微調整でモデルをカスタマイズする
Azure OpenAI Service を使用すると、"微調整" と呼ばれるプロセスを使用して、個人用データセットに合わせてモデルを調整できます。 このカスタマイズ手順では以下が提供されて、サービスをさらに活用できるようになります。
- プロンプト エンジニアリングからだけでは得られないより高品質な結果
- モデルの最大要求コンテキスト制限を超える多くの例を使用してトレーニングする機能。
- 短いプロンプトによるトークンの節約
- 低遅延の要求 (特に小規模なモデルを使用する場合)。
少数のショット学習とは対照的に、微調整では、プロンプトに収まらない多くの例をトレーニングすることでモデルが改善され、多数のタスクでより良い結果が得られます。 微調整では、特定のタスクのパフォーマンスを向上させるために基本モデルの重みが調整されるため、プロンプトに含める例や手順を多く含める必要はありません。 つまり、送信されるテキストや API 呼び出しごとに処理されるトークンが少なくなり、コストが節約され、要求の待機時間が短縮される可能性があります。
LoRA (低ランク近似) を使用して、パフォーマンスに大きな影響を与えることなく複雑さを軽減する方法でモデルを微調整します。 このメソッドは、下位ランク行列を使用して元の高ランク行列の近似を求めることで機能します。つまり、教師あり学習フェーズ中に 重要 パラメーターの小さなサブセットのみを微調整し、モデルをより管理しやすい効率的なものにします。 ユーザーにとって、トレーニングが他の手法よりも速く、より手頃な価格になります。
Azure AI Foundry ポータルには、次の 2 つの固有のファインチューニング エクスペリエンスがあります。
- ハブ/プロジェクト ビュー - Azure OpenAI、Meta Llama、Microsoft Phi など、複数のプロバイダーのモデルのファインチューニングをサポートします。
- Azure OpenAI 中心のビュー - Azure OpenAI モデルのファインチューニングのみをサポートしますが、Weights & Biases (W&B) プレビュー統合などの追加機能のサポートを備えています。
Azure OpenAI モデルのみをファインチューニングする場合は、Azure OpenAI 中心のファインチューニング エクスペリエンスをお勧めします。これは、https://oai.azure.com に移動することによってご利用いただけます。
前提条件
- Azure OpenAI の微調整ガイドを使用する場合を参照してください。
- Azure サブスクリプション。 無料で作成できます。
- Azure OpenAI モデルの微調整をサポートするリージョンにある Azure OpenAI リソース。 リージョン別の使用可能なモデルとサポートされている機能の一覧については、「モデルの概要テーブルとリージョンの可用性」を参照してください。 詳細については、「Azure OpenAI を使用してリソースを作成し、モデルをデプロイする」を参照してください。
- アクセスの微調整には、Cognitive Services OpenAI 共同作成者が必要です。
- Azure AI Foundry ポータル内でクォータを表示する、およびモデルをデプロイするためのアクセスがまだない場合は、追加のアクセス許可が必要になります。
モデル
次のモデルでは、微調整がサポートされます。
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* このモデルのファインチューニングは、現在パブリック プレビューです。
または、base-model.ft-{jobid} として書式設定された、以前に微調整されたモデルを微調整することもできます。
現在微調整をサポートしているリージョンを確認するには、モデルに関するページを参照してください。
Azure AI Foundry ポータルのワークフローを確認する
少し時間を取って、Azure AI Foundry ポータルを使用するためのファインチューニング ワークフローを確認してください。
- トレーニングおよび検証用のデータを準備します。
- Azure AI Foundry ポータル内の [カスタム モデルの作成] ウィザードを使用して、カスタム モデルをトレーニングします。
- 基本モデルを選択します。
- トレーニング データを選択します。
- 必要に応じて、検証データを選択します。
- 必要に応じて、微調整ジョブのタスク パラメーターを構成します。
- 選択内容を確認して、新たにカスタマイズしたモデルをトレーニングします。
- カスタム微調整モデルの状態を確認します。
- カスタム モデルをデプロイして、使用できるようにします。
- カスタム モデルを使用します。
- 必要に応じて、カスタム モデルのパフォーマンスと適合度を分析します。
トレーニング データと検証データを準備する
トレーニング データと検証データのセットは、モデルの実行方法に関する入力と出力の例で構成されます。
モデルの種類が異なると、異なる形式のトレーニング データが必要になります。
使用するトレーニングおよび検証データは、JSON Lines (JSONL) ドキュメントの形式である必要があります。 gpt-35-turbo (すべてのバージョン)、gpt-4、gpt-4o、gpt-4o-mini の場合、微調整データセットの形式は、Chat Completions API で使用される会話形式である必要があります。
gpt-4o-mini (2024-07-18) モデルの微調整の詳細な手順については、「Azure OpenAI 微調整チュートリアル」を参照してください。
ファイル形式の例
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
マルチターン チャット ファイル形式 Azure OpenAI
jsonl トレーニング ファイルの 1 行での会話の複数のターンもサポートされています。 特定のアシスタント メッセージの微調整をスキップするには、オプションの weight キー値ペアを追加します。 現在、weight は 0 または 1 に設定できます。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
vision でのチャット補完
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
JSONL 形式に加えて、トレーニングおよび検証のデータ ファイルは UTF-8 でエンコードしてバイトオーダー マーク (BOM) を含める必要があります。 ファイルは、512 MB 未満のサイズにする必要があります。
トレーニングおよび検証のデータセットを作成する
トレーニング例が多いほど適切になります。 微調整ジョブは、少なくとも 10 個のトレーニング例がないと実行されませんが、このような少数では、目に見えるほどの影響をモデルの応答に与えられません。 成功するには、数千ではないにしても数百のトレーニング例を提供することをお勧めします。
一般的に、データセット サイズを 2 倍にすると、モデルの品質を直線的に向上させることができます。 ただし、低品質の例はパフォーマンスに悪影響を与える可能性があることに注意してください。 大量の内部データでモデルをトレーニングする場合、最初に最高品質の例についてのみデータセットを排除しないと、予想よりもはるかにパフォーマンスの低いモデルになる可能性があります。
[Create custom model](カスタム モデルの作成) ウィザードを使用する
Azure AI Foundry ポータルには、[カスタム モデルの作成] ウィザードが用意されているため、Azure リソース用にファインチューニングされたモデルを対話形式で作成してトレーニングできます。
https://oai.azure.com/ で Azure AI Foundry ポータルを開き、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。 サインイン ワークフローの途中で、適切なディレクトリ、Azure サブスクリプション、Azure OpenAI リソースを選択します。
Azure AI Foundry ポータル内で [ツール] > [ファインチューニング] ペインに移動し、[モデルのファインチューニング] を選択します。
![Azure AI Foundry ポータル内の [カスタム モデルの作成] ウィザードにアクセスする方法を示すスクリーンショット。](../media/fine-tuning/studio-create-custom-model.png)
![Azure AI Foundry ポータル内の [カスタム モデルの作成] ウィザードにアクセスする方法を示すスクリーンショット。](../media/fine-tuning/studio-create-custom-model.png#lightbox)
[Create custom model](カスタム モデルの作成) ウィザードが開きます。
基本モデルを選択する
カスタム モデルを作成するための最初の手順は、基本モデルを選択することです。 [Base model](基本モデル) ウィンドウで、カスタム モデルに使用する基本モデルを選択できます。 この選択は、モデルのパフォーマンスとコストの両方に影響します。
[Base model type](基本モデルの種類) ドロップダウンから基本モデルを選択し、[次へ] を選択して続行します。
次の使用可能な基本モデルのいずれかから、カスタム モデルを作成できます。
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)または、base-model.ft-{jobid} として書式設定された、以前に微調整されたモデルを微調整することもできます。

微調整が可能な基本モデルの詳細については、モデルに関する記事を参照してください。
トレーニング データを選択する
次の手順では、既存の準備済みトレーニング データを選択するか、モデルをカスタマイズするときに使用する新しい準備済みトレーニング データをアップロードします。 [トレーニング データ] ウィンドウには、以前にアップロードされた既存のデータセットが表示されるほか、新しいトレーニング データをアップロードできるオプションも表示されます。
![Azure AI Foundry ポータル内の [カスタム モデルの作成] ウィザードの [トレーニング データ] ペインのスクリーンショット。](../media/fine-tuning/studio-training-data.png#lightbox)
トレーニング データが既にサービスにアップロードされている場合は、[Azure OpenAI Connection のファイル] を選択します。
- 表示されたドロップダウン リストからファイルを選択します。
新しいトレーニング データをアップロードするには、次のいずれかのオプションを使用します。
ローカル ファイルからトレーニング データをアップロードするには、[ローカル ファイル] を選択します。
Azure BLOB または別の Web 上の共有の場所からトレーニング データをインポートするには、[Azure BLOB またはその他の Web 上の共有場所] を選択します。
大きなデータ ファイルの場合は、Azure BLOB ストアからインポートすることをお勧めします。 大きなファイルは、マルチパート フォームを介してアップロードすると不安定になる場合があります。要求がアトミックであり、再試行または再開ができないためです。 Azure Blob Storage の詳細については、「Azure Blob Storage とは」を参照してください。
Note
トレーニング データ ファイルは、JSONL ファイル形式にし、バイトオーダー マーク (BOM) を使用して UTF-8 でエンコードする必要があります。 ファイルは、512 MB 未満のサイズにする必要があります。
ローカル ファイルからトレーニング データをアップロードする
次のいずれかの方法を使用して、ローカル ファイルから新しいトレーニング データセットをサービスにアップロードできます。
ファイルを [トレーニング データ] ウィンドウのクライアント領域にドラッグ アンド ドロップし、[ファイルのアップロード] を選択します。
[トレーニング データ] ウィンドウのクライアント領域から [ファイルを参照する] を選択し、[開く] ダイアログからアップロードするファイルを選択して、[ファイルのアップロード] を選択します。
トレーニング データセットを選択してアップロードしたら、[次へ] を選択して続行します。
 ウィザードの [トレーニング データ] ウィンドウのスクリーンショット。](../media/fine-tuning/studio-training-data-local.png#lightbox)
Azure BLOB ストアからトレーニング データをインポートする
ファイルの名前と場所を指定することで、Azure BLOB または別の Web 上の共有の場所からトレーニング データセットをインポートできます。
ファイルの[ファイル名] を入力します。
[ファイルの場所] には、Azure BLOB の URL、Azure Storage Shared Access Signature (SAS)、またはアクセス可能な Web 上の共有の場所へのその他のリンクを指定します。
[インポート] を選択して、トレーニング データセットをサービスにインポートします。
トレーニング データセットを選択してアップロードしたら、[次へ] を選択して続行します。
