Azure Toolkit for IntelliJ を使用して HDInsight クラスター上で SSH により Apache Spark アプリケーションをデバッグする
この記事では、Azure Toolkit for IntelliJ の HDInsight Tools を使用して HDInsight クラスターでアプリケーションをリモートでデバッグする方法に関する詳細な手順について説明します。
前提条件
HDInsight での Apache Spark クラスター。 Apache Spark クラスターの作成に関するページを参照してください。
Windows ユーザーの場合:Windows コンピューターでローカルの Spark Scala アプリケーションを実行中に、SPARK-2356 で説明されている例外が発生する場合があります。 この例外は、Windows 上に WinUtils.exe がないことが原因で発生します。
このエラーを回避するには、Winutils.exe をダウンロードして、C:\WinUtils\bin などの場所に保存します。 次に、環境変数 HADOOP_HOME を追加し、この変数の値を C:\WinUtils に設定します。
IntelliJ IDEA (Community エディションは無料です。)
SSH クライアント 詳細については、SSH を使用して HDInsight (Apache Hadoop) に接続する方法に関するページを参照してください。
Spark Scala アプリケーションを作成する
IntelliJ IDEA を起動し、 [Create New Project](新しいプロジェクトの作成) を選択して、 [New Project](新しいプロジェクト) ウィンドウを開きます。
左側のウィンドウから [Apache Spark/HDInsight] を選択します。
メイン ウィンドウから [サンプルありの Spark プロジェクト (Scala)] を選択します。
[Build tool](ビルド ツール) ドロップダウン ボックスの一覧で、次のいずれかを選択します。
