クイック スタート: 会話言語理解
この記事では、Language Studio と REST API を使用した会話言語理解の概要について説明します。 次の手順で例を試してみてください。
前提条件
- Azure サブスクリプション - 無料アカウントを作成します。
Language Studio にサインインする
Language Studio にアクセスし、Azure アカウントでサインインします。
表示される [Choose a language resource](言語リソースの選択) ウィンドウで、自分の Azure サブスクリプションを見つけ、言語リソースを選びます。 リソースがない場合は、新しいものを作成できます。
インスタンスの詳細 必須値 Azure サブスクリプション Azure サブスクリプション。 Azure リソース グループ Azure リソース グループ名。 Azure リソース名 Azure リソース名。 場所 言語リソースのサポートされているリージョンの 1 つ。 たとえば "米国西部 2" にします。 価格レベル 言語リソースの有効な価格レベルの 1 つ。 Free (F0) レベルを利用してサービスを試用できます。 

会話言語理解プロジェクトを作成する
言語リソースを選択したら、会話言語理解プロジェクトを作成します。 プロジェクトは、データに基づいてカスタム ML モデルを構築するための作業領域です。 ご自分のプロジェクトにアクセスできるのは、本人と、使用されている言語リソースへのアクセス権を持つ方のみです。
このクイックスタートでは、このサンプル プロジェクト ファイルをダウンロードしてインポートできます。 このプロジェクトは、ユーザー入力から目的のコマンド (メールの読み取り、メールの削除、メールへのドキュメントの添付など) を予測できます。
Language Studio で、[Understand questions and conversational language](質問と会話言語を理解する) セクションで、[会話言語理解] を選びます。
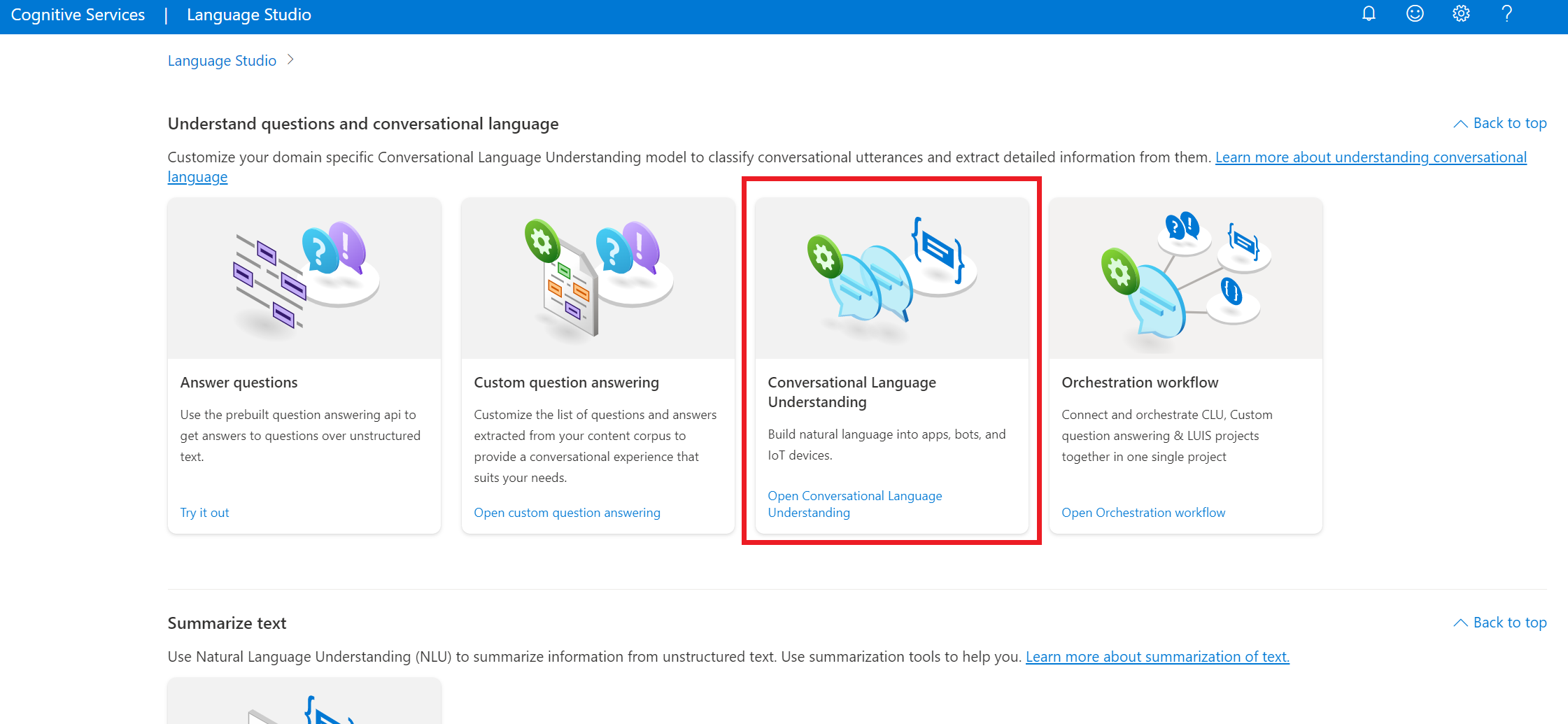
これにより、[会話言語理解プロジェクト] ページが表示されます。 [新しいプロジェクトの作成] ボタンの横で、[インポート] を選択します。
![Language Studio の [Conversations project]\(会話プロジェクト\) ページのスクリーンショット。](media/projects-page.png)
表示されたウィンドウで、インポートする JSON ファイルをアップロードします。 ファイルが サポートされている JSON 形式に従っていることを確認します。

![Language Studio の [Conversations project]\(会話プロジェクト\) ページのスクリーンショット。](media/projects-page.png#lightbox)
アップロードが完了すると、[Schema definition] (スキーマ定義) ページに移動します。 このクイックスタートでは、スキーマが既にビルドされており、発話には既に意図とエンティティのラベルが付けられています。
モデルをトレーニングする
通常は、プロジェクトを作成した後、スキーマをビルドし、発話にラベルを付ける必要があります。 このクイックスタートでは、準備が完了したプロジェクトが既にインポートされており、スキーマはビルドされ、発話にはラベルが付けられています。
モデルをトレーニングするには、トレーニング ジョブを開始する必要があります。 成功したトレーニング ジョブの出力は、トレーニング済みのモデルです。
Language Studio 内からモデルのトレーニングを開始するには:
左側のメニューから [モデルのトレーニング] を選択します。
上部のメニューから [Start a training job] (トレーニング ジョブの開始) を選択します。
