Azure Kubernetes Service (AKS) でのクラスターの自動スケーリングの概要
Azure Kubernetes Service (AKS) でのアプリケーションの需要に対応するため、ワークロードを実行するノードの数の調整が必要になる場合があります。 クラスター オートスケーラー コンポーネントは、リソース制約のためにスケジュールできないクラスター内のポッドを監視します。 クラスター自動スケーラーは、予定外のポッドを検出すると、アプリケーションの需要に合わせてノード プール内のノード数をスケールアップします。 また、スケジュールされたポッドがないノードを定期的にチェックし、必要に応じてノード数をスケールダウンします。
この記事では、AKS でのクラスターのオートスケーラーのしくみについて説明します。 AKS ワークロードに対してクラスター オートスケーラーを構成する際のガイダンス、ベスト プラクティス、考慮事項も提供します。 AKS ワークロードのクラスター オートスケーラーを有効化、無効化、または更新する場合は、「AKSでクラスター オートスケーラーを使用する」を参照してください。
クラスター オートスケーラーについて
平日と夜間、または週末など、アプリケーションの変則的な需要に対応するために、多くの場合、クラスターには自動的にスケーリングする方法が必要になります。 AKS クラスターは、次の方法でスケーリングできます。
- クラスター オートスケーラーは、リソース制約のためにノードでスケジュールできないポッドを定期的に監視します。 その後、クラスターによってノードの数が自動的に増やされます。 クラスター オートスケーラーを使用する場合、手動スケーリングは無効になります。 詳細については、「スケールアップの仕組み」を参照してください。
- ポッドの水平オートスケーラーは、Kubernetes クラスターのメトリック サーバーを使用して、ポッドのリソースの需要をモニターします。 アプリケーションで必要なリソースが増えると、その需要を満たすためにポッドの数が自動的に増やされます。
- ポッドの垂直オートスケーラー では、過去の使用量に基づいてワークロードごとのコンテナーに対するリソース要求と制限が自動的に設定され、必要な CPU およびメモリ リソースを持つノードにポッドがスケジュールされるようにします。
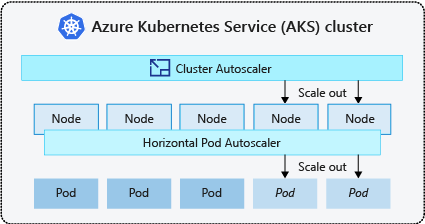
ノードに対してクラスター オートスケーラーを有効にし、ポッドに対してポッドの垂直オートスケーラーまたはポッドの水平オートスケーラーを有効にするのが一般的です。 クラスター自動スケーラーを有効にすると、ノード プールのサイズが最小ノード数より少ない場合、ノード数の上限まで、指定したスケーリング ルールが適用されます。 クラスター オートスケーラーは、ノード プールで新しいノードが必要になるまで、または現在のノード プールからノードを安全に削除できるようになるまで、作動を待機します。 詳細については、「スケールダウンの仕組み」をご覧ください。
ベスト プラクティスと考慮事項
- クラスター オートスケーラーで可用性ゾーンを実装する場合は、ゾーンごとに 1 つのノード プールを使用することをお勧めします。
--balance-similar-node-groupsパラメーターをTrueに設定すると、スケールアップ操作中にワークロードのゾーン間でノードをバランス良く分散させることができます。 この方法が実装されていない場合、スケールダウン操作によって、ゾーン間のノードのバランスが損なわれる可能性があります。 - ノード数が 400 を超えるクラスターの場合は、Azure CNI または Azure CNI オーバーレイを使用することをお勧めします。
- スポット ノード プールと固定ノード プールの両方でワークロードを効果的に同時に実行するには、priority expanderの使用を検討してください。 この方法では、ノード プールの優先順位に基づいてポッドをスケジュールできます。
- ポッドで CPU/メモリ要求を割り当てる場合は注意が必要です。 クラスター オートスケーラーは、ノードの CPU/メモリ負荷ではなく、保留中のポッドに基づいてスケールアップします。
- 実行時間の長いワークロード (Web アプリなど) と短時間で集中的に動作するジョブ ワークロードを両方同時にホストしているクラスターは、アフィニティ ルール/エキスパンダーを使用して別々のノード プールに分離するか、PodDisruptionBudget を使用して、必要以上のノード ドレインやスケールダウン操作を防ぐことをおすすめします。 また、注釈 cluster-autoscaler.kubernetes.io/safe-to-evict: "false" をポッド スペックに指定すると、ポッドが追い出されることを回避できます。 ただし、この注釈は慎重に使用してください。この注釈を含んだ実行中のポッドでノード ドレインを行うと、クラスター オートスケーラーに問題が発生することがあります。
