contoso Electronics offers two health plans: Northwind Health Plus and Northwind Standard [doc1]. Northwind Health Plus is a comprehensive plan that provides coverage for medical, vision, and dental services, prescription drug coverage, mental health and substance abuse coverage, and coverage for preventive care services. It also offers coverage for emergency services, both in-network and out-of-network. On the other hand, Northwind Standard is a basic plan that provides coverage for medical, vision, and dental services, prescription drug coverage, and coverage for preventive care services. However, it does not offer coverage for emergency services, mental health and substance abuse coverage, or out-of-network services [doc1].
Intent: ["What are the available health plans?", "List of health plans available", "Health insurance options", "Types of health plans offered"]
Citation:
Contoso Electronics plan and benefit packages
Thank you for your interest in the Contoso electronics plan and benefit packages. Use this document to
learn more about the various options available to you...// Omitted for brevity
これは、結果を出力する前に、モデルが応答全体を生成するまで待機します。 または、応答を非同期的にストリーミングして結果を出力する場合は、Program.cs の内容を次の例のコードに置き換えることができます。
ストリーミングを使用した非同期
using Azure;
using Azure.AI.OpenAI;
using Azure.AI.OpenAI.Chat;
using OpenAI.Chat;
using static System.Environment;
string azureOpenAIEndpoint = GetEnvironmentVariable("AZURE_OPENAI_ENDPOINT");
string azureOpenAIKey = GetEnvironmentVariable("AZURE_OPENAI_API_KEY");
string deploymentName = GetEnvironmentVariable("AZURE_OPENAI_DEPLOYMENT_ID");
string searchEndpoint = GetEnvironmentVariable("AZURE_AI_SEARCH_ENDPOINT");
string searchKey = GetEnvironmentVariable("AZURE_AI_SEARCH_API_KEY");
string searchIndex = GetEnvironmentVariable("AZURE_AI_SEARCH_INDEX");
#pragma warning disable AOAI001
AzureOpenAIClient azureClient = new(
new Uri(azureOpenAIEndpoint),
new AzureKeyCredential(azureOpenAIKey));
ChatClient chatClient = azureClient.GetChatClient(deploymentName);
ChatCompletionOptions options = new();
options.AddDataSource(new AzureSearchChatDataSource()
{
Endpoint = new Uri(searchEndpoint),
IndexName = searchIndex,
Authentication = DataSourceAuthentication.FromApiKey(searchKey),
});
var chatUpdates = chatClient.CompleteChatStreamingAsync(
[
new UserChatMessage("What are my available health plans?"),
], options);
AzureChatMessageContext onYourDataContext = null;
await foreach (var chatUpdate in chatUpdates)
{
if (chatUpdate.Role.HasValue)
{
Console.WriteLine($"{chatUpdate.Role}: ");
}
foreach (var contentPart in chatUpdate.ContentUpdate)
{
Console.Write(contentPart.Text);
}
if (onYourDataContext == null)
{
onYourDataContext = chatUpdate.GetAzureMessageContext();
}
}
Console.WriteLine();
if (onYourDataContext?.Intent is not null)
{
Console.WriteLine($"Intent: {onYourDataContext.Intent}");
}
foreach (AzureChatCitation citation in onYourDataContext?.Citations ?? [])
{
Console.Write($"Citation: {citation.Content}");
}
前提条件
次のリソース:
- Azure OpenAI
- Azure Blob Storage
- Azure AI Search
- サポート対象のリージョンに、サポートされているモデルでデプロイされた Azure OpenAI リソース。
- 少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
- 独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。
[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。
必要な変数を取得する
Azure OpenAI の呼び出しを正しく行うには、次の変数が必要です。 このクイックスタートでは、Azure Blob Storage アカウントにデータをアップロードし、Azure AI Search インデックスを作成していることを前提としています。 詳細については、Azure AI Studio を使ったデータの追加に関する記事を参照してください。
| 変数名 | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 または、Azure AI Studio>[チャット プレイグラウンド]>[コード ビュー] で値を確認することもできます。 エンドポイントの例: https://my-resource.openai.azure.com。 |
AZURE_OPENAI_API_KEY |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[リソース管理]>[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 KEY1 または KEY2 を使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_OPEN_AI_DEPLOYMENT_ID |
この値は、モデルのデプロイ時にデプロイに対して選択したカスタム名に対応します。 この値は、Azure portal の [リソース管理]>[デプロイ] または Azure AI Studio の [管理]>[デプロイ] で確認できます。 |
AZURE_AI_SEARCH_ENDPOINT |
この値は、Azure portal から Azure AI 検索リソースを確認する際に、[概要] セクションで確認できます。 |
AZURE_AI_SEARCH_API_KEY |
この値は、Azure portal から Azure AI 検索リソースを確認する際に、[設定]>[キー] セクションで確認できます。 プライマリ管理者キーまたはセカンダリ管理者キーのいずれかを使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_AI_SEARCH_INDEX |
この値は、データを格納するために作成したインデックスの名前に対応します。 Azure portal から Azure AI Search リソースを調べる場合は、[概要] セクションで確認できます。 |
環境変数
キーとエンドポイントの永続的な環境変数を作成して割り当てます。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Note
Spring AI の既定のモデル名は gpt-35-turbo です。 別の名前でモデルをデプロイした場合にのみ、SPRING_AI_AZURE_OPENAI_MODEL 値を指定する必要があります。
export SPRING_AI_AZURE_OPENAI_ENDPOINT=REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
export SPRING_AI_AZURE_OPENAI_API_KEY=REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
export SPRING_AI_AZURE_COGNITIVE_SEARCH_ENDPOINT=REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
export SPRING_AI_AZURE_COGNITIVE_SEARCH_API_KEY=REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
export SPRING_AI_AZURE_COGNITIVE_SEARCH_INDEX=REPLACE_WITH_YOUR_INDEX_NAME_HERE
export SPRING_AI_AZURE_OPENAI_MODEL=REPLACE_WITH_YOUR_MODEL_NAME_HERE
新しい Spring アプリケーションを作成する
Spring AI では現在、Azure AI クエリで取得拡張生成 (RAG) メソッドをカプセル化し、詳細をユーザーから隠せるようにする AzureCognitiveSearchChatExtensionConfiguration オプションはサポートされていません。 代わりに、アプリケーションで RAG メソッドを直接呼び出して、Azure AI 検索インデックス内のデータにクエリを実行し、取得したドキュメントを使ってクエリを強化することもできます。
Spring AI は VectorStore 抽象化をサポートしており、カスタム データのクエリを実行するために Azure AI 検索を Spring AI VectorStore 実装でラップできます。 次のプロジェクトでは、Azure AI 検索によってサポートされるカスタム VectorStore を実装し、RAG 操作を直接実行します。
Bash ウィンドウで、アプリの新しいディレクトリを作成し、そのディレクトリに移動します。
mkdir ai-custom-data-demo && cd ai-custom-data-demo
作業ディレクトリから spring init コマンドを実行します。 このコマンドは、main の Java クラス ソース ファイルや Maven ベースのプロジェクト管理に使用される pom.xml ファイルなど、Spring プロジェクトの標準ディレクトリ構造を作成します。
spring init -a ai-custom-data-demo -n AICustomData --force --build maven -x
生成されるファイルとフォルダーは次のような構造になります。
ai-custom-data-demo/
|-- pom.xml
|-- mvn
|-- mvn.cmd
|-- HELP.md
|-- src/
|-- main/
| |-- resources/
| | |-- application.properties
| |-- java/
| |-- com/
| |-- example/
| |-- aicustomdatademo/
| |-- AiCustomDataApplication.java
|-- test/
|-- java/
