Azure Kubernetes Service (AKS) のデプロイとクラスターの信頼性に関するベスト プラクティス
この記事では、Azure Kubernetes Service (AKS) ワークロードのデプロイ レベルとクラスター レベルの両方で実装されるクラスターの信頼性に関するベスト プラクティスについて説明します。 この記事は、AKS でのアプリケーションのデプロイと管理を担当するクラスター オペレーターと開発者を対象としています。
この記事のベスト プラクティスは、次のカテゴリに分類されます。
デプロイ レベルのベスト プラクティス
次のデプロイ レベルのベスト プラクティスは、AKS ワークロードの高可用性と信頼性を確保するのに役立ちます。 これらのベスト プラクティスは、ポッドとデプロイの YAML ファイルに実装できるローカル構成です。
Note
アプリケーションに更新プログラムをデプロイするときは、これらのベスト プラクティスを必ず実装してください。 実装しない場合、アプリケーションの可用性と信頼性に関する問題 (意図しないアプリケーションのダウンタイムなど) が発生する可能性があります。
ポッド中断バジェット (PDB)
ベスト プラクティスのガイダンス
ポッド中断バジェット (PDB) を使用して、自発的な中断 (アップグレード操作や誤ったポッドの削除など) の間に最小限の数のポッドを確実に使用できるようにします。
ポッド中断バジェット (PDB) を使用すると、自発的な中断 (アップグレード操作や誤ったポッドの削除など) の間にデプロイまたはレプリカ セットがどのように応答するかを定義できます。 PDB を使用すると、使用できないリソースの最小数または最大数を定義できます。 PDB は、自発的な中断の削除 API にのみ影響を与えます。
たとえば、クラスターのアップグレードを実行する必要があり、PDB が既に定義されているとします。 クラスターのアップグレードを実行する前に、Kubernetes スケジューラは、PDB で定義されているポッドの最小数が使用可能であるようにします。 アップグレードによって使用可能なポッドの数が PDB で定義されている最小数を下回る場合、スケジューラはアップグレードの続行を許可する前に、他のノードで追加のポッドをスケジュールします。 PDB を設定しない場合、スケジューラに、アップグレード中に使用できないポッドの数に関する制約がないため、リソースが不足したりクラスターが停止したりする可能性があります。
次の PDB 定義ファイルの例では、minAvailable フィールドは、自発的な中断中に使用可能である必要があるポッドの最小数を設定します。 この値には、絶対値 (3 など) または必要なポッド数の割合 (10% など) を指定できます。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mypdb
spec:
minAvailable: 3 # Minimum number of pods that must remain available during voluntary disruptions
selector:
matchLabels:
app: myapp
詳細については、PDB を使用した可用性の計画に関するページと「アプリケーションの中断バジェットを指定する」をご覧ください。
ポッドの CPU とメモリの制限
ベスト プラクティスのガイダンス
すべてのポッドに対して、ポッドの CPU とメモリの制限を設定します。これにより、ポッドがノード上のすべてのリソースを消費しないようにし、DDoS 攻撃などのサービスの脅威時に保護を提供できます。
ポッドの CPU とメモリの制限は、ポッドが使用できる CPU とメモリの最大量を定義します。 ポッドが定義された制限を超えると、削除対象としてマークされます。 詳細については、「Kubernetes での CPU リソース ユニット」と「Kubernetes でのメモリ リソース ユニット」をご覧ください。
CPU とメモリの制限を設定すると、ノードの正常性を維持し、ノード上の他のポッドへの影響を最小限に抑えることができます。 ポッドの制限を、ノードでサポートできる制限より高く設定しないでください。 各 AKS ノードでは、主要な Kubernetes コンポーネント用に一定量の CPU とメモリが予約されます。 ノードでサポートできるよりも高いポッド制限を設定すると、アプリケーションが消費するリソースが多くなりすぎて、ノード上の他のポッドに悪影響を与える可能性があります。 クラスター管理者は、リソースの要求と制限を設定する必要がある名前空間に、リソース クォータを設定する必要があります。 詳細については、AKS でのリソース クォータの適用に関するページをご覧ください。
次のポッド定義ファイルの例では、resources セクションでポッドの CPU とメモリの制限を設定します。
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
ヒント
