Azure Toolkit for IntelliJ を使用して HDInsight 上で VPN を介して Apache Spark アプリケーションをリモートでデバッグする
SSH を使用して Apache Spark アプリケーションをリモートでデバッグすることをお勧めします。 その手順については、SSH 経由で Azure Toolkit for IntelliJ を使用して、HDInsight クラスター上の Apache Spark アプリケーションをリモートでデバッグする方法に関するページをご覧ください。
この記事では、Azure Toolkit for IntelliJ の HDInsight ツールを使用して HDInsight Spark クラスター上で Spark ジョブを送信し、デスクトップ コンピューターからリモートでデバッグするための詳細な手順を紹介します。 これらの作業を行うために必要な手順の概要は以下のとおりです。
- サイト間またはポイント対サイトの Azure 仮想ネットワークを作成します。 このドキュメントの手順では、サイト間ネットワークを使用することを想定しています。
- サイト間仮想ネットワークの一部である HDInsight で Spark クラスターを作成します。
- クラスターのヘッド ノードとデスクトップの間の接続を確認します。
- IntelliJ IDEA で Scala アプリケーションを作成し、リモート デバッグ用に構成します。
- アプリケーションを実行し、デバッグします。
前提条件
- Azure サブスクリプション。 詳しくは、Azure 無料試用版の取得に関するページを参照してください。
- HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。
- Oracle Java Development Kit。 Oracle Web サイトからインストールできます。
- IntelliJ IDEA。 この記事では、バージョン 2017.1 を使用します。 JetBrains Web サイトからインストールできます。
- Azure Toolkit for IntelliJ のHDInsight ツール。 IntelliJ 用の HDInsight ツールは、Azure Toolkit for IntelliJ に付属しています。 Azure Toolkit をインストールする手順については、Azure Toolkit for IntelliJ のインストールに関するページをご覧ください。
- IntelliJ IDEA から Azure サブスクリプションにサインインします。 「Azure Toolkit for IntelliJ を使用して HDInsight クラスター向けの Apache Spark アプリケーションを作成する」の手順に従います。
- 例外の回避策。 リモート デバッグを行うために Windows コンピューター上で Spark Scala アプリケーションを実行しているときに、例外が発生する場合があります。 この例外は SPARK-2356 に説明があり、Windows に WinUtils.exe ファイルがないことが原因で発生します。 このエラーを回避するには、Winutils.exe を C:\WinUtils\bin などの場所にダウンロードする必要があります。 HADOOP_HOME 環境変数を追加し、この変数の値を C\WinUtils に設定します。
手順 1:Azure の仮想ネットワークを作成する
次のリンクの手順に従って Azure 仮想ネットワークを作成し、デスクトップ コンピューターと仮想ネットワークの間の接続を確認します。
- Azure Portal を使用してサイト間 VPN 接続を持つ VNet を作成する
- PowerShell を使用してサイト間 VPN 接続を持つ VNet を作成する
- PowerShell を使用して仮想ネットワークへのポイント対サイト接続を構成する