|-- com/
|-- example/
|-- aicustomdatademo/
|-- AiCustomDataApplicationTests.java
Spring アプリケーションを編集する
pom.xml ファイルを編集します。
プロジェクト ディレクトリのルートから、任意のエディターまたは IDE で pom.xml ファイルを開き、次の内容でファイルを上書きします。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.0</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>ai-custom-data-demo</artifactId> <version>0.0.1-SNAPSHOT</version> <name>AICustomData</name> <description>Demo project for Spring Boot</description> <properties> <java.version>17</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.experimental.ai</groupId> <artifactId>spring-ai-azure-openai-spring-boot-starter</artifactId> <version>0.7.0-SNAPSHOT</version> </dependency> <dependency> <groupId>com.azure</groupId> <artifactId>azure-search-documents</artifactId> <version>11.6.0-beta.10</version> <exclusions> <!-- exclude this to avoid changing the default serializer and the null-value behavior --> <exclusion> <groupId>com.azure</groupId> <artifactId>azure-core-serializer-json-jackson</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> <repositories> <repository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/snapshot</url> <releases> <enabled>false</enabled> </releases> </repository> </repositories> </project>src/main/java/com/example/aicustomdatademo フォルダーから、任意のエディターまたは IDE で AiCustomDataApplication.java を開き、次のコードを貼り付けます。
package com.example.aicustomdatademo; import java.util.Collections; import java.util.List; import java.util.Map; import java.util.Optional; import java.util.stream.Collectors; import org.springframework.ai.client.AiClient; import org.springframework.ai.document.Document; import org.springframework.ai.embedding.EmbeddingClient; import org.springframework.ai.prompt.Prompt; import org.springframework.ai.prompt.SystemPromptTemplate; import org.springframework.ai.prompt.messages.MessageType; import org.springframework.ai.prompt.messages.UserMessage; import org.springframework.ai.vectorstore.VectorStore; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.CommandLineRunner; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.Bean; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Context; import com.azure.search.documents.SearchClient; import com.azure.search.documents.SearchClientBuilder; import com.azure.search.documents.models.IndexingResult; import com.azure.search.documents.models.SearchOptions; import com.azure.search.documents.models.RawVectorQuery; import lombok.AllArgsConstructor; import lombok.NoArgsConstructor; import lombok.Builder; import lombok.Data; import lombok.extern.jackson.Jacksonized; @SpringBootApplication public class AiCustomDataApplication implements CommandLineRunner { private static final String ROLE_INFO_KEY = "role"; private static final String template = """ You are a helpful assistant. Use the information from the DOCUMENTS section to augment answers. DOCUMENTS: {documents} """; @Value("${spring.ai.azure.cognitive-search.endpoint}") private String acsEndpoint; @Value("${spring.ai.azure.cognitive-search.api-key}") private String acsApiKey; @Value("${spring.ai.azure.cognitive-search.index}") private String acsIndexName; @Autowired private AiClient aiClient; @Autowired private EmbeddingClient embeddingClient; public static void main(String[] args) { SpringApplication.run(AiCustomDataApplication.class, args); } @Override public void run(String... args) throws Exception { System.out.println(String.format("Sending custom data prompt to AI service. One moment please...\r\n")); final var store = vectorStore(embeddingClient); final String question = "What are my available health plans?"; final var candidateDocs = store.similaritySearch(question); final var userMessage = new UserMessage(question); final String docPrompts = candidateDocs.stream().map(entry -> entry.getContent()).collect(Collectors.joining("\n")); final SystemPromptTemplate promptTemplate = new SystemPromptTemplate(template); final var systemMessage = promptTemplate.createMessage(Map.of("documents", docPrompts)); final var prompt = new Prompt(List.of(systemMessage, userMessage)); final var resps = aiClient.generate(prompt); System.out.println(String.format("Prompt created %d generated response(s).", resps.getGenerations().size())); resps.getGenerations().stream() .forEach(gen -> { final var role = gen.getInfo().getOrDefault(ROLE_INFO_KEY, MessageType.ASSISTANT.getValue()); System.out.println(String.format("Generated respose from \"%s\": %s", role, gen.getText())); }); } @Bean public VectorStore vectorStore(EmbeddingClient embeddingClient) { final SearchClient searchClient = new SearchClientBuilder() .endpoint(acsEndpoint) .credential(new AzureKeyCredential(acsApiKey)) .indexName(acsIndexName) .buildClient(); return new AzureCognitiveSearchVectorStore(searchClient, embeddingClient); } public static class AzureCognitiveSearchVectorStore implements VectorStore { private static final int DEFAULT_TOP_K = 4; private static final Double DEFAULT_SIMILARITY_THRESHOLD = 0.0; private SearchClient searchClient; private final EmbeddingClient embeddingClient; public AzureCognitiveSearchVectorStore(SearchClient searchClient, EmbeddingClient embeddingClient) { this.searchClient = searchClient; this.embeddingClient = embeddingClient; } @Override public void add(List<Document> documents) { final var docs = documents.stream().map(document -> { final var embeddings = embeddingClient.embed(document); return new DocEntry(document.getId(), "", document.getContent(), embeddings); }).toList(); searchClient.uploadDocuments(docs); } @Override public Optional<Boolean> delete(List<String> idList) { final List<DocEntry> docIds = idList.stream().map(id -> DocEntry.builder().id(id).build()) .toList(); var results = searchClient.deleteDocuments(docIds); boolean resSuccess = true; for (IndexingResult result : results.getResults()) if (!result.isSucceeded()) { resSuccess = false; break; } return Optional.of(resSuccess); } @Override public List<Document> similaritySearch(String query) { return similaritySearch(query, DEFAULT_TOP_K); } @Override public List<Document> similaritySearch(String query, int k) { return similaritySearch(query, k, DEFAULT_SIMILARITY_THRESHOLD); } @Override