[新しいモデルのトレーニング] を選択し、テキスト ボックスに新しいモデル名を入力します。 それ以外の場合、既存のモデルを新しいデータでトレーニングされたモデルに置き換えるには、[既存のモデルを上書きする](Overwrite an existing model) を選択し、既存のモデルを選択します。 トレーニング済みモデルを上書きすると、元に戻すことはできません。ただし、新しいモデルをデプロイするまで、デプロイされているモデルには影響しません。
トレーニング モードを選択します。 [標準トレーニング] を選択すると、高速でトレーニングできますが、これを使用できるのは英語に限られます。 または、[高度なトレーニング] を選択できます。これは、他の言語や多言語プロジェクトでもサポートされていますが、トレーニング時間が長くなります。 トレーニング モードの詳細を参照してください。
[データ分割] 方法を選択します。 [トレーニング用データからテスト用セットを自動分割] を選択できます。その場合、システムにより、指定した割合に従って、発話がトレーニング用セットとテスト用セットに分割されます。 または、[トレーニング用データとテスト用データの手動分割を使用] を選択することもできます。このオプションは、発話にラベルを付ける際に発話をテスト用セットに追加した場合にのみ有効になります。
[トレーニング] ボタンを選択します。
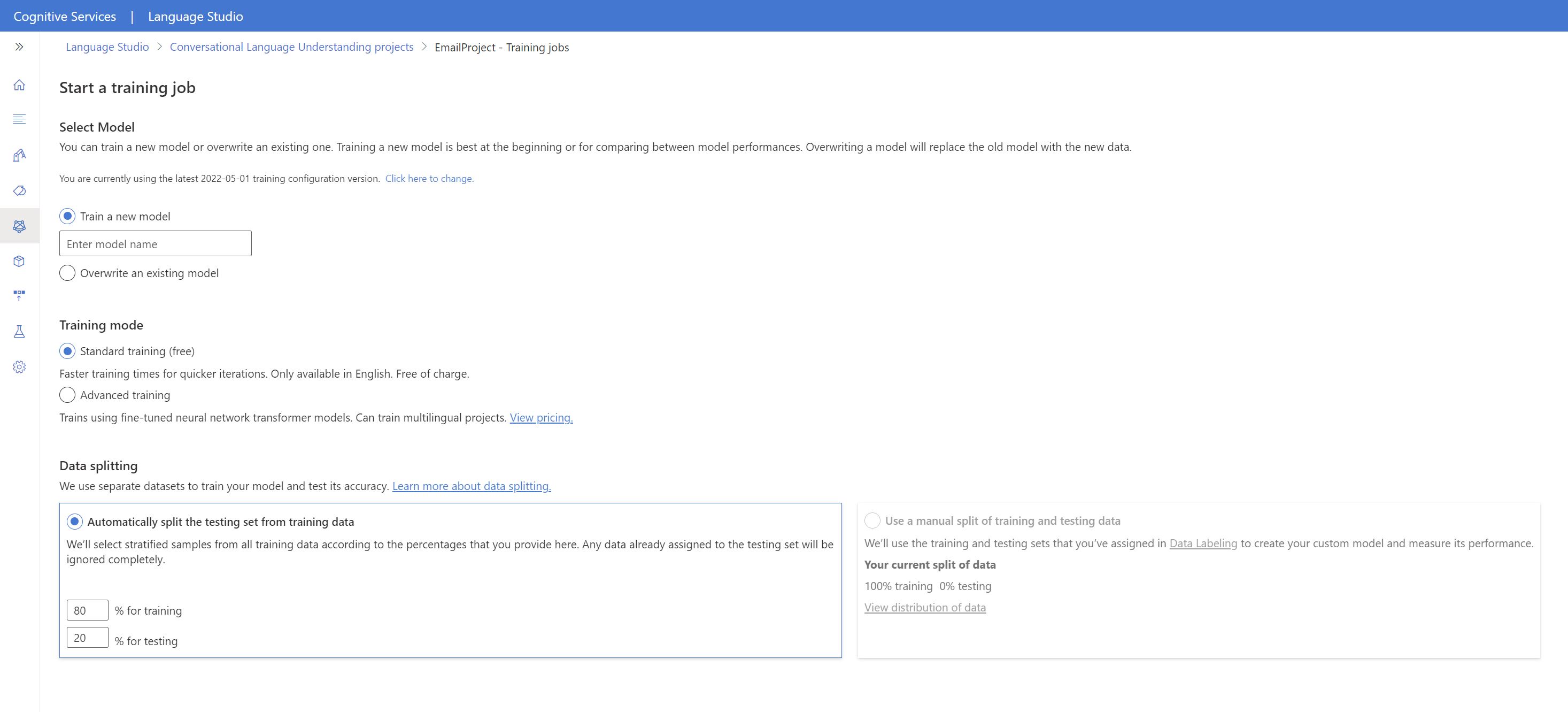
リストからトレーニング ジョブ ID を選択します。 ウィンドウが表示され、そのジョブのトレーニングの進行状況、ジョブの状態、その他の詳細を確認できます。
注意
- 正常に完了したトレーニング ジョブでのみ、モデルが生成されます。
- トレーニングは、発話数に応じて、数分から数時間かかる場合があります。
- 一度に実行できるトレーニング ジョブは 1 つだけです。 実行中のジョブが完了しない限り、同じプロジェクト内で他のトレーニング ジョブを開始することはできません。
- モデルのトレーニングに使用される機械学習は定期的に更新されます。 以前の構成バージョンでトレーニングするには、[トレーニング ジョブの開始] ページから [変更するには、ここを選択してください] を選択し、以前のバージョンを選択します。

モデルをデプロイする
通常はモデルをトレーニングした後、その評価の詳細を確認します。 このクイックスタートでは、モデルをデプロイして Language Studio で試せるようにするところまで行いますが、予測 API を呼び出すこともできます。
Language Studio 内からモデルのデプロイを開始するには、次の手順を行います。
左側のメニューから [Deploying a model](モデルのデプロイ) を選びます。
[デプロイの追加] を選択して、[デプロイの追加] ウィザードを開始します。

[新しいデプロイ名を作成する] を選択して新しいデプロイを作成し、下のドロップダウンからトレーニング済みのモデルを割り当てます。 それ以外の場合は、[Overwrite an existing deployment name] (既存のデプロイ名を上書きする) を選択して、既存のデプロイで使用されているモデルを効果的に置き換えることができます。
注意
既存のデプロイを上書きしても、Prediction API の呼び出しを変更する必要はありませんが、その結果は、新しく割り当てたモデルに基づくものになります。
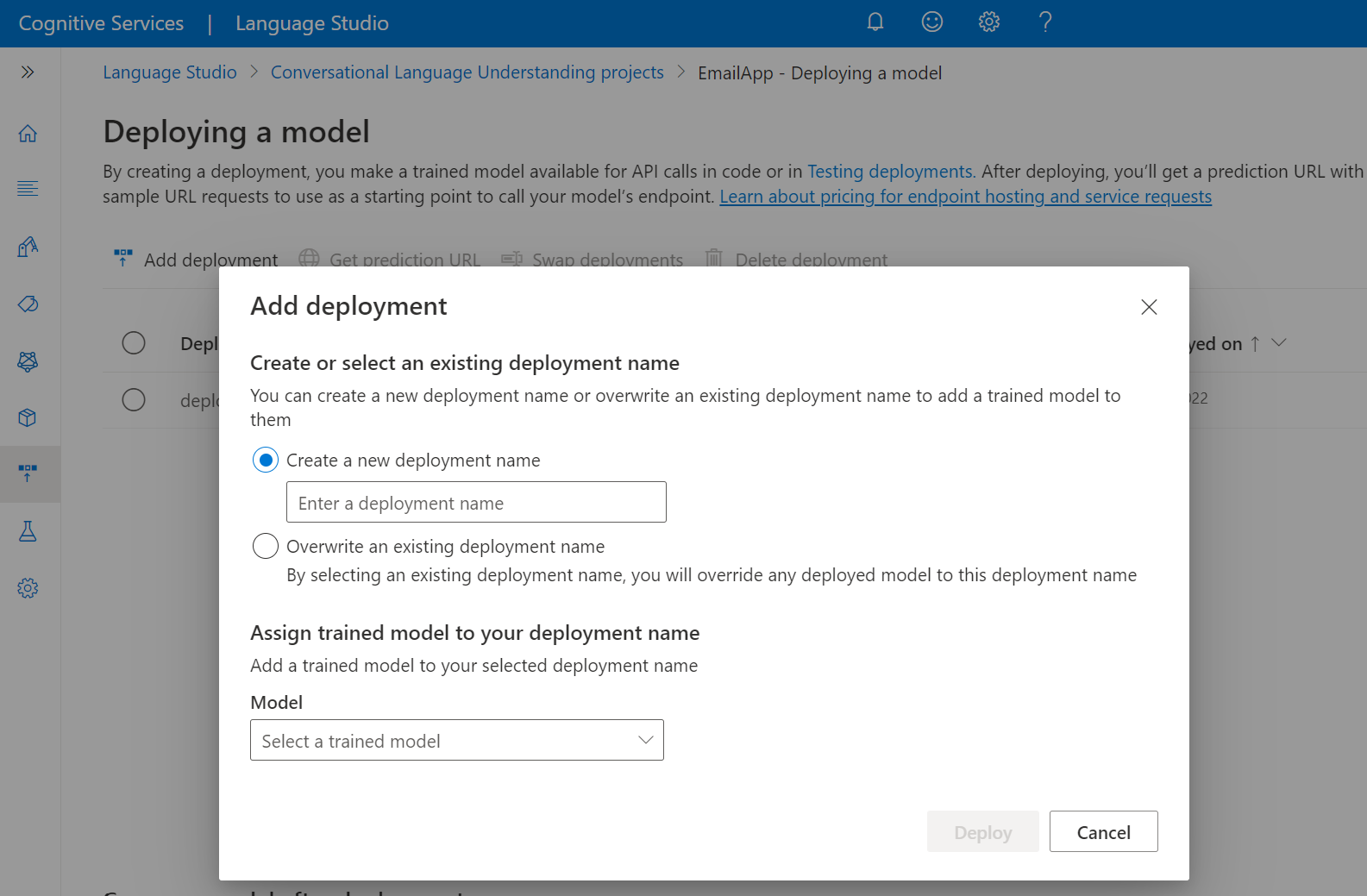
[モデル] ドロップダウンからトレーニング済みのモデルを選択します。
[デプロイ] を選択して、デプロイ ジョブを開始します。
デプロイが成功すると、その横に有効期限が表示されます。 デプロイの有効期限とは、デプロイされたモデルを予測に使用できなくなるときであり、通常は、トレーニング構成の有効期限が切れる 12 か月後に発生します。


デプロイされたモデルをテストする