- Scala プロジェクト作成ウィザードをサポートする場合は Maven。
- 依存関係を管理し、Scala プロジェクトをビルドする場合は SBT。
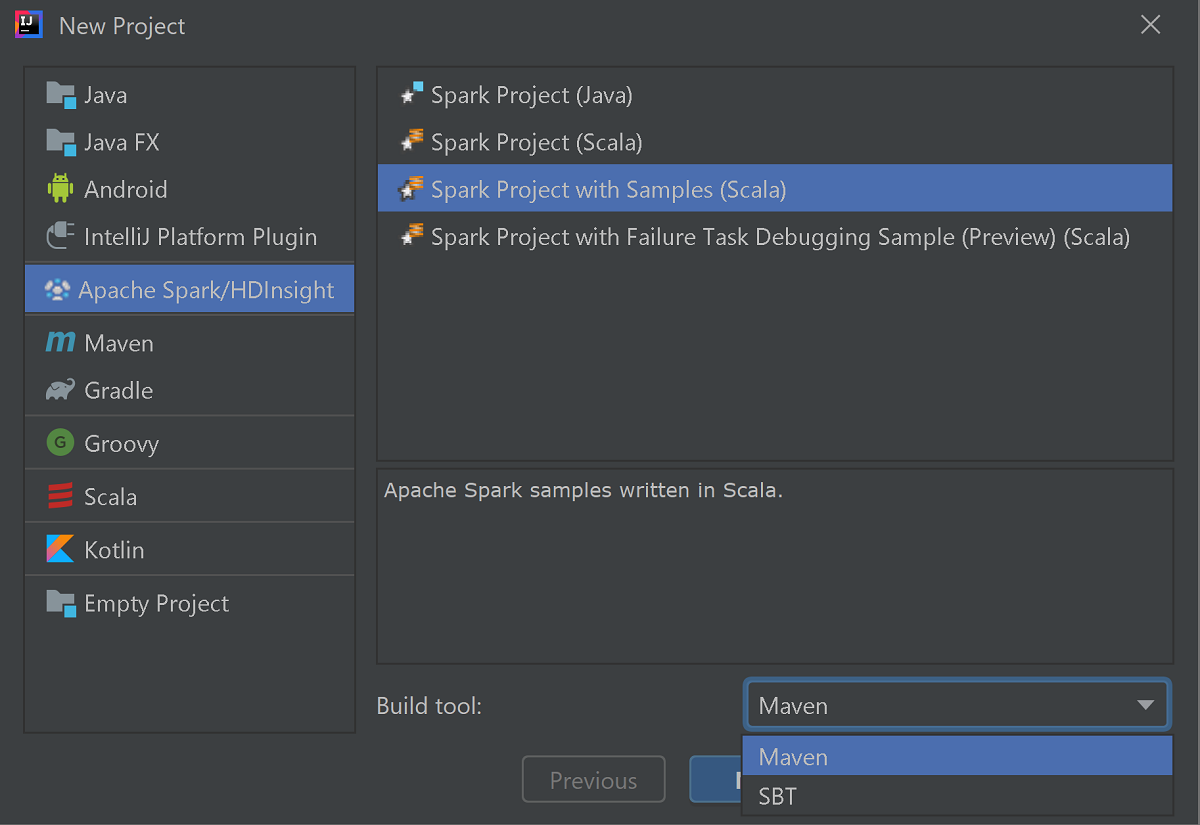
[次へ] を選択します。
次の [新しいプロジェクト] ウィンドウで、次の情報を指定します。
プロパティ 説明 プロジェクト名 名前を入力します。 このチュートリアルは myAppを使用します。プロジェクトの場所 プロジェクトを保存する任意の場所を入力します。 Project SDK (プロジェクト SDK) 空白の場合は、 [新規作成] を選択し、JDK に移動します。 Spark バージョン 作成ウィザードにより、Spark SDK と Scala SDK の適切なバージョンが統合されます。 Spark クラスターのバージョンが 2.0 より前の場合は、 [Spark 1.x] を選択します。 それ以外の場合は、 [Spark 2.x] を選択します。 この例では、Spark 2.3.0 (Scala 2.11.8) を使用します。 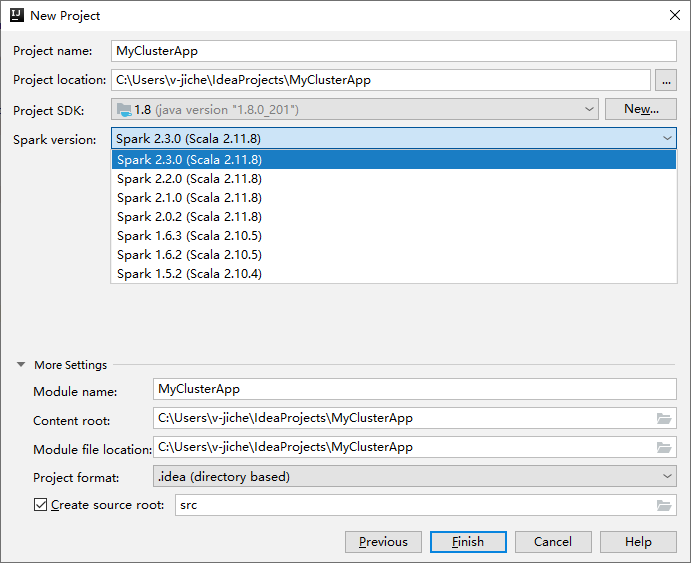
完了 を選択します。 プロジェクトが使用可能になるまで数分かかる場合があります。 右下隅の進行状況を監視します。
プロジェクトを展開し、src>main>scala>sample に移動します。 [SparkCore_WasbIOTest] をダブルクリックします。
ローカルで実行する
SparkCore_WasbIOTest スクリプトから、スクリプト エディターを右クリックし、 [Run 'SparkCore_WasbIOTest'] ('SparkCore_WasbIOTest' の実行) オプションを選択してローカルで実行します。
ローカル実行が完了すると、現在のプロジェクト エクスプローラーの [data]>[default] に出力ファイルが保存されていることを確認できます。
