Come usare il metastore Hive con il cluster Apache Spark™
Importante
Azure HDInsight su AKS è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight su AKS. Per domande o suggerimenti sulle funzionalità, inviare una richiesta su AskHDInsight con i dettagli e seguire noi per altri aggiornamenti su Azure HDInsight Community.
È essenziale condividere i dati e il metastore tra più servizi. Uno dei metastore comunemente usati nel contesto del metastore HIVE. HDInsight nel servizio Azure Kubernetes consente agli utenti di connettersi a un metastore esterno. Questo passaggio consente agli utenti di HDInsight di connettersi facilmente ad altri servizi nell'ecosistema.
Azure HDInsight su Azure Kubernetes Service (AKS) supporta metastore personalizzati, consigliati per i cluster di produzione. I passaggi chiave coinvolti sono
- Creare un database SQL di Azure
- Creare una cassaforte delle chiavi per la conservazione delle credenziali
- Configurare il metastore durante la creazione di un cluster HDInsight su AKS di Azure con Apache Spark™
- Operare su metastore esterno (mostra i database ed eseguire un limite di selezione 1).
Durante la creazione del cluster, il servizio HDInsight deve connettersi al metastore esterno e verificare le credenziali.
Creare un database SQL di Azure
Creare o avere un database SQL di Azure esistente prima di configurare un metastore Hive personalizzato per un cluster HDInsight.
Nota
Attualmente è supportato solo il database SQL di Azure per il metastore HIVE. A causa della limitazione di Hive, il carattere "-" (trattino) nel nome del database metastore non è supportato.