 ウィザードの [トレーニング データ] ウィンドウのスクリーンショット。](../media/fine-tuning/studio-training-data-blob.png#lightbox)
検証データを選択する
次の手順では、トレーニング プロセスで検証データを使用するようにモデルを構成するためのオプションが提供されます。 検証データを使用しない場合は、[次へ] を選択してモデルの詳細オプションに進むことができます。 それ以外で、検証データセットがある場合は、既存の準備済みの検証データを選択するか、モデルをカスタマイズするときに使用する新しい準備済みの検証データをアップロードできます。
[検証データ] ウィンドウには、以前にアップロードされた既存のトレーニングおよび検証のデータセットが表示され、新しいトレーニング データをアップロードできるオプションが表示されます。
![Azure AI Foundry ポータル内の [カスタム モデルの作成] ウィザードの [検証データ] ペインのスクリーンショット。](../media/fine-tuning/studio-validation-data.png#lightbox)
検証データが既にサービスにアップロードされている場合は、[データセットの選択] を選択します。
- [検証データ] ウィンドウに表示される一覧からファイルを選択します。
新しい検証データをアップロードするには、次のいずれかのオプションを使用します。
ローカル ファイルから検証データをアップロードするには、[ローカル ファイル] を選択します。
Azure BLOB または別の Web 上の共有の場所から検証データをインポートするには、[Azure BLOB またはその他の Web 上の共有場所] を選択します。
大きなデータ ファイルの場合は、Azure BLOB ストアからインポートすることをお勧めします。 大きなファイルは、マルチパート フォームを介してアップロードすると不安定になる場合があります。要求がアトミックであり、再試行または再開ができないためです。
Note
検証データ ファイルは、トレーニング データ ファイルと同様に JSONL ファイル形式にし、バイトオーダー マーク (BOM) を使用して UTF-8 でエンコードする必要があります。 ファイルは、512 MB 未満のサイズにする必要があります。
ローカル ファイルから検証データをアップロードする
次のいずれかの方法を使用して、ローカル ファイルから新しい検証データセットをサービスにアップロードできます。
ファイルを [検証データ] ウィンドウのクライアント領域にドラッグ アンド ドロップし、[ファイルのアップロード] を選択します。
[検証データ] ウィンドウのクライアント領域から [ファイルを参照する] を選択し、[開く] ダイアログからアップロードするファイルを選択して、[ファイルのアップロード] を選択します。
検証データセットを選択してアップロードしたら、[次へ] を選択して続行します。
 ウィザードの [検証データ] ウィンドウのスクリーンショット。](../media/fine-tuning/studio-validation-data-local.png#lightbox)
Azure BLOB ストアから検証データをインポートする
ファイルの名前と場所を指定することで、Azure BLOB または別の Web 上の共有の場所から検証データセットをインポートできます。
ファイルの[ファイル名] を入力します。
[ファイルの場所] には、Azure BLOB の URL、Azure Storage Shared Access Signature (SAS)、またはアクセス可能な Web 上の共有の場所へのその他のリンクを指定します。
[インポート] を選択して、トレーニング データセットをサービスにインポートします。
検証データセットを選択してアップロードしたら、[次へ] を選択して続行します。
 ウィザードの [検証データ] ウィンドウのスクリーンショット。](../media/fine-tuning/studio-validation-data-blob.png#lightbox)
タスク パラメーターを構成する
[カスタム モデルの作成] ウィザードの [タスク パラメーター] ペインには、微調整されたモデルをトレーニングするためのパラメーターが表示されます。 次のパラメーターを使用できます。
| 名前 | タイプ | 説明 |
|---|---|---|
batch_size |
integer | トレーニングに使用するバッチ サイズ。 バッチ サイズは、単一の順方向および逆方向の合格をトレーニングするために使用するトレーニング例の数です。 一般的に、大規模なデータセットでは、バッチ サイズが大きいほど適切に機能する傾向があることがわかっています。 このプロパティの既定値と最大値は、基本モデルに固有です。 バッチ サイズが大きいほど、モデル パラメーターの更新頻度は低くなりますが、分散は小さくなります。 |
learning_rate_multiplier |
数値 | トレーニングに使用する学習率乗数。 微調整の学習率は、事前トレーニングに使用された元の学習率にこの値を掛けた値です。 学習率が高いほど、大きいバッチ サイズでのパフォーマンスが向上する傾向があります。 0.02 から 0.2 の範囲の値を試して、最適な結果が得られるものを確認することをお勧めします。 学習率を小さくすると、オーバーフィットを避けるのに役立つ場合があります。 |
n_epochs |
integer | モデルをトレーニングするエポックの数。 エポックとは、トレーニング データセット全体での 1 つの完全なサイクルを指します。 |
seed |
integer | シードはジョブの再現性を制御します。 同じシードとジョブ パラメーターを渡すと同じ結果が得られますが、まれに異なる場合があります。 シードが指定されていない場合は生成されます |
Beta |
integer | dpo 損失の温度パラメーター (通常は 0.1 から 0.5 の範囲)。 これは、参照モデルをどれだけ重視するのかを制御します。 ベータが小さいほど、モデルが参照モデルから逸れることを許容します。 ベータが小さくなるにつれて、参照モデルは無視されます。 |
 ウィザードの [高度なオプション] ウィンドウのスクリーンショット。](../media/fine-tuning/studio-advanced-options.png#lightbox)
[既定値] を選択して微調整ジョブの既定値を使用するか、[カスタム] を選択してハイパーパラメーター値を表示して編集します。 既定値を選択すると、トレーニング データに基づいて正しい値がアルゴリズムによって決定されます。
高度なオプションを構成したら [次へ] を選択し、選択内容を確認して微調整したモデルをトレーニングします。
選択内容をレビューしてモデルをトレーニングする
ウィザードの [レビュー] ウィンドウには、構成の選択に関する情報が表示されます。
![Azure AI Foundry ポータル内の [カスタム モデルの作成] ウィザードの [レビュー] ペインのスクリーンショット。](../media/fine-tuning/studio-review.png#lightbox)
モデルをトレーニングする準備ができたら、[Start Training job](トレーニング ジョブの開始) を選択して微調整ジョブを開始し、[モデル] ウィンドウに戻ります。
カスタム モデルの状態を確認する
[モデル] ウィンドウでは、[Customized models](カスタマイズされたモデル) タブにカスタム モデルに関する情報が表示されます。このタブには、カスタム モデルの微調整ジョブの状態とジョブ ID に関する情報が含まれます。 ジョブが完了すると、タブに結果ファイルのファイル ID が表示されます。 モデル トレーニング ジョブの更新された状態を表示するには、[最新の情報に更新] を選択する必要がある場合があります。
![カスタム モデルが表示された、Azure AI Foundry ポータルの [モデル] ペインのスクリーンショット。](../media/fine-tuning/studio-models-job-running.png#lightbox)
微調整ジョブを開始した後、完了するまでに時間がかかる場合があります。 ジョブは、システム上の他のジョブの後にキューに入れられる場合があります。 モデルのトレーニングには、モデルおよびデータセットのサイズに応じて、数分または数時間かかる場合があります。
[モデル] ウィンドウで実行できるタスクの一部を次に示します。
[Customized models](カスタマイズされたモデル) タブの [状態] 列で、カスタム モデルの微調整ジョブの状態を確認します。
[モデル名] 列でモデル名を選択して、カスタム モデルに関する詳細情報を表示します。 微調整ジョブの状態、トレーニング結果、トレーニング イベント、ジョブで使用されているハイパーパラメーターを確認できます。
[トレーニング ファイルをダウンロードする] を選択して、モデルに使用したトレーニング データをダウンロードします。
[結果のダウンロード] を選択して、モデルの微調整ジョブに添付された結果ファイルをダウンロードし、トレーニングおよび検証のパフォーマンスについてカスタム モデルを分析します。
[更新] を選んで、ページを最新の情報に更新します。
チェックポイント
各トレーニング エポックが完了すると、チェックポイントが生成されます。 チェックポイントは、完全な機能を持つモデルのバージョンであり、デプロイすることも、後続の微調整ジョブのターゲット モデルとして使用することもできます。 チェックポイントは、オーバーフィットが発生する前のモデルのスナップショットを提供できるため、特に有益です。 微調整が完了すると、3 つの最新バージョンのモデルをデプロイできるようになります。
安全性評価 GPT-4、GPT-4o、および GPT-4o-mini の微調整 - パブリック プレビュー
GPT-4o、GPT-4o-mini、GPT-4 は、お客様のニーズに合わせて微調整できる最も高度なモデルです。 Azure OpenAI の他のモデルと同様、微調整されたモデルは高度な機能を備えていますが、その分、有害なコンテンツの生成、操作、人間のような振る舞い、プライバシー問題など、責任ある AI の利用に関する課題も増大します。 リスク、機能、制限に関する詳細については、「責任ある AI プラクティスの概要」および「透明性に関する注意事項」をご参照ください。 高度に微調整されたモデルに伴うリスク軽減のため、微調整されたモデルのトレーニングと出力において有害なコンテンツを検出し、その生成を防止する追加の評価手順を導入しました。 これらの手順は、「Microsoft の責任ある AI の基本原則」と「Azure OpenAI Service のコンテンツのフィルター処理」に準拠しています。
- 評価は、顧客ごとに専用のプライベート ワークスペースを設けて実施されます。
- 評価エンドポイントは Azure OpenAI リソースと同じ地域に配置されます。
- 評価の実施に際し、トレーニング データは保存されず、最終的なモデル評価 (デプロイの可否) のみが保存されます。
GPT-4o、GPT-4o-mini、GPT-4 のファインチューニングされたモデルの評価フィルターは定義済みのしきい値に設定されており、お客様が変更することはできません。お客様が作成したカスタム コンテンツのフィルタリング構成には関連付けられません。
データの評価
トレーニングを開始する前に、データ内に潜む可能性のある有害コンテンツ (暴力、性的、ヘイト、公平性、自傷行為など - 各カテゴリの定義はこちら) の評価が行われます。 指定された重大度レベルを超える有害なコンテンツが検出された場合、トレーニング ジョブは失敗し、失敗の原因となったカテゴリを通知するメッセージが表示されます。
サンプル メッセージ:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
微調整機能の一環として、お客様のトレーニング データは、データ インポート ジョブにおいて自動的に評価されます。
トレーニング データで有害なコンテンツが検出されて微調整ジョブが失敗した場合、課金されません。
モデルの評価
トレーニング完了後、微調整されたモデルをデプロイできるようになる前に、Azure に組み込まれているリスクおよび安全性の指標を用いて、モデルが有害な応答を生成する可能性がないか評価されます。 大規模言語モデルのベースモデルと同じテスト手法を用いて、微調整済みモデルとの会話をシミュレートし、有害なコンテンツを出力する可能性を評価します。評価では、暴力、性的、ヘイト、公平性、自傷行為といった特定の有害なコンテンツのカテゴリを使用します。
モデルが許容範囲を超えて有害なコンテンツを含む出力を生成する場合、モデルはデプロイできなくなり、具体的にどの有害カテゴリが検出されたかについての情報が提供されます。
サンプル メッセージ:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

データ評価と同様、微調整機能を提供する一環として、モデルは微調整ジョブ内で自動的に評価されます。 サービスによりログに記録されるのは、結果として得られた評価 (デプロイの可否) のみです。 微調整されたモデルのデプロイ時に、モデルの出力が有害なコンテンツを含むと判断されデプロイされなかった場合、トレーニングにかかった費用は発生しません。
微調整されたモデルをデプロイする
微調整ジョブが正常に完了したら、[モデル] ウィンドウからカスタム モデルをデプロイできます。 カスタム モデルをデプロイして、補完呼び出しで使用できるようにする必要があります。
重要
