Azure OpenAI の保存された入力候補および蒸留 (プレビュー)
保存された入力候補を利用すると、チャット入力候補セッションから会話履歴をキャプチャして、評価と微調整のためのデータセットとして使用できます。
保存された入力候補のサポート
API のサポート
サポートは最初に 2024-10-01-preview に追加されました
モデルと利用可能なリージョン
| リージョン | o1-preview、2024-09-12 | o1-mini、2024-09-12 | gpt-4o、2024-08-06 | gpt-4o、2024 年 5 月 13 日 | gpt-4o-mini、2024-07-18 |
|---|---|---|---|---|---|
| スウェーデン中部 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 米国中北部 | - | - | ✅ | - | - |
| 米国東部 2 | - | - | ✅ | - | - |
保存された入力候補を構成する
Azure OpenAI デプロイに対して保存された入力候補を有効にするには、store パラメーターを True に設定します。 保存された入力候補データセットを追加情報でエンリッチするには、metadata パラメーターを使用します。
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-01-preview"
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
保存された入力候補が Azure OpenAI デプロイに対して有効になると、Azure AI Foundry ポータルの [保存された入力候補] ウィンドウに表示されるようになります。

蒸留
蒸留を使用すると、保存された入力候補を微調整データセットに変えることができます。 一般的なユース ケースは、特定のタスクに対してより大きくより強力なモデルで保存された入力候補を使用してから、保存された入力候補を使用して、モデル対話の高品質な例で小さいモデルをトレーニングすることです。
蒸留には少なくとも 10 個の保存された入力候補が必要ですが、最適な結果を得るには、数百から数千の保存された入力候補を提供することをお勧めします。
Azure AI Foundry ポータルの [保存された入力候補] ウィンドウで、[フィルター] オプションを使用して、モデルのトレーニングに使用する入力候補を選択します。
