Creare un cluster Spark in HDInsight su Azure Kubernetes Service (AKS) (Anteprima)
Importante
Azure HDInsight su Azure Kubernetes Service (AKS) è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight in anteprima su AKS. Per domande o suggerimenti sulle funzionalità, inviare una richiesta su AskHDInsight con i dettagli e seguire la Azure HDInsight Community su per altri aggiornamenti.
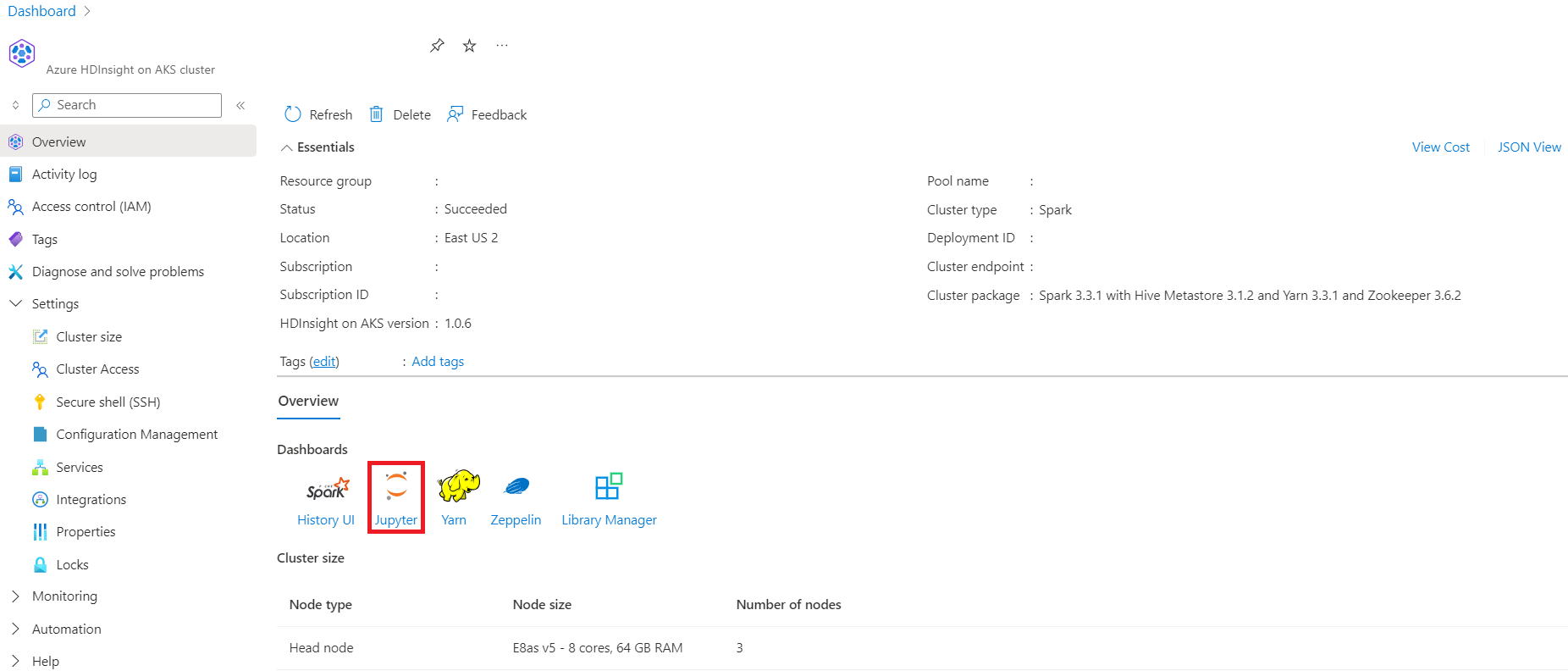
Dopo aver completato i prerequisiti della sottoscrizione e e i prerequisiti delle risorse e, e avete un pool di cluster distribuito, continua a utilizzare il portale di Azure per creare un cluster Spark. È possibile usare il portale di Azure per creare un cluster Apache Spark nel pool di cluster. È quindi possibile creare un notebook di Jupyter e usarlo per eseguire query Spark SQL sulle tabelle Apache Hive.
Nel portale di Azure, digitare "pool di cluster" e selezionarlo per accedere alla pagina dei pool di cluster. Nella pagina Pool di cluster selezionare il pool di cluster in cui è possibile aggiungere un nuovo cluster Spark.
Nella pagina del pool di cluster specifico, fare clic su + Nuovo cluster.
