Azure OpenAI 評価 (プレビュー)
大規模な言語モデルの評価は、さまざまなタスクとディメンションのパフォーマンスを測定する上で重要なステップです。 これは、トレーニングによるパフォーマンスの向上 (または損失) を評価することが重要な微調整されたモデルでは特に重要です。 徹底的な評価は、さまざまなバージョンのモデルがアプリケーションまたはシナリオに与える影響を理解するのに役立ちます。
Azure OpenAI 評価を使用すると、開発者は、予想される入力/出力ペアをテストするために実行する評価を作成し、精度、信頼性、全体的なパフォーマンスなどの主要なメトリック間でモデルのパフォーマンスを評価できます。
評価のサポート
リージョン別の提供状況
- 米国東部 2
- 米国中北部
- スウェーデン中部
- スイス西部
サポートされるデプロイの種類
- Standard
- グローバル標準
- データ ゾーン標準
- プロビジョニング済みマネージド
- グローバル プロビジョニング済みマネージド
- データ ゾーン プロビジョニング済みマネージド
評価パイプライン
テスト データ
テスト対象のグランド トゥルース データセットを組み立てる必要があります。 通常、データセットの作成は反復的なプロセスであり、評価は時間の経過に伴ってシナリオとの関連を保ち続けます。 通常、このグランド トゥルース データセットは手動で作成され、モデルからの期待される動作を表します。 データセットにもラベルが付き、予想される回答が含まれます。
Note
センチメントと有効な JSON または XML などの一部の評価テストでは、グランド トゥルース データは必要ありません。
データ ソースは JSONL 形式である必要があります。 JSONL 評価データセットの 2 つの例を次に示します。
評価形式
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
評価ファイルをアップロードして選択すると、最初の 3 行のプレビューが返されます。


以前にアップロードした既存のデータセットを選択するか、新しいデータセットをアップロードできます。
応答を作成する (省略可能)
評価で使用するプロンプトは、運用環境で使用する予定のプロンプトと一致する必要があります。 これらのプロンプトは、モデルが従う手順を示します。 プレイグラウンド エクスペリエンスと同様に、複数の入力を作成して、プロンプトに少数ショットの例を含めることができます。 詳細については、「プロンプト エンジニアリングの手法」で、プロンプト設計とプロンプト エンジニアリングの高度な手法の詳細を参照してください。
{{input.column_name}} の形式を使用して、プロンプト内の入力データを参照できます。ここで、column_name は、入力ファイル内の列の名前に対応します。
評価中に生成された出力は、{{sample.output_text}} の形式を使用して後続の手順で参照されます。
Note
データを正しく参照するには、二重中かっこを使用する必要があります。
モデル デプロイ
評価の作成の一環として、応答を生成するときに使用するモデル (省略可能) と、特定のテスト条件を使用してモデルを評価するときに使用するモデルを選択します。
Azure OpenAI では、評価の一部として使用する特定のモデル デプロイを割り当てます。 1 回の評価実行で複数のモデル デプロイを比較できます。
基本または微調整されたモデル デプロイを評価できます。 一覧で使用できるデプロイは、Azure OpenAI リソース内で作成したデプロイによって異なります。 目的のデプロイが見つからない場合は、Azure OpenAI 評価ページから新しいデプロイを作成できます。
テスト条件
テスト条件は、ターゲット モデルによって生成された各出力の有効性を評価するために使用されます。 これらのテストでは、一貫性を確保するために、入力データと出力データを比較します。 さまざまなレベルで出力の品質と関連性をテストおよび測定するために、さまざまな条件を柔軟に構成できます。