カスタマイズされたモデルをデプロイした後、デプロイが 15 日を超えて非アクティブのままである場合、デプロイは削除されます。 カスタマイズされたモデルのデプロイは、モデルが 15 日以上前にデプロイされ、15 日間連続して完了またはチャット完了の呼び出しが行われなかった場合、"非アクティブ" になります。
非アクティブなデプロイを削除しても、基になるカスタマイズされたモデルは削除されることも影響を受けることもなく、カスタマイズされたモデルはいつでも再デプロイできます。 「Azure OpenAI Service の価格」で説明されているように、デプロイ済みのカスタマイズされた (微調整された) 各モデルには、補完またはチャット補完の呼び出しがモデルに対して行われているかどうかに関係なく、1 時間ごとのホスティング コストが発生します。 Azure OpenAI を使用したコストの計画と管理の詳細については、「Azure OpenAI Service のコストを管理するための計画」のガイダンスを参照してください。
Note
カスタム モデルに対して許可されるデプロイは 1 つだけです。 既にデプロイされているカスタム モデルを選択すると、エラー メッセージが表示されます。
カスタム モデルをデプロイするには、デプロイするカスタム モデルを選択し、[モデルをデプロイします] を選択します。

[モデルをデプロイします] ダイアログ ボックスが開きます。 ダイアログ ボックスで [デプロイ名] を入力し、[作成] を選択して、カスタム モデルのデプロイを開始します。
![Azure AI Foundry ポータル内の [モデルのデプロイ] ダイアログのスクリーンショット。](../media/fine-tuning/studio-models-deploy.png#lightbox)
Azure AI Foundry ポータル内の [デプロイ] ペイン上で、デプロイの進行状況を監視できます。
リージョン間デプロイ
微調整では、微調整されたモデルを、モデルが最初に微調整された場所とは異なるリージョンにデプロイすることがサポートされています。 別のサブスクリプション/リージョンにデプロイすることもできます。
唯一の制限は、新しいリージョンが微調整もサポートする必要があることと、サブスクリプション間でデプロイする場合、デプロイ用の認可トークンを生成するアカウントがソース サブスクリプションと宛先サブスクリプションの両方にアクセスできる必要があることです。
サブスクリプション/リージョン間のデプロイは、Python または REST を使って実行できます。
デプロイされたカスタム モデルを使用する
カスタム モデルをデプロイしたら、他のデプロイ済みモデルと同様に使用できます。 Azure AI Foundry ポータルの [プレイグラウンド] を使用して、新しいデプロイを試すことができます。 カスタム モデルでは、他のデプロイ済みモデルと同様に、temperature や max_tokens などの同じパラメーターを引き続き使用できます。 微調整された babbage-002 および davinci-002 モデルに対して、入力候補プレイグラウンドと入力候補 API を使用します。 微調整された gpt-35-turbo-0613 モデルに対して、チャット プレイグラウンドとチャット入力候補 API を使用します。
![セクションが強調表示されている、Azure AI Foundry ポータル内の [プレイグラウンド] ペインのスクリーンショット。](../media/quickstarts/playground-load-new.png#lightbox)
カスタム モデルを分析する
Azure OpenAI では、各微調整ジョブが完了すると、results.csv という名前の結果ファイルが添付されます。 この結果ファイルを使用して、カスタム モデルのトレーニングと検証のパフォーマンスを分析できます。 結果ファイルのファイル ID は、Azure AI Foundry ポータルの [モデル] ペイン上の [結果ファイル ID] 列に、カスタム モデルごとに一覧表示されます。 ファイル ID を使用して、Azure AI Foundry ポータルの [データ ファイル] ペインから結果ファイルを特定してダウンロードできます。
結果ファイルは、ヘッダー行と、微調整ジョブによって実行される各トレーニング ステップの行が含まれる CSV ファイルです。 この結果ファイルには、次の列が含まれています。
| 列名 | 説明 |
|---|---|
step |
トレーニング ステップの数。 トレーニング ステップは、トレーニング データのバッチに対する前方と後方の 1 回のパスを表します。 |
train_loss |
トレーニング バッチの損失。 |
train_mean_token_accuracy |
モデルによって正しく予測されたトレーニング バッチ内のトークンの割合。 たとえば、バッチ サイズが 3 に設定されていて、データに候補 [[1, 2], [0, 5], [4, 2]] が含まれており、モデルが [[1, 1], [0, 5], [4, 2]] を予測した場合、この値は 0.83 (5/6) に設定されます。 |
valid_loss |
検証バッチの損失。 |
validation_mean_token_accuracy |
モデルによって正しく予測された検証バッチ内のトークンの割合。 たとえば、バッチ サイズが 3 に設定されていて、データに候補 [[1, 2], [0, 5], [4, 2]] が含まれており、モデルが [[1, 1], [0, 5], [4, 2]] を予測した場合、この値は 0.83 (5/6) に設定されます。 |
full_valid_loss |
各エポックの終了時に計算される検証損失。 トレーニングがうまくいった場合は、損失は減少します。 |
full_valid_mean_token_accuracy |
各エポックの終了時に計算された有効平均トークン精度。 トレーニングがうまくいった場合は、トークンの精度が向上します。 |
Azure AI Foundry ポータル内で、results.csv ファイル内のデータをプロットとして表示することもできます。 トレーニング済みのモデルのリンクを選択すると、損失、平均トークンの精度、トークンの精度の 3 つのグラフが表示されます。 検証データを指定した場合、両方のデータセットが同じプロットに表示されます。
時間の経過と同時に減少する損失を探し、精度を向上させます。 トレーニングデータと検証データの間に相違がある場合は、オーバーフィットしていることを示している可能性があります。 エポックが少ない、または学習率の乗数が小さいトレーニングを試してみてください。
デプロイ、カスタム モデル、トレーニング ファイルをクリーンアップする
カスタム モデルの利用が完了したら、デプロイとモデルを削除できます。 必要に応じて、サービスにアップロードしたトレーニングおよび検証のファイルを削除することもできます。
モデル デプロイの削除
重要
カスタマイズされたモデルをデプロイした後、デプロイが 15 日を超えて非アクティブのままである場合、デプロイは削除されます。 カスタマイズされたモデルのデプロイは、モデルが 15 日以上前にデプロイされ、15 日間連続して完了またはチャット完了の呼び出しが行われなかった場合、"非アクティブ" になります。
非アクティブなデプロイを削除しても、基になるカスタマイズされたモデルは削除されることも影響を受けることもなく、カスタマイズされたモデルはいつでも再デプロイできます。 「Azure OpenAI Service の価格」で説明されているように、デプロイ済みのカスタマイズされた (微調整された) 各モデルには、補完またはチャット補完の呼び出しがモデルに対して行われているかどうかに関係なく、1 時間ごとのホスティング コストが発生します。 Azure OpenAI を使用したコストの計画と管理の詳細については、「Azure OpenAI Service のコストを管理するための計画」のガイダンスを参照してください。
Azure AI Foundry ポータル内の [デプロイ] ペイン上でカスタム モデルのデプロイを削除できます。 削除するデプロイを選択し、[削除] を選択してデプロイを削除します。
カスタム モデルを削除する
Azure AI Foundry ポータル内の [モデル] ペイン上でカスタム モデルを削除できます。 [Customized models](カスタマイズされたモデル) タブから削除するカスタム モデルを選択し、[削除] を選択してカスタム モデルを削除します。
Note
既存のデプロイがある場合は、カスタム モデルを削除できません。 カスタム モデルを削除する前に、まずモデル デプロイを削除する必要があります。
トレーニング ファイルの削除
必要に応じて、トレーニング用にアップロードしたトレーニングおよび検証のファイルと、トレーニング中に生成された結果ファイルを、Azure AI Foundry ポータル内の [管理]>[データとインデックス] ペインで削除できます。 削除するファイルを選択し、[削除] を選択してファイルを削除します。
継続的な微調整
微調整されたモデルを作成したら、さらに微調整を行い時間をかけてモデルを改良し続けることができます。 継続的な微調整は、既に微調整されたモデルを基本モデルとして選び、新しいトレーニング サンプルのセットでさらに微調整する反復プロセスです。
以前に微調整したモデルに対して微調整を実行するには、カスタマイズされたモデルを作成するに関するセクションで説明したのと同じプロセスを使いますが、汎用基本モデルの名前を指定する代わりに、既に微調整されたモデルを指定します。 カスタムの微調整されたモデルは gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7 のようになります
![微調整されたモデルが強調表示されている [カスタム モデルを作成する] UI のスクリーンショット。](../media/fine-tuning/studio-continuous.png#lightbox)
また、微調整モデルの異なるイテレーションを区別しやすくするために、suffix パラメーターを含めることをお勧めします。 suffix は文字列を受け取り、微調整されたモデルを特定するように設定されます。 OpenAI Python API では、微調整されたモデル名に追加される最大 18 文字の文字列がサポートされています。



![Azure AI Foundry ポータル内の [モデルのファインチューニング] ウィザードの [トレーニング データ] ペインのスクリーンショット。](../media/fine-tuning/ai-studio/fine-tune-training-data-local.png#lightbox)



前提条件
- Azure OpenAI の微調整ガイドを使用する場合を参照してください。
- Azure サブスクリプション。 無料で作成できます。
- Azure OpenAI リソース。 詳細については、「Azure OpenAI を使用してリソースを作成し、モデルをデプロイする」を参照してください。
- 次の Python ライブラリ:
os、json、requests、openai。 - OpenAI Python ライブラリは、バージョン 0.28.1 以上である必要があります。
- アクセスの微調整には、Cognitive Services OpenAI 共同作成者が必要です。
- Azure AI Foundry ポータル内でクォータを表示する、およびモデルをデプロイするためのアクセスがまだない場合は、追加のアクセス許可が必要になります。
モデル
次のモデルでは、微調整がサポートされます。
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* このモデルのファインチューニングは、現在パブリック プレビューです。
または、base-model.ft-{jobid} として書式設定された、以前に微調整されたモデルを微調整することもできます。
現在微調整をサポートしているリージョンを確認するには、モデルに関するページを参照してください。
Python SDK のワークフローを確認する
少し時間を取って、Python SDK と Azure OpenAI を使用するための微調整ワークフローを確認してください。
- トレーニングおよび検証用のデータを準備します。
- 基本モデルを選択します。
- トレーニング データをアップロードします。
- 新たにカスタマイズしたモデルをトレーニングします。
- カスタマイズしたモデルの状態を確認します。
- カスタマイズしたモデルをデプロイして使用できるようにします。
- カスタマイズしたモデルを使用します。
- 必要に応じて、カスタマイズしたモデルをパフォーマンスと適合度を分析します。
トレーニング データと検証データを準備する
トレーニング データと検証データのセットは、モデルの実行方法に関する入力と出力の例で構成されます。
モデルの種類が異なると、異なる形式のトレーニング データが必要になります。
使用するトレーニングおよび検証データは、JSON Lines (JSONL) ドキュメントの形式である必要があります。 gpt-35-turbo-0613 の場合、微調整データセットの形式は、チャット入力候補 API で使用される会話形式でである必要があります。
gpt-35-turbo-0613 の微調整の詳細な手順については、Azure OpenAI の微調整に関するチュートリアルを参照してください。
ファイル形式の例
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
マルチターン チャット ファイル形式