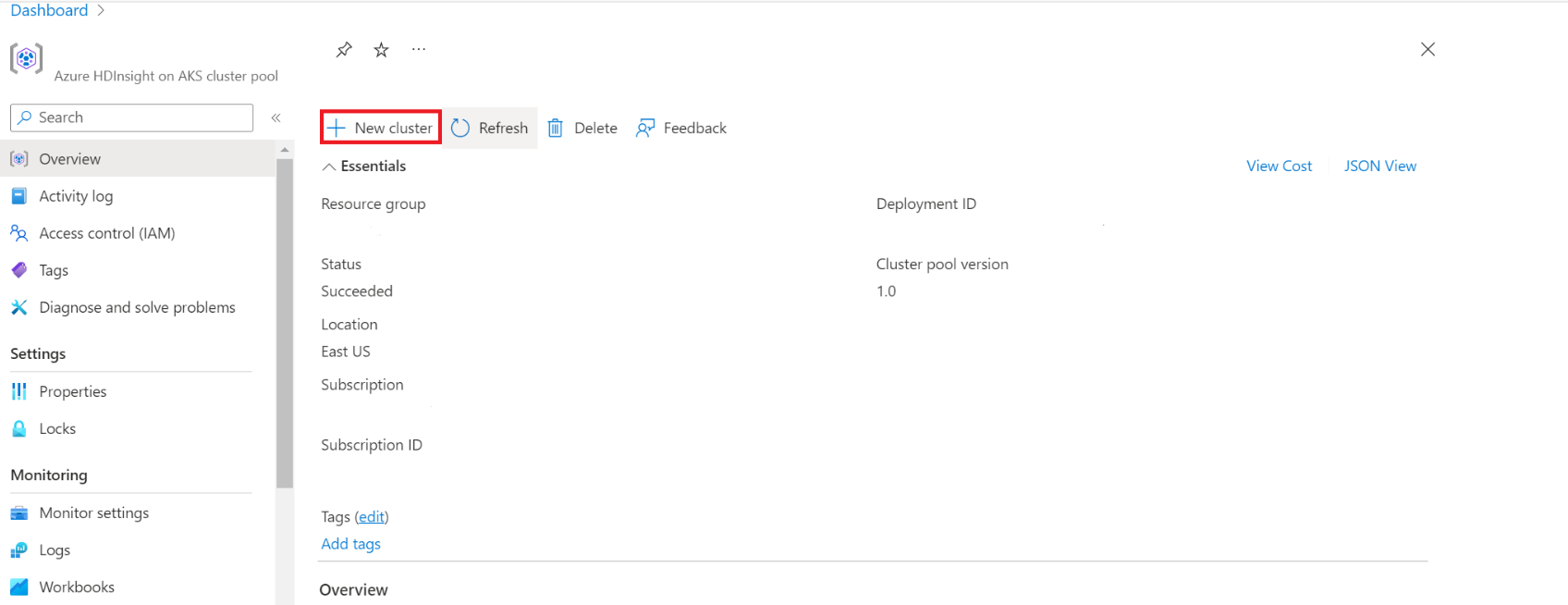
Questo passaggio apre la pagina di creazione del cluster.
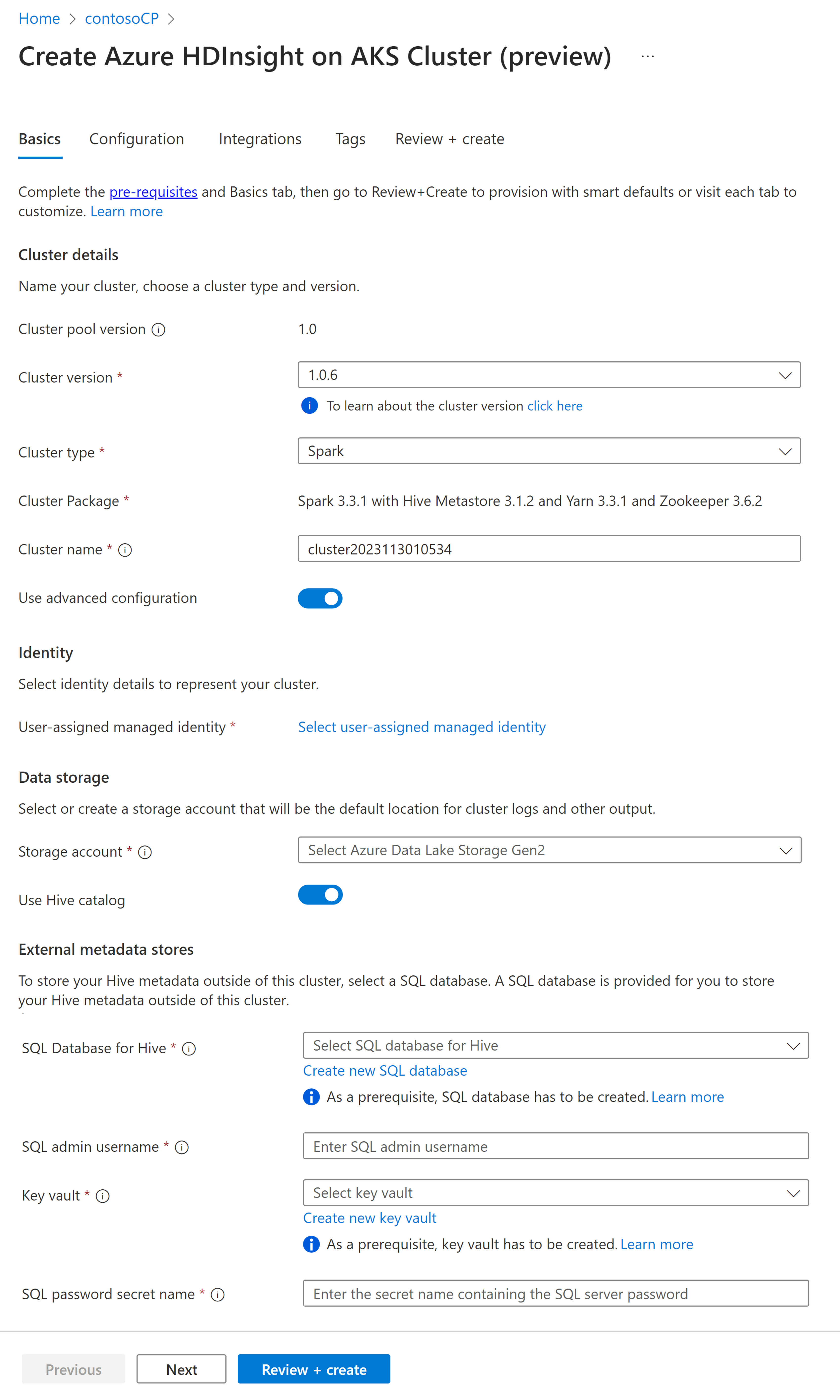
Proprietà Descrizione Abbonamento La sottoscrizione di Azure registrata per l'uso con HDInsight su AKS nella sezione Prerequisiti sarà precompilata. Gruppo di risorse Lo stesso gruppo di risorse del pool di cluster verrà popolato automaticamente Regione La stessa regione del pool di cluster e virtuale verranno prepopolate Pool di cluster Il nome del pool di cluster verrà precompilato Versione del pool HDInsight La versione del pool di cluster verrà prepopolata in base alla selezione durante la creazione del pool. HDInsight su AKS versione Specificare l'HDI nella versione di AKS Tipo di cluster Nell'elenco a discesa selezionare Spark Versione cluster Selezionare la versione dell'immagine da usare Nome del cluster Immettere il nome del nuovo cluster Identità gestita assegnata dall'utente Selezionare l'identità gestita assegnata dall'utente che funzionerà come stringa di connessione con l'archiviazione Account di archiviazione Selezionare l'account di archiviazione precedentemente creato che deve essere usato come risorsa di archiviazione primaria per il cluster Nome contenitore Selezionare il nome del contenitore (univoco) se è stato creato o creato un nuovo contenitore Catalogo Hive (facoltativo) Selezionare il metastore Hive creato in anteprima (database SQL di Azure) Database SQL per Hive Nell'elenco a discesa selezionare il database SQL in cui aggiungere tabelle hive-metastore. Nome utente amministratore SQL Immettere il nome utente dell'amministratore SQL Archivio chiavi Nell'elenco a discesa selezionare il Key Vault, che contiene una chiave segreta con la password per il nome utente dell'amministratore SQL. Nome del segreto per la password SQL Inserire il nome segreto nel Key Vault dove è memorizzata la password del database SQL Nota
- Attualmente HDInsight supporta solo i database MS SQL Server.
- A causa della limitazione di Hive, il carattere "-" (trattino) nel nome del database metastore non è supportato.
Selezionare Avanti: Configurazione + Prezzi per continuare.