kubectl describe node コマンドを使用して、ノードの CPU とメモリの容量を表示できます。これを次の例に示します。
kubectl describe node <node-name>
# Example output
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863116Ki
pods: 110
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28362636Ki
pods: 110
詳細については、「コンテナーとポッドへの CPU リソースの割り当て」と「コンテナーとポッドへのメモリ リソースの割り当て」をご覧ください。
停止前フック
ベスト プラクティスのガイダンス
該当する場合は、停止前フックを使用して、コンテナーを正常に終了させます。
PreStop フックは、API 要求または管理イベント (プリエンプション、リソースの競合、liveness probe/startup probe の失敗など) が原因でコンテナーが終了する直前に呼び出されます。 コンテナーが既に終了状態または完了状態であり、コンテナーを停止するための TERM シグナルが送信される前にフックを完了する必要がある場合、PreStop フックの呼び出しは失敗します。 ポッドの終了の猶予期間のカウントダウンは、PreStop フックが実行される前に開始されるため、コンテナーは最終的に終了の猶予期間内に終了します。
次のポッド定義ファイルの例は、PreStop フックを使用してコンテナーを正常に終了させる方法を示しています。
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
詳細については、「コンテナー ライフサイクル フック」と「ポッドの終了」をご覧ください。
maxUnavailable
ベスト プラクティスのガイダンス
アップグレード中にポッドの最小数を確実に使用できるようにするために、デプロイの
maxUnavailableフィールドを使用して、ローリング アップデート中に使用できないポッドの最大数を定義します。
maxUnavailable フィールドは、更新プロセス中に使用できないポッドの最大数を指定します。 この値には、絶対値 (3 など) または必要なポッド数の割合 (10% など) を指定できます。 maxUnavailable は、ローリング更新時に使用される Delete API に関連します。
次の配置マニフェストの例では、maxAvailable フィールドを使用して、更新プロセス中に使用できないポッドの最大数を設定します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Maximum number of pods that can be unavailable during the upgrade
詳細については、「使用できない最大数」をご覧ください。
ポッド トポロジの分散制約
ベスト プラクティスのガイダンス
ポッド トポロジの分散制約を使用して、ポッドが異なるノードまたはゾーンに分散されるようにして、可用性と信頼性を向上させます。
ポッド トポロジの分散制約を使用すると、ノードのトポロジに基づいてポッドをクラスター全体に分散する方法を制御し、ポッドを異なるノードまたはゾーンに分散させて可用性と信頼性を向上させることができます。
次のポッド定義ファイルの例は、この topologySpreadConstraints フィールドを使用してポッドを異なるノードに分散させる方法を示しています。
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional
nodeAffinityPolicy: [Honor|Ignore] # optional
nodeTaintsPolicy: [Honor|Ignore] # optional
詳細については、「ポッド トポロジの分散制約 」を参照してください。
readiness probe、liveness probe、startup probe
ベスト プラクティスのガイダンス
該当する場合、readiness probe、liveness probe、startup probe を構成することで、高負荷時の回復性を向上させ、コンテナーの再起動を減らします。
Readiness probe
Kubernetes では、kubelet が readiness probe を使用して、コンテナーがトラフィックの受け入れを開始する準備ができていることを認識します。 ポッドは、すべてのコンテナーの準備ができたときに準備完了と見なされます。 ポッドが準備未完了の場合、ポッドはサービス ロード バランサーから削除されます。 詳細については、Kubernetes の readiness probe に関するページをご覧ください。
次のポッド定義ファイルの例は、readiness probe の構成を示しています。