Creare un vault di chiavi per l'archiviazione delle credenziali
Creare un Azure Key Vault.
Lo scopo del Key Vault è consentire di archiviare la password dell'amministratore di SQL Server impostata al momento della creazione del database SQL. HDInsight sulla piattaforma AKS non gestisce direttamente le credenziali. Di conseguenza, è necessario archiviare le credenziali importanti in Azure Key Vault. Impara i passaggi per creare un Azure Key Vault.
Dopo la creazione di Azure Key Vault, assegnare i ruoli seguenti
Oggetto Ruolo Osservazioni Identità gestita assegnata dall'utente (lo stesso UAMI usato dal cluster HDInsight) Utente dei segreti di Key Vault Informazioni su come Assegnare un ruolo a UAMI Utente (che crea il segreto in Azure Key Vault) Amministratore del Key Vault Scopri come assegnare un ruolo all'utente. Nota
Senza questo ruolo, l'utente non può creare un segreto.
Creare un segreto
Questo passaggio consente di mantenere la password di amministratore di SQL Server come segreto in Azure Key Vault. Aggiungere la password (stessa password fornita nel database SQL per l'amministratore) nel campo "Valore" durante l'aggiunta di un segreto.
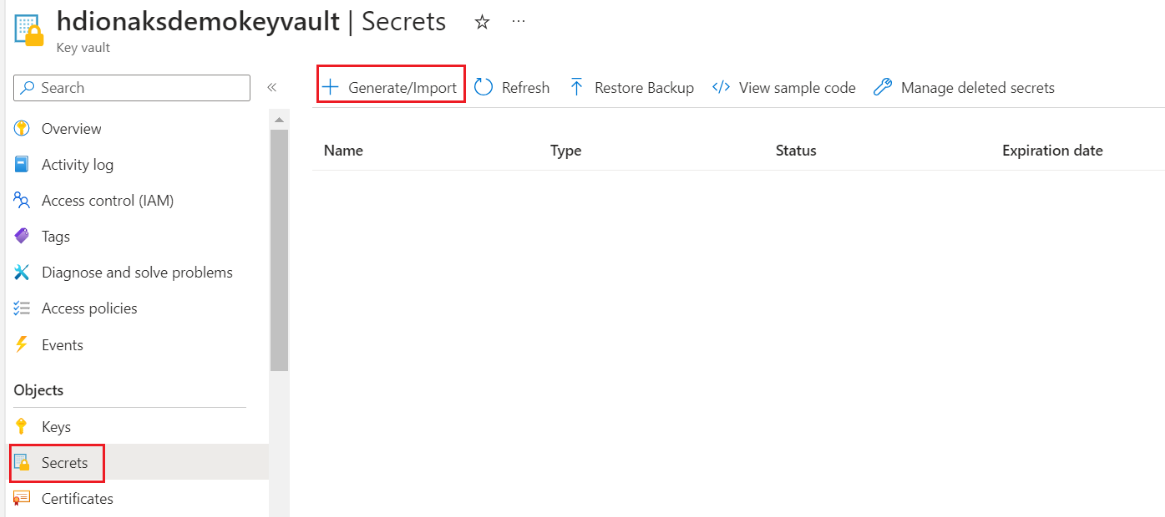
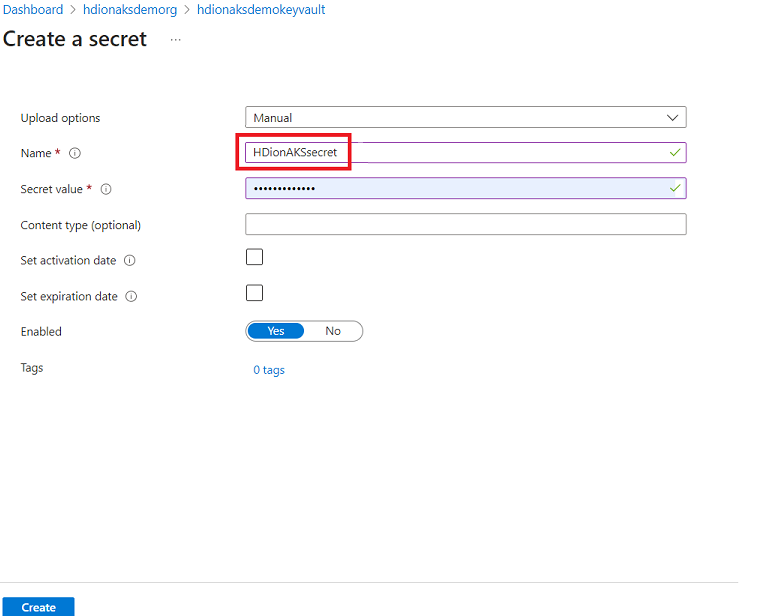
Nota
Annota il nome del segreto, perché ti servirà durante la creazione del cluster.


Configurare il metastore mentre si crea un cluster HDInsight Spark
Passare a HDInsight nell'AKS Cluster pool per creare cluster.
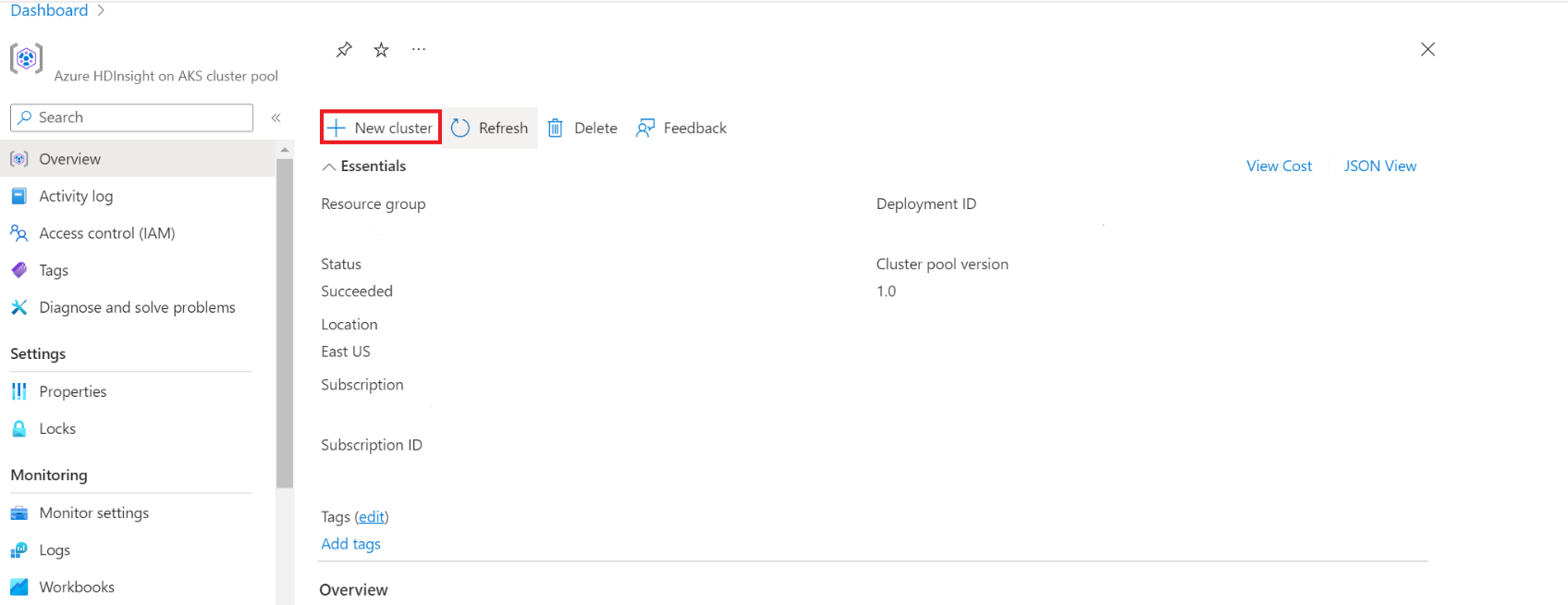
Attivare l'interruttore a levetta per aggiungere un metastore Hive esterno e compilare i dettagli seguenti.