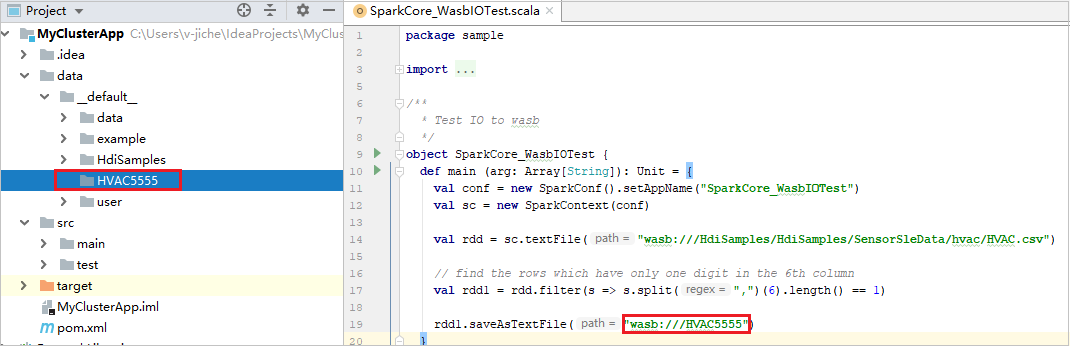
ローカル実行とローカル デバッグを行うと、既定のローカル実行構成が自動的に設定されます。 右上済の [Spark on HDInsight] XXX という構成を開くと、 [HDInsight の Apache Spark] の下に [Spark on HDInsight]XXX が既に作成されていることがわかります。 [Locally Run](ローカル実行) タブに切り替えます。
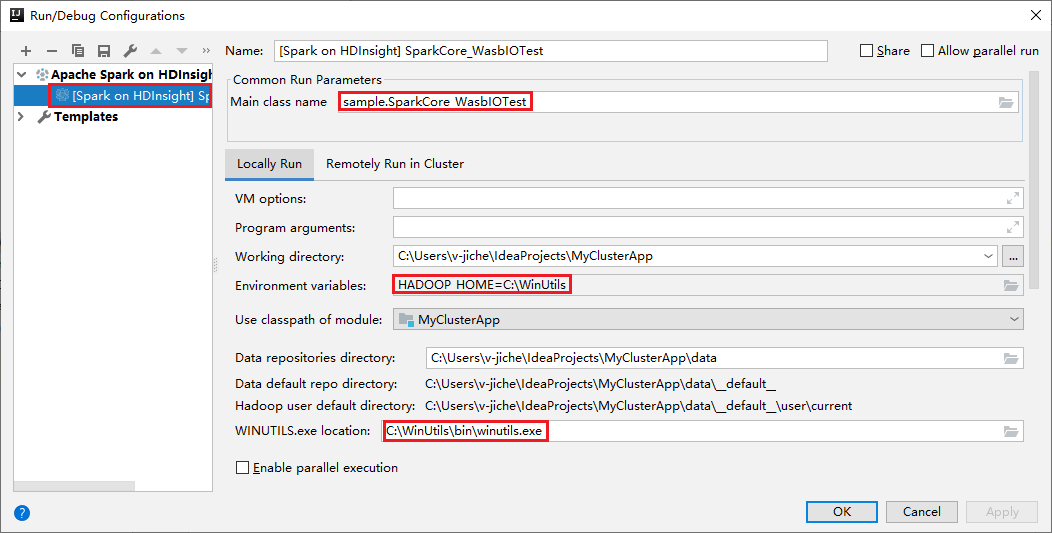
- 環境変数:システム環境変数 HADOOP_HOME を C:\WinUtils に設定した場合は、自動的に検出されます。手動で追加する必要はありません。
- [WinUtils.exe Location](WinUtils.exe の場所):システム環境変数が未設定である場合、対応するボタンをクリックして場所を探すことができます。
- 2 つのオプションのどちらかを選択するだけです。これらは macOS と Linux では必要ありません。
ローカル実行とローカル デバッグの前に構成を手動で設定することもできます。 先ほどのスクリーンショットの正符号 ( + ) を選択します。 次に [HDInsight での Apache Spark] オプションを選択します。 [Name](名前) と [Main class name](メイン クラス名) の情報を入力して保存し、ローカル実行ボタンをクリックします。
ローカル デバッグを実行する
SparkCore_wasbloTest スクリプトを開いてブレークポイントを設定します。
スクリプト エディターを右クリックし、 [Debug '[Spark on HDInsight]XXX']('[Spark on HDInsight]XXX' のデバッグ) オプションを選択してローカル デバッグを実行します。
リモートで実行する
[実行]>[Edit Configurations...] (構成の編集...) の順に移動します。このメニューでは、リモート デバッグの構成を作成または編集できます。