public List<Document> similaritySearch(String query, int k, double threshold) { final var searchQueryVector = new RawVectorQuery() .setVector(toFloatList(embeddingClient.embed(query))) .setKNearestNeighborsCount(k) .setFields("contentVector"); final var searchResults = searchClient.search(null, new SearchOptions().setVectorQueries(searchQueryVector), Context.NONE); return searchResults.stream() .filter(r -> r.getScore() >= threshold) .map(r -> { final DocEntry entry = r.getDocument(DocEntry.class); final Document doc = new Document(entry.getId(), entry.getContent(), Collections.emptyMap()); doc.setEmbedding(entry.getContentVector()); return doc; }) .collect(Collectors.toList()); } private List<Float> toFloatList(List<Double> doubleList) { return doubleList.stream().map(Double::floatValue).toList(); } } @Data @Builder @Jacksonized @AllArgsConstructor @NoArgsConstructor static class DocEntry { private String id; private String hash; private String content; private List<Double> contentVector; } }重要
運用環境では、Azure Key Vault などの資格情報を格納してアクセスする安全な方法を使用します。 資格情報のセキュリティについて詳しくは、Azure AI サービスのセキュリティに関する記事をご覧ください。
プロジェクトのルート フォルダーに戻り、次のコマンドを使ってアプリを実行します:
./mvnw spring-boot:run
出力
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.1.5)
2023-11-07T14:40:45.250-06:00 INFO 18557 --- [ main] c.e.a.AiCustomDataApplication : No active profile set, falling back to 1 default profile: "default"
2023-11-07T14:40:46.035-06:00 INFO 18557 --- [ main] c.e.a.AiCustomDataApplication : Started AiCustomDataApplication in 1.095 seconds (process running for 1.397)
Sending custom data prompt to AI service. One moment please...
Prompt created 1 generated response(s).
Generated response from "assistant": The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans.
前提条件
Azure サブスクリプション。無料で作成できます。
Azure CLI をローカル開発環境でのパスワードレス認証に使用する場合は、Azure CLI でサインインして必要なコンテキストを作成します。
サポートされているリージョンにサポートされているモデルでデプロイされた Azure OpenAI リソース。
少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
リファレンスのドキュメント | ソース コード | パッケージ (NuGet) | サンプル
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。
[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。
必要な変数を取得する
Azure OpenAI の呼び出しを正しく行うには、次の変数が必要です。 このクイックスタートでは、Azure Blob Storage アカウントにデータをアップロードし、Azure AI Search インデックスを作成していることを前提としています。 Azure AI Studio を使用したデータの追加に関するページを参照してください。
| 変数名 | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 または、Azure AI Studio>[チャット プレイグラウンド]>[コード ビュー] で値を確認することもできます。 エンドポイントの例: https://my-resoruce.openai.azure.com。 |
AZURE_OPENAI_API_KEY |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[リソース管理]>[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 KEY1 または KEY2 を使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_OPENAI_DEPLOYMENT_ID |
この値は、モデルのデプロイ時にデプロイに対して選択したカスタム名に対応します。 この値は、Azure portal の [リソース管理]>[デプロイ] または Azure AI Studio の [管理]>[デプロイ] で確認できます。 |
AZURE_AI_SEARCH_ENDPOINT |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[概要]セクションで確認することができます。 |
AZURE_AI_SEARCH_API_KEY |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[設定]>[キー] セクションで確認することができます。 プライマリ管理者キーまたはセカンダリ管理者キーのいずれかを使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_AI_SEARCH_INDEX |
この値は、データを格納するために作成したインデックスの名前に対応します。 Azure portal から Azure AI Search リソースを調べる場合は、[概要] セクションで確認できます。 |
環境変数
キーとエンドポイントの永続的な環境変数を作成して割り当てます。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
setx AZURE_OPENAI_ENDPOINT REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
setx AZURE_OPENAI_API_KEY REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
setx AZURE_OPENAI_DEPLOYMENT_ID REPLACE_WITH_YOUR_AOAI_DEPLOYMENT_VALUE_HERE
setx AZURE_AI_SEARCH_ENDPOINT REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
setx AZURE_AI_SEARCH_API_KEY REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
setx AZURE_AI_SEARCH_INDEX REPLACE_WITH_YOUR_INDEX_NAME_HERE
Node.js アプリケーションを初期化する
コンソール ウィンドウ (cmd、PowerShell、Bash など) で、ご利用のアプリ用に新しいディレクトリを作成し、そこに移動します。 次に、npm init コマンドを実行し、package.json ファイルを使用してノード アプリケーションを作成します。
npm init
クライアント ライブラリをインストールする
npm を使用して、JavaScript 用の Azure OpenAI クライアントと Azure ID ライブラリをインストールします。
npm install @azure/openai @azure/identity
アプリの package.json ファイルは依存関係を含めて更新されます。
JavaScript コードを追加する
新しいプロジェクトを作成するコマンド プロンプトを開き、
ChatWithOwnData.jsという名前の新しいファイルを作成します。 次のコードをChatWithOwnData.jsファイルにコピーします。const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { AzureOpenAI } = require("openai"); // Set the Azure and AI Search values from environment variables const endpoint = process.env["AZURE_OPENAI_ENDPOINT"]; const searchEndpoint = process.env["AZURE_AI_SEARCH_ENDPOINT"]; const searchIndex = process.env["AZURE_AI_SEARCH_INDEX"]; // keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Required Azure OpenAI deployment name and API version const deploymentName = "gpt-4"; const apiVersion = "2024-07-01-preview"; function getClient() { return new AzureOpenAI({ endpoint, azureADTokenProvider, deployment: deploymentName, apiVersion, }); } async function main() { const client = getClient(); const messages = [ { role: "user", content: "What are my available health plans?" }, ]; console.log(`Message: ${messages.map((m) => m.content).join("\n")}`); const events = await client.chat.completions.create({ stream: true, messages: [ { role: "user", content: "What's the most common feedback we received from our customers about the product?", }, ], max_tokens: 128, model: "", data_sources: [ { type: "azure_search", parameters: { endpoint: searchEndpoint, index_name: searchIndex, authentication: { type: "api_key", key: searchKey, }, }, }, ], }); let response = ""; for await (const event of events) { for (const choice of event.choices) { const newText = choice.delta?.content; if (newText) { response += newText; // To see streaming results as they arrive, uncomment line below // console.log(newText); } } } console.log(response); } main().catch((err) => { console.error("The sample encountered an error:", err); });次のコマンドでアプリケーションを実行します。
node ChatWithOwnData.js
重要
運用環境では、Azure Key Vault などの資格情報を格納してアクセスする安全な方法を使用します。 資格情報のセキュリティについて詳しくは、Azure AI サービスのセキュリティに関する記事をご覧ください。
出力
Message: What are my available health plans?
