Preparare i dati per l'analisi
Nella fase precedente di questa esercitazione è stato installato PyTorch nel computer. A questo punto, verrà usato per configurare il codice con i dati che verranno usati per creare il modello.
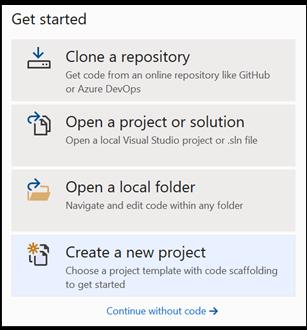
Aprire un nuovo progetto in Visual Studio.
- Aprire Visual Studio e scegliere
create a new project.
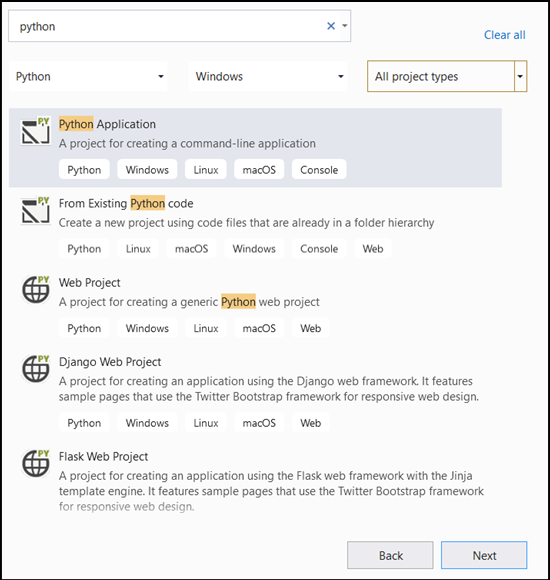
- Nella barra di ricerca digitare
Pythone selezionarePython Applicationcome modello di progetto.
- Nella finestra di configurazione:
- Assegnare un nome al progetto. In questo caso, viene chiamato DataClassifier.
- Scegliere il percorso del progetto.
- Se si usa VS2019, verificare che
Create directory for solutionsia selezionata. - Se si usa VS2017, verificare che
Place solution and project in the same directorysia deselezionata.
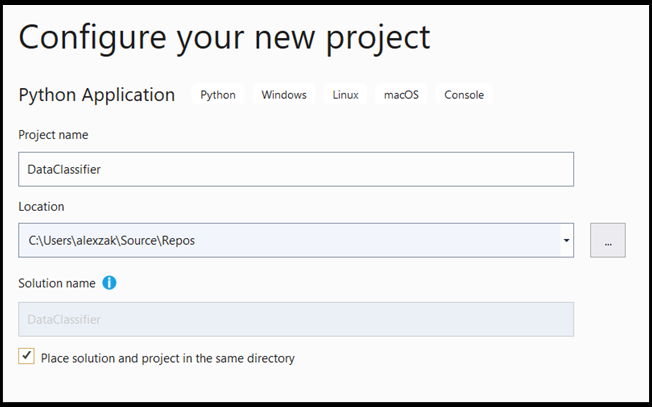
Premere create per creare il progetto.
Creare un interprete Python
A questo scopo, è necessario definire un nuovo interprete Python. Deve includere il pacchetto PyTorch installato di recente.
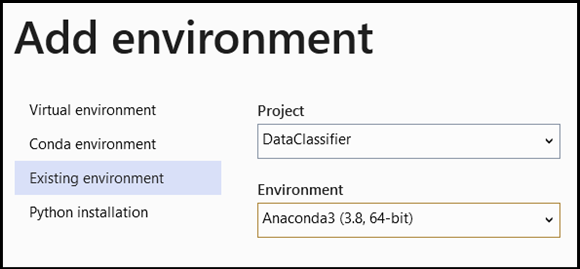
- Passare alla selezione dell'interprete e selezionare
Add Environment:

Add EnvironmentNella finestra selezionareExisting environmente scegliereAnaconda3 (3.6, 64-bit). Questo include il pacchetto PyTorch.
Per testare il nuovo interprete Python e il pacchetto PyTorch, immettere il codice seguente nel DataClassifier.py file:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
L'output deve essere un tensore casuale 5x3 simile al seguente.
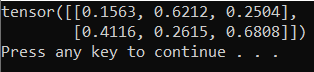
Nota
Sei interessato a scoprire di più? Visita il sito ufficiale di PyTorch.
Informazioni sui dati
Verrà eseguito il training del modello nel set di dati Iris di Fisher. Questo famoso set di dati include 50 record per ognuna delle tre specie Iris: Iris setosa, Iris virginica e Iris versicolor.
Sono state pubblicate diverse versioni del set di dati. È possibile trovare il set di dati Iris nel repository di Machine Learning UCI, importare il set di dati direttamente dalla libreria Python Scikit-learn o usare qualsiasi altra versione pubblicata in precedenza. Per informazioni sul set di dati dei fiori Iris, visitare la pagina di Wikipedia.
In questa esercitazione, per illustrare come eseguire il training del modello con il tipo tabulare di input, si userà il set di dati Iris esportato nel file di Excel.