概要
Azure AI Foundry ポータル内の [Azure OpenAI Evaluation]\(Azure OpenAI 評価\) (プレビュー) を選択します。 このビューをオプションとして表示するには、まず、サポートされているリージョンの既存の Azure OpenAI リソースを選択する必要があります。
[New evaluation]\(新しい評価\) を選択します
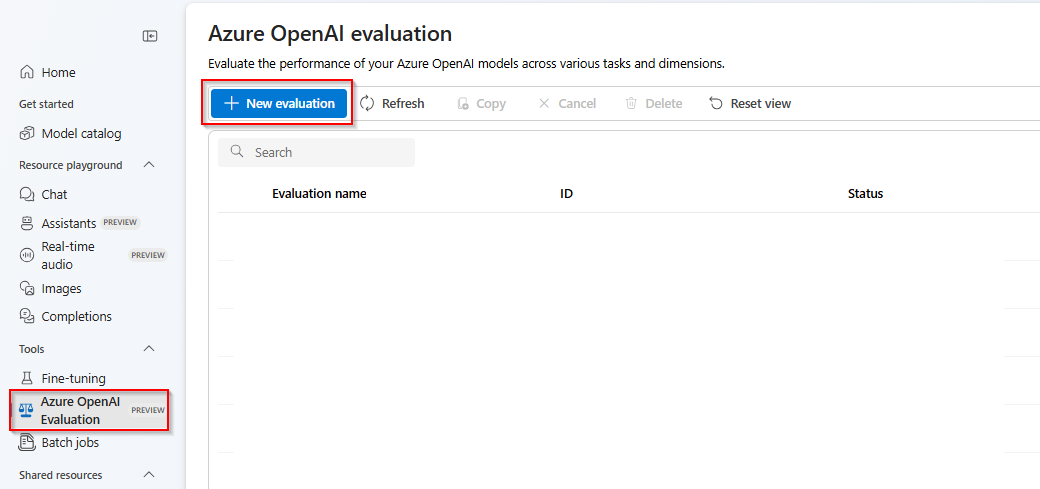
評価の名前を入力します。 既定では、編集して置き換えない限り、ランダムな名前が自動的に生成されます。 [新しいデータセットのアップロード] を選択します。
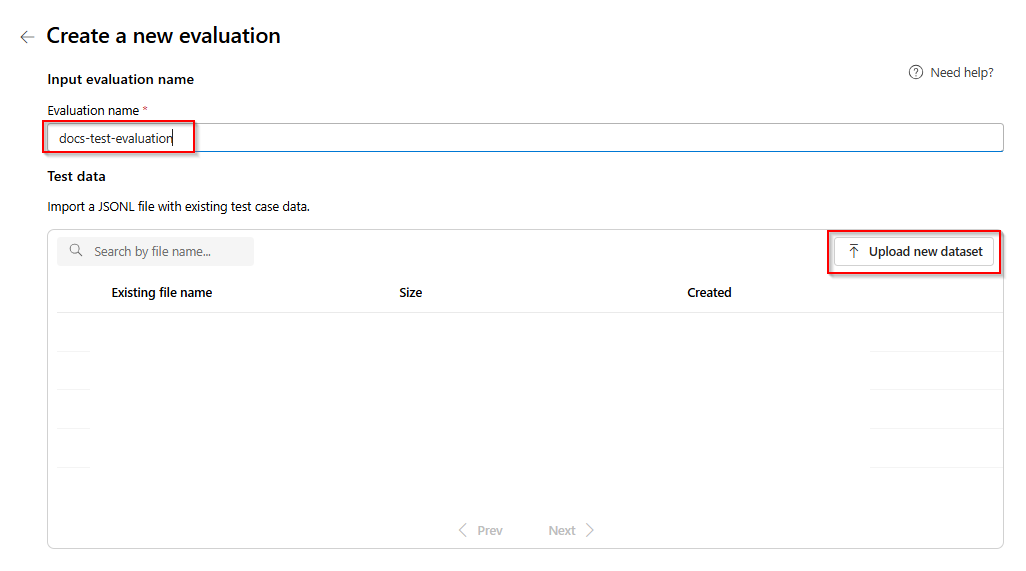
.jsonlの形式の評価を選択します。 サンプルのテスト ファイルが必要な場合は、次の 10 行をeval-test.jsonlという名前のファイルに保存できます。{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}ファイルの最初の 3 行がプレビューとして表示されます。