- 自動スケーラー対応ノード プールでは、ノード数を手動で減らすのではなく、ワークロードを削除してノードをスケールダウンします。 これは、ノード プールが既に最大容量に達している場合、またはノード上でアクティブなワークロードが実行中であり、クラスター自動スケーラーによる予期しない動作が起こりうる場合に、問題になることがあります。
- ポッドの PriorityClass 値が -10 未満の場合、ノードはスケールアップしません。 優先度 -10 は、ポッドのオーバープロビジョニングのために予約済みです。 詳細については、「 ポッド優先度とプリエンプションでクラスター オートスケーラーを使用する」を参照してください。
- 仮想マシン スケール セット オートスケーラーなど、他のノード自動スケーリング メカニズムをクラスター オートスケーラーと組み合わせないでください。
- 次のような状況で、ポッドが移動できない場合、クラスター オートスケーラーはスケールダウンできないことがあります。
- 直接作成されたポッドが、デプロイや ReplicaSet トなどのコントローラー オブジェクトによってサポートされていない。
- ポッド中断バジェット (PDB) の制限が非常に厳しく、ポッドの数が特定のしきい値を下回ることが許可されていない。
- ポッドが、別のノードでスケジュールされた場合に適用できないノード セレクターまたはアンチ アフィニティーを使用している。 詳細については、「クラスター オートスケーラーによるノード削除の妨げとなる可能性があるポッドの種類」を参照してください。
重要
自動スケーリングされたノード プール内の個々のノードに変更を加えないでください。 同じノード グループ内のすべてのノードには、同じ容量、ラベル、テイント、およびそれらに対して実行されているシステム ポッドが含まれている必要があります。
- ポッドのスケジュールに関する考慮事項に関係なく、クラスター自動スケーラーはクラスター ノード プールに "最大ノード数" を適用する処理を行いません。 クラスター以外の自動スケーラー アクターを使って、クラスター自動スケーラーの構成済み最大値を超えるノード プール数を設定した場合、クラスター自動スケーラーによってノードは自動削除されません。 クラスター自動スケーラーのスケールダウン動作は、スケジュールされたポッドがないノードのみを削除するようにスコープが設定されたままです。 クラスター自動スケーラーの最大ノード数構成の目的は、スケールアップ操作の上限を適用することのみです。 スケールダウンの考慮事項には影響しません。
クラスター オートスケーラーのプロファイル
クラスター オートスケーラー プロファイル は、クラスター オートスケーラーの動作を制御するパラメーターのセットです。 クラスターを作成するときまたは既存のクラスターを更新するときに、クラスター オートスケーラー プロファイルを構成することもできます。
クラスター オートスケーラー プロファイルの最適化
パフォーマンスとコストのトレードオフも考慮しながら、特定のワークロード シナリオに応じてクラスター オートスケーラー プロファイルの設定を微調整する必要があります。 このセクションでは、これらのトレードオフを示す例を提供します。
クラスター オートスケーラー プロファイルの設定はクラスター全体にわたり、自動スケールが有効なすべてのノード プールに適用されることに注意してください。 あるノード プールで行われるスケーリング アクションは、他のノード プールの自動スケール動作に影響を与える可能性があり、予期しない結果につながる可能性があります。 必要な結果が得られるように、すべての関連ノード プールに一貫性のある同期プロファイル構成を適用してください。
例 1: パフォーマンスの最適化
パフォーマンスに重点を置いた、かなりの集中的なワークロードを処理するクラスターでは、scan-interval を増やし、scale-down-utilization-threshold を減らすことをお勧めします。 これらの設定は、複数のスケーリング操作を 1 回の呼び出しにバッチ処理し、スケーリング時間とコンピューティングの読み取り/書き込みクォータの使用率を最適化するのに役立ちます。 また、使用率の低いノードに対して迅速なスケールダウン操作を行うリスクを軽減し、ポッドのスケジュール設定の効率を高めます。 また、ok-total-unready-count と max-total-unready-percentage を増やします。
デーモンセット ポッドを使用するクラスターの場合は、ignore-daemonsets-utilization を trueに設定することをお勧めします。これは、デーモンセット ポッドによるノード使用率を効果的に無視し、不要なスケールダウン操作を最小限に抑えます。 集中的なワークロード用のプロファイルを見る
例 2: コストの最適化
コスト最適化プロファイルの使用を希望する場合は、次のパラメーター構成を設定することをお勧めします。