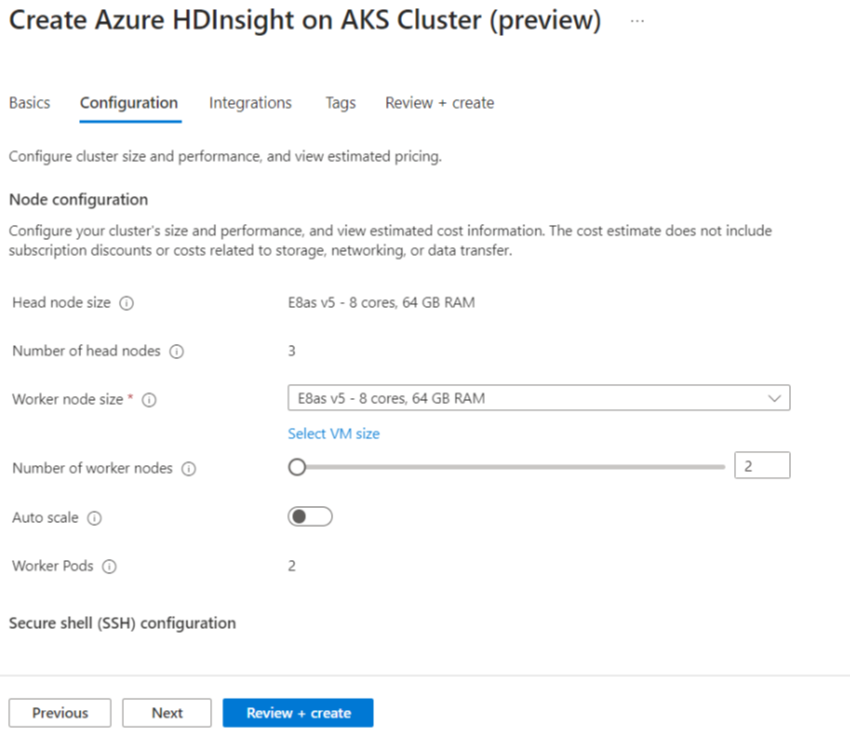
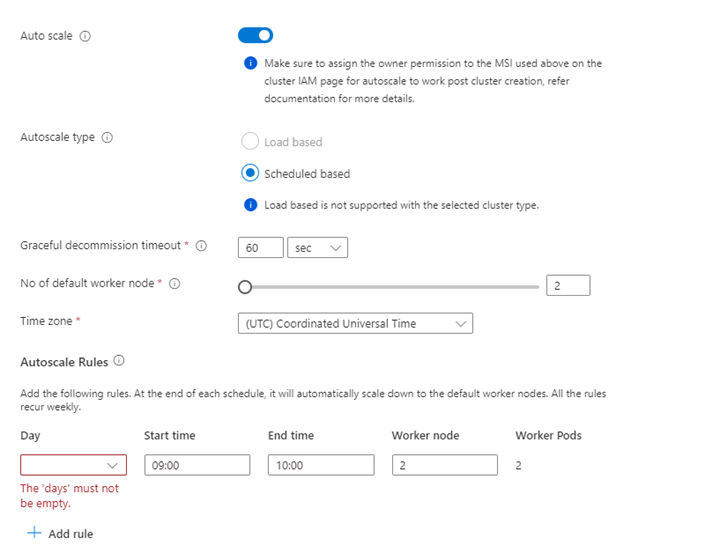
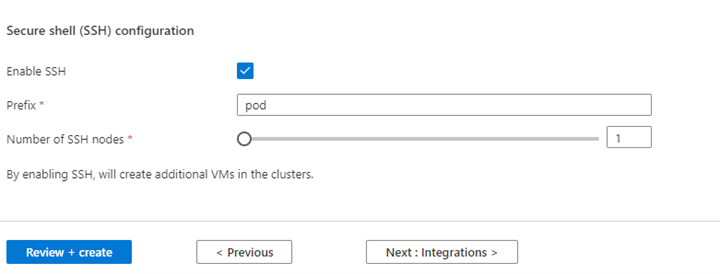
Proprietà Descrizione Dimensioni nodo Selezionare le dimensioni del nodo da usare per i nodi Spark Numero di nodi di lavoro Selezionare il numero di nodi per il cluster Spark. Al di fuori di questi, tre nodi sono riservati per il coordinatore e i servizi di sistema, mentre i nodi rimanenti sono dedicati agli worker Spark, uno per nodo. Ad esempio, in un cluster a cinque nodi sono presenti due ruoli di lavoro Scalabilità automatica Fare clic sul pulsante Attiva/Disattiva per abilitare la scalabilità automatica Tipo di scalabilità automatica Selezionare una scalabilità automatica basata sul carico o sulla pianificazione Timeout di disattivazione graduale Specificare il timeout di dismissione graduale Numero di nodi di lavoro predefiniti Selezionare il numero di nodi per la scalabilità automatica Fuso orario Selezionare il fuso orario Regole di scalabilità automatica Selezionare il giorno, l'ora di inizio, l'ora di fine, no. dei nodi di lavoro Abilitare SSH Se abilitata, consente di definire il prefisso e il numero di nodi SSH Fare clic su Avanti : Integrazioni per abilitare e selezionare Log Analytics per la registrazione.