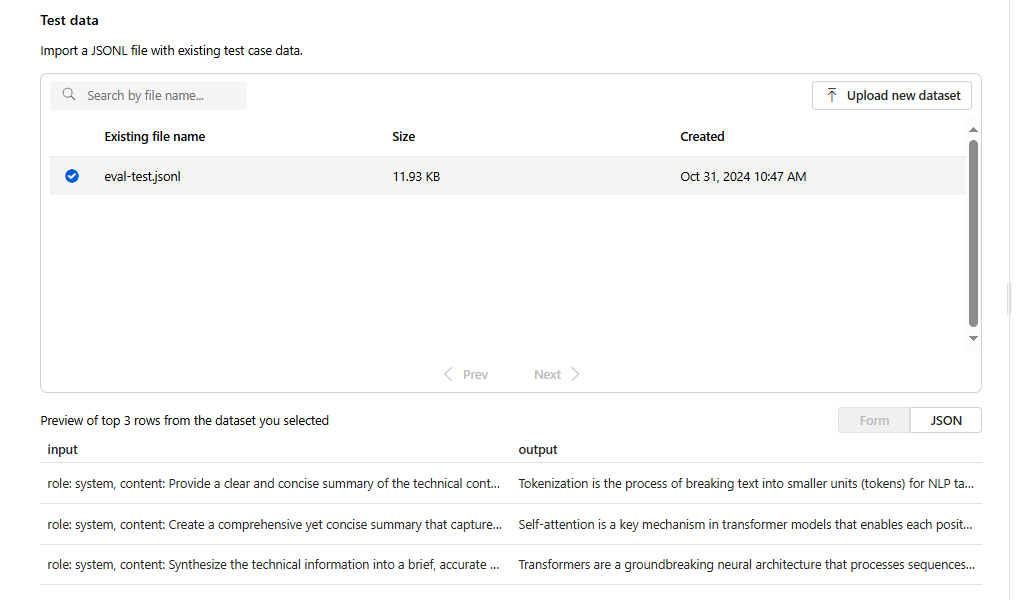
[応答] で [作成] ボタンを選択します。 [テンプレートを使って作成する] ドロップダウンから [
{{item.input}}] を選択します。 これにより、評価ファイルの入力フィールドが、評価データセットと比較できる新しいモデル実行の個々のプロンプトに挿入されます。 モデルはその入力を受け取り、独自の一意の出力を生成します。出力は、この場合、{{sample.output_text}}という変数に格納されます。 その後、テスト条件の一部として、後でそのサンプル出力テキストを使用します。 または、独自のカスタム システム メッセージと個々のメッセージの例を手動で指定することもできます。評価に基づいて応答を生成するモデルを選択します。 モデルがない場合は、モデルを作成できます。 この例では、
gpt-4o-miniの標準的なデプロイを使用しています。
設定/鎖歯車記号は、モデルに渡される基本パラメーターを制御します。 現時点では、次のパラメーターのみがサポートされています。