手順 2:HDInsight Spark クラスターを作成する
先ほど作成した Azure 仮想ネットワークに属する Apache Spark クラスターも Azure HDInsight で作成することをお勧めします。 詳しくは、HDInsight での Linux ベースの Hadoop クラスターの作成に関するページを参照してください。 オプションの構成の一環として、前の手順で作成した Azure 仮想ネットワークを選択します。
手順 3:クラスターのヘッド ノードとデスクトップの間の接続を確認する
ヘッド ノードの IP アドレスを取得します。 クラスターの Ambari UI を開きます。 クラスター ブレードから、 [ダッシュボード] を選択します。
Ambari UI から、 [Hosts]\(ホスト\) を選択します。

ヘッド ノード、ワーカー ノード、Zookeeper ノードの一覧が表示されます。 ヘッド ノードには hn* プレフィックスが付いています。 最初のヘッド ノードを選択します。
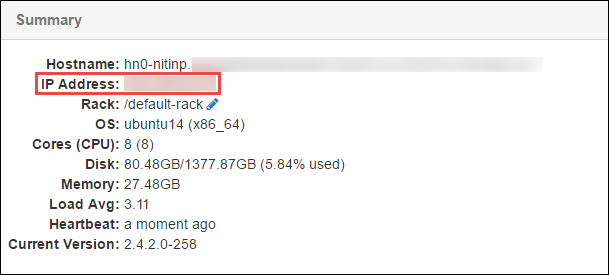
開いたページの下部にある [Summary]\(概要\) ウィンドウから、ヘッド ノードの IP アドレスとホスト名をコピーします。
ヘッド ノードの IP アドレスとホスト名を、Spark ジョブの実行とリモート デバッグに使用するコンピューターの hosts ファイルに追加します。 これで、ホスト名と IP アドレスのどちらを使用してもヘッド ノードと通信できるようになります。
a. 管理者特権のアクセス許可を使用してメモ帳のファイルを開きます。 [ファイル] メニューから [開く] を選択し、hosts ファイルの場所を見つけます。 Windows コンピューター上での場所は C:\Windows\System32\Drivers\etc\hosts です。
b. 以下の情報を hosts ファイルに追加します。
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netHDInsight クラスターで使用されている Azure 仮想ネットワークに接続したコンピューターから、ヘッド ノードに対して IP アドレスとホスト名を使用して ping を実行できることを確認します。
SSH を使用した HDInsight クラスターへの接続に関するセクションの手順に従い、SSH を使用してクラスターのヘッド ノードに接続します。 クラスターのヘッド ノードから、デスクトップ コンピューターの IP アドレスに ping を実行します。 コンピューターに割り当てられた以下の両 IP アドレスへの接続をテストします。
- ネットワーク接続用の IP アドレス
- Azure 仮想ネットワーク用の IP アドレス
他のヘッド ノードに対して同じ手順を繰り返します。
手順 4:Azure Toolkit for IntelliJ 内の HDInsight ツールを使用して Apache Spark Scala アプリケーションを作成し、リモート デバッグ用に構成する
IntelliJ IDEA を開き、新しいプロジェクトを作成します。 [新しいプロジェクト] ダイアログ ボックスで、次の操作を行います。
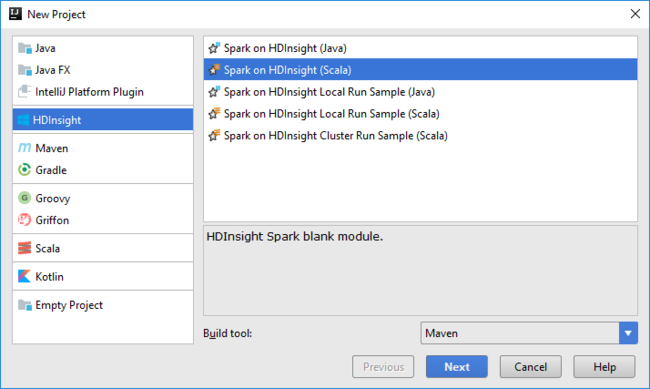
a. [HDInsight]>[Spark on HDInsight (Scala)]\(HDInsight の Spark (Scala)\) を選択します。
b. [次へ] を選択します。
次の [新しいプロジェクト] ダイアログ ボックスで以下の手順を実行し、 [Finish]\(完了\) を選択します。
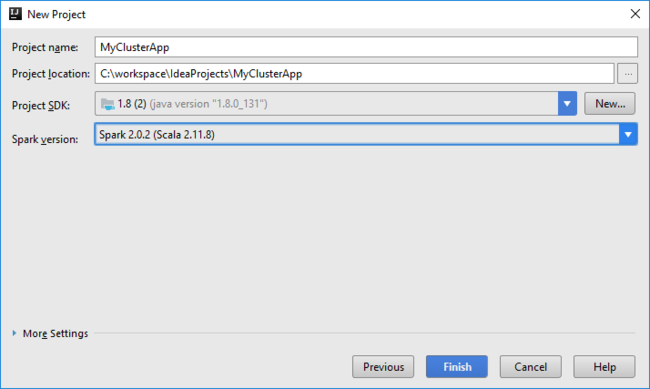
プロジェクトの名前と場所を入力します。
