Utilizzare lakehouse di Microsoft Fabric
Ora che si conoscono le funzionalità principali di un lakehouse Microsoft Fabric, è possibile esaminarne le modalità di utilizzo.
Creare ed esplorare una lakehouse
Quando si crea un nuovo lakehouse, vengono creati automaticamente tre elementi di dati diversi nell’area di lavoro.
- Il lakehouse contiene collegamenti, cartelle, file e tabelle.
- Il modello semantico (impostazione predefinita) offre un'origine dati semplice per gli sviluppatori di report di Power BI.
- L'endpoint di Analisi SQL consente l'accesso in sola lettura ai dati di query con SQL.
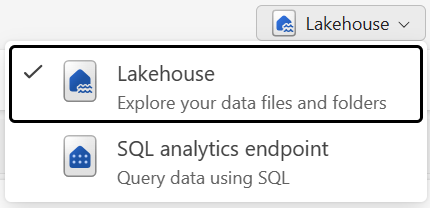
È possibile usare i dati nella lakehouse in due modalità:
- Il lakehouse consente di aggiungere e interagire con tabelle, file e cartelle nel lakehouse.
- L'endpoint di analisi SQL consente di usare SQL per eseguire query sulle tabelle nella lakehouse e gestire il modello semantico relazionale.
Inserire dati in una lakehouse
L'inserimento di dati nel lakehouse è il primo passaggio del processo ETL. Usare uno dei metodi seguenti per inserire i dati nel lakehouse.
- Caricamento: Caricare i file locali.
- Flussi di dati Gen2: Importare e trasformare i dati usando Power Query.
- Notebooks: Usare Apache Spark per inserire, trasformare e caricare i dati.
- Pipeline di Data factory: Usare l'attività Copia dati.
Questi dati possono quindi essere caricati direttamente in file o tabelle. Prendere in considerazione il modello di caricamento dei dati durante l'inserimento di dati per determinare se è necessario caricare tutti i dati non elaborati come file prima dell’elaborazione o usare tabelle di staging.
Le definizioni dei processi Spark possono essere usate anche per inviare processi batch/streaming ai cluster Spark. Caricando i file binari dall'output di compilazione di linguaggi diversi (ad esempio .jar da Java), è possibile applicare logica di trasformazione diversa ai dati ospitati in un lakehouse. Oltre al file binario, è possibile personalizzare ulteriormente il comportamento del processo caricando più librerie e argomenti della riga di comando.
Nota
Per altre informazioni, vedere la documentazione relativa a Creare una definizione del processo Apache Spark.
Accedere ai dati usando i collegamenti
Un altro modo per accedere e usare i dati in Fabric consiste nell'usare i collegamenti. I collegamenti consentono di integrare i dati nella lakehouse mantenendoli archiviati nell’archiviazione esterna.
I collegamenti sono utili quando è necessario recuperare i dati che si trovano in un altro account di archiviazione o addirittura in un altro provider di servizi cloud. All'interno del lakehouse è possibile creare collegamenti per accedere a diversi account di archiviazione e ad altri elementi di Fabric, ad esempio data warehouse, database KQL e altri lakehouse.
Le autorizzazioni e le credenziali dei dati di origine sono tutte gestite da OneLake. Quando si accede ai dati tramite un collegamento a un'altra sede OneLake, l'identità dell'utente chiamante verrà utilizzata per autorizzare l'accesso ai dati nel percorso di destinazione del collegamento. L'utente deve disporre delle autorizzazioni nella posizione di destinazione per leggere i dati.
I collegamenti possono essere creati sia nelle lakehouse che nei database KQL e vengono visualizzati come una cartella nel lake. Ciò consente a Spark, SQL, Real-Time intelligence e Analysis Services di usare collegamenti per l'esecuzione di query sui dati.
Nota
Per altre informazioni sull’uso dei collegamenti, vedere la documentazione dei collegamenti a OneLake nella documentazione di Microsoft Fabric.