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
詳細については、「readiness probe の構成」をご覧ください。
Liveness probe
Kubernetes では、kubelet が liveness probe を使用して、コンテナーを再起動するタイミングを把握します。 コンテナーの liveness probe が失敗した場合、コンテナーは再起動されます。 詳細については、Kubernetes の liveness probe に関するページをご覧ください。
次のポッド定義ファイルの例は、liveness probe の構成を示しています。
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
別の種類の liveness probe は、HTTP GET 要求を使用します。 次のポッド定義ファイルの例は、HTTP GET 要求の liveness probe の構成を示しています。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
詳細については、「liveness probe の構成」と「liveness HTTP 要求を定義する」をご覧ください。
Startup probe
Kubernetes では、kubelet が startup probe を使用して、コンテナー アプリケーションがいつ開始されたかを把握します。 startup probe を構成すると、readiness probe と liveness probe は startup probe が成功するまで開始されません。これにより、readiness probe と liveness probe がアプリケーションの起動に干渉することがありません。 詳細については、Kubernetes の startup probe に関するページをご覧ください。
次のポッド定義ファイルの例は、startup probe の構成を示しています。
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
マルチレプリカ アプリケーション
ベスト プラクティスのガイダンス
ノードがダウン状態になったシナリオで高可用性と回復性を確保するために、アプリケーションのレプリカを少なくとも 2 つデプロイします。
Kubernetes では、デプロイの replicas フィールドを使用して、実行するポッドの数を指定できます。 アプリケーションのインスタンスを複数実行すると、ノードがダウン状態になったシナリオでも高可用性と回復性を確保できます。 可用性ゾーンが有効な場合は、replicas フィールドを使用して、複数の可用性ゾーンで実行するポッドの数を指定できます。
次のポッド定義ファイルの例は、replicas フィールドを使用して、実行するポッドの数を指定する方法を示しています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
詳細については、「AKS に推奨されるアクティブ/アクティブ高可用性ソリューションの概要」とデプロイのレプリカの指定に関するページをご覧ください。
クラスターおよびノード プール レベルのベスト プラクティス
次のクラスターおよびノード プール レベルのベスト プラクティスは、AKS クラスターの高可用性と信頼性を確保するのに役立ちます。 これらのベスト プラクティスは、AKS クラスターを作成または更新するときに実装できます。
可用性ゾーン
ベスト プラクティスのガイダンス
ゾーンがダウン状態になったシナリオで高可用性を確保するために、AKS クラスターを作成するときに複数の可用性ゾーンを使用します。 クラスターを作成した後は可用性ゾーンの構成を変更できないことにご注意ください。
可用性ゾーンは、リージョン内のデータセンターの分離されたグループです。 これらのゾーンは、互いへの待機時間の短い接続を行えるほど十分に近接していますが、複数のゾーンがローカルな停止や気象の影響を受ける可能性を減らせるほど十分に離れています。 可用性ゾーンを使用すると、ゾーンがダウン状態になったシナリオでも、データの同期が維持され、データにアクセスできます。 詳細については、「複数のゾーンでの実行」をご覧ください。
クラスターの自動スケール
ベスト プラクティスのガイダンス
クラスターの自動スケーリングを使用して、クラスターが負荷の増加を確実に処理できるようにし、低負荷時のコストを削減します。
AKS でのアプリケーションの需要に対応するため、ワークロードを実行するノードの数の調整が必要になる場合があります。 クラスター オートスケーラー コンポーネントは、リソース制約のためにスケジュールできないクラスター内のポッドを監視します。 クラスター オートスケーラーは、問題を検出すると、アプリケーションの需要に合わせてノード プール内のノード数をスケールアップします。 また、実行ポッドの不足について定期的にノードがチェックされ、必要に応じてノードの数がスケールダウンされます。 詳細については、AKS でのクラスター自動スケーリングに関するページをご覧ください。