蒸留を開始するには、[Distill]\(蒸留\) を選択します
![[蒸留] が強調表示された、保存された入力候補ユーザー エクスペリエンスのスクリーンショット。](../media/stored-completions/distill.png)
保存された入力候補データセットで微調整するモデルを選択します。
微調整するモデルのバージョンを確認します。
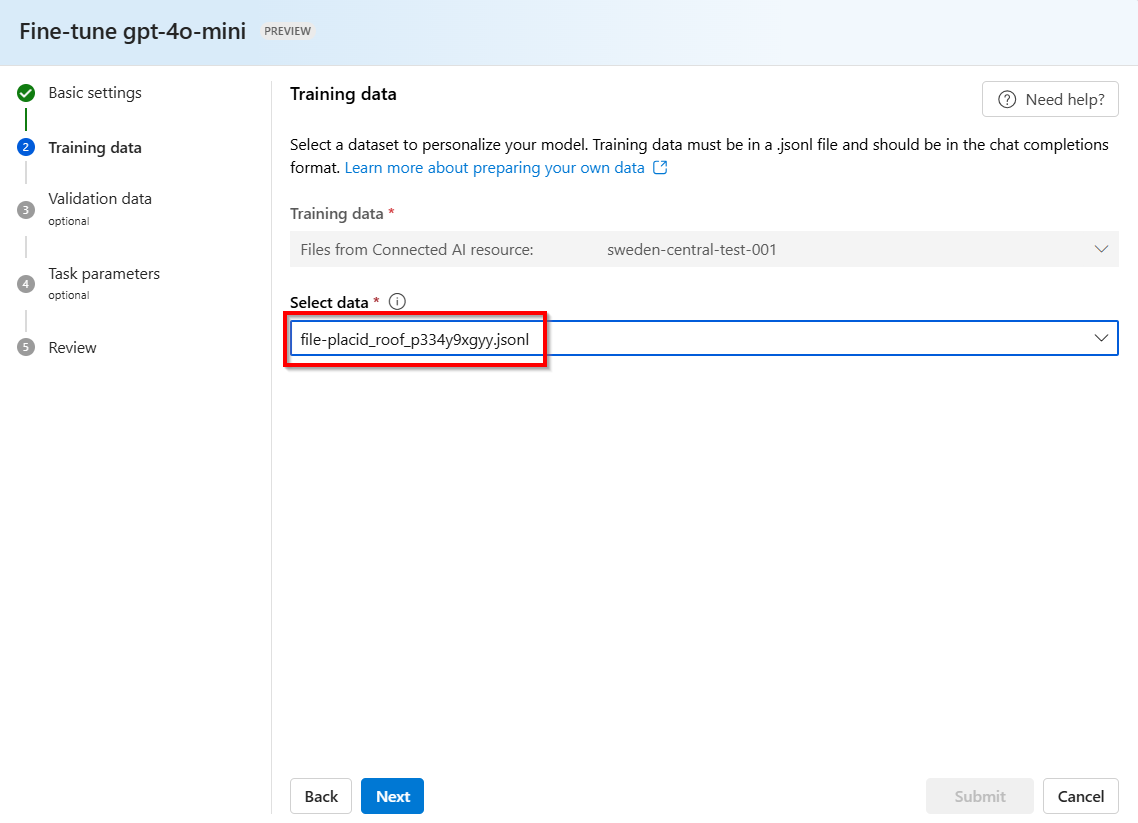
ランダムに生成された名前を持つ
.jsonlファイルが、保存された入力候補からトレーニング データセットとして作成されます。 ファイル >[次へ] を選択します。Note
保存された入力候補の蒸留トレーニング ファイルに直接アクセスすることはできません。外部にエクスポートまたはダウンロードすることもできません。
![[蒸留] が強調表示された、保存された入力候補ユーザー エクスペリエンスのスクリーンショット。](../media/stored-completions/distill.png#lightbox)



残りの手順は、一般的な Azure OpenAI の微調整手順に対応しています。 詳細については、微調整のファースト ステップ ガイドを参照してください。
評価
大規模な言語モデルの評価は、さまざまなタスクとディメンションのパフォーマンスを測定する上で重要なステップです。 これは、トレーニングによるパフォーマンスの向上 (または損失) を評価することが重要な微調整されたモデルでは特に重要です。 徹底的な評価は、さまざまなバージョンのモデルがアプリケーションまたはシナリオに与える影響を理解するのに役立ちます。
保存された入力候補は、評価を実行するためのデータセットとして使用できます。
Azure AI Foundry ポータルの [保存された入力候補] ウィンドウで、[フィルター] オプションを使用して、評価データ・セットに含める入力候補を選択します。
評価を構成するには、[評価] を選択します。
![[評価] が選択されている、保存された入力候補ウィンドウのスクリーンショット。](../media/stored-completions/evaluate.png)
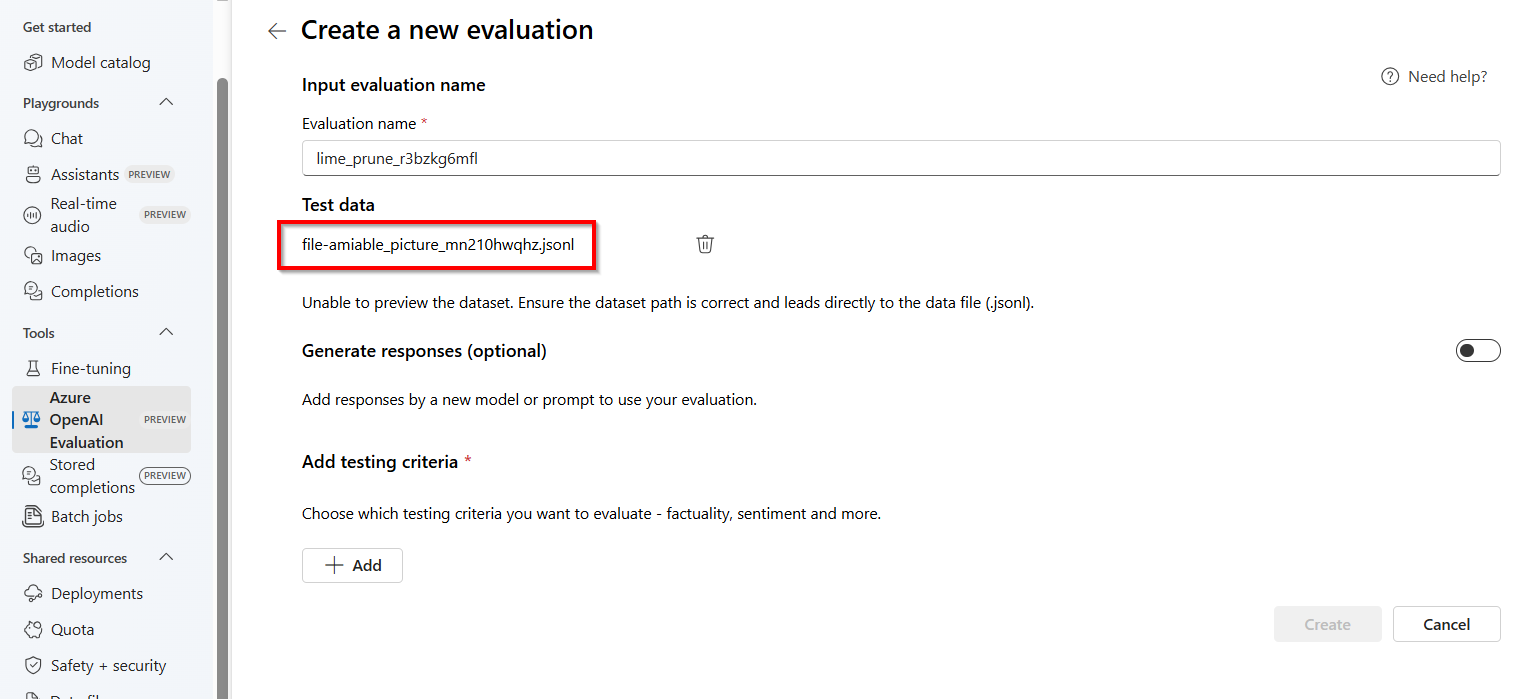
これにより、[評価] ウィンドウが起動します。ランダムに生成された名前を持つ事前に設定された