Language Studio 内からデプロイされたモデルをテストするには、次の手順を行います。
左側のメニューから [デプロイのテスト] を選びます。
多言語プロジェクトの場合は、[テキスト言語の選択] ドロップダウンから、テストする発話の言語を選択します。
[デプロイ名] ドロップダウンから、テストするモデルに対応するデプロイ名を選択します。 テストできるのは、デプロイに割り当てられているモデルのみです。
テキスト ボックスに、テストする発話を入力します。 たとえば、メール関連の発話用のアプリケーションを作成した場合は、「このメールを削除する」と入力できます。
ページの上部で、[テストの実行] を選択します。
テストを実行すると、結果にモデルの応答が表示されます。 結果はエンティティ カード ビューで表示することも、JSON 形式で表示することもできます。
リソースをクリーンアップする
プロジェクトが不要な場合は、Language Studio を使ってプロジェクトを削除できます。 左側のナビゲーション メニューで [プロジェクト] を選択し、削除するプロジェクトを選択して、上部のメニューで [削除] を選択します。
前提条件
- Azure サブスクリプション - 無料アカウントを作成します。
Azure portal から新しいリソースを作成します
Azure portal にサインインし、新しい Azure AI Language リソースを作成します。
[新しいリソースを作成] を選択します
表示されるウィンドウで、言語サービスを検索します
[作成] を選択します。
次の詳細を使用して言語リソースを作成します。
インスタンスの詳細 必須値 リージョン 言語リソースのサポートされているリージョンの 1 つ。 Name Language リソースに必須の名前 価格レベル 言語リソースのサポートされている価格レベルの 1 つ。
リソースのキーとエンドポイントを取得する
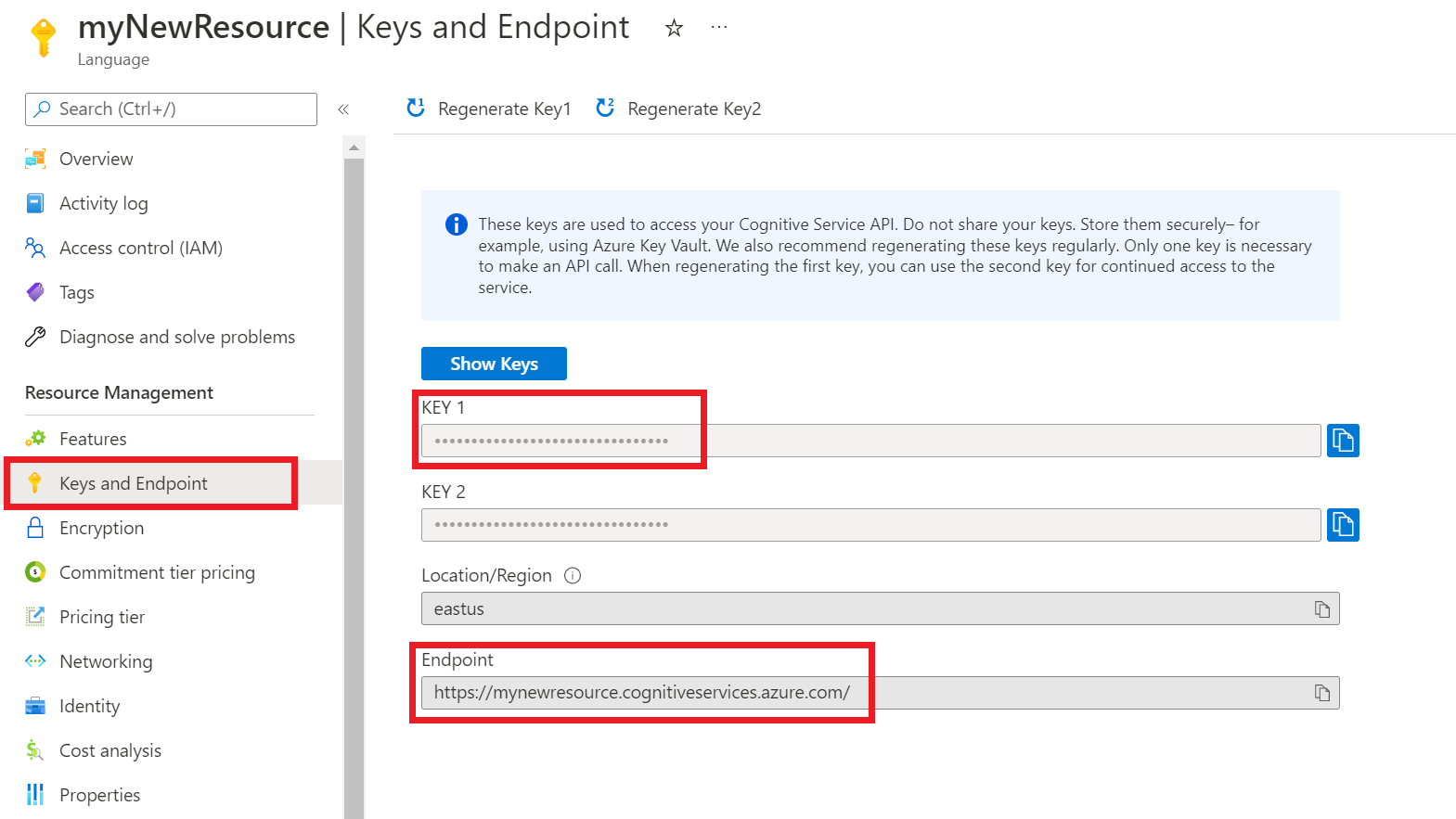
Azure portal でリソースの概要ページに移動します。
左側のメニューで [キーとエンドポイント] を選びます。 API 要求のエンドポイントとキーを使います

新しい CLU サンプル プロジェクトをインポートする
言語リソースを作成したら、会話言語理解プロジェクトを作成します。 プロジェクトは、データに基づいてカスタム ML モデルを構築するための作業領域です。 ご自分のプロジェクトにアクセスできるのは、本人と、使用されている言語リソースへのアクセス権を持つ方のみです。
このクイックスタートでは、このサンプル プロジェクトをダウンロードしてインポートできます。 このプロジェクトは、ユーザー入力から目的のコマンド (メールの読み取り、メールの削除、メールへのドキュメントの添付など) を予測できます。
プロジェクトのインポート ジョブをトリガーする
プロジェクトをインポートするには、次の URL、ヘッダー、JSON 本文を使って POST 要求を送信します。
要求 URL
API 要求を作るときは、次の URL を使います。 プレースホルダーの値は、実際の値に置き換えます。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は大文字と小文字が区別され、インポートする JSON ファイルのプロジェクト名と一致している必要があります。 | EmailAppDemo |
{API-VERSION} |
呼び出している API のバージョン。 | 2023-04-01 |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
本文
送信する JSON 本文は、次の例のようになります。 JSON オブジェクトの詳細については、リファレンス ドキュメントを参照してください。
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Conversation",