The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans.
前提条件
Azure サブスクリプション。無料で作成できます。
Azure CLI をローカル開発環境でのパスワードレス認証に使用する場合は、Azure CLI でサインインして必要なコンテキストを作成します。
サポートされているリージョンにサポートされているモデルでデプロイされた Azure OpenAI リソース。
少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
リファレンスのドキュメント | ソース コード | パッケージ (NuGet) | サンプル
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。
[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。
必要な変数を取得する
Azure OpenAI の呼び出しを正しく行うには、次の変数が必要です。 このクイックスタートでは、Azure Blob Storage アカウントにデータをアップロードし、Azure AI Search インデックスを作成していることを前提としています。 Azure AI Studio を使用したデータの追加に関するページを参照してください。
| 変数名 | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 または、Azure AI Studio>[チャット プレイグラウンド]>[コード ビュー] で値を確認することもできます。 エンドポイントの例: https://my-resoruce.openai.azure.com。 |
AZURE_OPENAI_API_KEY |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[リソース管理]>[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 KEY1 または KEY2 を使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_OPENAI_DEPLOYMENT_ID |
この値は、モデルのデプロイ時にデプロイに対して選択したカスタム名に対応します。 この値は、Azure portal の [リソース管理]>[デプロイ] または Azure AI Studio の [管理]>[デプロイ] で確認できます。 |
AZURE_AI_SEARCH_ENDPOINT |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[概要]セクションで確認することができます。 |
AZURE_AI_SEARCH_API_KEY |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[設定]>[キー] セクションで確認することができます。 プライマリ管理者キーまたはセカンダリ管理者キーのいずれかを使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_AI_SEARCH_INDEX |
この値は、データを格納するために作成したインデックスの名前に対応します。 Azure portal から Azure AI Search リソースを調べる場合は、[概要] セクションで確認できます。 |
環境変数
キーとエンドポイントの永続的な環境変数を作成して割り当てます。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
setx AZURE_OPENAI_ENDPOINT REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
setx AZURE_OPENAI_API_KEY REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
setx AZURE_OPENAI_DEPLOYMENT_ID REPLACE_WITH_YOUR_AOAI_DEPLOYMENT_VALUE_HERE
setx AZURE_AI_SEARCH_ENDPOINT REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
setx AZURE_AI_SEARCH_API_KEY REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
setx AZURE_AI_SEARCH_INDEX REPLACE_WITH_YOUR_INDEX_NAME_HERE
Node.js アプリケーションを初期化する
コンソール ウィンドウ (cmd、PowerShell、Bash など) で、ご利用のアプリ用に新しいディレクトリを作成し、そこに移動します。 次に、npm init コマンドを実行し、package.json ファイルを使用してノード アプリケーションを作成します。
npm init
クライアント ライブラリをインストールする
npm を使用して、JavaScript 用の Azure OpenAI クライアントと Azure ID ライブラリをインストールします。
npm install openai @azure/identity @azure/openai
@azure/openai/types 依存関係は、data_sources プロパティの Azure OpenAI モデルを拡張するために含まれています。 このインポートは TypeScript でのみ必要です。
アプリの package.json ファイルは依存関係を含めて更新されます。
TypeScript コードを追加する
新しいプロジェクトを作成するコマンド プロンプトを開き、
ChatWithOwnData.tsという名前の新しいファイルを作成します。 次のコードをChatWithOwnData.tsファイルにコピーします。import { AzureOpenAI } from "openai"; import { DefaultAzureCredential, getBearerTokenProvider } from "@azure/identity"; import "@azure/openai/types"; // Set the Azure and AI Search values from environment variables const endpoint = process.env["AZURE_OPENAI_ENDPOINT"]; const searchEndpoint = process.env["AZURE_AI_SEARCH_ENDPOINT"]; const searchIndex = process.env["AZURE_AI_SEARCH_INDEX"]; // keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Required Azure OpenAI deployment name and API version const deploymentName = "gpt-4"; const apiVersion = "2024-07-01-preview"; function getClient(): AzureOpenAI { return new AzureOpenAI({ endpoint, azureADTokenProvider, deployment: deploymentName, apiVersion, }); } async function main() { const client = getClient(); const messages = [ { role: "user", content: "What are my available health plans?" }, ]; console.log(`Message: ${messages.map((m) => m.content).join("\n")}`); const events = await client.chat.completions.create({ stream: true, messages: [ { role: "user", content: "What's the most common feedback we received from our customers about the product?", }, ], max_tokens: 128, model: "", data_sources: [ { type: "azure_search", parameters: { endpoint: searchEndpoint, index_name: searchIndex, authentication: { type: "api_key", key: searchKey, }, }, }, ], }); let response = ""; for await (const event of events) { for (const choice of event.choices) { const newText = choice.delta?.content; if (newText) { response += newText; // To see streaming results as they arrive, uncomment line below // console.log(newText); } } } console.log(response); } main().catch((err) => { console.error("The sample encountered an error:", err); });次のコマンドでアプリケーションをビルドします。
tsc次のコマンドでアプリケーションを実行します。
node ChatWithOwnData.js
重要
運用環境では、Azure Key Vault などの資格情報を格納してアクセスする安全な方法を使用します。 資格情報のセキュリティについて詳しくは、Azure AI サービスのセキュリティに関する記事をご覧ください。
出力
Message: What are my available health plans?