.jsonlファイルが、保存された入力候補から評価データセットとして作成されています。Note
保存された入力候補の評価データ ファイルに直接アクセスすることはできません。外部にエクスポートまたはダウンロードすることもできません。
![[評価] が選択されている、保存された入力候補ウィンドウのスクリーンショット。](../media/stored-completions/evaluate.png#lightbox)

評価の詳細については、評価の概要に関するページを参照してください。
トラブルシューティング
保存された入力候補を使用するには、特別なアクセス許可が必要ですか?
保存された入力候補へのアクセスは、次の 2 つの DataActions によって制御されます。
Microsoft.CognitiveServices/accounts/OpenAI/stored-completions/readMicrosoft.CognitiveServices/accounts/OpenAI/stored-completions/action
既定では、Cognitive Services OpenAI Contributor はこれらの両方のアクセス許可にアクセスできます。

保存されたデータを削除するにはどうすればよいですか?
関連付けられている Azure OpenAI リソースを削除することで、データを削除できます。 保存された入力候補データのみを削除する場合は、カスタマーサポートでケースを開く必要があります。
どのくらいの量の保存された入力候補データを保存できますか?
最大 10 GB のデータを保存できます。
保存された入力候補がサブスクリプションで有効にならないようにすることができますか?
保存された入力候補をサブスクリプション レベルで無効にするには、カスタマーサポートでケースを開く必要があります。
TypeError: Completions.create() got an unexpected argument 'store' (TypeError: Completions.create() で予期しない引数 'store' を取得しました)
このエラーが発生するのは、保存された入力候補機能がリリースされる前の古いバージョンの OpenAI クライアント ライブラリを実行している場合です。
pip install openai --upgrade を実行します。