- 気温
- 最大長
- 上位 p
現在、選択したモデルに関係なく、最大長は 2048 に制限されます。
[Add testing criteria]\(テスト条件の追加\) を選択し、[追加] を選択します。
[セマンティックの類似性]>[Compare] を選択し、その下に
{{item.output}}を追加し、[With] の下に{{sample.output_text}}を追加します。 これにより、評価.jsonlファイルから元の参照出力が取得され、{{item.input}}に基づいてモデルにプロンプトが与えられ、生成される出力と比較されます。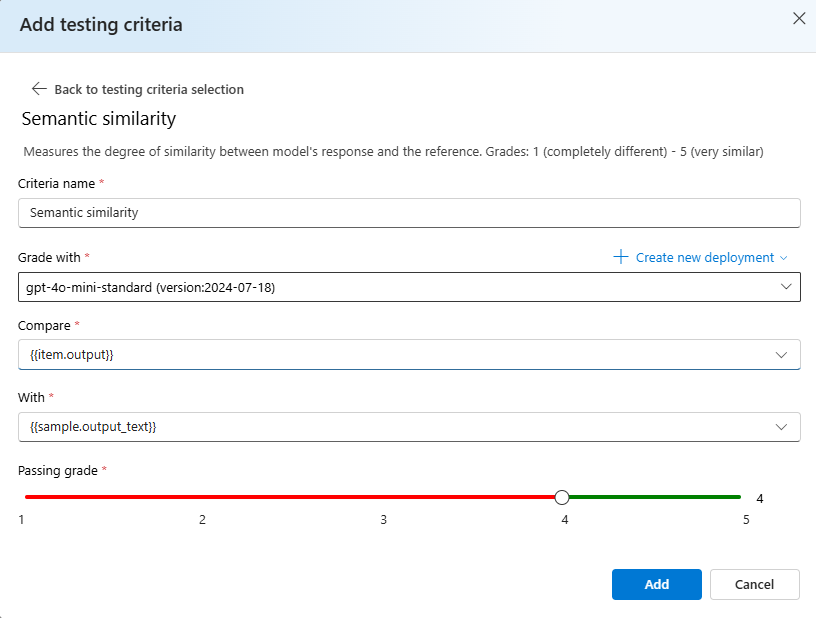