"settings": {
"confidenceThreshold": 0.7
},
"projectName": "{PROJECT-NAME}",
"multilingual": true,
"description": "Trying out CLU",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Conversation",
"intents": [
{
"category": "intent1"
},
{
"category": "intent2"
}
],
"entities": [
{
"category": "entity1"
}
],
"utterances": [
{
"text": "text1",
"dataset": "{DATASET}",
"intent": "intent1",
"entities": [
{
"category": "entity1",
"offset": 5,
"length": 5
}
]
},
{
"text": "text2",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"intent": "intent2",
"entities": []
}
]
}
}
| キー | プレースホルダー | 値 | 例 |
|---|---|---|---|
{API-VERSION} |
呼び出している API のバージョン。 | 2023-04-01 |
|
projectName |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | EmailAppDemo |
language |
{LANGUAGE-CODE} |
プロジェクトで使用される発話の言語コードを指定する文字列。 プロジェクトが多言語プロジェクトの場合は、ほとんどの発話の言語コードを選択します。 | en-us |
multilingual |
true |
データセット内に複数の言語のドキュメントを含めるブール値。 モデルがデプロイされると、サポートされている任意の言語 (トレーニング ドキュメントに含まれていない言語も含む) でモデルにクエリを実行できます。 | true |
dataset |
{DATASET} |
テスト セットとトレーニング セットの間でデータを分割する方法については、モデルをトレーニングする方法を参照してください。 このフィールドで使用できる値は Train および Test です。 |
Train |
要求が成功すると、API 応答には、インポート ジョブの状態を確認するために使用できる URL を含む operation-location ヘッダーが含まれます。 次のように書式設定されています。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
インポート ジョブの状態を取得する
プロジェクトのインポート要求の送信に成功すると、インポート ジョブの状態を確認するための完全な要求 URL (エンドポイント、プロジェクト名、ジョブ ID を含む) が応答の operation-location ヘッダーに組み込まれます。
次の GET 要求を使用して、インポート ジョブの状態を照会します。 前のステップで取得した URL を使うことも、プレースホルダーの値を実際の値に置き換えることもできます。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{JOB-ID} |
インポート ジョブの状態を検索するための ID。 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
呼び出す API のバージョン。 | 2023-04-01 |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 説明 | 値 |