The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans.
前提条件
次のリソース:
- Azure OpenAI
- Azure Blob Storage
- Azure AI Search
- サポート対象のリージョンに、サポートされているモデルでデプロイされた Azure OpenAI リソース。
- 少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
- 独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
参照 | ソース コード | パッケージ (pypi) | サンプル
これらのリンクは、OpenAI API for Python を参照しています。 Azure 固有の OpenAI Python SDK はありません。 OpenAI サービスと Azure OpenAI サービスを切り替える方法の詳細については、こちらを参照してください。
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。
[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。
必要な変数を取得する
Azure OpenAI の呼び出しを正しく行うには、次の変数が必要です。 このクイックスタートでは、Azure Blob Storage アカウントにデータをアップロードし、Azure AI Search インデックスを作成していることを前提としています。 Azure AI Studio を使用したデータの追加に関するページを参照してください。
| 変数名 | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 または、Azure AI Studio>[チャット プレイグラウンド]>[コード ビュー] で値を確認することもできます。 エンドポイントの例: https://my-resoruce.openai.azure.com。 |
AZURE_OPENAI_API_KEY |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[リソース管理]>[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 KEY1 または KEY2 を使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_OPENAI_DEPLOYMENT_ID |
この値は、モデルのデプロイ時にデプロイに対して選択したカスタム名に対応します。 この値は、Azure portal の [リソース管理]>[デプロイ] または Azure AI Studio の [管理]>[デプロイ] で確認できます。 |
AZURE_AI_SEARCH_ENDPOINT |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[概要]セクションで確認することができます。 |
AZURE_AI_SEARCH_API_KEY |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[設定]>[キー] セクションで確認することができます。 プライマリ管理者キーまたはセカンダリ管理者キーのいずれかを使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_AI_SEARCH_INDEX |
この値は、データを格納するために作成したインデックスの名前に対応します。 Azure portal から Azure AI Search リソースを調べる場合は、[概要] セクションで確認できます。 |
環境変数
キーとエンドポイントの永続的な環境変数を作成して割り当てます。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
setx AZURE_OPENAI_ENDPOINT REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
setx AZURE_OPENAI_API_KEY REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
setx AZURE_OPENAI_DEPLOYMENT_ID REPLACE_WITH_YOUR_AOAI_DEPLOYMENT_VALUE_HERE
setx AZURE_AI_SEARCH_ENDPOINT REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
setx AZURE_AI_SEARCH_API_KEY REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
setx AZURE_AI_SEARCH_INDEX REPLACE_WITH_YOUR_INDEX_NAME_HERE
Python 環境の作成
- プロジェクト用の openai-python という名前の新しいフォルダーと、main.py という名前の新しい Python コード ファイルを作成します。 そのディレクトリに変更します。
mkdir openai-python
cd openai-python
- 次の Python ライブラリをインストールします。
pip install openai
pip install python-dotenv
Python アプリを作成する
- プロジェクト ディレクトリから、main.py ファイルを開いて、次のコードを追加します。
import os
import openai
import dotenv
dotenv.load_dotenv()
endpoint = os.environ.get("AZURE_OPENAI_ENDPOINT")
api_key = os.environ.get("AZURE_OPENAI_API_KEY")
deployment = os.environ.get("AZURE_OPENAI_DEPLOYMENT_ID")
client = openai.AzureOpenAI(
azure_endpoint=endpoint,
api_key=api_key,
api_version="2024-02-01",
)
completion = client.chat.completions.create(
model=deployment,
messages=[
{
"role": "user",
"content": "What are my available health plans?",
},
],
extra_body={
"data_sources":[
{
"type": "azure_search",
"parameters": {
"endpoint": os.environ["AZURE_AI_SEARCH_ENDPOINT"],
"index_name": os.environ["AZURE_AI_SEARCH_INDEX"],
"authentication": {
"type": "api_key",
"key": os.environ["AZURE_AI_SEARCH_API_KEY"],
}
}
}
],
}
)
print(completion.model_dump_json(indent=2))
重要
運用環境では、Azure Key Vault などの資格情報を格納してアクセスする安全な方法を使用します。 資格情報のセキュリティについて詳しくは、Azure AI サービスのセキュリティに関する記事をご覧ください。
- 次のコマンドを実行します。
python main.py
このアプリケーションは、多くのシナリオで使用するのに適した JSON 形式で応答を出力します。 これには、クエリに対する回答とアップロードされたファイルからの引用の両方が含まれます。
前提条件
次のリソース:
- Azure OpenAI
- Azure Blob Storage
- Azure AI Search
- サポート対象のリージョンに、サポートされているモデルでデプロイされた Azure OpenAI リソース。
- 少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
- 独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。
[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。
必要な変数を取得する
Azure OpenAI の呼び出しを正しく行うには、次の変数が必要です。 このクイックスタートでは、Azure Blob Storage アカウントにデータをアップロードし、Azure AI Search インデックスを作成していることを前提としています。 Azure AI Studio を使用したデータの追加に関するページを参照してください。
| 変数名 | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 または、Azure AI Studio>[チャット プレイグラウンド]>[コード ビュー] で値を確認することもできます。 エンドポイントの例: https://my-resoruce.openai.azure.com。 |
AZURE_OPENAI_API_KEY |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[リソース管理]>[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 KEY1 または KEY2 を使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_OPENAI_DEPLOYMENT_ID |
この値は、モデルのデプロイ時にデプロイに対して選択したカスタム名に対応します。 この値は、Azure portal の [リソース管理]>[デプロイ] または Azure AI Studio の [管理]>[デプロイ] で確認できます。 |