[実行/デバッグ構成] ダイアログ ボックスで、プラス記号 ( + ) を選択します。 次に [HDInsight での Apache Spark] オプションを選択します。
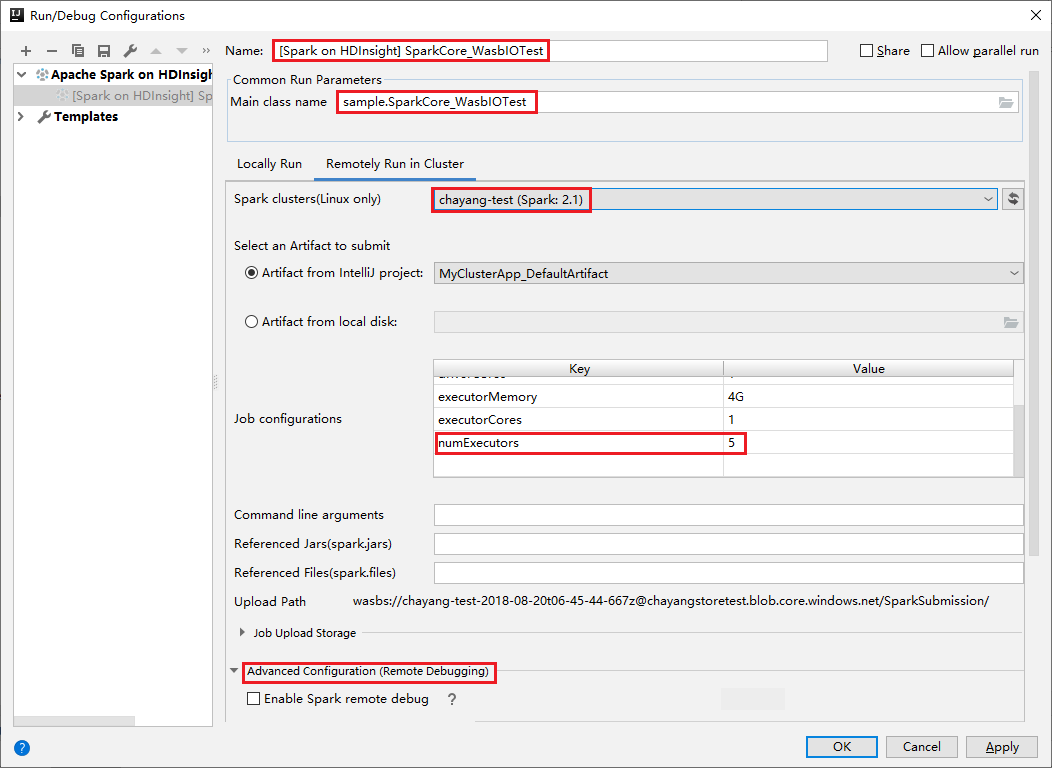
[Remotely Run in Cluster](クラスターでリモート実行) タブに切り替えます。 [名前] 、 [Spark cluster](Spark クラスター) 、 [Main class name](メイン クラス名) に情報を入力します。 [詳細な構成 (リモート デバッグ)] をクリックします。 ツールでは、Executor を使用したデバッグがサポートされています。 numExecutors の既定値は 5 です。 3 より大きい値に設定することはお勧めできません。
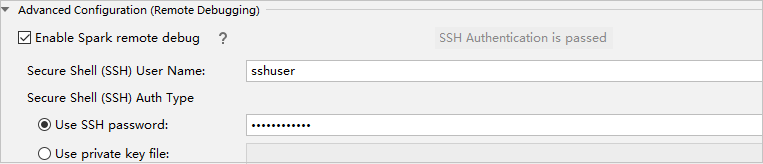
[詳細な構成 (リモート デバッグ)] パートで、 [Enable Spark remote debug](Spark のリモート デバッグを有効化) を選択します。 SSH ユーザー名を入力し、次にパスワードを入力するか、秘密キー ファイルを使用します。 リモート デバッグを実行する場合は、これを設定する必要があります。 リモート実行を使用する場合は、設定する必要はありません。
指定した名前で構成が保存されます。 構成の詳細を表示するには、構成名を選択します。 変更するには、 [構成の編集] を選択します。
構成の設定が完了したら、リモート クラスターでプロジェクトを実行したり、リモート デバッグを実行したりすることができます。

[切断] ボタンをクリックします。送信ログは左側のパネルに表示されません。 ただし、バックエンドで実行が続けられています。
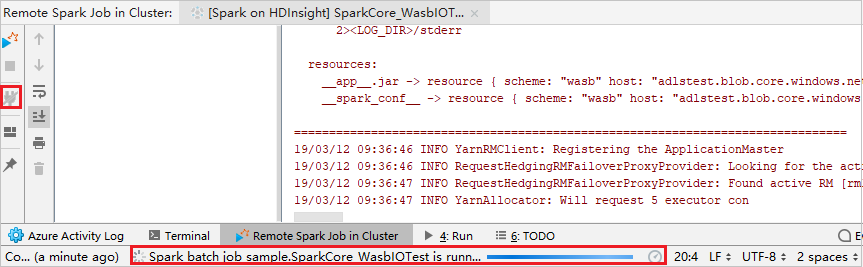
リモート デバッグを実行する