- ノードがスケールダウンの対象になるまで不要となる時間である
scale-down-unneeded-timeを減らします。 - ノードを追加してからスケールダウンを検討するまでの待機時間である
scale-down-delay-after-addを減らします。 - ノードを削除するための使用率のしきい値である
scale-down-utilization-thresholdを増やします。 - 1 回の呼び出しで削除できるノードの最大数である
max-empty-bulk-deleteを増やします。 skip-nodes-with-local-storageを false に設定します。ok-total-unready-countとmax-total-unready-percentageを増やします。
一般的な問題と軽減策のレコメンデーション
CLI または Portalでトリガーされないイベントのスケーリング エラーとスケールアップを表示します。
スケールアップ操作をトリガーしない
| 一般的な原因 | 軽減策のレコメンデーション |
|---|---|
| PersistentVolume ノード アフィニティの競合。これは、複数の可用性ゾーンでクラスター オートスケーラーを使用するとき、またはポッドか永続ボリュームのゾーンがノードのゾーンと異なる場合に発生する可能性があります。 | 可用性ゾーンごと 1 つのノード プールを使用して、--balance-similar-node-groups を有効にします。 また、volumeBindingMode フィールドをポッド仕様で WaitForFirstConsumer に設定して、ボリュームを使用するポッドが作成されるまで、ボリュームがノードにバインドされないようにすることもできます。 |
| テイントと容認/ノード アフィニティの競合 | ノードに割り当てられているテイントを評価し、ポッドで定義されている容認を確認します。 必要に応じて、ノードでポッドを効率的にスケジュールできるように、テイントと容認を調整します。 |
スケールアップ操作の失敗
| 一般的な原因 | 軽減策のレコメンデーション |
|---|---|
| サブネットの IP アドレスのポート不足 | 同じ仮想ネットワークに別のサブネットを追加し、新しいサブネットに別のノード プールを追加します。 |
| コア クォータの枯渇 | 承認済みのコア クォータが枯渇しました。 クォータの増加を要求します。 クラスター オートスケーラーは、複数のスケールアップ試行が失敗した場合に、特定のノード グループ内で エクスポネンシャル バックオフ状態 になります。 |
| ノード プールの最大サイズ | ノード プールの最大ノード数を増やすか、新しいノード プールを作成します。 |
| 要求/呼び出しがレート制限を超えている | 429: 要求が多すぎるエラー を参照してください。 |
スケールダウン操作の失敗
| 一般的な原因 | 軽減策のレコメンデーション |
|---|---|
| ポッドがノードのドレインを妨げている/ポッドを削除できない | •スケールダウンを妨げるポッドの種類 を表示します。 • hostPath や emptyDir などのローカル ストレージを使用するポッドの場合は、クラスター オートスケーラー プロファイル フラグ skip-nodes-with-local-storage を falseに設定します。 • ポッドの仕様で、 cluster-autoscaler.kubernetes.io/safe-to-evict 注釈を true に設定します。 • 制限が厳しい可能性があるため、PDBを確認します。 |
| ノード プールの最小サイズ | ノード プールの最小サイズを小さくします。 |
| 要求/呼び出しがレート制限を超えている | 429: 要求が多すぎるエラー を参照してください。 |
| 書き込み操作がロックされている | フル マネージド AKS リソース グループ に変更を加えないでください (AKS サポート ポリシー を参照します)。 以前にリソース グループに適用した リソース ロック を削除またはリセットします。 |
その他の問題
| 一般的な原因 | 軽減策のレコメンデーション |
|---|---|
| PriorityConfigMapNotMatchedGroup | 自動スケールを必要とするすべてのノード グループを、エキスパンダー構成ファイルに追加してください。 |
バックオフのノード プール
バックオフのノード プールはバージョン 0.6.2 で導入され、障害が発生した後、クラスター オートスケーラーはノード プールのスケーリングからバックオフします。
スケーリング操作でエラーが発生している時間によっては、もう一度試行するまでに最大 30 分かかる場合があります。 ノード プールのバックオフ状態をリセットするには、自動スケールを無効にしてから再度有効にします。

Azure Kubernetes Service