AZURE_AI_SEARCH_ENDPOINT |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[概要]セクションで確認することができます。 |
AZURE_AI_SEARCH_API_KEY |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[設定]>[キー] セクションで確認することができます。 プライマリ管理者キーまたはセカンダリ管理者キーのいずれかを使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_AI_SEARCH_INDEX |
この値は、データを格納するために作成したインデックスの名前に対応します。 Azure portal から Azure AI Search リソースを調べる場合は、[概要] セクションで確認できます。 |
環境変数
キーとエンドポイントの永続的な環境変数を作成して割り当てます。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
setx AZURE_OPENAI_ENDPOINT REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
setx AZURE_OPENAI_API_KEY REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
setx AZURE_OPENAI_DEPLOYMENT_ID REPLACE_WITH_YOUR_AOAI_DEPLOYMENT_VALUE_HERE
setx AZURE_AI_SEARCH_ENDPOINT REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
setx AZURE_AI_SEARCH_API_KEY REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
setx AZURE_AI_SEARCH_INDEX REPLACE_WITH_YOUR_INDEX_NAME_HERE
PowerShell コマンドの例
Azure OpenAI チャット モデルは、会話形式の入力を処理するように最適化されています。 messages 変数は、システム、ユーザー、ツール、アシスタントによって示された会話内のさまざまなロールを持つディクショナリの配列を渡します。 dataSources 変数は Azure Cognitive Search インデックスに接続し、Azure OpenAI モデルがデータを使用して応答できるようにします。
モデルからの応答をトリガーするには、アシスタントが応答する番であることを示すユーザー メッセージで終了する必要があります。
ヒント
temperature や top_p など、モデルの応答を変更するために使用できるパラメーターがいくつかあります。 詳しくは、リファレンス ドキュメントをご覧ください。
# Azure OpenAI metadata variables
$openai = @{
api_key = $Env:AZURE_OPENAI_API_KEY
api_base = $Env:AZURE_OPENAI_ENDPOINT # your endpoint should look like the following https://YOUR_RESOURCE_NAME.openai.azure.com/
api_version = '2023-07-01-preview' # this may change in the future
name = 'YOUR-DEPLOYMENT-NAME-HERE' #This will correspond to the custom name you chose for your deployment when you deployed a model.
}
$acs = @{
search_endpoint = 'YOUR ACS ENDPOINT' # your endpoint should look like the following https://YOUR_RESOURCE_NAME.search.windows.net/
search_key = 'YOUR-ACS-KEY-HERE' # or use the Get-Secret cmdlet to retrieve the value
search_index = 'YOUR-INDEX-NAME-HERE' # the name of your ACS index
}
# Completion text
$body = @{
dataSources = @(
@{
type = 'AzureCognitiveSearch'
parameters = @{
endpoint = $acs.search_endpoint
key = $acs.search_key
indexName = $acs.search_index
}
}
)
messages = @(
@{
role = 'user'
content = 'What are my available health plans?'
}
)
} | convertto-json -depth 5
# Header for authentication
$headers = [ordered]@{
'api-key' = $openai.api_key
}
# Send a completion call to generate an answer
$url = "$($openai.api_base)/openai/deployments/$($openai.name)/extensions/chat/completions?api-version=$($openai.api_version)"
$response = Invoke-RestMethod -Uri $url -Headers $headers -Body $body -Method Post -ContentType 'application/json'
return $response.choices.messages[1].content
出力例
The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans.
重要
運用環境では、Azure Key Valut を使用した PowerShell Secret Management のような安全な方法で認証情報を保存し、アクセスしてください。 資格情報のセキュリティについて詳しくは、Azure AI サービスのセキュリティに関する記事をご覧ください。
Web アプリを使用してモデルとチャットする
データを使用する Azure OpenAI モデルとのチャットを開始するには、Azure OpenAI studio または GitHub で提供 されているサンプル コードを使用して Web アプリをデプロイします。 このアプリは、Azure App Service を使用してデプロイされます。これにより、クエリを送信するためのユーザー インターフェイスが提供されます。 このアプリは、データを使用する Azure OpenAI モデル、またはデータを使用しないモデルで使用できます。 要件、セットアップ、デプロイの手順については、リポジトリ内の readme ファイルを参照してください。 必要に応じて、ソース コードを変更することで、Web アプリのフロントエンドとバックエンドのロジックをカスタマイズできます。
前提条件
次のリソース:
- Azure OpenAI
- Azure Blob Storage
- Azure AI Search
- サポート対象のリージョンに、サポートされているモデルでデプロイされた Azure OpenAI リソース。
- 少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
- 独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
参照 | ソース コード | パッケージ (Go) | サンプル
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。
[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。
必要な変数を取得する
Azure OpenAI の呼び出しを正しく行うには、次の変数が必要です。 このクイックスタートでは、Azure Blob Storage アカウントにデータをアップロードし、Azure AI Search インデックスを作成していることを前提としています。 Azure AI Studio を使用したデータの追加に関するページを参照してください。
| 変数名 | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 または、Azure AI Studio>[チャット プレイグラウンド]>[コード ビュー] で値を確認することもできます。 エンドポイントの例: https://my-resoruce.openai.azure.com。 |
AZURE_OPENAI_API_KEY |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[リソース管理]>[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 KEY1 または KEY2 を使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_OPENAI_DEPLOYMENT_ID |
この値は、モデルのデプロイ時にデプロイに対して選択したカスタム名に対応します。 この値は、Azure portal の [リソース管理]>[デプロイ] または Azure AI Studio の [管理]>[デプロイ] で確認できます。 |
AZURE_AI_SEARCH_ENDPOINT |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[概要]セクションで確認することができます。 |