|---|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 | {YOUR-PRIMARY-RESOURCE-KEY} |
応答本文
要求を送信すると、次の応答を受け取ります。 [status](状態) パラメーターが [succeeded](成功) に変更されるまで、このエンドポイントのポーリングを続けます。
{
"jobId": "xxxxx-xxxxx-xxxx-xxxxx",
"createdDateTime": "2022-04-18T15:17:20Z",
"lastUpdatedDateTime": "2022-04-18T15:17:22Z",
"expirationDateTime": "2022-04-25T15:17:20Z",
"status": "succeeded"
}
モデルのトレーニングを開始する
通常は、プロジェクトを作成した後、スキーマをビルドし、発話にタグを付ける必要があります。 このクイックスタートでは、準備が完了したプロジェクトが既にインポートされており、スキーマはビルドされ、発話にはタグが付けられています。
次の URL、ヘッダー、JSON 本文を使用して POST 要求を作成し、トレーニング ジョブを送信します。
要求 URL
API 要求を作るときは、次の URL を使います。 プレースホルダーの値は、実際の値に置き換えます。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | EmailApp |
{API-VERSION} |
呼び出す API のバージョン。 | 2023-04-01 |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
要求本文
要求では次のオブジェクトを使います。 トレーニングが完了すると、modelLabel パラメーターに使用する値の後にモデルの名前が付けられます。
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "{TRAINING-MODE}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| キー | プレースホルダー | 値 | 例 |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
モデルの名前。 | Model1 |
trainingConfigVersion |
{CONFIG-VERSION} |
トレーニング構成モデルのバージョン。 既定では、最新のモデル バージョンが使用されます。 | 2022-05-01 |
trainingMode |
{TRAINING-MODE} |
トレーニングに使用するトレーニング モード。 サポートされているモードは、高速のトレーニングですが、英語でのみ使用可能な [標準トレーニング]と、他の言語や多言語プロジェクトでもサポートされていますが、トレーニング時間が長くなる [高度なトレーニング] です。 トレーニング モードの詳細を参照してください。 | standard |
kind |
percentage |
分割方法。 設定可能な値は、percentage または manual です。 詳細については、モデルのトレーニング方法に関するセクションを参照してください。 |
percentage |
trainingSplitPercentage |
80 |
トレーニング セットに含まれるタグ付きデータの割合。 推奨値は 80 です。 |
80 |
testingSplitPercentage |
20 |
テスト用セットに含めるタグ付けされたデータの割合。 推奨値は 20 です。 |
20 |
注意
trainingSplitPercentage と testingSplitPercentage は、Kind が percentage に設定されている場合にのみ必要であり、両方の割合の合計は 100 に等しくなる必要があります。