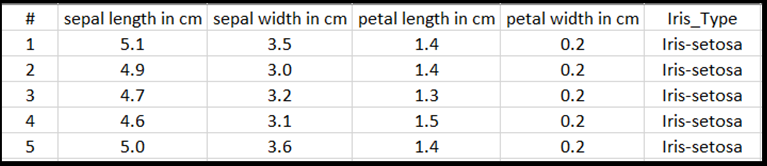
Ogni riga della tabella excel mostrerà quattro caratteristiche di Irises: lunghezza sepale in cm, larghezza del sepale in cm, lunghezza petalo in cm e larghezza petalo in cm. Queste funzionalità fungeranno da input. L'ultima colonna include il tipo Iris correlato a questi parametri e rappresenterà l'output di regressione. In totale, il set di dati include 150 input di quattro funzionalità, ognuno dei quali corrisponde al tipo Iris pertinente.
L'analisi della regressione esamina la relazione tra le variabili di input e il risultato. In base all'input, il modello imparerà a stimare il tipo di output corretto, uno dei tre tipi Iris: Iris-setosa, Iris-versicolor, Iris-virginica.
Importante
Se si decide di usare qualsiasi altro set di dati per creare un modello personalizzato, sarà necessario specificare le variabili di input del modello e l'output in base allo scenario.
Caricare il set di dati.
Scaricare il set di dati Iris in formato Excel. È possibile trovarlo qui.
DataClassifier.pyNel file nella cartella Esplora soluzioni Files aggiungere l'istruzione import seguente per ottenere l'accesso a tutti i pacchetti necessari.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Come si può notare, si usa il pacchetto pandas (analisi dei dati Python) per caricare e modificare i dati e il pacchetto torch.nn che contiene moduli e classi estendibili per la creazione di reti neurali.
- Caricare i dati in memoria e verificare il numero di classi. Ci aspettiamo di vedere 50 elementi di ogni tipo Iris. Assicurarsi di specificare il percorso del set di dati nel PC.
Aggiungere il codice seguente al file DataClassifier.py.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Quando si esegue questo codice, l'output previsto è il seguente:
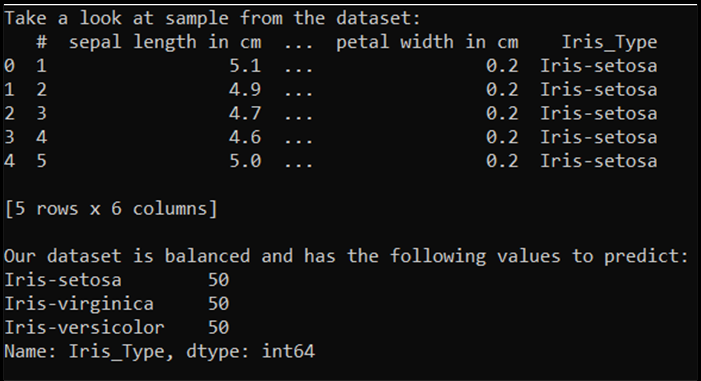
Per poter usare il set di dati ed eseguire il training del modello, è necessario definire l'input e l'output. L'input include 150 righe di funzionalità e l'output è la colonna di tipo Iris. La rete neurale che verrà usata richiede variabili numeriche, quindi si convertirà la variabile di output in un formato numerico.
- Creare una nuova colonna nel set di dati che rappresenterà l'output in un formato numerico e definirà un input e un output di regressione.
Aggiungere il codice seguente al file DataClassifier.py.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Quando si esegue questo codice, l'output previsto è il seguente:
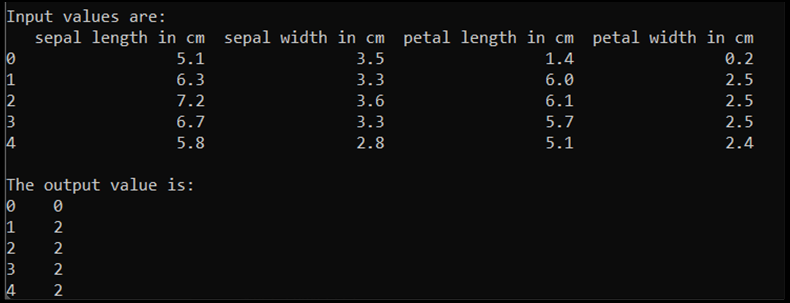
Per eseguire il training del modello, è necessario convertire l'input e l'output del modello nel formato Tensor:
- Converti in Tensor:
Aggiungere il codice seguente al file DataClassifier.py.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Se si esegue il codice, l'output previsto mostrerà il formato di input e output, come indicato di seguito:

Sono presenti 150 valori di input. Circa il 60% sarà rappresentato dai dati di training del modello. Si manterrà il 20% per la convalida e il 30% per un test.
In questa esercitazione le dimensioni del batch per un set di dati di training vengono definite come 10. Nel set di training sono presenti 95 elementi, il che significa che in media sono presenti 9 batch completi per scorrere il set di training una volta (un periodo). Le dimensioni batch dei set di convalida e di test verranno mantenuto come 1.
- Suddividere i dati per eseguire il training, la convalida e i set di test:
Aggiungere il codice seguente al file DataClassifier.py.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Passaggi successivi
Con i dati pronti per l'uso, è possibile eseguire il training del modello PyTorch