AZURE_AI_SEARCH_API_KEY |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[設定]>[キー] セクションで確認することができます。 プライマリ管理者キーまたはセカンダリ管理者キーのいずれかを使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_AI_SEARCH_INDEX |
この値は、データを格納するために作成したインデックスの名前に対応します。 Azure portal から Azure AI Search リソースを調べる場合は、[概要] セクションで確認できます。 |
環境変数
キーとエンドポイントの永続的な環境変数を作成して割り当てます。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
setx AZURE_OPENAI_ENDPOINT REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
setx AZURE_OPENAI_API_KEY REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
setx AZURE_OPENAI_DEPLOYMENT_ID REPLACE_WITH_YOUR_AOAI_DEPLOYMENT_VALUE_HERE
setx AZURE_AI_SEARCH_ENDPOINT REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
setx AZURE_AI_SEARCH_API_KEY REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
setx AZURE_AI_SEARCH_INDEX REPLACE_WITH_YOUR_INDEX_NAME_HERE
Go 環境を作成する
プロジェクト用の openai-go という名前の新しいフォルダーと、sample.go という名前の新しい Go コード ファイルを作成します。 そのディレクトリに変更します。
mkdir openai-go cd openai-go次の Go パッケージをインストールします。
go get github.com/Azure/azure-sdk-for-go/sdk/ai/azopenaiコードの依存関係追跡を有効にします。
go mod init example/azure-openai
Go アプリを作成する
プロジェクト ディレクトリから、sample.go ファイルを開いて、次のコードを追加します。
package main import ( "context" "fmt" "log" "os" "github.com/Azure/azure-sdk-for-go/sdk/ai/azopenai" "github.com/Azure/azure-sdk-for-go/sdk/azcore" "github.com/Azure/azure-sdk-for-go/sdk/azcore/to" ) func main() { azureOpenAIKey := os.Getenv("AZURE_OPENAI_API_KEY") modelDeploymentID := os.Getenv("AZURE_OPENAI_DEPLOYMENT_ID") // Ex: "https://<your-azure-openai-host>.openai.azure.com" azureOpenAIEndpoint := os.Getenv("AZURE_OPENAI_ENDPOINT") // Azure AI Search configuration searchIndex := os.Getenv("AZURE_AI_SEARCH_INDEX") searchEndpoint := os.Getenv("AZURE_AI_SEARCH_ENDPOINT") searchAPIKey := os.Getenv("AZURE_AI_SEARCH_API_KEY") if azureOpenAIKey == "" || modelDeploymentID == "" || azureOpenAIEndpoint == "" || searchIndex == "" || searchEndpoint == "" || searchAPIKey == "" { fmt.Fprintf(os.Stderr, "Skipping example, environment variables missing\n") return } keyCredential := azcore.NewKeyCredential(azureOpenAIKey) // In Azure OpenAI you must deploy a model before you can use it in your client. For more information // see here: https://learn.microsoft.com/azure/cognitive-services/openai/how-to/create-resource client, err := azopenai.NewClientWithKeyCredential(azureOpenAIEndpoint, keyCredential, nil) if err != nil { // TODO: Update the following line with your application specific error handling logic log.Fatalf("ERROR: %s", err) } resp, err := client.GetChatCompletions(context.TODO(), azopenai.ChatCompletionsOptions{ Messages: []azopenai.ChatRequestMessageClassification{ &azopenai.ChatRequestUserMessage{Content: azopenai.NewChatRequestUserMessageContent("What are my available health plans?")}, }, MaxTokens: to.Ptr[int32](512), AzureExtensionsOptions: []azopenai.AzureChatExtensionConfigurationClassification{ &azopenai.AzureSearchChatExtensionConfiguration{ // This allows Azure OpenAI to use an Azure AI Search index. // // > Because the model has access to, and can reference specific sources to support its responses, answers are not only based on its pretrained knowledge // > but also on the latest information available in the designated data source. This grounding data also helps the model avoid generating responses // > based on outdated or incorrect information. // // Quote from here: https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/use-your-data Parameters: &azopenai.AzureSearchChatExtensionParameters{ Endpoint: &searchEndpoint, IndexName: &searchIndex, Authentication: &azopenai.OnYourDataAPIKeyAuthenticationOptions{ Key: &searchAPIKey, }, }, }, }, DeploymentName: &modelDeploymentID, }, nil) if err != nil { // TODO: Update the following line with your application specific error handling logic log.Fatalf("ERROR: %s", err) } fmt.Fprintf(os.Stderr, "Extensions Context Role: %s\nExtensions Context (length): %d\n", *resp.Choices[0].Message.Role, len(*resp.Choices[0].Message.Content)) fmt.Fprintf(os.Stderr, "ChatRole: %s\nChat content: %s\n", *resp.Choices[0].Message.Role, *resp.Choices[0].Message.Content, ) }重要
運用環境では、Azure Key Vault などの資格情報を格納してアクセスする安全な方法を使用します。 資格情報のセキュリティについて詳しくは、Azure AI サービスのセキュリティに関する記事をご覧ください。
次のコマンドを実行します。
go run sample.goこのアプリケーションは、クエリに対する回答とアップロードされたファイルからの引用の両方を含む応答を出力します。
前提条件
次のリソース:
- Azure OpenAI
- Azure Blob Storage
- Azure AI Search
- サポート対象のリージョンに、サポートされているモデルでデプロイされた Azure OpenAI リソース。
- 少なくとも Azure OpenAI リソースに対する Cognitive Services 共同作成者ロールが割り当てられていることを確認してください。
- 独自のデータがない場合は、GitHub からサンプル データをダウンロードします。
Azure OpenAI Studio を使用してデータを追加する
ヒント