[Project SDK]\(プロジェクト SDK\) ドロップダウン リストで、Spark 2.x クラスターの場合は [Java 1.8] を選択し、Spark 1.x クラスターの場合は [Java 1.7] を選択します。
[Spark version]\(Spark バージョン\) ボックスの一覧には、Spark SDK と Scala SDK の適切なバージョンが組み合わされて表示されます。 Spark クラスターのバージョンが 2.0 より前の場合は、 [Spark 1.x] を選択します。 それ以外の場合は、 [Spark2.x] を選択します。 この例では、 [Spark 2.0.2 (Scala 2.11.8)] を使用します。
Spark プロジェクトによって自動的に成果物が作成されます。 次の操作を実行して、アーティファクトを表示します。
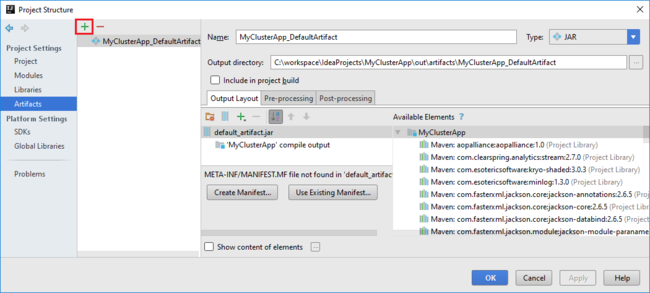
a. [File]\(ファイル\) メニューの [Project Structure]\(プロジェクトの構造\) を選択します。
b. [Project Structure](プロジェクト構造) ダイアログ ボックスで、 [Artifacts](成果物) を選択して、作成された既定の成果物を表示します。 プラス記号 ( + ) を選択して、独自の成果物を作成することもできます。
プロジェクトにライブラリを追加します。 ライブラリを追加するには、以下の手順を実行します。
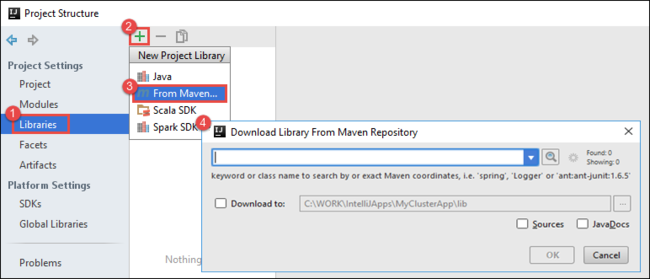
a. プロジェクト ツリーのプロジェクト名を右クリックし、 [Open Module Settings]\(モジュール設定を開く\) を選択します。
b. [Project Structure]\(プロジェクトの構造\) ダイアログ ボックスで、 [Libraries]\(ライブラリ\) 、( + ) 記号、 [From Maven]\(Maven から\) の順に選択します。
c. [Download Library from Maven Repository (Maven リポジトリからライブラリをダウンロード)] ダイアログ ボックスで、以下のライブラリを検索して追加します。
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
クラスターのヘッド ノードから
yarn-site.xmlとcore-site.xmlをコピーし、プロジェクトに追加します。 ファイルのコピーには次のコマンドを使用します。 Cygwin を使用して以下のscpコマンドを実行し、クラスターのヘッド ノードからファイルをコピーできます。scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .クラスター ヘッド ノードの IP アドレスとホスト名をデスクトップ上の hosts ファイルに追加済みであるため、以下のように
scpコマンドを使用できます。scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .これらのファイルをプロジェクトに追加するには、プロジェクト ツリー内の /src フォルダー (例:
<your project directory>\src) の下にこれらのファイルをコピーします。以下の変更を行うために
core-site.xmlファイルを更新します。a. 暗号化されたキーを置換します。
core-site.xmlファイルには、クラスターに関連付けられたストレージ アカウント用の暗号化されたキーが含まれます。 プロジェクトに追加したcore-site.xmlファイルで、暗号化されたキーを、既定のストレージ アカウントに関連付けられた実際のストレージ キーに置き換えます。 詳細については、「ストレージ アカウント アクセス キーを管理する」を参照してください。<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. 以下のエントリを