ブレークポイントを設定し、 [Remote debug](リモート デバッグ) アイコンをクリックします。 リモート送信との違いは、SSH ユーザー名/パスワードの構成が必要である点です。

プログラムの実行がブレークポイントに達すると、 [ドライバー] タブと 2 つの [Executor] タブが [デバッガー] ウィンドウに表示されます。 [Resume Program](プログラムの再開) アイコンを選択してコードの実行を続けます。その後、次のブレークポイントに到達します。 デバッグの対象となる Executor を見つけるには、正しい [Executor] タブに切り替える必要があります。 対応する [Console](コンソール) タブで実行ログを確認できます。
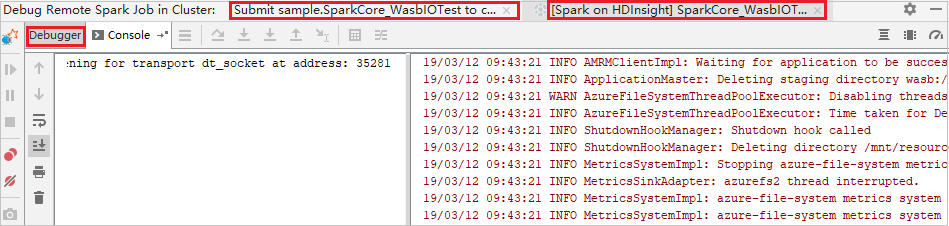
リモート デバッグを実行し、バグを修正するには
2 つのブレークポイントを設定し、 [デバッグ] アイコンを選択して、リモート デバッグ プロセスを開始します。
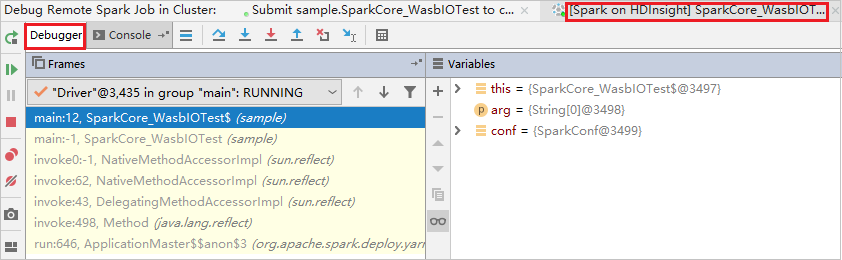
最初のブレークポイントでコードが停止し、 [変数] ウィンドウにパラメーターと変数の情報が表示されます。
[Resume Program](プログラムの再開) アイコンを選択して続行します。 2 番めのブレーク ポイントでコードが停止します。 例外が想定どおりにキャッチされます。
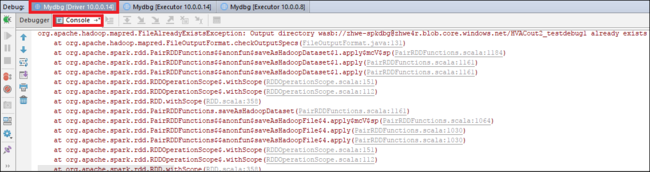
もう一度 [Resume Program](プログラムの再開) アイコンを選択します。 [HDInsight Spark Submission](HDInsight Spark の送信) ウィンドウに、"ジョブ実行失敗" エラーが表示されます。
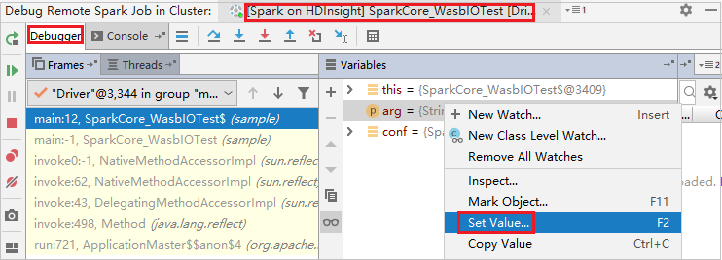
IntelliJ のデバッグ機能を使って変数の値を動的に更新するには、もう一度 [デバッグ] を選択します。 [変数] ウィンドウが再度表示されます。
