Azure Data Factory での差分形式
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、差分形式を使用して、Azure Data Lake Store Gen2 または Azure Blob Storage に保存されている Delta Lake との間でデータをコピーする方法について説明します。 このコネクタは、ソースとシンクの両方としてデータ フローをマッピングするとき、インライン データセットとして利用できます。
Mapping Data Flow のプロパティ
このコネクタは、ソースとシンクの両方としてデータ フローをマッピングするとき、インライン データセットとして利用できます。
ソース プロパティ
次の表に、差分ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [ソース オプション] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| Format | 形式は delta である必要があります |
はい | delta |
format |
| ファイル システム | Delta Lake のコンテナーまたはファイル システム | はい | String | fileSystem |
| フォルダー パス | Delta Lake のディレクトリ | はい | String | folderPath |
| [圧縮の種類] | 差分テーブルの圧縮の種類 | no | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| 圧縮レベル | 圧縮を可能な限り短時間で完了させるか、圧縮後のファイルを最適に圧縮するかを選択します。 | compressedType を指定した場合は必須。 |
Optimal または Fastest |
compressionLevel |
| タイム トラベル | 差分テーブルの古いスナップショットにクエリを実行するかどうかを選択します | いいえ | タイムスタンプ別のクエリ: Timestamp バージョン別のクエリ:Integer |
timestampAsOf versionAsOf |
| [Allow no files found](ファイルの未検出を許可) | true の場合、ファイルが見つからない場合でもエラーはスローされない | no | true または false |
ignoreNoFilesFound |
Import schema
差分はインライン データセットとしてのみ利用できます。既定では、スキーマは関連付けられていません。 列メタデータを取得するには、[プロジェクション] タブの [Import schema](スキーマのインポート) ボタンをクリックします。これにより、コーパスによって指定されている列名とデータ型を参照できます。 スキーマをインポートするには、データ フロー デバッグ セッションをアクティブにする必要があり、既存の CDM エンティティ定義ファイルをポイントする必要があります。
差分ソース スクリプトの例
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
シンクのプロパティ
次の表に、差分シンクでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [設定] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| Format | 形式は delta である必要があります |
はい | delta |
format |
| ファイル システム | Delta Lake のコンテナーまたはファイル システム | はい | String | fileSystem |
| フォルダー パス | Delta Lake のディレクトリ | はい | String | folderPath |
| [圧縮の種類] | 差分テーブルの圧縮の種類 | no | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| 圧縮レベル | 圧縮を可能な限り短時間で完了させるか、圧縮後のファイルを最適に圧縮するかを選択します。 | compressedType を指定した場合は必須。 |
Optimal または Fastest |
compressionLevel |
| VACUUM | 指定された期間より古い、現在のテーブル バージョンに関連しなくなったファイルを削除します。 0 以下の値を指定すると、バキューム操作は実行されません。 | はい | Integer | vacuum |
| テーブル アクション | シンク内のターゲット Delta テーブルの操作を ADF に指示します。 そのままにして新しい行を追加したり、既存のテーブル定義とデータを新しいメタデータとデータで上書きしたり、既存のテーブル構造を維持しながら、最初にすべての行を切り詰めてから新しい行を挿入したりできます。 | no | None、Truncate、Overwrite | deltaTruncate、overwrite |