この時点で [追加]> を選択すると、追加のテスト条件を追加するか、[作成] を選択して評価ジョブの実行を開始できます。
[作成] を選択すると、評価ジョブの状態ページが表示されます。
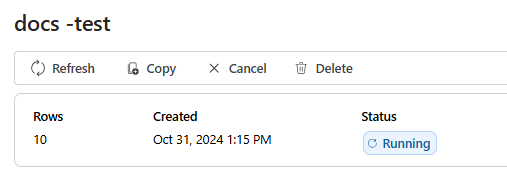
評価ジョブが作成されたら、ジョブを選択してジョブの完全な詳細を表示できます。
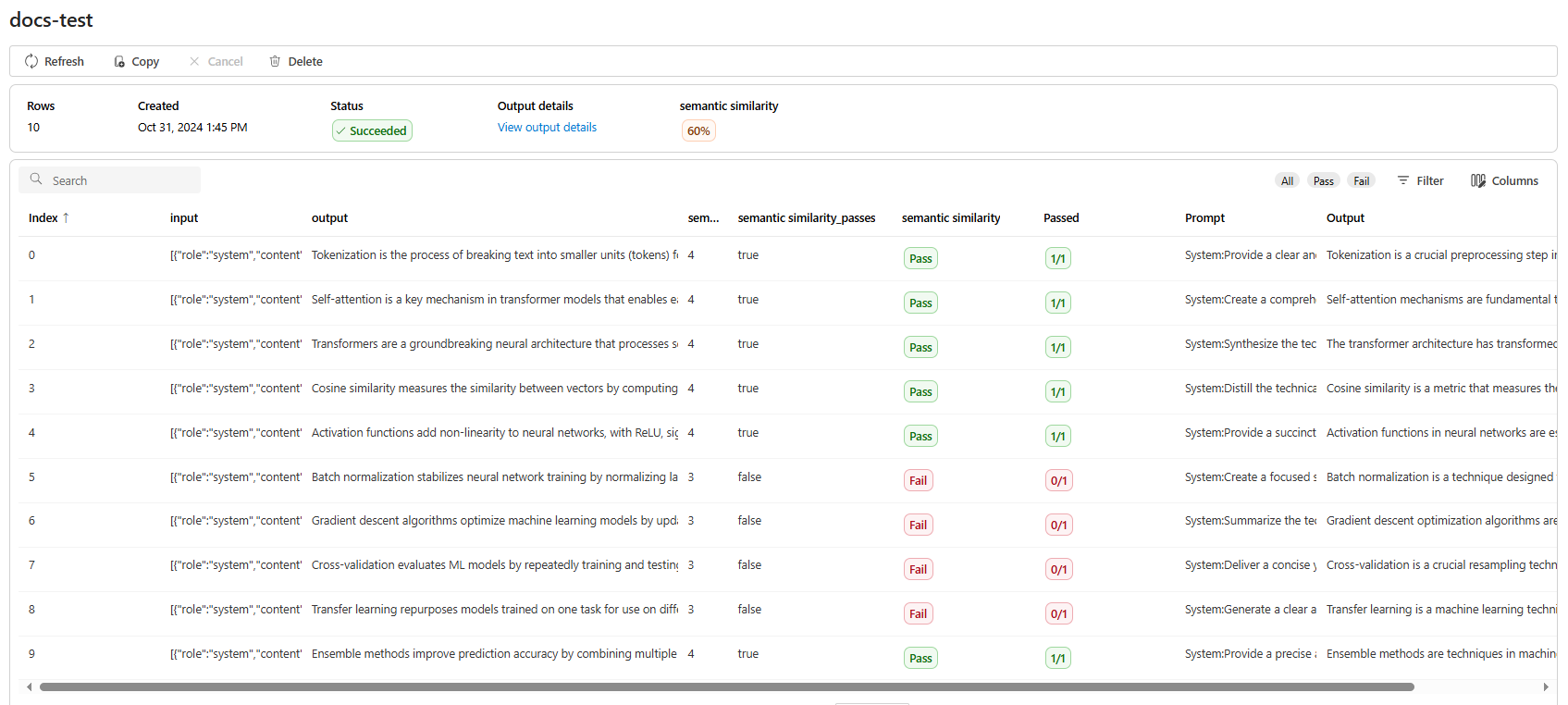
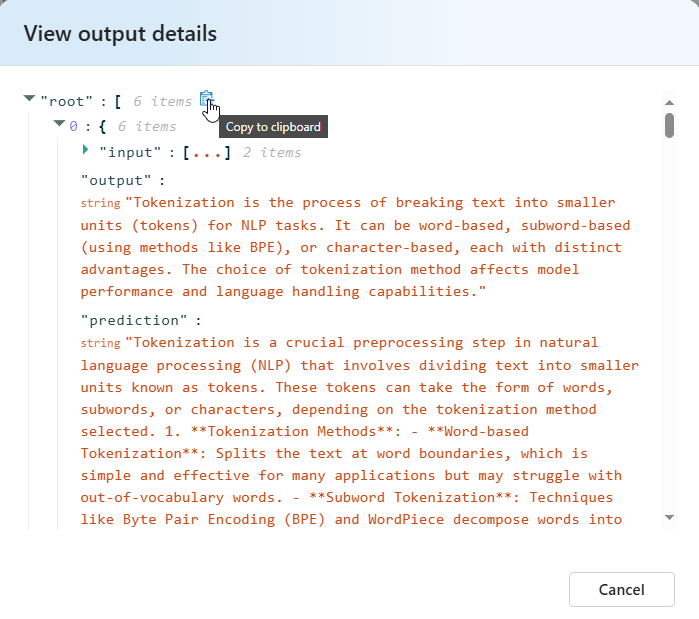
セマンティック類似性の [View output details]\(出力詳細の表示\) に、合格したテストをコピーして貼り付けられる JSON 表現が含まれます。