jsonl トレーニング ファイルの 1 行での会話の複数のターンもサポートされています。 特定のアシスタント メッセージの微調整をスキップするには、オプションの weight キー値ペアを追加します。 現在、weight は 0 または 1 に設定できます。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
vision でのチャット補完
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
JSONL 形式に加えて、トレーニングおよび検証のデータ ファイルは UTF-8 でエンコードしてバイトオーダー マーク (BOM) を含める必要があります。 ファイルは、512 MB 未満のサイズにする必要があります。
トレーニングおよび検証のデータセットを作成する
トレーニング例が多いほど適切になります。 微調整ジョブは、少なくとも 10 個のトレーニング例がないと続行されませんが、このような少数ではモデルの応答に顕著な影響を与えるには不十分です。 成功するには、数千ではないにしても数百のトレーニング例を提供することをお勧めします。
一般的に、データセット サイズを 2 倍にすると、モデルの品質を直線的に向上させることができます。 ただし、低品質の例はパフォーマンスに悪影響を与える可能性があることに注意してください。 大量の内部データでモデルをトレーニングする場合、最初に最高品質の例についてのみデータセットを排除しないと、予想よりもはるかにパフォーマンスの低いモデルになる可能性があります。
トレーニング データをアップロードする
次の手順では、既存の準備済みトレーニング データを選択するか、モデルをカスタマイズするときに使用する新しい準備済みトレーニング データをアップロードします。 トレーニング データを準備したら、ファイルをサービスにアップロードできます。 トレーニング データをアップロードする方法は 2 つあります。
大きなデータ ファイルの場合は、Azure BLOB ストアからインポートすることをお勧めします。 大きなファイルは、マルチパート フォームを介してアップロードすると不安定になる場合があります。要求がアトミックであり、再試行または再開ができないためです。 Azure Blob Storage の詳細については、「Azure Blob Storage とは」を参照してください。
Note
トレーニング データ ファイルは、JSONL ファイル形式にし、バイトオーダー マーク (BOM) を使用して UTF-8 でエンコードする必要があります。 ファイルは、512 MB 未満のサイズにする必要があります。
次の Python の例では、Python SDK を使用してローカルのトレーニングおよび検証ファイルをアップロードし、返されたファイル ID を取得します。
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
カスタマイズしたモデルを作成する
トレーニングおよび検証ファイルをアップロードしたら、微調整ジョブを開始する準備が整います。
次の Python コードは、Python SDK を使用して新しい微調整ジョブを作成する方法の例を示しています。
この例では、seed パラメーターも渡しています。 シードはジョブの再現性を制御します。 同じシードとジョブ パラメーターを渡すと同じ結果が得られますが、まれに異なる場合があります。 シードが指定されていない場合は生成されます。
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
ハイパーパラメーターなどの追加の省略可能なパラメーターを渡して、微調整プロセスをより細かく制御することもできます。 初期トレーニングでは、これらのパラメーターを指定せずに、存在する自動既定値を使うことをお勧めします。
現在サポートされている微調整用のハイパーパラメーターは次のとおりです。
| 名前 | タイプ | 説明 |
|---|---|---|
batch_size |
integer | トレーニングに使用するバッチ サイズ。 バッチ サイズは、単一の順方向および逆方向の合格をトレーニングするために使用するトレーニング例の数です。 一般的に、大規模なデータセットでは、バッチ サイズが大きいほど適切に機能する傾向があることがわかっています。 このプロパティの既定値と最大値は、基本モデルに固有です。 バッチ サイズが大きいほど、モデル パラメーターの更新頻度は低くなりますが、分散は小さくなります。 |
learning_rate_multiplier |
数値 | トレーニングに使用する学習率乗数。 微調整の学習率は、事前トレーニングに使用された元の学習率にこの値を掛けた値です。 学習率が高いほど、大きいバッチ サイズでのパフォーマンスが向上する傾向があります。 0.02 から 0.2 の範囲の値を試して、最適な結果が得られるものを確認することをお勧めします。 学習率を低くすると、オーバーフィットを避けるのに役立つ場合があります。 |
n_epochs |
integer | モデルをトレーニングするエポックの数。 エポックとは、トレーニング データセット全体での 1 つの完全なサイクルを指します。 |
seed |
integer | シードはジョブの再現性を制御します。 同じシードとジョブ パラメーターを渡すと同じ結果が得られますが、まれに異なる場合があります。 シードが指定されていない場合は生成されます。 |
OpenAI Python API の 1.x バージョンでカスタム ハイパーパラメーターを設定するには:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required to access fine-tuning for turbo/babbage-002/davinci-002
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
微調整ジョブの状態を確認する
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
微調整イベントの一覧
トレーニング中に生成された個々の微調整イベントを調べるには、次の操作を行います。
このコマンドを実行するには、pip install openai --upgrade を使用して OpenAI クライアント ライブラリを最新バージョンにアップグレードする必要がある場合があります。
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
チェックポイント
各トレーニング エポックが完了すると、チェックポイントが生成されます。 チェックポイントは、完全な機能を持つモデルのバージョンであり、デプロイすることも、後続の微調整ジョブのターゲット モデルとして使用することもできます。 チェックポイントは、オーバーフィットが発生する前のモデルのスナップショットを提供できるため、特に有益です。 微調整が完了すると、3 つの最新バージョンのモデルをデプロイできるようになります。 最後のエポックは微調整されたモデルで表され、前の 2 つのエポックはチェックポイントとして利用できます。
個々の微調整ジョブに関連付けられたチェックポイントの一覧を取得するために、list checkpoints コマンドを実行できます。
このコマンドを実行するには、pip install openai --upgrade を使用して OpenAI クライアント ライブラリを最新バージョンにアップグレードする必要がある場合があります。
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
安全性評価 GPT-4、GPT-4o、GPT-4o-mini の微調整 - パブリック プレビュー
GPT-4o、GPT-4o-mini、GPT-4 は、お客様のニーズに合わせて微調整できる最も高度なモデルです。 Azure OpenAI の他のモデルと同様、微調整されたモデルは高度な機能を備えていますが、その分、有害なコンテンツの生成、操作、人間のような振る舞い、プライバシー問題など、責任ある AI の利用に関する課題も増大します。 リスク、機能、制限に関する詳細については、「責任ある AI プラクティスの概要」および「透明性に関する注意事項」をご参照ください。 高度に微調整されたモデルに伴うリスク軽減のため、微調整されたモデルのトレーニングと出力において有害なコンテンツを検出し、その生成を防止する追加の評価手順を導入しました。 これらの手順は、「Microsoft の責任ある AI の基本原則」と「Azure OpenAI Service のコンテンツのフィルター処理」に準拠しています。
- 評価は、顧客ごとに専用のプライベート ワークスペースを設けて実施されます。
- 評価エンドポイントは Azure OpenAI リソースと同じ地域に配置されます。
- 評価の実施に際し、トレーニング データは保存されず、最終的なモデル評価 (デプロイの可否) のみが保存されます。
GPT-4o、GPT-4o-mini、GPT-4 のファインチューニングされたモデルの評価フィルターは定義済みのしきい値に設定されており、お客様が変更することはできません。お客様が作成したカスタム コンテンツのフィルタリング構成には関連付けられません。
データの評価
トレーニングを開始する前に、データ内に潜む可能性のある有害コンテンツ (暴力、性的、ヘイト、公平性、自傷行為など - 各カテゴリの定義はこちら) の評価が行われます。 指定された重大度レベルを超える有害なコンテンツが検出された場合、トレーニング ジョブは失敗し、失敗の原因となったカテゴリを通知するメッセージが表示されます。
サンプル メッセージ:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
微調整機能の一環として、お客様のトレーニング データは、データ インポート ジョブにおいて自動的に評価されます。
トレーニング データで有害なコンテンツが検出されて微調整ジョブが失敗した場合、課金されません。
モデルの評価
トレーニング完了後、微調整されたモデルをデプロイできるようになる前に、Azure に組み込まれているリスクおよび安全性の指標を用いて、モデルが有害な応答を生成する可能性がないか評価されます。 大規模言語モデルのベースモデルと同じテスト手法を用いて、微調整済みモデルとの会話をシミュレートし、有害なコンテンツを出力する可能性を評価します。評価では、暴力、性的、ヘイト、公平性、自傷行為といった特定の有害なコンテンツのカテゴリを使用します。
モデルが許容範囲を超えて有害なコンテンツを含む出力を生成する場合、モデルはデプロイできなくなり、具体的にどの有害カテゴリが検出されたかについての情報が提供されます。
サンプル メッセージ:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
データ評価と同様、微調整機能を提供する一環として、モデルは微調整ジョブ内で自動的に評価されます。 サービスによりログに記録されるのは、結果として得られた評価 (デプロイの可否) のみです。 微調整されたモデルのデプロイ時に、モデルの出力が有害なコンテンツを含むと判断されデプロイされなかった場合、トレーニングにかかった費用は発生しません。
微調整されたモデルをデプロイする
微調整ジョブが成功すると、応答本文の fine_tuned_model 変数の値がカスタマイズされたモデルの名前に設定されます。 これで、モデルは list Models API からも検出するできるようになります。 ただし、カスタマイズしたモデルがデプロイされるまで、カスタマイズしたモデルに対して候補呼び出しを発行することはできません。 カスタマイズしたモデルを候補呼び出しで使用できるようにするには、デプロイする必要があります。
重要
カスタマイズされたモデルをデプロイした後、デプロイが 15 日を超えて非アクティブのままである場合、デプロイは削除されます。 カスタマイズされたモデルのデプロイは、モデルが 15 日以上前にデプロイされ、15 日間連続して完了またはチャット完了の呼び出しが行われなかった場合、"非アクティブ" になります。
非アクティブなデプロイを削除しても、基になるカスタマイズされたモデルは削除されることも影響を受けることもなく、カスタマイズされたモデルはいつでも再デプロイできます。 「Azure OpenAI Service の価格」で説明されているように、デプロイ済みのカスタマイズされた (微調整された) 各モデルには、補完またはチャット補完の呼び出しがモデルに対して行われているかどうかに関係なく、1 時間ごとのホスティング コストが発生します。 Azure OpenAI を使用したコストの計画と管理の詳細については、「Azure OpenAI Service のコストを管理するための計画」のガイダンスを参照してください。
また、Azure AI Foundry または Azure CLI を使用して、カスタマイズしたモデルをデプロイすることもできます。
Note
カスタマイズしたモデルに対して許可されるデプロイは 1 つだけです。 既にデプロイされているカスタマイズしたモデルを選択すると、エラーが発生します。
前の SDK コマンドとは異なり、個別の認可、異なる API パス、および異なる API バージョンを必要とするコントロール プレーン API を使用してデプロイを行う必要があります。
| variable | 定義 |
|---|---|
| token | 認証トークンを生成するには、複数の方法があります。 初期テストの最も簡単な方法は、Azure portal から Cloud Shell を起動することです。 次に、az account get-access-token を実行します。 このトークンは、API テストの一時的な認証トークンとして使用できます。 これを新しい環境変数に格納することをお勧めします。 |