API 要求を送信すると、成功を示す 202 応答が返されます。 応答ヘッダーで、operation-location の値を抽出します。 それは次のように書式設定されています。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
この URL を使用してトレーニング ジョブの状態を取得できます。
トレーニング ジョブの状態を取得する
トレーニングの完了には時間がかかる場合があります (10 分から 30 分)。 次の要求を使用して、トレーニング ジョブが正常に完了するまで、その状態をポーリングし続けることができます。
トレーニング要求の送信に成功すると、インポート ジョブの状態を確認するための完全な要求 URL (エンドポイント、プロジェクト名、ジョブ ID を含む) が応答の operation-location ヘッダーに組み込まれます。
モデルのトレーニングの進行状況を表す状態を取得するには、次の GET 要求を使用します。 次のプレースホルダーの値を実際の値に置き換えてください。
要求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{YOUR-ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | EmailApp |
{JOB-ID} |
モデルのトレーニングの状態を取得するための ID。 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
呼び出す API のバージョン。 | 2023-04-01 |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
応答本文
要求を送信すると、次の応答を受け取ります。 [status](状態) パラメーターが [succeeded](成功) に変更されるまで、このエンドポイントのポーリングを続けます。
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"trainingMode": "{TRAINING-MODE}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxx-xxxxx-xxxx-xxxxx-xxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| キー | 値 | 例 |
|---|---|---|
modelLabel |
モデル名 | Model1 |
trainingConfigVersion |
トレーニング構成バージョン。 既定では、最新バージョンが使用されます。 | 2022-05-01 |
trainingMode |
選択したトレーニング モード。 | standard |
startDateTime |
トレーニングが開始された時間 | 2022-04-14T10:23:04.2598544Z |
status |
トレーニング ジョブの状態 | running |
estimatedEndDateTime |
トレーニング ジョブが完了するまでの推定時間 | 2022-04-14T10:29:38.2598544Z |
jobId |
トレーニング ジョブ ID | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
トレーニング ジョブの作成日時 | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
トレーニング ジョブの最終更新日時 | 2022-04-14T10:23:45Z |
expirationDateTime |
トレーニング ジョブの有効期限の日時 | 2022-04-14T10:22:42Z |
モデルをデプロイする