テスト条件の詳細
Azure OpenAI 評価には、複数のテスト条件オプションが用意されています。 次のセクションでは、各オプションの詳細について説明します。
事実性
エキスパートの回答と比較して、提出された回答の事実の正確性を評価します。
事実性は、提出された回答をエキスパートの回答と比較することで、実際の正確性を評価します。 グレーダーは、詳細な CoT (chain-of-thought) プロンプトを使用して、提出された回答がエキスパートの回答と一貫性があるか、そのサブセットであるか、そのスーパーセットであるか、競合しているかを判断します。 スタイル、文法、句読点の違いは無視され、事実に基づくコンテンツのみに焦点が当てられます。 事実性は、AI によって提供される回答の精度を保証するコンテンツ検証、教育ツールなど、その他の多くのシナリオで役立ちます。

このテスト条件の一部として使用されるプロンプト テキストを表示するには、プロンプトの横にあるドロップダウンを選択します。 現在のプロンプト テキストは次のとおりです。
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
セマンティックの類似性
モデルの応答と参照の類似性の度合いを測定します。
Grades: 1 (completely different) - 5 (very similar).

センチメント
出力の感情的なトーンの特定を試みます。

このテスト条件の一部として使用されるプロンプト テキストを表示するには、プロンプトの横にあるドロップダウンを選択します。 現在のプロンプト テキストは次のとおりです。
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
文字列チェック
出力が予想される文字列と正確に一致するかどうかを検証します。

文字列チェックは、さまざまな評価基準を可能にする 2 つの文字列変数に対してさまざまなバイナリ操作を実行します。 これは、等価性、包含、特定のパターンなど、さまざまな文字列の関係の検証に役立ちます。 このエバリュエータでは、大文字と小文字を区別する比較と、大文字と小文字を区別しない比較を実行できます。 また、真または偽の結果に対して指定された成績を提供し、比較結果に基づいてカスタマイズされた評価結果を可能にします。 サポートされる操作の種類を次に示します。
-
equals: 出力文字列が評価文字列と正確に等しいかどうかを確認します。 -
contains: 評価文字列が出力文字列の substring であるかどうかを確認します。 -
starts-with: 出力文字列が評価文字列で始まるかどうかを確認します。 -
ends-with: 出力文字列が評価文字列で終わるかどうかを確認します。
Note
テスト条件で特定のパラメーターを設定する場合は、"variable" と "template" から選択できるオプションがあります。 入力データ内の列を参照する場合は、"variable" を選択します。 固定の文字列指定する場合は、"template" を選択します。
有効な JSON または XML
出力が有効な JSON または XML であるかどうかを検証します。

スキーマに一致
出力が指定した構造に従っていることを確認します。

条件一致
モデルの応答が条件と一致するかどうかを評価します。 成績: 合格または不合格。

このテスト条件の一部として使用されるプロンプト テキストを表示するには、プロンプトの横にあるドロップダウンを選択します。 現在のプロンプト テキストは次のとおりです。
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
テキスト品質
参照テキストと比較して、テキストの品質を評価します。

要約:
- BLEU スコア: BLEU スコアを使用して、生成されたテキストの品質を 1 つ以上の高品質の参照翻訳と比較して評価します。
- ROUGE スコア: ROUGE スコアを使用して、生成されたテキストの品質を参照概要と比較して評価します。
- コサイン: コサイン類似性とも呼ばれ、モデル出力や参照テキストなどの 2 つのテキスト埋め込みがどの程度厳密に一致しているかを測定し、それらの間のセマンティック類似性を評価するのに役立ちます。 これは、ベクトル空間内の距離を測定することによって行われます。
詳細:
BLEU (BiLingual Evaluation Understudy) スコアは、自然言語処理 (NLP) と機械翻訳で一般に使用されています。 テキストの要約とテキストの生成というユース ケースで広く使用されています。 生成されたテキストが参照テキストとどの程度一致するかを評価します。 BLEU スコアの範囲は 0 から 1 であり、スコアが高いほど高い品質を示します。
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) は、自動要約と機械翻訳を評価するために使用される一連のメトリックです。 生成されたテキストと参照の要約の間の重複を測定します。 ROUGE は、生成されたテキストが参照テキストをどの程度カバーしているかを評価する、リコール指向の測定に重点を置いています。 ROUGE スコアは、次のようなさまざまなメトリックを提供します。• ROUGE-1: 生成されたテキストと参照テキストとの間にユニグラム (1 つの単語) の重なりがあります。 •ROUGE-2: 生成されたテキストと参照テキストの間にビグラム (2 つの連続する単語) の重なりがあります。 • ROUGE-3: 生成されたテキストと参照テキストの間にトリグラム (3 つの連続する単語) の重なりがあります。 • ROUGE-4: 生成されたテキストと参照テキストの間に 4 グラム (4 つの連続する単語) の重なりがあります。 • ROUGE-5: 生成されたテキストと参照テキストの間に 5 グラム (5 つの連続する単語) の重なりがあります。 • ROUGE-L: 生成されたテキストと参照テキストの間の L グラム (L 個の連続する単語) の重なりがあります。 テキストの要約とドキュメントの比較は、特にテキストの一貫性と関連性が重要なシナリオにおいて、ROUGE に最適なユース ケースの 1 つです。
コサイン類似度は、モデル出力や参照テキストなどの 2 つのテキスト埋め込みがどの程度厳密に一致しているかを測定し、それらの間のセマンティック類似性を評価するのに役立ちます。 他のモデル ベースのエバリュエータと同じように、評価に使用するモデル デプロイを提供する必要があります。
重要
このエバリュエータでは、埋め込みモデルのみがサポートされています。
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
カスタム プロンプト
モデルを使用して、出力を指定されたラベルのセットに分類します。 このエバリュエータは、定義する必要があるカスタム プロンプトを使用します。