Azure Developer CLI を使用して、Azure OpenAI On Your Data に必要なリソースをプログラムで作成できます
Azure AI Studio に移動し、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
[プロジェクトの作成] をクリックして AI Studio プロジェクトを作成するか、または [Azure OpenAI Service を重視する] タイルのボタンをクリックして直接続行できます。
左側ナビゲーション メニューの [プレイグラウンド] の下にある [チャット] を選択し、モデル デプロイを選択します。
[チャット プレイグラウンド] で、[データの追加] を選んでから、[データ ソースの追加] を選びます
表示されたウィンドウで、[データ ソースの選択] の [ファイルのアップロード (プレビュー)] を選択します。 Azure OpenAI では、データにアクセスしてインデックスを付けるために、ストレージ リソースと検索リソースの両方が必要です。
ヒント
- 詳細については、次のリソースを参照してください。
- 長いテキストを含むドキュメントとデータセットの場合は、使用可能な データ準備スクリプトを使用することをお勧めします。
Azure OpenAI がストレージ アカウントにアクセスするには、クロス オリジン リソース共有 (CORS) を有効にする必要があります。 Azure Blob Storage リソースに対して CORS がまだ有効になっていない場合は、[CORS を有効にする] を選択します。
ご自分の Azure AI Search リソースを選択し、接続するとアカウントで使用量が発生することの確認を選択します。 [次へ] を選択します。
[ファイルのアップロード] ウィンドウで、[ファイルの参照] を選択し、[前提条件] セクションからダウンロードしたファイルを選択するか、独自のデータを選択します。 その後、[ファイルのアップロード] を選択します。 [次へ] を選択します。
[データ管理] ウィンドウで、インデックスのセマンティック検索とベクター検索のどちらを有効にするかを選択できます。
入力した詳細を確認し、[保存して閉じる] を選択します。 これでモデルとチャットできるようになり、データからの情報を使用して応答が作成されます。
必要な変数を取得する
Azure OpenAI の呼び出しを正しく行うには、次の変数が必要です。 このクイックスタートでは、Azure Blob Storage アカウントにデータをアップロードし、Azure AI Search インデックスを作成していることを前提としています。 Azure AI Studio を使用したデータの追加に関するページを参照してください。
| 変数名 | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 または、Azure AI Studio>[チャット プレイグラウンド]>[コード ビュー] で値を確認することもできます。 エンドポイントの例: https://my-resoruce.openai.azure.com。 |
AZURE_OPENAI_API_KEY |
この値は、Azure portal から Azure OpenAI リソースを確認する際に、[リソース管理]>[Keys & Endpoint] (キーとエンドポイント) セクションで確認できます。 KEY1 または KEY2 を使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_OPENAI_DEPLOYMENT_ID |
この値は、モデルのデプロイ時にデプロイに対して選択したカスタム名に対応します。 この値は、Azure portal の [リソース管理]>[デプロイ] または Azure AI Studio の [管理]>[デプロイ] で確認できます。 |
AZURE_AI_SEARCH_ENDPOINT |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[概要]セクションで確認することができます。 |
AZURE_AI_SEARCH_API_KEY |
この値は、Azure portal から Azure AI Search リソースを確認する際に、[設定]>[キー] セクションで確認することができます。 プライマリ管理者キーまたはセカンダリ管理者キーのいずれかを使用できます。 常に 2 つのキーを用意しておくと、サービスを中断させることなく、キーのローテーションと再生成を安全に行うことができます。 |
AZURE_AI_SEARCH_INDEX |
この値は、データを格納するために作成したインデックスの名前に対応します。 Azure portal から Azure AI Search リソースを調べる場合は、[概要] セクションで確認できます。 |
環境変数
キーとエンドポイントの永続的な環境変数を作成して割り当てます。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
setx AZURE_OPENAI_ENDPOINT REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
setx AZURE_OPENAI_API_KEY REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
setx AZURE_OPENAI_DEPLOYMENT_ID REPLACE_WITH_YOUR_AOAI_DEPLOYMENT_VALUE_HERE
setx AZURE_AI_SEARCH_ENDPOINT REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
setx AZURE_AI_SEARCH_API_KEY REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
setx AZURE_AI_SEARCH_INDEX REPLACE_WITH_YOUR_INDEX_NAME_HERE
cURL コマンドの例
Azure OpenAI チャット モデルは、会話形式の入力を処理するように最適化されています。 messages 変数は、システム、ユーザー、ツール、アシスタントによって示された会話内のさまざまなロールを持つディクショナリの配列を渡します。 dataSources 変数は Azure AI Search インデックスに接続し、Azure OpenAI モデルがデータを使用して応答できるようにします。
モデルからの応答をトリガーするには、アシスタントが応答する番であることを示すユーザー メッセージで終了する必要があります。
ヒント
temperature や top_p など、モデルの応答を変更するために使用できるパラメーターがいくつかあります。 詳しくは、リファレンス ドキュメントをご覧ください。
curl -i -X POST $AZURE_OPENAI_ENDPOINT/openai/deployments/$AZURE_OPENAI_DEPLOYMENT_ID/chat/completions?api-version=2024-02-15-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d \
'
{
"data_sources": [
{
"type": "azure_search",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"index_name": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are my available health plans?"
}
]
}
'
出力例
{
"id": "12345678-1a2b-3c4e5f-a123-12345678abcd",
"model": "gpt-4",
"created": 1709835345,
"object": "extensions.chat.completion",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans. [doc1].",
"end_turn": true,
"context": {
"citations": [
{
"content": "...",
"title": "...",
"url": "https://mysearch.blob.core.windows.net/xyz/001.txt",
"filepath": "001.txt",
"chunk_id": "0"
}
],
"intent": "[\"Available health plans\"]"
}
}
}
],
"usage": {
"prompt_tokens": 3779,
"completion_tokens": 105,
"total_tokens": 3884
}
}
Web アプリを使用してモデルとチャットする
データを使用する Azure OpenAI モデルとのチャットを開始するには、Azure OpenAI studio または GitHub で提供 されているサンプル コードを使用して Web アプリをデプロイします。 このアプリは、Azure App Service を使用してデプロイされます。これにより、クエリを送信するためのユーザー インターフェイスが提供されます。 このアプリは、データを使用する Azure OpenAI モデル、またはデータを使用しないモデルで使用できます。 要件、セットアップ、デプロイの手順については、リポジトリ内の readme ファイルを参照してください。 必要に応じて、ソース コードを変更することで、Web アプリのフロントエンドとバックエンドのロジックをカスタマイズできます。
リソースをクリーンアップする
Azure OpenAI リソースまたは Azure AI Search リソースをクリーンアップして削除する場合は、リソースまたはリソース グループを削除します。 リソース グループを削除すると、それに関連付けられている他のリソースも削除されます。
次の手順
- Azure OpenAI Service でのデータの使用に関する詳細を確認します。
- GitHub 上のチャット アプリのサンプル コード。