通常はモデルをトレーニングした後、その評価の詳細を確認します。 このクイック スタートでは、モデルをデプロイし、予測 API を呼び出して結果を照会します。
デプロイ ジョブを送信する
会話言語理解モデルのデプロイを始めるには、次の URL、ヘッダー、JSON 本文を使って PUT 要求を作ります。
要求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{DEPLOYMENT-NAME} |
デプロイの名前。 この値は、大文字と小文字が区別されます。 | staging |
{API-VERSION} |
呼び出す API のバージョン。 | 2023-04-01 |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
要求本文
{
"trainedModelLabel": "{MODEL-NAME}",
}
| キー | プレースホルダー | 値 | 例 |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
デプロイに割り当てられるモデル名。 正常にトレーニングされたモデルのみ割り当てることができます。 この値は、大文字と小文字が区別されます。 | myModel |
API 要求を送信すると、成功を示す 202 応答が返されます。 応答ヘッダーで、operation-location の値を抽出します。 それは次のように書式設定されています。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
この URL を使用してデプロイ ジョブの状態を取得できます。
デプロイ ジョブの状態を取得する
プロジェクトのデプロイ要求の送信に成功すると、インポート ジョブの状態を確認するための完全な要求 URL (エンドポイント、プロジェクト名、ジョブ ID を含む) が応答の operation-location ヘッダーに組み込まれます。
次の GET 要求を使って、デプロイ ジョブの状態を取得します。 プレースホルダーの値は、実際の値に置き換えます。
要求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{DEPLOYMENT-NAME} |
デプロイの名前。 この値は、大文字と小文字が区別されます。 | staging |
{JOB-ID} |
モデルのトレーニングの状態を取得するための ID。 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
呼び出す API のバージョン。 | 2023-04-01 |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
応答本文
要求を送信すると、次の応答を受け取ります。 [status](状態) パラメーターが [succeeded](成功) に変更されるまで、このエンドポイントのポーリングを続けます。
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
モデルにクエリを実行する
モデルがデプロイされたら、モデルの使用を開始し、予測 API を使用して予測を行うことができます。
デプロイが成功すると、予測用にデプロイしたモデルに対してクエリを開始できます。
会話言語理解モデルのテストを開始するには、次の URL、ヘッダー、JSON 本文を使って POST 要求を作成します。
要求 URL
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
呼び出す API のバージョン。 | 2023-04-01 |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
要求本文
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"participantId": "1",