AKS クラスターを作成するときに --enable-cluster-autoscaler パラメーターを使用して、クラスター オートスケーラーを有効にすることができます。これを次の例に示します。
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--vm-set-type VirtualMachineScaleSets \
--load-balancer-sku standard \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--generate-ssh-keys
クラスター全体のオートスケーラー プロファイルで既定値を変更すると、既存のノード プールでクラスター オートスケーラーを有効にし、クラスター オートスケーラーの詳細をよりきめ細かに構成することもできます。
詳細については、「AKS でのクラスター オートスケーラーの使用」をご覧ください。
Standard Load Balancer
ベスト プラクティスのガイダンス
Standard Load Balancer を使用して、より高い信頼性とリソース、複数の可用性ゾーンのサポート、HTTP プローブ、複数のデータ センター間の機能を提供します。
Azure では、Standard Load Balancer SKU は、ハイ パフォーマンスと低待機時間が必要な場合にネットワーク層トラフィックを負荷分散できるように設計されています。 Standard Load Balancer は、リージョン内およびリージョン間でトラフィックをルーティングし、高い回復性を実現するために可用性ゾーンにルーティングします。 Standard SKU は、AKS クラスターの作成時に使用するように推奨される既定の SKU です。
重要
Basic Load Balancer は 2025 年 9 月 30 日に廃止されます。 詳細については、公式告知を参照してください。 新しいデプロイには Standard Load Balancer を使用し、既存のデプロイを Standard Load Balancer にアップグレードすることをお勧めします。 詳細については、「Basic Load Balancer からのアップグレード」をご覧ください。
次の例は、Standard Load Balancer を使用する LoadBalancer サービス マニフェストを示しています。
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4 # Service annotation for an IPv4 address
name: azure-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: azure-load-balancer
詳細については、AKS でパブリック Standard Load Balancer を使用することに関するページをご覧ください。
ヒント
また、イングレス コントローラー またはサービス メッシュを使用して、ネットワーク トラフィックを管理することもできます。それぞれのオプションは、さまざまな機能を提供します。
システム ノード プール
専用システム ノード プールの使用
ベスト プラクティスのガイダンス
システム ノード プールを使用して、他のユーザー アプリケーションが同じノードで実行されないようにします。これが起きると、リソースの不足やシステム ポッドへの影響が発生する可能性があります。
専用システム ノード プールを使用して、同じノード上で他のユーザー アプリケーションが実行されないようにします。これが起きると、競合状態のためにリソースが不足したり、クラスターが停止する可能性があります。 専用システム ノード プールを使用するには、システム ノード プールで CriticalAddonsOnly テイントを使用できます。 詳細については、AKS でのシステム ノード プールの使用に関するページをご覧ください。
システム ノード プールの自動スケーリング
ベスト プラクティスのガイダンス
システム ノード プールの自動スケーラーを構成して、ノード プールの最小スケール制限と最大スケール制限を設定します。
ノード プールの自動スケーラーを使用して、ノード プールの最小スケール制限と最大スケール制限を構成します。 システム ノード プールは、システム ポッドの需要に合わせて常にスケーリングできる必要があります。 システム ノード プールをスケーリングできない場合、クラスターはスケジュール、スケーリング、負荷分散を管理するためのリソースを使い切り、クラスターが応答しなくなる可能性があります。
詳細については、「ノード プールでクラスター オートスケーラーを使用する」をご覧ください。
システム ノード プールあたり少なくとも 3 つのノード
ベスト プラクティスのガイダンス