| subscription | 関連付けられている Azure OpenAI リソースのサブスクリプション ID。 |
| resource_group | Azure OpenAI リソースのリソース グループ名。 |
| resource_name | Azure OpenAI リソース名。 |
| model_deployment_name | 微調整された新しいモデル デプロイのカスタム名。 これは、チャット入力候補の呼び出しを行うときにコードで参照される名前です。 |
| fine_tuned_model | この値は、前の手順の微調整ジョブの結果から取得します。 これは gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83 のようになります。 その値を deploy_data json に追加する必要があります。 また、ftchkpt-e559c011ecc04fc68eaa339d8227d02d 形式で表示されるチェックポイント ID を渡すことで、チェックポイントをデプロイすることもできます。 |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
リージョン間デプロイ
微調整では、微調整されたモデルを、モデルが最初に微調整された場所とは異なるリージョンにデプロイすることがサポートされています。 別のサブスクリプション/リージョンにデプロイすることもできます。
唯一の制限は、新しいリージョンが微調整もサポートする必要があることと、サブスクリプション間でデプロイする場合、デプロイ用の認可トークンを生成するアカウントがソース サブスクリプションと宛先サブスクリプションの両方にアクセスできる必要があることです。
以下は、あるサブスクリプション/リージョンで微調整されたモデルを別のサブスクリプション/リージョンにデプロイする例です。
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
同じサブスクリプションであるが異なるリージョン間でデプロイするには、サブスクリプションとリソース グループがソース変数と宛先変数の両方で同一であり、ソースと宛先のリソース名のみが一意である必要があります。
クロス テナントのデプロイ
az account get-access-token --tenant でアクセス トークンを生成するために使用するアカウントには、ソースと宛先の両方の Azure OpenAI リソースに対する、Cognitive Services OpenAI 共同作成者のアクセス許可が必要です。 ソース テナント用と移行先テナント用に、2 つの異なるトークンを生成する必要があります。
import requests
subscription = "DESTINATION-SUBSCRIPTION-ID"
resource_group = "DESTINATION-RESOURCE-GROUP"
resource_name = "DESTINATION-AZURE-OPENAI-RESOURCE-NAME"
model_deployment_name = "DESTINATION-MODEL-DEPLOYMENT-NAME"
fine_tuned_model = "gpt-4o-mini-2024-07-18.ft-f8838e7c6d4a4cbe882a002815758510" #source fine-tuned model id example id provided
source_subscription_id = "SOURCE-SUBSCRIPTION-ID"
source_resource_group = "SOURCE-RESOURCE-GROUP"
source_account = "SOURCE-AZURE-OPENAI-RESOURCE-NAME"
dest_token = "DESTINATION-ACCESS-TOKEN" # az account get-access-token --tenant DESTINATION-TENANT-ID
source_token = "SOURCE-ACCESS-TOKEN" # az account get-access-token --tenant SOURCE-TENANT-ID
headers = {
"Authorization": f"Bearer {dest_token}",
"x-ms-authorization-auxiliary": f"Bearer {source_token}",
"Content-Type": "application/json"
}
url = f"https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}?api-version=2024-10-01"
payload = {
"sku": {
"name": "standard",
"capacity": 1
},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model,
"version": "1",
"sourceAccount": f"/subscriptions/{source_subscription_id}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_account}"
}
}
}
response = requests.put(url, headers=headers, json=payload)
# Check response
print(f"Status Code: {response.status_code}")
print(f"Response: {response.json()}")
Azure CLI を使用してモデルをデプロイする
次の例は、Azure CLI を使用してカスタマイズしたモデルをデプロイする方法を示しています。 Azure CLI では、カスタマイズしたモデルのデプロイの名前を指定する必要があります。 Azure CLI を使ってカスタマイズされたモデルをデプロイする方法の詳細については、az cognitiveservices account deployment を参照してください。
コンソール ウィンドウでこの Azure CLI コマンドを実行するには、次の "<プレースホルダー>" をカスタマイズしたモデルの対応する値に置き換える必要があります。
| プレースホルダー | 値 |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Azure サブスクリプションの名前または ID。 |
| <YOUR_RESOURCE_GROUP> | Azure リソース グループの名前。 |
| <YOUR_RESOURCE_NAME> | Azure OpenAI リソースの名前。 |
| <YOUR_DEPLOYMENT_NAME> | モデル デプロイに使用する名前。 |
| <YOUR_FINE_TUNED_MODEL_ID> | カスタマイズしたモデルの名前。 |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
デプロイされたカスタマイズしたモデルを使用する
カスタム モデルをデプロイしたら、他のデプロイ済みモデルと同様に使用できます。 Azure AI Foundry 内の [プレイグラウンド] を使用して、新しいデプロイを試すことができます。 カスタム モデルでは、他のデプロイ済みモデルと同様に、temperature や max_tokens などの同じパラメーターを引き続き使用できます。 微調整された babbage-002 および davinci-002 モデルに対して、入力候補プレイグラウンドと入力候補 API を使用します。 微調整された gpt-35-turbo-0613 モデルに対して、チャット プレイグラウンドとチャット入力候補 API を使用します。
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
カスタマイズしたモデルを分析する
Azure OpenAI では、各微調整ジョブが完了すると、results.csv という名前の結果ファイルが添付されます。 この結果ファイルを使用して、カスタマイズしたモデルのトレーニングと検証のパフォーマンスを分析できます。 カスタマイズしたモデルごとに結果ファイルのファイル ID が一覧表示され、Python SDK を使用してファイル ID を取得し、分析するために結果ファイルをダウンロードできます。
次の Python の例では、カスタマイズされたモデルの微調整ジョブに添付された最初の結果ファイルのファイル ID を取得し、Python SDK を使って、分析するために作業ディレクトリにファイルをダウンロードします。
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
結果ファイルは、ヘッダー行と、微調整ジョブによって実行される各トレーニング ステップの行が含まれる CSV ファイルです。 この結果ファイルには、次の列が含まれています。
| 列名 | 説明 |
|---|---|
step |
トレーニング ステップの数。 トレーニング ステップは、トレーニング データのバッチに対する前方と後方の 1 回のパスを表します。 |
train_loss |
トレーニング バッチの損失。 |
train_mean_token_accuracy |
モデルによって正しく予測されたトレーニング バッチ内のトークンの割合。 たとえば、バッチ サイズが 3 に設定されていて、データに候補 [[1, 2], [0, 5], [4, 2]] が含まれており、モデルが [[1, 1], [0, 5], [4, 2]] を予測した場合、この値は 0.83 (5/6) に設定されます。 |
valid_loss |
検証バッチの損失。 |
validation_mean_token_accuracy |
モデルによって正しく予測された検証バッチ内のトークンの割合。 たとえば、バッチ サイズが 3 に設定されていて、データに候補 [[1, 2], [0, 5], [4, 2]] が含まれており、モデルが [[1, 1], [0, 5], [4, 2]] を予測した場合、この値は 0.83 (5/6) に設定されます。 |
full_valid_loss |
各エポックの終了時に計算される検証損失。 トレーニングがうまくいった場合は、損失は減少します。 |
full_valid_mean_token_accuracy |
各エポックの終了時に計算された有効平均トークン精度。 トレーニングがうまくいった場合は、トークンの精度が向上します。 |
Azure AI Foundry ポータル内で、results.csv ファイル内のデータをプロットとして表示することもできます。 トレーニング済みのモデルのリンクを選択すると、損失、平均トークンの精度、トークンの精度の 3 つのグラフが表示されます。 検証データを指定した場合、両方のデータセットが同じプロットに表示されます。
時間の経過と同時に減少する損失を探し、精度を向上させます。 トレーニング データと検証データの間に相違がある場合は、オーバーフィットしていることを示している可能性があります。 エポックが少ない、または学習率の乗数が小さいトレーニングを試してみてください。
デプロイ、カスタマイズしたモデル、トレーニング ファイルをクリーンアップする
カスタマイズしたモデルの利用が完了したら、デプロイとモデルを削除できます。 必要に応じて、サービスにアップロードしたトレーニングおよび検証のファイルを削除することもできます。
モデル デプロイの削除
重要
カスタマイズされたモデルをデプロイした後、デプロイが 15 日を超えて非アクティブのままである場合、デプロイは削除されます。 カスタマイズされたモデルのデプロイは、モデルが 15 日以上前にデプロイされ、15 日間連続して完了またはチャット完了の呼び出しが行われなかった場合、"非アクティブ" になります。
非アクティブなデプロイを削除しても、基になるカスタマイズされたモデルは削除されることも影響を受けることもなく、カスタマイズされたモデルはいつでも再デプロイできます。 「Azure OpenAI Service の価格」で説明されているように、デプロイ済みのカスタマイズされた (微調整された) 各モデルには、補完またはチャット補完の呼び出しがモデルに対して行われているかどうかに関係なく、1 時間ごとのホスティング コストが発生します。 Azure OpenAI を使用したコストの計画と管理の詳細については、「Azure OpenAI Service のコストを管理するための計画」のガイダンスを参照してください。
さまざまな方法を使用して、カスタマイズしたモデルのデプロイを削除できます。
カスタマイズしたモデルの削除
同様に、さまざまな方法を使用して、カスタマイズしたモデルを削除できます。
Note
既存のデプロイがある場合は、カスタマイズしたモデルを削除できません。 カスタマイズしたモデルを削除する前に、まずモデル デプロイを削除する必要があります。
トレーニング ファイルの削除
必要に応じて、トレーニング用にアップロードしたトレーニングおよび検証のファイル、およびトレーニング中に生成された結果ファイルを、Azure OpenAI サブスクリプションから削除できます。 次の方法を使用して、トレーニング、検証、および結果のファイルを削除できます。
- Azure AI Foundry