core-site.xmlから削除します。<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. ファイルを保存します。
アプリケーションに main クラスを追加します。 Project Explorer で、 [src] を右クリックし、 [New]\(新規\) をポイントして、 [Scala class]\(Scala クラス\) を選択します。
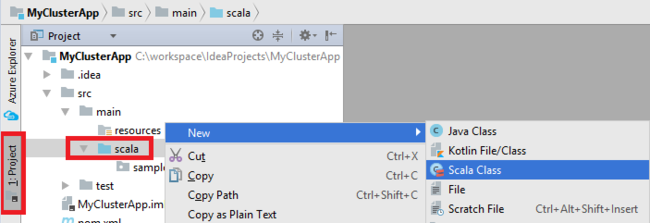
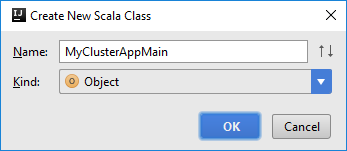
[Create New Scala Class]\(新規 Scala クラスの作成\) ダイアログ ボックスで、名前を指定し、 [Kind]\(種類\) ボックスの一覧で [Object]\(オブジェクト\) を選択して、 [OK] をクリックします。
以下のコードを
MyClusterAppMain.scalaファイルに貼り付けます。 このコードは Spark コンテキストを作成し、SparkSampleオブジェクトからexecuteJobメソッドを開きます。import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }手順 8. と手順 9. を繰り返して、
*SparkSampleという名前の新しい Scala オブジェクトを追加します。 以下のコードをこのクラスに追加します。 このコードは HVAC.csv (すべての HDInsight Spark クラスターで使用可能) からデータを読み取ります。 このコードは、CSV ファイルの 7 番目の列で 1 桁の数字のみが含まれる行を取得し、出力をクラスター用の既定のストレージ コンテナーの下にある /HVACOut に書き込みます。import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }手順 8. と手順 9. を繰り返して、
RemoteClusterDebuggingという名前の新しいクラスを追加します。 このクラスは、アプリケーションのデバッグに使用する Spark テスト フレームワークを実装します。 以下のコードをRemoteClusterDebuggingクラスに追加します。import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }注意すべき重要な点がいくつかあります。
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar")では、指定されたパスのクラスター ストレージで Spark アセンブリ JAR が使用可能であることを確認します。setJarsでは、アーティファクト JAR が作成される場所を指定します。 通常は<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jarです。
*RemoteClusterDebuggingクラスでtestキーワードを右クリックし、 [Create RemoteClusterDebugging Configuration]\(RemoteClusterDebugging 構成の作成\) を選択します。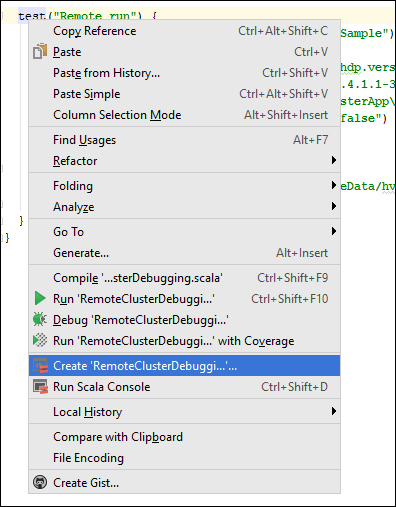
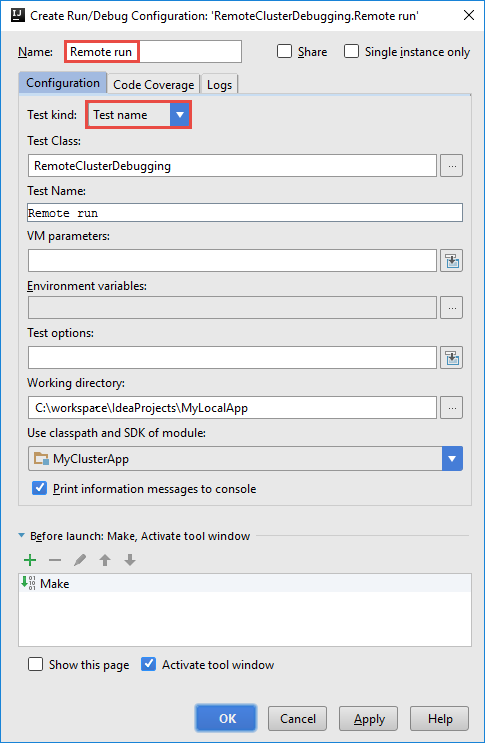
[Create RemoteClusterDebugging Configuration]\(RemoteClusterDebugging 構成の作成\) ダイアログ ボックスで、構成の名前を指定し、 [Test name]\(テスト名\) として [Test kind]\(テストの種類\) を選択します。 他の値はすべて規定の設定のままにします。 [Apply]\(適用\) を選択し、次に [OK] を選択します。