[デバッグ] タブでターゲットを右クリックし、 [値の設定] を選択します。 次に、変数に新しい値を入力します。 [Enter](確定) を選択して値を保存します。
[Resume Program](プログラムの再開) アイコンを選択して、プログラムの実行を続けます。 今回は例外はキャッチされません。 プロジェクトは例外なしに正常に実行されていることが表示されます。
次のステップ
シナリオ
- Apache Spark と BI:HDInsight と BI ツールで Spark を使用して対話型データ分析を実行する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して、HVAC データを使用して建物の温度を分析する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して食品の検査結果を予測する
- HDInsight 上での Apache Spark を使用した Web サイト ログ分析
アプリケーションの作成と実行
ツールと拡張機能
- Azure Toolkit for IntelliJ を使用して HDInsight クラスター向けの Apache Spark アプリケーションを作成する
- Azure Toolkit for IntelliJ を使用して VPN 経由で Apache Spark アプリケーションをリモートでデバッグする
- Azure Toolkit for Eclipse 上の HDInsight Tools を使用して Apache Spark アプリケーションを作成する
- HDInsight 上の Apache Spark クラスターで Apache Zeppelin Notebook を使用する
- HDInsight 用の Apache Spark クラスター内の Jupyter Notebook で使用可能なカーネル
- Jupyter Notebook で外部のパッケージを使用する
- Jupyter をコンピューターにインストールして HDInsight Spark クラスターに接続する