Qualità dei dati per fabric lakehouse data estate (anteprima)
Fabric OneLake è un singolo data lake logico unificato per l'intera organizzazione. Un data Lake elabora grandi volumi di dati da varie origini. Come OneDrive, OneLake viene fornito automaticamente con ogni tenant di Microsoft Fabric ed è progettato per essere l'unica posizione per tutti i dati di analisi. OneLake offre ai clienti:
- Un data lake per l'intera organizzazione
- Una copia dei dati da usare con più motori analitici
OneLake ha lo scopo di offrire il massimo valore possibile da una singola copia di dati senza spostamento o duplicazione dei dati. Non è più necessario copiare i dati solo per usarli con un altro motore o per suddividere i silo in modo da poter analizzare i dati con dati provenienti da altre origini. È possibile usare Microsoft Purview per catalogare il patrimonio dati dell'infrastruttura e misurare la qualità dei dati per gestire e promuovere l'azione di miglioramento.
È possibile usare il collegamento per fare riferimento ai dati archiviati in altri percorsi di file. Questi percorsi di file possono trovarsi all'interno della stessa area di lavoro o in aree di lavoro diverse, all'interno di OneLake o esterne a OneLake in Azure Data Lake Storage (ADLS), AWS S3 o Dataverse con altre posizioni di destinazione presto disponibili. La posizione dell'origine dati non importa molto, i collegamenti a OneLake fanno sembrare che file e cartelle siano archiviati in locale. Quando i team lavorano in modo indipendente in aree di lavoro separate, i collegamenti consentono di combinare i dati tra diversi gruppi di business e domini in un prodotto dati virtuale in base alle esigenze specifiche di un utente.
È possibile usare il mirroring per riunire i dati di varie origini in Fabric Mirroring in Fabric è una soluzione a basso costo e a bassa latenza per riunire i dati di vari sistemi in un'unica piattaforma di analisi. È possibile replicare continuamente il patrimonio dati esistente direttamente in OneLake di Fabric, inclusi i dati di Azure SQL Database, Azure Cosmos DB e Snowflake. Con i dati più aggiornati in un formato queryable in OneLake, è ora possibile usare tutti i diversi servizi in Fabric. Ad esempio, l'esecuzione di analisi con Spark, l'esecuzione di notebook, la progettazione dei dati, la visualizzazione tramite report di Power BI e altro ancora. Le tabelle Delta possono quindi essere usate ovunque Fabric, consentendo agli utenti di accelerare il loro percorso in Fabric.
Configurare l'analisi della mappa dati
Per configurare l'analisi di Mapping dei dati, è necessario registrare l'origine dati da analizzare.
Registrare Fabric OneLake
Per l'analisi dell'area di lavoro di Fabric, non sono presenti modifiche all'esperienza esistente per registrare un tenant di Fabric come origine dati. Per registrare una nuova origine dati in Microsoft Purview Unified Catalog, seguire questa procedura:
- Passare all'account Microsoft Purview nel portale di governance di Microsoft Purview.
- Selezionare Mappa dati nel riquadro di spostamento a sinistra.
- Selezionare Registra
- In Registra origini selezionare Infrastruttura
Per istruzioni sull'installazione, vedere lo stesso tenant e lo stesso tenant.
Configurare l'analisi della mappa dati
Per l'analisi dei subartifact di Lakehouse, non sono presenti modifiche all'esperienza esistente in Purview per configurare un'analisi. È disponibile un altro passaggio per concedere alle credenziali di analisi almeno il ruolo Collaboratore nelle aree di lavoro fabric per estrarre le informazioni sullo schema dai formati di file supportati.
Attualmente solo l'entità servizio è supportata come metodo di autenticazione. Il supporto dell'identità del servizio gestito è ancora in backlog.
Per istruzioni sull'installazione, vedere lo stesso tenant e lo stesso tenant.
Configurare la connessione per l'analisi di Fabric Lakehouse
Dopo aver registrato Fabric Lakehouse come origine, è possibile selezionare Fabric dall'elenco delle origini dati registrate e selezionare Nuova analisi. Aggiungere i dettagli di connessione come evidenziato negli screenshot seguenti.

- Creare un gruppo di sicurezza e un'entità servizio
- Assicurarsi di aggiungere sia questa entità servizio che l'identità gestita purview al gruppo di sicurezza e quindi specificare questo gruppo di sicurezza.
- Associare il gruppo di sicurezza al tenant di Fabric
- Accedere al portale di amministrazione di Fabric.
- Selezionare la pagina Impostazioni tenant. È necessario essere un Amministrazione fabric per visualizzare la pagina delle impostazioni del tenant.
- Selezionare Amministrazione impostazioni > API Consenti alle entità servizio di usare le API di amministrazione di sola lettura.
- Selezionare Gruppi di sicurezza specifici.
- Selezionare Amministrazione impostazioni > API Migliorare le risposte alle API di amministrazione con metadati dettagliati e Migliorare le risposte alle API di amministrazione con espressioni > DAX e mashup Abilita l'interruttore per consentire Microsoft Purview Data Map individuare automaticamente i metadati dettagliati dei set di dati di Fabric come parte delle analisi. Dopo aver aggiornato le impostazioni dell'API Amministrazione nel tenant di Fabric, attendere circa 15 minuti prima di registrare una connessione di analisi e test.
- Specificare Amministrazione'autorizzazione API di sola lettura per le impostazioni DELL'API per questo gruppo di sicurezza.
- Aggiungere SPN nel campo Credenziali .
- Aggiungere il nome della risorsa di Azure.