システム ノード プールに少なくとも 3 つのノードがあることを確認して、ノードの再起動またはシャットダウンの原因となるフリーズ/アップグレードのシナリオに対する回復性を確保します。
システム ノード プールは、kube-proxy、coredns、Azure CNI プラグインなどのシステム ポッドを実行するために使用されます。 システム ノード プールに少なくとも 3 つのノードがあることを確認して、ノードの再起動またはシャットダウンの原因となるフリーズ/アップグレードのシナリオに対する回復性を確保することをお勧めします。 詳細については、「AKS でシステム ノード プールを管理する」をご覧ください。
高速ネットワーク
ベスト プラクティスのガイダンス
高速ネットワークを使用して、待ち時間を少なくし、ジッターを減らし、VM の CPU 使用率を減少させます。
高速ネットワークによって、サポートされた VM の種類でシングル ルート I/O 仮想化 (SR-IOV) が可能になり、ネットワークのパフォーマンスが大幅に向上します。
次の図は、高速ネットワークを使用した場合と使用しない場合の、2 台の VM 間の通信を比較したものです。
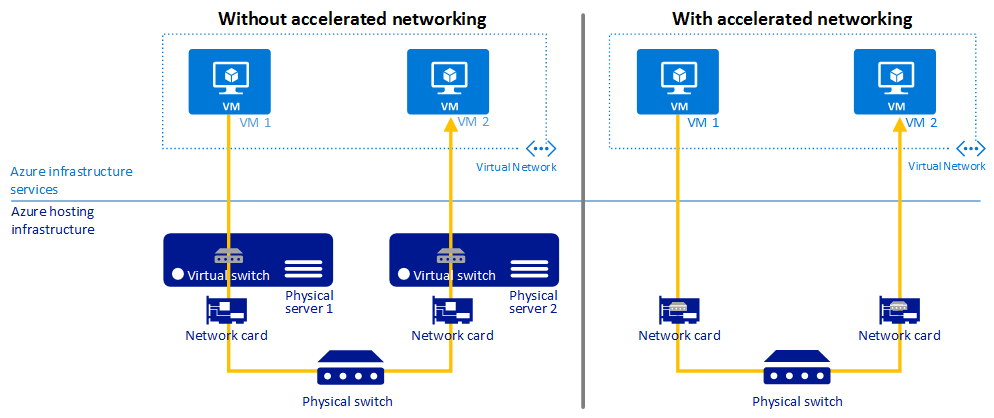
詳細については、「高速ネットワークの概要」をご覧ください。
イメージ バージョン
ベスト プラクティスのガイダンス
イメージでは、
latestタグを使用しないでください。
コンテナー イメージ タグ
コンテナー イメージに latest タグを使用すると、予期しない動作が発生し、クラスターで実行されているイメージのバージョンを追跡することが困難になる可能性があります。 スキャンおよび修復のツールを統合してコンテナー内のビルドおよびランタイムで実行すると、リスクを最小限に抑えられます。 詳細については、AKS でのコンテナー イメージの管理に関するベスト プラクティスに関するページをご覧ください。
ノード イメージのアップグレード
AKS では、ノード OS イメージのアップグレード用に複数の自動アップグレード チャネルを提供しています。 これらのチャネルを使用して、アップグレードのタイミングを制御できます。 これらの自動アップグレード チャネルに参加して、ノードで最新のセキュリティ パッチと更新プログラムが確実に実行されるようにすることをお勧めします。 詳細については、AKS でノードの OS イメージを自動アップグレードすることに関するページをご覧ください。
運用環境のワークロードに Standard レベルを使用する
ベスト プラクティスのガイダンス
製品ワークロードには Standard レベルを使用します。これにより、クラスターの信頼性とリソースが向上し、クラスター内で最大 5,000 ノードがサポートされ、アップタイム SLA が既定で有効になります。 LTS が必要な場合は、Premium レベルの使用をご検討ください。
Azure Kubernetes Service (AKS) の Standard レベルでは、運用環境のワークロードに対してアップタイムが 99.9% の財政的に裏付けされたサービス レベル アグリーメント (SLA) が提供されます。 また、Standard レベルでは、クラスターの信頼性とリソースが向上し、クラスター内で最大 5,000 ノードがサポートされ、アップタイム SLA が既定で有効になります。 詳細については、AKS クラスター管理のための価格レベルに関するページをご覧ください。
動的 IP 割り当てのための Azure CNI
ベスト プラクティスのガイダンス
動的 IP 割り当てのための Azure CNI を構成して、IP 使用率を向上させ、AKS クラスターの IP 枯渇を防ぎます。
Azure CNI の動的 IP 割り当て機能は、AKS クラスターをホストしているサブネットとは別のサブネットから ポッド IP を割り当てます。また、次のベネフィットを提供します。
- IP の使用効率の向上: IP は、ポッド サブネットからクラスター ポッドへと動的に割り当てられます。 これにより、すべてのノードで IP が静的に割り当てられる従来の CNI ソリューションと比べて、クラスター内での IP の使用効率が向上します。
- スケーラブルで柔軟: ノードとポッドのサブネットを個別にスケーリングできます。 1 つのポッド サブネットを、クラスターの複数のノード プール間で共有することも、同じ VNet にデプロイされた複数の AKS クラスター間で共有することもできます。 ノード プール用に個別のポッド サブネットを構成することもできます。
- ハイ パフォーマンス: ポッドには仮想ネットワークの IP が割り当てられるため、VNet 内の他のクラスター ポッドとリソースに直接接続できます。 このソリューションでは、パフォーマンスを低下させることなく、非常に大規模なクラスターをサポートできます。