- REST API
- Python SDK
次の Python の例では、Python SDK を使用して、カスタマイズしたモデルのトレーニング、検証、および結果のファイルを削除します。
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
継続的な微調整
微調整されたモデルを作成したら、さらに微調整を行い時間をかけてモデルを改良し続けることができます。 継続的な微調整は、既に微調整されたモデルを基本モデルとして選び、新しいトレーニング サンプルのセットでさらに微調整する反復プロセスです。
以前に微調整したモデルに対して微調整を実行するには、カスタマイズされたモデルを作成するに関するセクションで説明したのと同じプロセスを使いますが、汎用基本モデルの名前を指定する代わりに、既に微調整されたモデルの ID を指定します。 微調整されたモデル ID は gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7 のようになります
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
また、微調整モデルの異なるイテレーションを区別しやすくするために、suffix パラメーターを含めることをお勧めします。 suffix は文字列を受け取り、微調整されたモデルを特定するように設定されます。 OpenAI Python API では、微調整されたモデル名に追加される最大 18 文字の文字列がサポートされています。
既存のファインチューニングされたモデルの ID が不明な場合は、Azure AI Foundry の [モデル] ページの中でこの情報を確認できます。または REST API を使用して、特定の Azure OpenAI リソースのモデルの一覧を生成できます。
前提条件
- Azure OpenAI の微調整ガイドを使用する場合を参照してください。
- Azure サブスクリプション。 無料で作成できます。
- Azure OpenAI リソース。 詳細については、「Azure OpenAI を使用してリソースを作成し、モデルをデプロイする」を参照してください。
- アクセスの微調整には、Cognitive Services OpenAI 共同作成者が必要です。
- Azure AI Foundry ポータル内でクォータを表示する、およびモデルをデプロイするためのアクセスがまだない場合は、追加のアクセス許可が必要になります。
モデル
次のモデルでは、微調整がサポートされます。
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* このモデルのファインチューニングは、現在パブリック プレビューです。
または、base-model.ft-{jobid} として書式設定された、以前に微調整されたモデルを微調整することもできます。
現在微調整をサポートしているリージョンを確認するには、モデルに関するページを参照してください。
REST API のワークフローを確認する
少し時間を取って、REST API および Python と Azure OpenAI を使用するための微調整ワークフローを確認してください。
- トレーニングおよび検証用のデータを準備します。
- 基本モデルを選択します。
- トレーニング データをアップロードします。
- 新たにカスタマイズしたモデルをトレーニングします。
- カスタマイズしたモデルの状態を確認します。
- カスタマイズしたモデルをデプロイして使用できるようにします。
- カスタマイズしたモデルを使用します。
- 必要に応じて、カスタマイズしたモデルをパフォーマンスと適合度を分析します。
トレーニング データと検証データを準備する
トレーニング データと検証データのセットは、モデルの実行方法に関する入力と出力の例で構成されます。
モデルの種類が異なると、異なる形式のトレーニング データが必要になります。
使用するトレーニングおよび検証データは、JSON Lines (JSONL) ドキュメントの形式である必要があります。 gpt-35-turbo-0613 とその他の関連モデルの場合、微調整データセットの形式は、チャット入力候補 API で使用される会話形式にする必要があります。
gpt-35-turbo-0613 の微調整の詳細な手順については、Azure OpenAI の微調整に関するチュートリアルを参照してください。
ファイル形式の例
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
マルチターン チャット ファイル形式
jsonl トレーニング ファイルの 1 行での会話の複数のターンもサポートされています。 特定のアシスタント メッセージの微調整をスキップするには、オプションの weight キー値ペアを追加します。 現在、weight は 0 または 1 に設定できます。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
vision でのチャット補完
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
JSONL 形式に加えて、トレーニングおよび検証のデータ ファイルは UTF-8 でエンコードしてバイトオーダー マーク (BOM) を含める必要があります。 ファイルは、512 MB 未満のサイズにする必要があります。
トレーニングおよび検証のデータセットを作成する
トレーニング例が多いほど適切になります。 微調整ジョブは、少なくとも 10 個のトレーニング例がないと続行されませんが、このような少数ではモデルの応答に顕著な影響を与えるには不十分です。 成功するには、数千ではないにしても数百のトレーニング例を提供することをお勧めします。
一般的に、データセット サイズを 2 倍にすると、モデルの品質を直線的に向上させることができます。 ただし、低品質の例はパフォーマンスに悪影響を与える可能性があることに注意してください。 大量の内部データでモデルをトレーニングする場合、最初に最高品質の例のみになるようにデータセットを取り除かないと、予想よりもはるかにパフォーマンスの低いモデルになる可能性があります。
基本モデルを選択する
カスタム モデルを作成するための最初の手順は、基本モデルを選択することです。 [Base model](基本モデル) ウィンドウで、カスタム モデルに使用する基本モデルを選択できます。 この選択は、モデルのパフォーマンスとコストの両方に影響します。
[Base model type](基本モデルの種類) ドロップダウンから基本モデルを選択し、[次へ] を選択して続行します。
次の使用可能な基本モデルのいずれかから、カスタム モデルを作成できます。
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)gpt-4o(2024-08-06)gpt-4o-mini(2023-07-18)
または、base-model.ft-{jobid} として書式設定された、以前に微調整されたモデルを微調整することもできます。
微調整が可能な基本モデルの詳細については、モデルに関する記事を参照してください。
トレーニング データをアップロードする
次の手順では、既存の準備済みトレーニング データを選択するか、新しい準備済みトレーニング データをアップロードして、モデルを微調整するときに使用します。 トレーニング データを準備したら、ファイルをサービスにアップロードできます。 トレーニング データをアップロードする方法は 2 つあります。
大きなデータ ファイルの場合は、Azure BLOB ストアからインポートすることをお勧めします。 大きなファイルは、マルチパート フォームを介してアップロードすると不安定になる場合があります。要求がアトミックであり、再試行または再開ができないためです。 Azure Blob Storage の詳細については、「Azure Blob Storage とは」を参照してください。
Note
トレーニング データ ファイルは、JSONL ファイル形式にし、バイトオーダー マーク (BOM) を使用して UTF-8 でエンコードする必要があります。 ファイルは、512 MB 未満のサイズにする必要があります。
トレーニング データのアップロード
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
検証データのアップロード
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
カスタマイズしたモデルを作成する
トレーニングおよび検証ファイルをアップロードしたら、微調整ジョブを開始する準備が整います。 次のコードは、REST API を使って新しい微調整ジョブを作成する方法の例を示しています。
この例では、seed パラメーターも渡しています。 シードはジョブの再現性を制御します。 同じシードとジョブ パラメーターを渡すと同じ結果が得られますが、まれに異なる場合があります。 シードが指定されていない場合は生成されます。
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
ハイパーパラメーターなどの追加の省略可能なパラメーターを渡して、微調整プロセスをより細かく制御することもできます。 初期トレーニングでは、これらのパラメーターを指定せずに、存在する自動既定値を使うことをお勧めします。
現在サポートされている微調整用のハイパーパラメーターは次のとおりです。
| 名前 | タイプ | 説明 |
|---|---|---|
batch_size |
integer | トレーニングに使用するバッチ サイズ。 バッチ サイズは、単一の順方向および逆方向の合格をトレーニングするために使用するトレーニング例の数です。 一般的に、大規模なデータセットでは、バッチ サイズが大きいほど適切に機能する傾向があることがわかっています。 このプロパティの既定値と最大値は、基本モデルに固有です。 バッチ サイズが大きいほど、モデル パラメーターの更新頻度は低くなりますが、分散は小さくなります。 |
learning_rate_multiplier |
数値 | トレーニングに使用する学習率乗数。 微調整の学習率は、事前トレーニングに使用された元の学習率にこの値を掛けた値です。 学習率が高いほど、大きいバッチ サイズでのパフォーマンスが向上する傾向があります。 0.02 から 0.2 の範囲の値を試して、最適な結果が得られるものを確認することをお勧めします。 学習率を低くすると、オーバーフィットを避けるのに役立つ場合があります。 |
n_epochs |
integer | モデルをトレーニングするエポックの数。 エポックとは、トレーニング データセット全体での 1 つの完全なサイクルを指します。 |
seed |
integer | シードはジョブの再現性を制御します。 同じシードとジョブ パラメーターを渡すと同じ結果が得られますが、まれに異なる場合があります。 シードが指定されていない場合は生成されます。 |
カスタマイズしたモデルの状態を確認する
微調整ジョブを開始した後、完了するまでに時間がかかる場合があります。 ジョブは、システム内の他のジョブの後にキューに入れられる場合があります。 モデルのトレーニングには、モデルおよびデータセットのサイズに応じて、数分または数時間かかる場合があります。 次の例では、REST API を使用して、微調整ジョブの状態を確認します。 この例では、前の例で返されたジョブ ID を使用して、ジョブに関する情報を取得します。
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
微調整イベントの一覧
トレーニング中に生成された個々の微調整イベントを調べるには、次の操作を行います。
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
チェックポイント
各トレーニング エポックが完了すると、チェックポイントが生成されます。 チェックポイントは、完全な機能を持つモデルのバージョンであり、デプロイすることも、後続の微調整ジョブのターゲット モデルとして使用することもできます。 チェックポイントは、オーバーフィットが発生する前のモデルのスナップショットを提供できるため、特に有益です。 微調整が完了すると、3 つの最新バージョンのモデルをデプロイできるようになります。 最後のエポックは微調整されたモデルで表され、前の 2 つのエポックはチェックポイントとして利用できます。
個々の微調整ジョブに関連付けられたチェックポイントの一覧を取得するために、list checkpoints コマンドを実行できます。
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
安全性評価 GPT-4、GPT-4o、GPT-4o-mini の微調整 - パブリック プレビュー
GPT-4o、GPT-4o-mini、GPT-4 は、お客様のニーズに合わせて微調整できる最も高度なモデルです。 Azure OpenAI の他のモデルと同様、微調整されたモデルは高度な機能を備えていますが、その分、有害なコンテンツの生成、操作、人間のような振る舞い、プライバシー問題など、責任ある AI の利用に関する課題も増大します。 リスク、機能、制限に関する詳細については、「責任ある AI プラクティスの概要」および「透明性に関する注意事項」をご参照ください。 高度に微調整されたモデルに伴うリスク軽減のため、微調整されたモデルのトレーニングと出力において有害なコンテンツを検出し、その生成を防止する追加の評価手順を導入しました。 これらの手順は、「Microsoft の責任ある AI の基本原則」と「Azure OpenAI Service のコンテンツのフィルター処理」に準拠しています。