- Aggiungere l'ID tenant.
- Aggiungere l'ID principio di servizio.
- Aggiungere Key Vault connessione.
- Aggiungere il nome del segreto.

Dopo aver completato l'analisi della mappa dati, individuare un'istanza di Lakehouse da Unified Catalog.

Sfogliare le tabelle lakehouse tramite la categoria tabelle .

Prerequisiti per l'analisi della qualità dei dati di Fabric Lakehouse
- Collegamento, mirroring o caricamento dei dati in Fabric Lakehouse in formato delta.

Importante
Se sono state aggiunte nuove tabelle, file o nuovi set di dati a Fabric Lakehouse tramite morroring o collegamento, è necessario eseguire l'analisi dell'ambito della mappa dati per catalogare il nuovo set di dati prima di aggiungere tali asset di dati al prodotto dati per la valutazione della qualità dei dati.
- Concedere il diritto collaboratore all'area di lavoro per l'identità del servizio gestito di Purview

- Aggiungere asset di dati analizzati da Lakehouse ai prodotti dati del dominio di governance. La profilatura dei dati e l'analisi DQ possono essere eseguite solo per gli asset di dati associati ai prodotti dati nel dominio di governance.

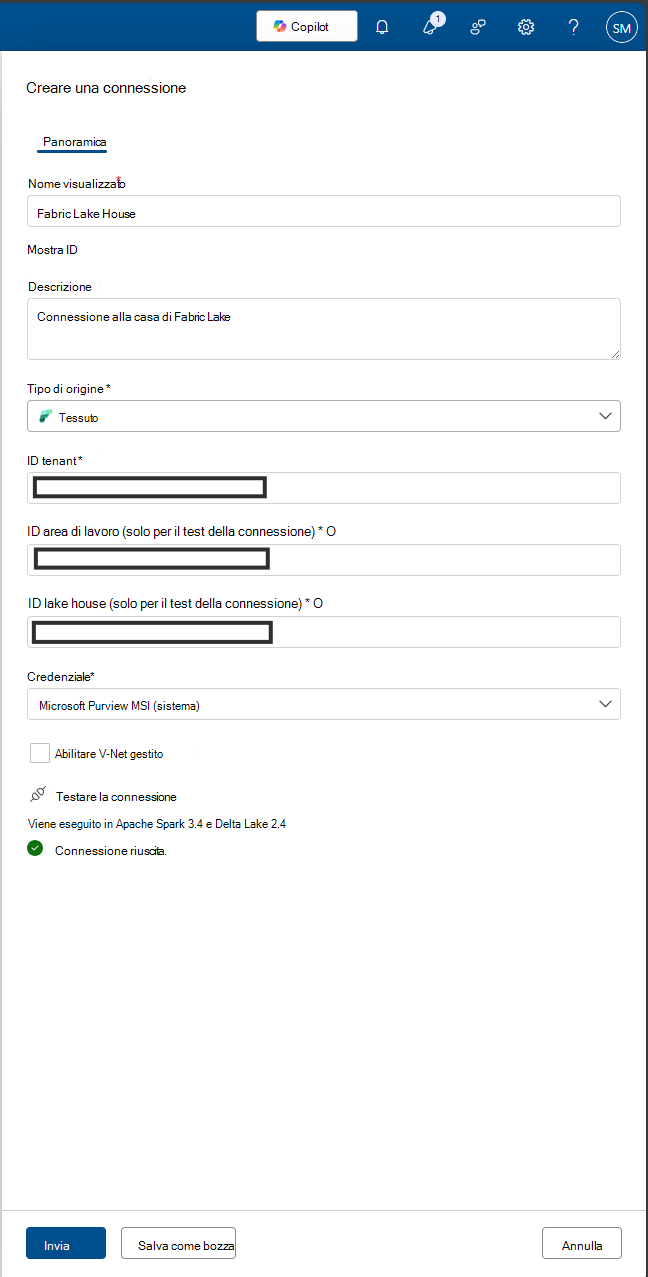
Per la profilatura dei dati e l'analisi della qualità dei dati, è necessario creare una connessione all'origine dati perché si usa un connettore diverso per connettere l'origine dati e analizzare i dati per acquisire dati e dimensioni e fatti relativi alla qualità dei dati. Per configurare la connessione:
In Unified Catalog selezionare Gestione integrità e quindi Qualità dei dati.
Selezionare un dominio di governance e nell'elenco a discesa Gestisci selezionare Connections.
Selezionare Nuovo per aprire la pagina di configurazione della connessione.
Aggiungere il nome visualizzato della connessione e una descrizione.
Aggiungere il tipo di origine Fabric.
Aggiungere l'ID tenant.
Aggiungere Credential - Microsoft Purview MSI.
Testare la connessione per assicurarsi che la connessione configurata abbia esito positivo.