- ポッドに対する個別の VNet ポリシー: ポッドには個別のサブネットがあるので、ノード ポリシーとは異なる VNet ポリシーを構成できます。 このため、ノードではなくポッドに対してのみインターネット接続を許可したり、Azure NAT Gateway を使用してノード プール内のポッドのソース IP を修正したり、NSG を使用してノード プール間のトラフィックをフィルター処理したりするなど、多くの便利なシナリオを実現できます。
- Kubernetes ネットワーク ポリシー: Azure ネットワーク ポリシーと Calico は、どちらもこのソリューションと連携して動作します。
詳細については、動的 IP 割り当てと拡張サブネットのサポートのために Azure CNI ネットワークを構成することに関するページをご覧ください。
v5 SKU VM
ベスト プラクティスのガイダンス
v5 VM SKU を使用して、更新中と更新後のパフォーマンスを向上させ、全体的な影響を軽減し、アプリケーションの接続の信頼性を高めます。
AKS のノード プールの場合は、エフェメラル OS ディスクを備えた v5 SKU VM を使用して、kube-system ポッドに十分なコンピューティング リソースを提供します。 詳細については、「AKS での大規模なワークロードのパフォーマンスとスケーリングに関するベスト プラクティス」を参照してください。
B シリーズ VM は使用しない
ベスト プラクティスのガイダンス
B シリーズの VM はパフォーマンスが低く、AKS ではうまく機能しないため、AKS クラスターには使用しないでください。
B シリーズの VM はパフォーマンスが低く、AKS ではうまく機能しません。 代わりに、v5 SKU VM を使用することをお勧めします。
Premium ディスク
ベスト プラクティスのガイダンス
Premium ディスクを使用して、1 つの仮想マシン (VM) で 99.9% の可用性を実現します。
Azure Premium ディスクは、ミリ秒未満の安定したディスク待機時間と、高い IOPS とスループットを実現します。 Premium ディスクは、VM の待機時間の短縮、高パフォーマンス、一貫したディスク パフォーマンスを提供するように設計されています。
次の YAML マニフェストの例は、Premium ディスクのストレージ クラス定義を示しています。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: premium2-disk-sc
parameters:
cachingMode: None
skuName: PremiumV2_LRS
DiskIOPSReadWrite: "4000"
DiskMBpsReadWrite: "1000"
provisioner: disk.csi.azure.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
詳細については、「AKS で Azure Premium SSD v2 ディスクを使用する」をご覧ください。
Container Insights
ベスト プラクティスのガイダンス
コンテナーの分析情報を有効にして、コンテナ化されたアプリケーションのパフォーマンスを監視および診断します。
コンテナーの分析情報は、AKS からコンテナー ログを収集して分析する Azure Monitor の機能です。 さまざまなビューと事前構築済みのブックを使用して、収集されたデータを分析できます。
さまざまな方法を使用して、AKS クラスターでコンテナーの分析情報の監視を有効にすることができます。 次の例は、Azure CLI を使用して既存のクラスターでコンテナーの分析情報の監視を有効にする方法を示しています。
az aks enable-addons -a monitoring --name myAKSCluster --resource-group myResourceGroup
詳細については、「Kubernetes クラスターの監視を有効にする」をご覧ください。
Azure Policy
ベスト プラクティスのガイダンス
Azure Policy を使用して、AKS クラスターのセキュリティとコンプライアンスの要件を強制的に適用します。
Azure Policy を使用して、AKS クラスターに組み込みのセキュリティ ポリシーを適用し実施することができます。 Azure Policy は、組織の標準を適用してコンプライアンスを大規模に評価するのに役立ちます。 AKS 用の Azure Policy アドオンをインストールしたら、個々のポリシー定義またはイニシアチブと呼ばれるポリシー定義のグループをクラスターに適用できます。
詳細については、「Azure Policy を使用して AKS クラスターをセキュリティで保護する」をご覧ください。
次のステップ
この記事では、Azure Kubernetes Service (AKS) のデプロイとクラスターの信頼性のベスト プラクティスに注目しました。 その他のベスト プラクティスについては、以下の記事をご覧ください。

Azure Kubernetes Service