- 評価は、顧客ごとに専用のプライベート ワークスペースを設けて実施されます。
- 評価エンドポイントは Azure OpenAI リソースと同じ地域に配置されます。
- 評価の実施に際し、トレーニング データは保存されず、最終的なモデル評価 (デプロイの可否) のみが保存されます。
GPT-4o、GPT-4o-mini、GPT-4 のファインチューニングされたモデルの評価フィルターは定義済みのしきい値に設定されており、お客様が変更することはできません。お客様が作成したカスタム コンテンツのフィルタリング構成には関連付けられません。
データの評価
トレーニングを開始する前に、データ内に潜む可能性のある有害コンテンツ (暴力、性的、ヘイト、公平性、自傷行為など - 各カテゴリの定義はこちら) の評価が行われます。 指定された重大度レベルを超える有害なコンテンツが検出された場合、トレーニング ジョブは失敗し、失敗の原因となったカテゴリを通知するメッセージが表示されます。
サンプル メッセージ:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
微調整機能の一環として、お客様のトレーニング データは、データ インポート ジョブにおいて自動的に評価されます。
トレーニング データで有害なコンテンツが検出されて微調整ジョブが失敗した場合、課金されません。
モデルの評価
トレーニング完了後、微調整されたモデルをデプロイできるようになる前に、Azure に組み込まれているリスクおよび安全性の指標を用いて、モデルが有害な応答を生成する可能性がないか評価されます。 大規模言語モデルのベースモデルと同じテスト手法を用いて、微調整済みモデルとの会話をシミュレートし、有害なコンテンツを出力する可能性を評価します。評価では、暴力、性的、ヘイト、公平性、自傷行為といった特定の有害なコンテンツのカテゴリを使用します。
モデルが許容範囲を超えて有害なコンテンツを含む出力を生成する場合、モデルはデプロイできなくなり、具体的にどの有害カテゴリが検出されたかについての情報が提供されます。
サンプル メッセージ:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
データ評価と同様、微調整機能を提供する一環として、モデルは微調整ジョブ内で自動的に評価されます。 サービスによりログに記録されるのは、結果として得られた評価 (デプロイの可否) のみです。 微調整されたモデルのデプロイ時に、モデルの出力が有害なコンテンツを含むと判断されデプロイされなかった場合、トレーニングにかかった費用は発生しません。
微調整されたモデルをデプロイする
重要
カスタマイズされたモデルをデプロイした後、デプロイが 15 日を超えて非アクティブのままである場合、デプロイは削除されます。 カスタマイズされたモデルのデプロイは、モデルが 15 日以上前にデプロイされ、15 日間連続して完了またはチャット完了の呼び出しが行われなかった場合、"非アクティブ" になります。
非アクティブなデプロイを削除しても、基になるカスタマイズされたモデルは削除されることも影響を受けることもなく、カスタマイズされたモデルはいつでも再デプロイできます。 「Azure OpenAI Service の価格」で説明されているように、デプロイ済みのカスタマイズされた (微調整された) 各モデルには、補完またはチャット補完の呼び出しがモデルに対して行われているかどうかに関係なく、1 時間ごとのホスティング コストが発生します。 Azure OpenAI を使用したコストの計画と管理の詳細については、「Azure OpenAI Service のコストを管理するための計画」のガイダンスを参照してください。
次の Python の例は、REST API を使用して、カスタマイズしたモデルのモデル デプロイを作成する方法を示しています。 REST API は、カスタマイズしたモデルのデプロイの名前を生成します。
| variable | 定義 |
|---|---|
| token | 認証トークンを生成するには、複数の方法があります。 初期テストの最も簡単な方法は、Azure portal から Cloud Shell を起動することです。 次に、az account get-access-token を実行します。 このトークンは、API テストの一時的な認証トークンとして使用できます。 これを新しい環境変数に格納することをお勧めします。 |
| subscription | 関連付けられている Azure OpenAI リソースのサブスクリプション ID。 |
| resource_group | Azure OpenAI リソースのリソース グループ名。 |
| resource_name | Azure OpenAI リソース名。 |
| model_deployment_name | 微調整された新しいモデル デプロイのカスタム名。 これは、チャット入力候補の呼び出しを行うときにコードで参照される名前です。 |
| fine_tuned_model | この値は、前の手順の微調整ジョブの結果から取得します。 これは gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83 のようになります。 その値を deploy_data json に追加する必要があります。 また、ftchkpt-e559c011ecc04fc68eaa339d8227d02d 形式で表示されるチェックポイント ID を渡すことで、チェックポイントをデプロイすることもできます。 |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
リージョン間デプロイ
微調整では、微調整されたモデルを、モデルが最初に微調整された場所とは異なるリージョンにデプロイすることがサポートされています。 別のサブスクリプション/リージョンにデプロイすることもできます。
唯一の制限は、新しいリージョンが微調整もサポートする必要があることと、サブスクリプション間でデプロイする場合、デプロイ用の認可トークンを生成するアカウントがソース サブスクリプションと宛先サブスクリプションの両方にアクセスできる必要があることです。
以下は、あるサブスクリプション/リージョンで微調整されたモデルを別のサブスクリプション/リージョンにデプロイする例です。
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
同じサブスクリプションであるが異なるリージョン間でデプロイするには、サブスクリプションとリソース グループがソース変数と宛先変数の両方で同一であり、ソースと宛先のリソース名のみが一意である必要があります。
クロス テナントのデプロイ
az account get-access-token --tenant でアクセス トークンを生成するために使用するアカウントには、ソースと宛先の両方の Azure OpenAI リソースに対する、Cognitive Services OpenAI 共同作成者のアクセス許可が必要です。 ソース テナント用と移行先テナント用に、2 つの異なるトークンを生成する必要があります。
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-01" \
-H "Authorization: Bearer <DESTINATION TOKEN>" \
-H "x-ms-authorization-auxiliary: Bearer <SOURCE TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"sourceAccount": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Azure CLI を使用してモデルをデプロイする
次の例は、Azure CLI を使用してカスタマイズしたモデルをデプロイする方法を示しています。 Azure CLI では、カスタマイズしたモデルのデプロイの名前を指定する必要があります。 Azure CLI を使ってカスタマイズされたモデルをデプロイする方法の詳細については、az cognitiveservices account deployment を参照してください。
コンソール ウィンドウでこの Azure CLI コマンドを実行するには、次の "<プレースホルダー>" をカスタマイズしたモデルの対応する値に置き換える必要があります。
| プレースホルダー | 値 |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Azure サブスクリプションの名前または ID。 |
| <YOUR_RESOURCE_GROUP> | Azure リソース グループの名前。 |
| <YOUR_RESOURCE_NAME> | Azure OpenAI リソースの名前。 |
| <YOUR_DEPLOYMENT_NAME> | モデル デプロイに使用する名前。 |
| <YOUR_FINE_TUNED_MODEL_ID> | カスタマイズしたモデルの名前。 |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
デプロイされたカスタマイズしたモデルを使用する
カスタム モデルをデプロイしたら、他のデプロイ済みモデルと同様に使用できます。 Azure AI Foundry 内の [プレイグラウンド] を使用して、新しいデプロイを試すことができます。 カスタム モデルでは、他のデプロイ済みモデルと同様に、temperature や max_tokens などの同じパラメーターを引き続き使用できます。 微調整された babbage-002 および davinci-002 モデルに対して、入力候補プレイグラウンドと入力候補 API を使用します。 微調整された gpt-35-turbo-0613 モデルに対して、チャット プレイグラウンドとチャット入力候補 API を使用します。
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
カスタマイズしたモデルを分析する
Azure OpenAI では、各微調整ジョブが完了すると、results.csv という名前の結果ファイルが添付されます。 この結果ファイルを使用して、カスタマイズしたモデルのトレーニングと検証のパフォーマンスを分析できます。 カスタマイズしたモデルごとに結果ファイルのファイル ID が一覧表示され、REST API を使用してファイル ID を取得し、分析するために結果ファイルをダウンロードできます。
次の Python の例では、REST API を使ってカスタマイズしたモデルの微調整ジョブに添付された最初の結果ファイルのファイル ID を取得し、分析するために作業ディレクトリにファイルをダウンロードします。
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
結果ファイルは、ヘッダー行と、微調整ジョブによって実行される各トレーニング ステップの行が含まれる CSV ファイルです。 この結果ファイルには、次の列が含まれています。
| 列名 | 説明 |
|---|---|
step |
トレーニング ステップの数。 トレーニング ステップは、トレーニング データのバッチに対する前方と後方の 1 回のパスを表します。 |
train_loss |
トレーニング バッチの損失。 |
train_mean_token_accuracy |
モデルによって正しく予測されたトレーニング バッチ内のトークンの割合。 たとえば、バッチ サイズが 3 に設定されていて、データに候補 [[1, 2], [0, 5], [4, 2]] が含まれており、モデルが [[1, 1], [0, 5], [4, 2]] を予測した場合、この値は 0.83 (5/6) に設定されます。 |
valid_loss |
検証バッチの損失。 |
validation_mean_token_accuracy |
モデルによって正しく予測された検証バッチ内のトークンの割合。 たとえば、バッチ サイズが 3 に設定されていて、データに候補 [[1, 2], [0, 5], [4, 2]] が含まれており、モデルが [[1, 1], [0, 5], [4, 2]] を予測した場合、この値は 0.83 (5/6) に設定されます。 |
full_valid_loss |
各エポックの終了時に計算される検証損失。 トレーニングがうまくいった場合は、損失は減少します。 |
full_valid_mean_token_accuracy |
各エポックの終了時に計算された有効平均トークン精度。 トレーニングがうまくいった場合は、トークンの精度が向上します。 |
Azure AI Foundry ポータル内で、results.csv ファイル内のデータをプロットとして表示することもできます。 トレーニング済みのモデルのリンクを選択すると、損失、平均トークンの精度、トークンの精度の 3 つのグラフが表示されます。 検証データを指定した場合、両方のデータセットが同じプロットに表示されます。
時間の経過と同時に減少する損失を探し、精度を向上させます。 トレーニング データと検証データの間に相違がある場合は、オーバーフィットしていることを示している可能性があります。 エポックが少ない、または学習率の乗数が小さいトレーニングを試してみてください。
デプロイ、カスタマイズしたモデル、トレーニング ファイルをクリーンアップする
カスタマイズしたモデルの利用が完了したら、デプロイとモデルを削除できます。 必要に応じて、サービスにアップロードしたトレーニングおよび検証のファイルを削除することもできます。