メニュー バーに、 [Remote Run]\(リモート実行\) の構成のドロップダウン リストが表示されます。

手順 5:デバッグ モードでアプリケーションを実行する
IntelliJ IDEA プロジェクトで、
SparkSample.scalaを開き、val rdd1の次にブレークポイントを作成します。 [Create Breakpoint for]\(ブレークポイントの作成対象\) ポップアップ メニューで [line in function executeJob]\(executeJob 関数内の行\) を選択します。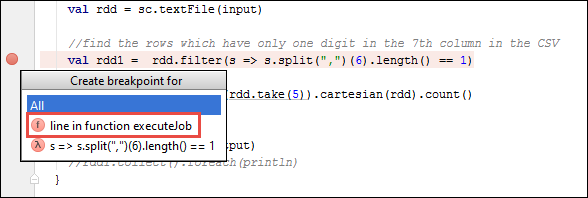
アプリケーションを実行するには、 [Remote Run]\(リモート実行\) の構成のドロップダウンの横にある [Debug Run]\(デバッグを実行\) ボタンを選択します。

プログラムの実行がブレークポイントに到達すると、下部のウィンドウに [Debugger]\(デバッガー\) タブが表示されます。
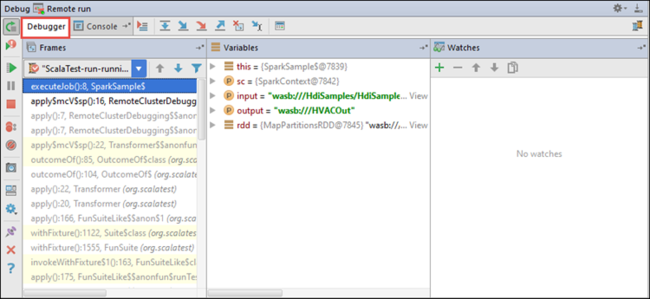
ウォッチ式を追加するには、( + ) アイコンを選択します。
この例では、変数
rdd1が作成される前にアプリケーションは停止しています。 このウォッチ式を使用して、変数rddの最初の 5 行を見ることができます。 [Enter] を選択します。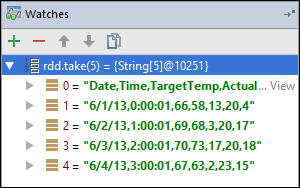
前の画像からわかるように、実行時に大量のデータを照会し、アプリケーションがどのように進行するかをデバッグできます。 たとえば、前の画像で示されている出力では、出力の最初の行がヘッダーであることがわかります。 この出力に基づいて、必要に応じてヘッダー行をスキップするようにアプリケーション コードを変更できます。
この時点で [Resume Program]\(プログラムの再開\) アイコンを選択すると、アプリケーションの実行を続けることができます。
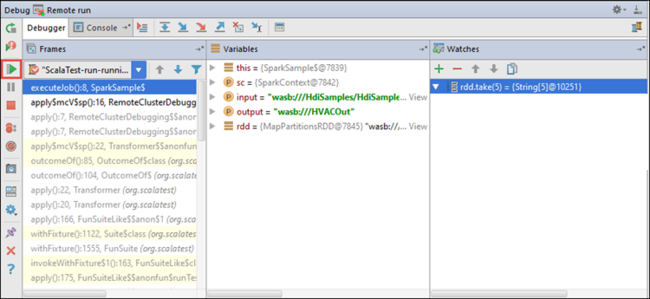
アプリケーションが正常に完了すると、次のような出力が表示されます。
次のステップ
シナリオ
- Apache Spark と BI:HDInsight と BI ツールで Spark を使用して対話型データ分析を実行する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して、HVAC データを使用して建物の温度を分析する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して食品の検査結果を予測する
- HDInsight 上での Apache Spark を使用した Web サイト ログ分析
アプリケーションの作成と実行
ツールと拡張機能
- Azure Toolkit for IntelliJ を使用して HDInsight クラスター向けの Apache Spark アプリケーションを作成する
- Azure Toolkit for IntelliJ を使用して SSH 経由で Apache Spark アプリケーションをリモートでデバッグする
- Azure Toolkit for Eclipse 上の HDInsight Tools を使用して Apache Spark アプリケーションを作成する
- HDInsight 上の Apache Spark クラスターで Apache Zeppelin Notebook を使用する
- HDInsight 用の Apache Spark クラスター内の Jupyter Notebook で使用可能なカーネル
- Jupyter Notebook で外部のパッケージを使用する
- Jupyter をコンピューターにインストールして HDInsight Spark クラスターに接続する