Importante
- Per l'analisi DQ, l'identità del servizio gestito di Purview deve avere accesso come collaboratore all'area di lavoro Fabric per connettere l'area di lavoro di Fabric. Per concedere l'accesso ai collaboratori, aprire l'area di lavoro di Fabric, selezionare tre punti (...), selezionare Accesso all'area di lavoro, quindi Aggiungere utenti o gruppi e quindi aggiungere Purview MSI come collaboratore.
- Le tabelle di infrastruttura devono essere in formato delta o iceberg.
Analisi della profilatura e della qualità dei dati (DQ) per i dati in Fabric Lakehouse
Dopo aver completato correttamente l'installazione della connessione, è possibile profilare, creare e applicare regole ed eseguire l'analisi DQ (Data Quality) dei dati in Fabric Lakehouse. Seguire le linee guida dettagliate descritte di seguito:
- Associare una tabella Lakehouse a un prodotto dati per la cura, l'individuazione e la sottoscrizione. Per altri dettagli, seguire il documento -how to create and manage data products (Come creare e gestire i prodotti dati)

- Tabella Lakehouse di Profile Fabric. Per altri dettagli, seguire il documento -how to configure and run data profiling of your data profiling of your data (Come configurare ed eseguire la profilatura dei dati dei dati)

- Configurare ed eseguire l'analisi della qualità dei dati per misurare la qualità dei dati di una tabella fabric lakehouse. Per altri dettagli, seguire il documento : come configurare ed eseguire l'analisi della qualità dei dati

Importante
- Assicurarsi che i dati siano in formato delta o iceberg.
- Assicurarsi che l'analisi mappa dati sia stata eseguita correttamente, se non eseguire di nuovo l'analisi della mappa dati.
Limitazione
La qualità dei dati per il file Parquet è progettata per supportare:
- Directory con il file di parte Parquet. Ad esempio: ./Sales/{Parquet Part Files}. Il nome completo deve seguire
https://(storage account).dfs.core.windows.net/(container)/path/path2/{SparkPartitions}. Assicurarsi di non avere {n} modelli nella struttura di directory/sottodirectory, ma deve essere un FQN diretto che porta a {SparkPartitions}. - Directory con file Parquet partizionati, partizionati in base alle colonne all'interno del set di dati, ad esempio i dati di vendita partizionati per anno e mese. Ad esempio: ./Sales/{Year=2018}/{Month=Dec}/{Parquet Part Files}.
Sono supportati entrambi questi scenari essenziali che presentano uno schema di set di dati Parquet coerente. Limitazione: non è progettata per supportare o non supporta N gerarchie arbitrarie di directory con file Parquet. Si consiglia al cliente di presentare i dati nella struttura costruita (1) o (2). Pertanto, consigliare al cliente di seguire lo standard parquet supportato o di eseguire la migrazione dei dati al formato delta conforme ad ACID .
Consiglio
Per mappa dati
- Assicurarsi che SPN disponga delle autorizzazioni dell'area di lavoro.
- Assicurarsi che la connessione di analisi usi SPN.
- Suggerirei di eseguire la scansione completa se si sta configurando la prima analisi lakehouse.
- Verificare che gli asset inseriti siano stati aggiornati/aggiornati
Unified Catalog
- La connessione DQ deve usare le credenziali dell'identità del servizio gestito.
- Creare idealmente un nuovo prodotto dati per testare per la prima volta l'analisi DQ dei dati lakehouse
- Aggiungere gli asset di dati inseriti, verificare che l'asset di dati sia aggiornato.
- Provare a eseguire il profilo, in caso di esito positivo, provare a eseguire la regola DQ. se l'operazione non riesce, provare ad aggiornare lo schema di asset (schema di importazione della gestione dello schema> )
- Alcuni utenti hanno anche dovuto creare un nuovo Lakehouse e dati di esempio solo per controllare tutto funziona da zero. In alcuni casi, l'uso di asset che sono stati inseriti in precedenza nel mapping dei dati non è coerente.
Documenti di riferimento
- Configurare ed eseguire la profilatura dei dati
- Configurare ed eseguire l'analisi della qualità dei dati
- Domande frequenti e self-help
- Configurare la connessione data quality
- Informazioni sul mirroring in Fabric
- Scorciatoie di OneLake
- Data Quality per le origini dati con mirroring di Fabric
- Data Quality for OneLake shortcuts data sources (Qualità dei dati per le origini dati di OneLake)