モデル デプロイの削除
さまざまな方法を使用して、カスタマイズしたモデルのデプロイを削除できます。
カスタマイズしたモデルの削除
同様に、さまざまな方法を使用して、カスタマイズしたモデルを削除できます。
Note
既存のデプロイがある場合は、カスタマイズしたモデルを削除できません。 カスタマイズしたモデルを削除する前に、まずモデル デプロイを削除する必要があります。
トレーニング ファイルの削除
必要に応じて、トレーニング用にアップロードしたトレーニングおよび検証のファイル、およびトレーニング中に生成された結果ファイルを、Azure OpenAI サブスクリプションから削除できます。 次の方法を使用して、トレーニング、検証、および結果のファイルを削除できます。
継続的な微調整
微調整されたモデルを作成したら、さらに微調整を行い時間をかけてモデルを改良し続けることができます。 継続的な微調整は、既に微調整されたモデルを基本モデルとして選び、新しいトレーニング サンプルのセットでさらに微調整する反復プロセスです。
以前に微調整したモデルに対して微調整を実行するには、カスタマイズされたモデルを作成するに関するセクションで説明したのと同じプロセスを使いますが、汎用基本モデルの名前を指定する代わりに、既に微調整されたモデルの ID を指定します。 微調整されたモデル ID は gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7 のようになります
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
また、微調整モデルの異なるイテレーションを区別しやすくするために、suffix パラメーターを含めることをお勧めします。 suffix は文字列を受け取り、微調整されたモデルを特定するように設定されます。 サフィックスには最大 40 文字 (a-z、A-Z、0-9、-、_) を指定することができ、微調整したモデル名に追加されます。
ファインチューニングされたモデルの ID が不明な場合は、Azure AI Foundry の [モデル] ページの中でこの情報を確認できます。または REST API を使用して、特定の Azure OpenAI リソースのモデルの一覧を生成できます。
グローバル標準 (プレビュー)
Azure OpenAI の微調整では、米国東部 2、米国中北部、スウェーデン中部における以下のグローバル標準の展開がサポートされます。
gpt-4o-mini-2024-07-18gpt-4o-2024-08-06(2025 年 1 月まで、新規デプロイは利用できません)
グローバル標準の微調整された展開によりコスト削減が提供されますが、カスタム モデルの重みは、Azure OpenAI リソースの地理的な外部に一時的に格納される場合があります。

グローバル標準の微調整の展開は、現在、ビジョンおよび構造化出力をサポートしていません。
Vision の微調整
JSONL ファイル形式の画像を使用して微調整することもできます。 チャット補完に 1 つまたは複数の画像入力を送信できるのと同じく、トレーニング データにも同様のメッセージの種類を含めることができます。 画像は、パブリック アクセスが可能な URL または Base64 にエンコードされた画像を含むデータ URI として提供できます。
画像データセットの要件
- トレーニング ファイルには、画像を含む例 (テキスト例を含まない) を最大 50,000 件含めることができます。
- 各例には、最大で 64 件の画像を含めることができます。
- 各画像サイズは最大で 10 MB です。
形式
画像形式は次のとおりです。
- JPEG
- PNG
- WEBP
画像モードは RGB または RGBA である必要があります。
アシスタント ロールのメッセージからの出力画像を含めることはできません。
コンテンツ モデレーション ポリシー
画像はトレーニング前にスキャンされ、利用ポリシーの「透過性のためのメモ」に準拠していることが確認されます。 これにより、微調整開始前のファイル検証に待機時間が生じる可能性があります。
次のものが含まれる画像はデータセットから除外され、トレーニングには使用されません。
- ユーザー
- 顔
- CAPTCHA
重要
Vision の微調整における顔スクリーニングプロセスでは、顔/人をスクリーニングして、対象の画像をモデルのトレーニングからスキップするようにします。 スクリーニング機能では、顔の識別を行うことなく、顔検出を活用します。つまり、顔テンプレートを作成したり、特定の顔ジオメトリを測定したりすることはなく、顔のスクリーニングに使用されるテクノロジでは、個人を一意に識別することはできません。 顔のデータとプライバシーの詳細については、「Face - Azure AI サービスのデータとプライバシー | Microsoft Learn」を参照してください。
プロンプト キャッシュ
Azure OpenAI の微調整では、一部のモデルでプロンプト キャッシュをサポートしています。 プロンプト キャッシュを使用すると、プロンプトの先頭のコンテンツが同一のより長いプロンプトに対する要求の全体的な待機時間とコストを削減できます。 プロンプト キャッシュの詳細については、プロンプト キャッシュの概要に関するページを参照してください。
直接選好最適化 (DPO) (プレビュー)
直接選好最適化 (DPO) は、大規模言語モデル用の調整手法であり、人間の嗜好に基づいてモデルの重みを調整するために使用されます。 これは、報酬モデルの適合を必要とせず、トレーニングに単純なバイナリ データの選好を使用するという点で、人間のフィードバックによる強化学習 (RLHF) とは異なります。 RLHF よりも計算量が少なく高速でありながら、調整においては同等の効果があります。
DPO が有用な理由
DPO は、明確な正解が存在せず、トーンやスタイル、特定のコンテンツの嗜好といった主観的な要素が重要なシナリオで特に役立ちます。 このアプローチにより、モデルは肯定的な例 (正しいか理想的と考えられるもの) と否定的な例 (望ましくないか間違っているもの) の両方から学習することもできます。
DPO は、顧客が高品質のトレーニング データ セットを生成しやすくする手法であると考えられています。 多くの顧客は、教師あり微調整に十分な大規模データ セットを生成するのに苦労していますが、ユーザー ログ、A/B テスト、または小規模な手動注釈作業に基づいて、選好データが既に収集されている場合がよくあります。
直接選好の最適化データセット形式
直接選好の最適化ファイルの形式は、教師あり微調整のものとは異なります。 顧客は、システム メッセージと初期ユーザー メッセージを含む "会話" を提供し、その後、ペアになった選好データを含む "入力候補" を提供します。 ユーザーが提供できるのは 2 つの入力候補のみです。
3 つの上位フィールド: input、preferred_output、non_preferred_output
- preferred_output、non_preferred_output の各要素には、少なくとも 1 つのアシスタント メッセージが含まれている必要があります
- preferred_output、non_preferred_output の各要素は、(assistant、tool) のロールのみを持つことができます
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
トレーニング データセットは jsonl 形式である必要があります。
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
直接選好の最適化モデルのサポート
gpt-4o-2024-08-06は、それぞれの微調整リージョンで直接選好の最適化をサポートします。 モデルのページで、最新の利用可能なリージョンが更新されます
ユーザーは、サポートされているモデルやバージョンである限り、基本モデルだけでなく、教師あり微調整を使用して既に微調整されているモデルでも、選好の微調整を利用できます。
直接選好の最適化微調整を使用する方法
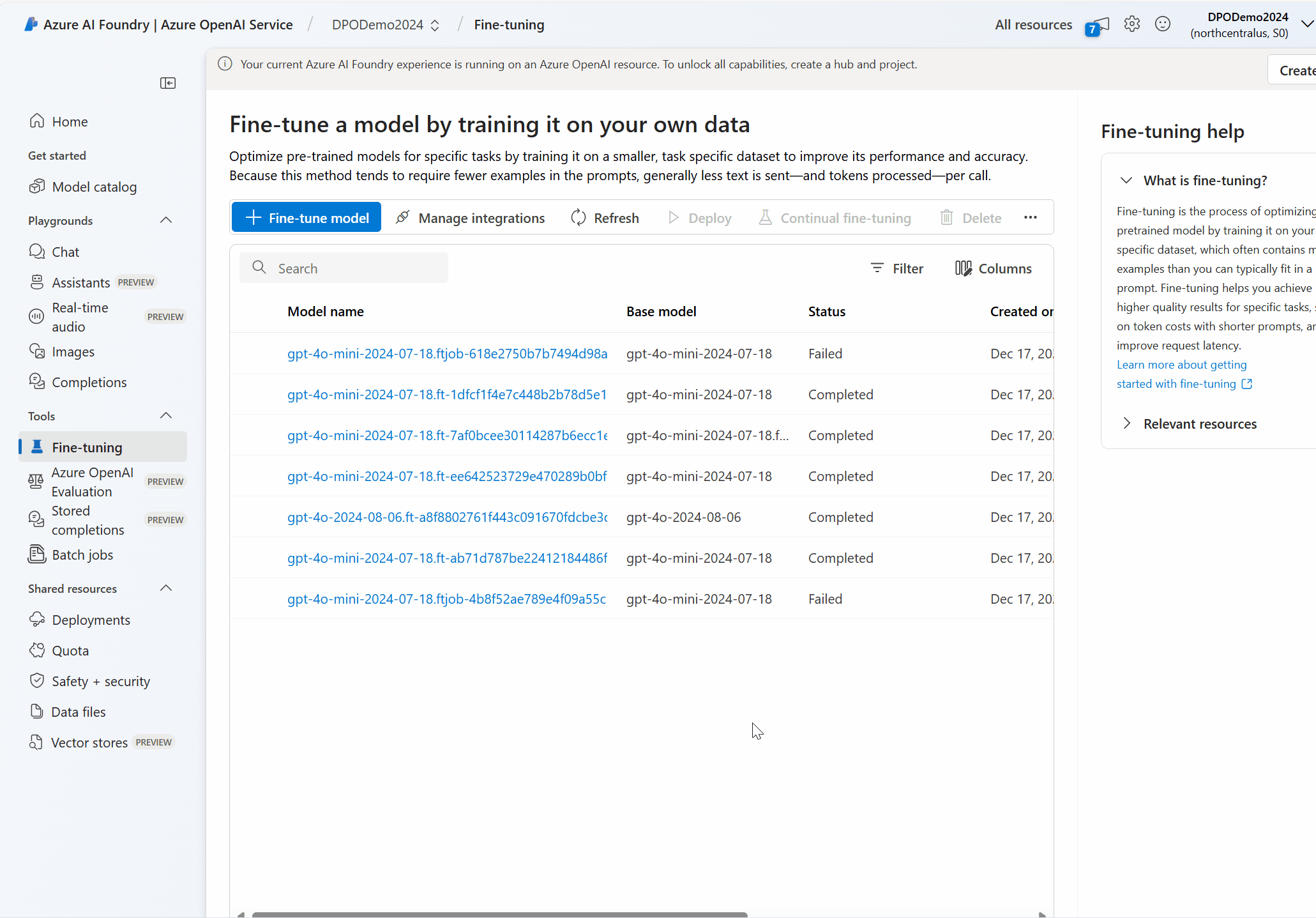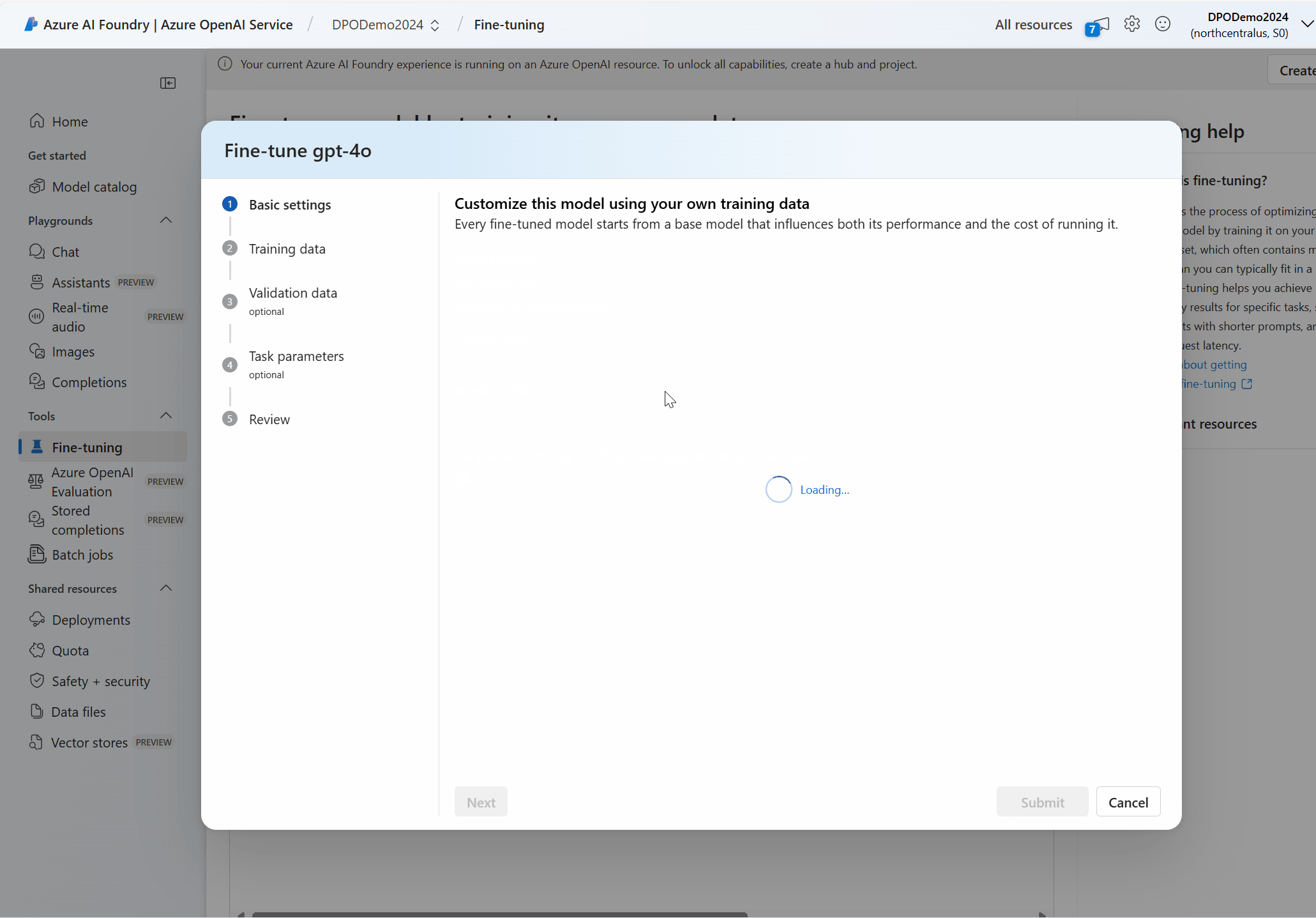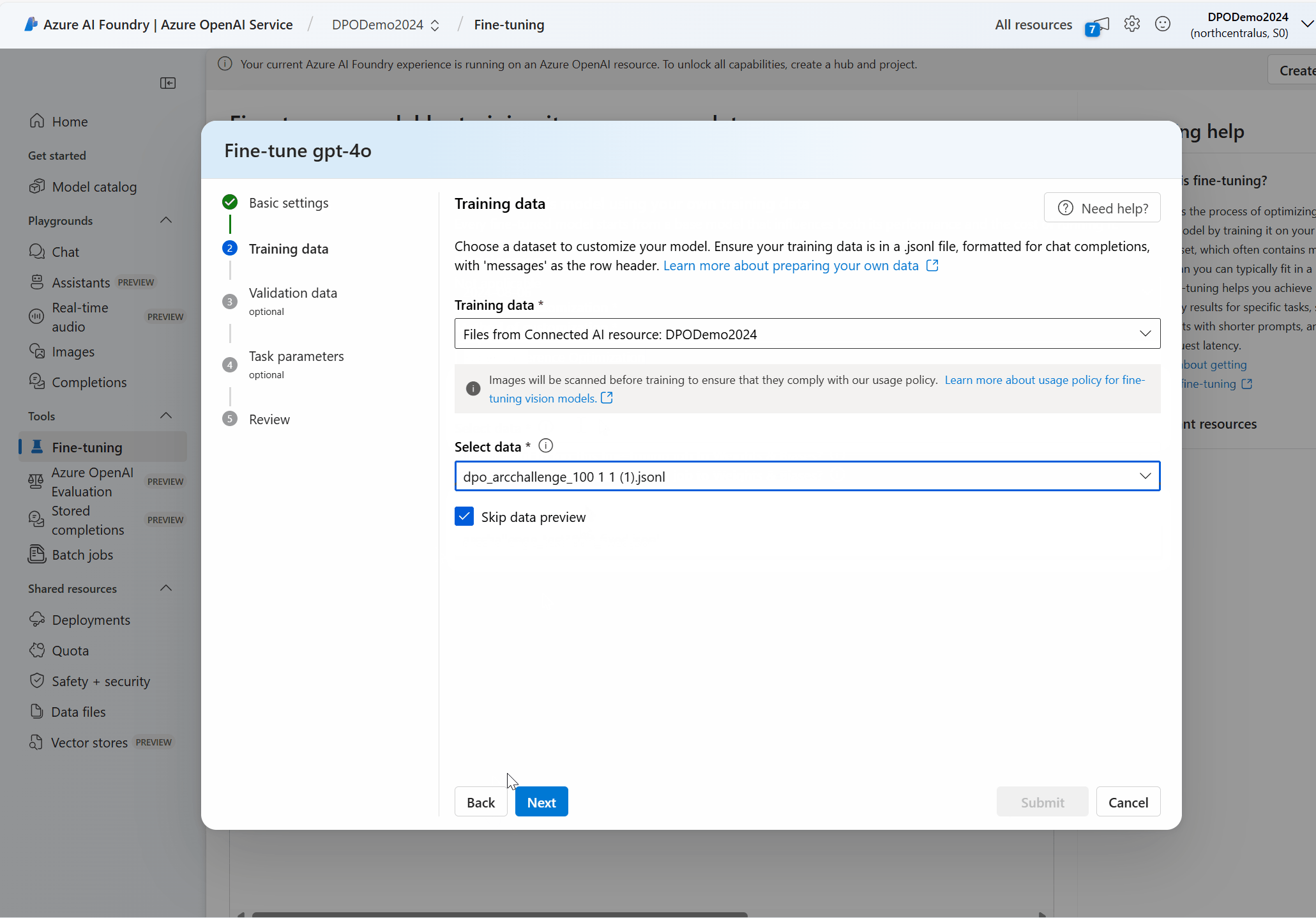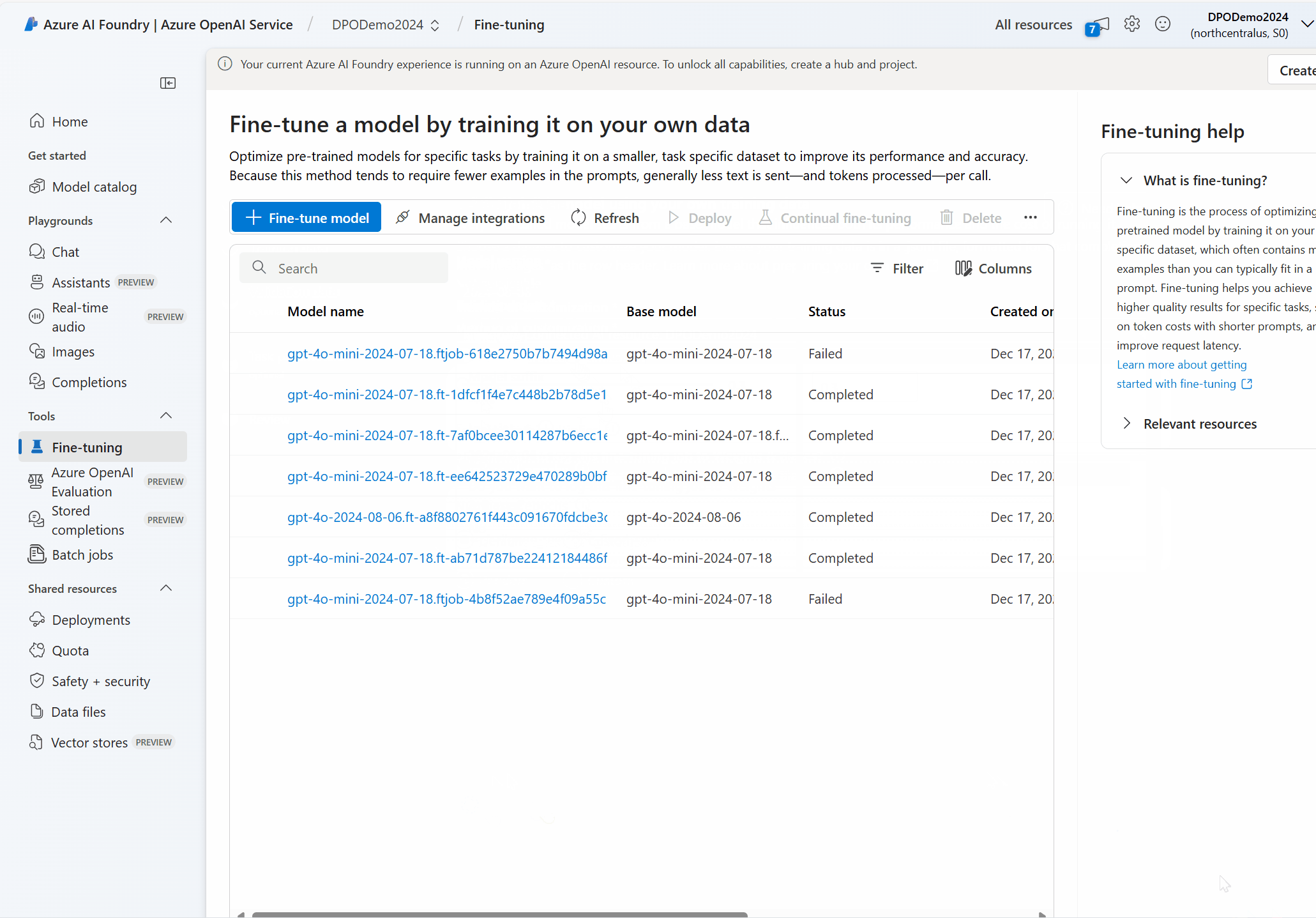
jsonlのデータセットを選好の形式で用意します。- モデルを選択し、カスタマイズ方法 [直接選好の最適化] を選択します。
- データセット - トレーニングと検証をアップロードします。 必要に応じてプレビューします。
- ハイパーパラメーターを選択します。最初の実験には既定値をお勧めします。
- 選択内容を確認し、微調整ジョブを作成します。
トラブルシューティング
微調整はどのように有効にしますか?
微調整に正常にアクセスするには、Cognitive Services OpenAI 共同作成者が割り当てられている必要があります。 高度なサービス管理者のアクセス許可を持つユーザーでも、微調整にアクセスするためにはこのアカウントを明示的に設定する必要があります。 詳細については、ロールベースのアクセス制御のガイダンスに関するページを参照してください。
アップロードが失敗した理由
Azure AI Foundry ポータルでファイルのアップロードが失敗した場合は、Azure AI Foundry ポータルの [データ ファイル] の下にエラー メッセージを表示できます。 「エラー」と表示されている場所 (状態列の下) にマウス ポインターを置くと、エラーの説明が表示されます。

微調整されたモデルが改善されていないようです
システムメッセージがありません: 微調整するときにシステムメッセージを提供する必要があります。微調整されたモデルを使用する場合は、同じシステム メッセージを提供する必要があります。 別のシステム メッセージを指定すると、微調整した結果とは異なる結果が表示されることがあります。
十分なデータがありません: パイプラインを実行するには 10 が最小ですが、モデルに新しいスキルを教えるには数百から数千のデータ ポイントが必要です。 データ ポイントが少なすぎると、オーバーフィットや一般化の不十分なリスクがあります。 微調整されたモデルはトレーニング データに対して適切に動作する可能性がありますが、学習パターンの代わりにトレーニング例を記憶しているため、他のデータではパフォーマンスが低下する可能性があります。 最適な結果を得るには、数百または数千のデータ ポイントを含むデータ セットを準備することを計画してください。
不適切なデータ: 不適切にキュレーションされたデータセットまたは表現されていないデータセットは、低品質のモデルを生成します。 モデルは、データセットから不正確または偏ったパターンを学習する場合があります。 たとえば、顧客サービスのチャットボットをトレーニングしているが、1 つのシナリオ (アイテムの返品など) のトレーニング データのみを提供する場合、他のシナリオに対応する方法はわかりません。 または、トレーニング データが正しくない (不適切な応答が含まれている) 場合、モデルは間違った結果を提供することを学習します。
vision での微調整
画像がスキップされた場合には
次の理由により、画像がスキップされる場合があります。
- CAPTCHA が含まれている
- 人物が含まれている
- 顔が含まれている
画像を削除してください。 現時点では、これらのエンティティが含まれる画像を使用して、モデルを微調整することはできません。
一般的な問題
| 問題点 | 原因/解決策 |
|---|---|
| 画像がスキップされる | 画像に CAPTCHA、人物、顔が含まれているという理由で、画像がスキップされる可能性があります。 画像を削除してください。 現時点では、これらのエンティティが含まれる画像を使用して、モデルを微調整することはできません。 |
| URL にアクセスできない | 画像 URL がパブリック アクセス可能かどうかを確認します。 |
| 画像が大きすぎる | 画像サイズがデータセットのサイズ制限内かどうかを確認します。 |
| 無効な画像形式 | 画像形式がデータセットの形式に適合しているかどうかを確認します。 |
大きなファイルのアップロード方法
トレーニング ファイルは非常に大きなサイズとなる可能性があります。 Uploads API を使用すると、複数の場所に最大 8 GB のファイルをアップロードすることができます。一方、Files API では最大 512 MB のファイルしかアップロードできません。
トレーニング コストの削減
画像の詳細パラメーターを [low] に設定すると、画像サイズは 512 x 512 ピクセルに変更され、サイズに関係なく 85 トークンのみで表示されます。 これにより、トレーニングのコストが削減されます。
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
vision の微調整に関するその他の考慮事項
画像認識の忠実さを制御するには、image_url の詳細パラメーターを各画像ごとに low、 high、または auto に設定します。 これは、トレーニング期間にモデルで表示される画像ごとのトークン数にも影響するほか、トレーニングのコストにも影響します。
次のステップ
- 微調整機能の詳細については、Azure OpenAI の微調整に関するチュートリアルを参照してください。
- 微調整モデルのリージョン別の利用可能性を確認する
- Azure OpenAI クォータについて詳しく知る