| 更新方法 | [Allow insert](挿入の許可) を単独で選択するか、新しいデルタ テーブルに書き込むときに、ターゲットは行ポリシー セットに関係なくすべての受信行を受け取ります。 データに他の行ポリシーの行が含まれている場合は、前述のフィルター変換を使用して除外する必要があります。 すべての更新メソッドを選択すると、マージが実行され、前述の行の変更変換を使用して設定された行ポリシーに従って行が挿入/削除/アップサート/更新されます。 |
はい | true または false |
insertable deletable upsertable updateable |
| 最適化された書き込み | Spark Executor の内部シャッフルを最適化することで、書き込み操作のスループットを向上させることができます。 結果として、サイズの大きいパーティションやファイルの数が減ります | no | true または false |
optimizedWrite: true |
| 自動圧縮 | 書き込み操作が完了すると、Spark によって自動的に OPTIMIZE コマンドが実行されてデータが再編成されます。これにより、必要に応じてより多くのパーティションが作成され、将来の読み取りパフォーマンスが向上します。 |
no | true または false |
autoCompact: true |
差分シンク スクリプトの例
関連付けられているデータ フロー スクリプトは次のとおりです。
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
パーティションの排除を使用した差分シンク
上記の Update メソッド (update/upsert/delete など) の下のこのオプションを使用すると、検査されるパーティションの数を制限できます。 この条件を満たすパーティションのみがターゲット ストアからフェッチされます。 パーティション列で使用できる固定値のセットを指定できます。
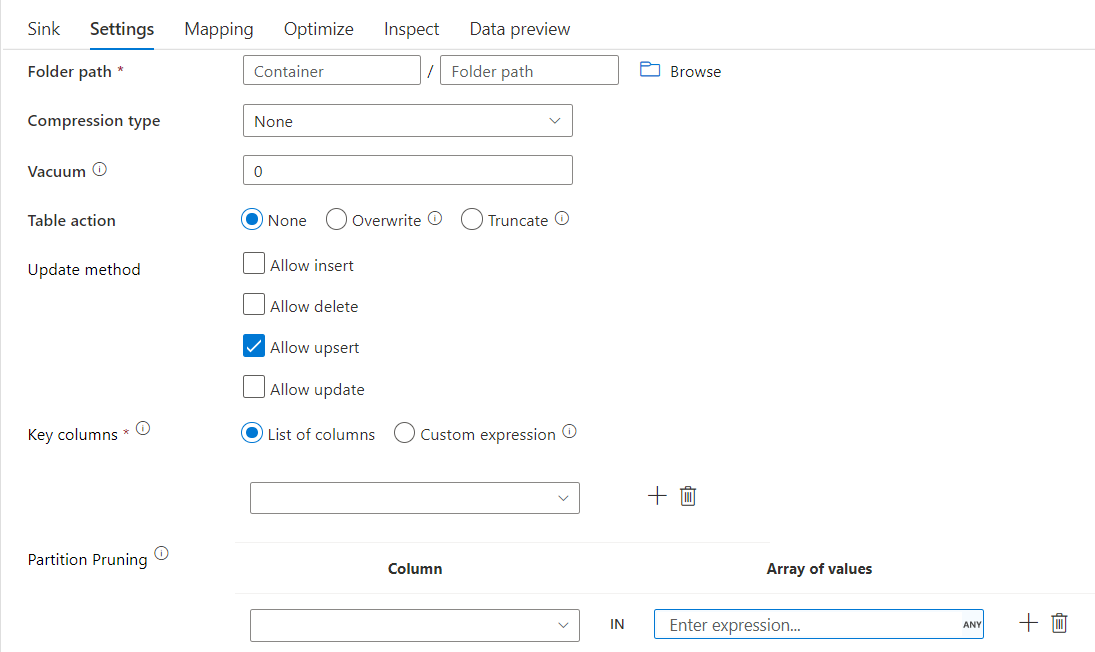
パーティションの削除を使用した差分シンク スクリプトの例
サンプル スクリプトを以下に示します。
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
差分では、すべてのパーティションではなく、ターゲット差分ストアから part_col == 5 と 8 の 2 つのパーティションのみが読み取られます。 part_col は、ターゲット差分データがパーティション分割される列です。 ソース データに存在する必要はありません。
差分シンク最適化オプション
[設定] タブには、差分シンク変換を最適化するための 3 つのオプションがあります。
[Merge schema](スキーマのマージ オプションを有効にすると、スキーマの展開が可能になります。すなわち、現在の受信ストリームには存在するが、ターゲットの Delta テーブルには存在しない列が、スキーマに自動的に追加されます。 このオプションは、すべての更新方法でサポートされます。
自動圧縮が有効になっている場合、コンパクト個別の書き込み後、ファイルをさらに圧縮できるかどうかを確認し、クイック OPTIMIZE ジョブ (1 GB ではなく 128 MB のファイル サイズで) を実行して、最大数の小さいファイルを保存するパーティション用にさらにファイルを圧縮します。 自動圧縮は、多数の小さなファイルをより少数の大きなファイルに結合するのに役立ちます。 自動圧縮は、少なくとも 50 個のファイルがある場合にのみ開始されます。 圧縮操作が実行されると、テーブルの新しいバージョンが作成され、圧縮された形式で複数の以前のファイルのデータを含む新しいファイルが書き込まれます。
書き込みの最適化が有効になっている場合、シンク変換では、テーブル パーティションごとに 128 MB のファイルを書き出そうとすることで、実際のデータに基づいてパーティション サイズが動的に最適化されます。 これは概算のサイズであり、データセットの特性に応じて異なる場合があります。 最適化された書き込みにより、 書き込みとその後の読み取り の全体的な効率が向上します。 パーティションが整理され、後続の読み取りのパフォーマンスが向上します。
ヒント
書き込みプロセスが最適化されると、ETL ジョブ全体の速度は低下します。これは、データが処理された後にシンクから Spark Delta Lake Optimize コマンドが発行されるからです。 最適化された書き込みは控えめに使うことをお勧めします。 たとえば、毎時のデータ パイプラインの場合、毎日の最適化された書き込みを使ってデータ フローを実行します。
既知の制限事項
差分シンクに書き込んだ場合、書き込まれた行数が監視出力に表示されないという既知の制限があります。