È possibile abilitare Azure Prometheus per il monitoraggio e le metriche dopo la creazione del cluster.
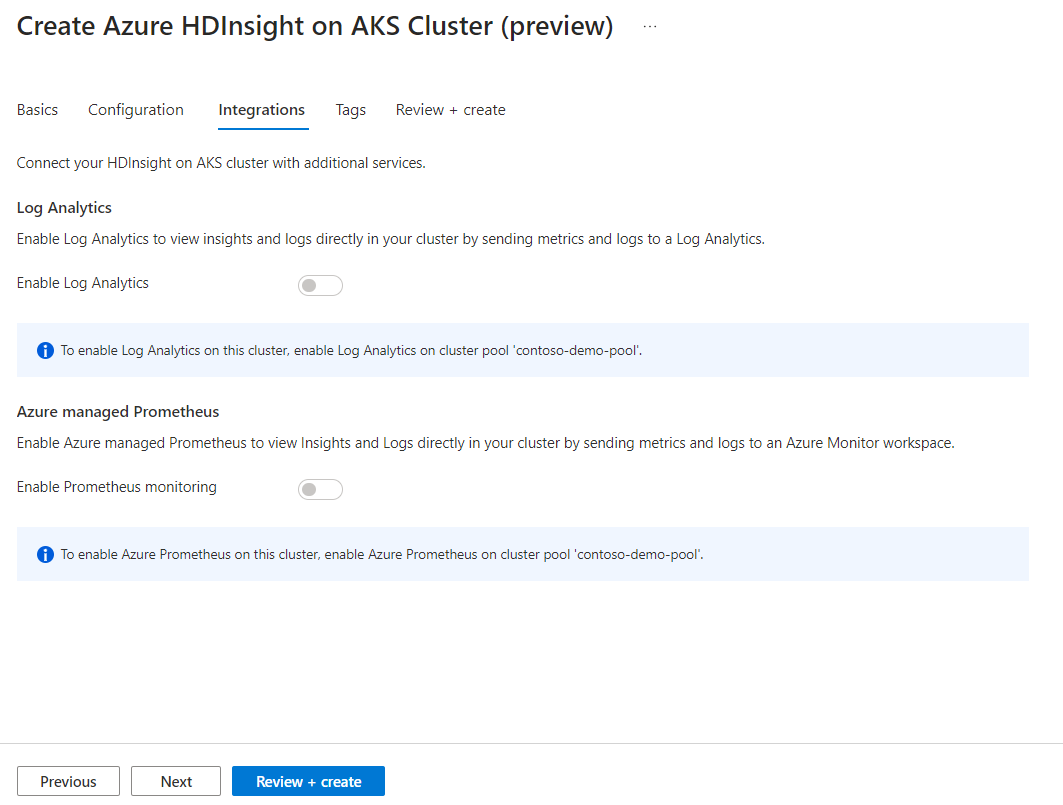
Fare clic su Avanti: tag per passare alla pagina successiva.

Nella pagina Tag, inserire qualsiasi tag si desideri aggiungere alla risorsa.
Proprietà Descrizione Nome Opzionale. Inserire un nome, come HDInsight nella Private Preview di AKS, per identificare facilmente tutte le risorse associate. Valore Lasciare vuoto questo campo Risorsa Selezionare Tutte le risorse selezionate Fare clic su Avanti: Rivedi e crea.
Nella pagina Rivedi e creacercare il messaggio Convalida riuscita nella parte superiore della pagina e quindi fare clic su Crea.
Viene visualizzata la pagina di distribuzione , in cui è in corso di creazione il cluster. La creazione del cluster richiede 5-10 minuti. Dopo aver creato il cluster, viene visualizzato La distribuzione è stata completata messaggio. Se si esce dalla pagina, è possibile controllare lo stato delle notifiche.
Vai alla pagina di panoramica del cluster , lì è possibile visualizzare i collegamenti all'endpoint.