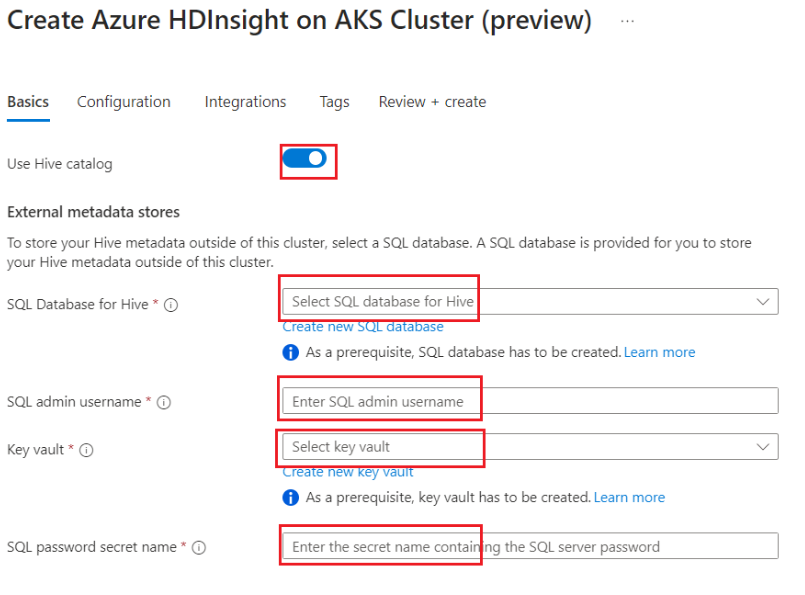
Gli altri dettagli devono essere compilati secondo le regole di creazione del cluster per il cluster Apache Spark in HDInsight nel servizio Azure Kubernetes Service.
Fai clic su Rivedi e crea.
Nota
- Il ciclo di vita del metastore non è associato a un ciclo di vita dei cluster, quindi è possibile creare ed eliminare cluster senza perdere i metadati. I metadati, ad esempio gli schemi Hive, vengono mantenuti anche dopo l'eliminazione e la ricreazione del cluster HDInsight.
- Un metastore personalizzato consente di collegare più cluster e tipi di cluster a tale metastore.



Operare su metastore esterno
Creare una tabella
>> spark.sql("CREATE TABLE sampleTable (number Int, word String)")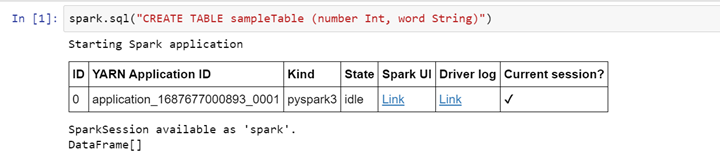
Aggiungere dati nella tabella
>> spark.sql("INSERT INTO sampleTable VALUES (123, \"HDIonAKS\")");\
Leggere la tabella
>> spark.sql("select * from sampleTable").show()



Riferimento
- Apache, Apache Spark, Spark e i nomi dei progetti open source associati sono marchi della Apache Software Foundation (ASF).