"text": "Text 1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"stringIndexType": "TextElement_V8"
}
}
| キー | プレースホルダー | 値 | 例 |
|---|---|---|---|
participantId |
{JOB-NAME} |
"MyJobName |
|
id |
{JOB-NAME} |
"MyJobName |
|
text |
{TEST-UTTERANCE} |
意図を予測してエンティティを抽出する発話。 | "Read Matt's email |
projectName |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
deploymentName |
{DEPLOYMENT-NAME} |
デプロイの名前。 この値は、大文字と小文字が区別されます。 | staging |
要求を送信すると、予測に関する次の応答を受け取ります
応答本文
{
"kind": "ConversationResult",
"result": {
"query": "Text1",
"prediction": {
"topIntent": "inten1",
"projectKind": "Conversation",
"intents": [
{
"category": "intent1",
"confidenceScore": 1
},
{
"category": "intent2",
"confidenceScore": 0
},
{
"category": "intent3",
"confidenceScore": 0
}
],
"entities": [
{
"category": "entity1",
"text": "text1",
"offset": 29,
"length": 12,
"confidenceScore": 1
}
]
}
}
}
| Key | 値の例 | 説明 |
|---|---|---|
| query | "Matt のメールを読む" | クエリ用に送信したテキスト。 |
| topIntent | "読む" | 信頼度スコアが最も高い予測された意図。 |
| 意図 | [] | クエリ テキストに対して予測されたすべての意図と信頼度スコアのリスト。 |
| entities | [] | クエリ テキストから抽出されたエンティティのリストを含む配列。 |
会話プロジェクトの API 応答
会話プロジェクトでは、プロジェクト内に存在する意図とエンティティの両方の予測が得られます。
- 意図とエンティティには、プロジェクト内の特定の要素のモデルの予測がどの程度信頼できるかの確実性に関する、0.0 から 1.0 の信頼スコアが含まれます。
- 上位スコアの意図は、独自のパラメーター内に含まれています。
- 予測されたエンティティのみが応答に表示されます。
- エンティティによって、次が示されます。
- 抽出されたエンティティのテキスト
- オフセット値で示される開始位置
- 長さの値で表されるエンティティ テキストの長さ
リソースをクリーンアップする
プロジェクトが不要になったら、API を使用してプロジェクトを削除できます。
会話言語理解プロジェクトを削除するには、次の URL、ヘッダー、JSON 本文を使って DELETE 要求を作成します。
要求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{API-VERSION} |
呼び出す API のバージョン。 | 2023-04-01 |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
API 要求を送信すると、成功を示す 202 応答を受け取ります。これは、プロジェクトが削除されたことを意味します。