Intelligenza artificiale con i flussi di dati
Questo articolo illustra come usare l'intelligenza artificiale con flussi di dati. L'articolo illustra:
- Servizi cognitivi
- Machine Learning automatizzato
- Integrazione con Azure Machine Learning
Importante
La creazione di modelli di Machine Learning automatizzato (AutoML) di Power BI per i flussi di dati v1 è stata ritirata e non è più disponibile. I clienti sono invitati a eseguire la migrazione della soluzione alla funzionalità AutoML in Microsoft Fabric. Per altre informazioni, vedere l'annuncio di ritiro.
Servizi cognitivi in Power BI
Con Servizi cognitivi in Power BI è possibile applicare diversi algoritmi dei Servizi cognitivi di Azure per arricchire i dati nella preparazione dei dati self-service per i flussi di dati.
I servizi attualmente supportati sono Analisi del sentiment, Estrazione frasi chiave, Rilevamento lingua e Assegnazione di tag alle immagini. Le trasformazioni vengono eseguite nel servizio Power BI e non richiedono una sottoscrizione di Servizi cognitivi di Azure. Questa funzionalità richiede Power BI Premium.
Abilitare le funzionalità di intelligenza artificiale
I servizi cognitivi sono supportati per i nodi di capacità Premium EM2, A2, P1 o F64 e altri nodi con più risorse. I servizi cognitivi sono disponibili anche con una licenza Premium per utente (PPU). Per eseguire i servizi cognitivi viene usato un carico di lavoro di Intelligenza artificiale separato nella capacità. Prima di usare i servizi cognitivi in Power BI è necessario abilitare il carico di lavoro di Intelligenza artificiale nelle impostazioni della capacità nel portale di amministrazione. È possibile attivare il carico di lavoro di intelligenza artificiale nella sezione Carichi di lavoro.
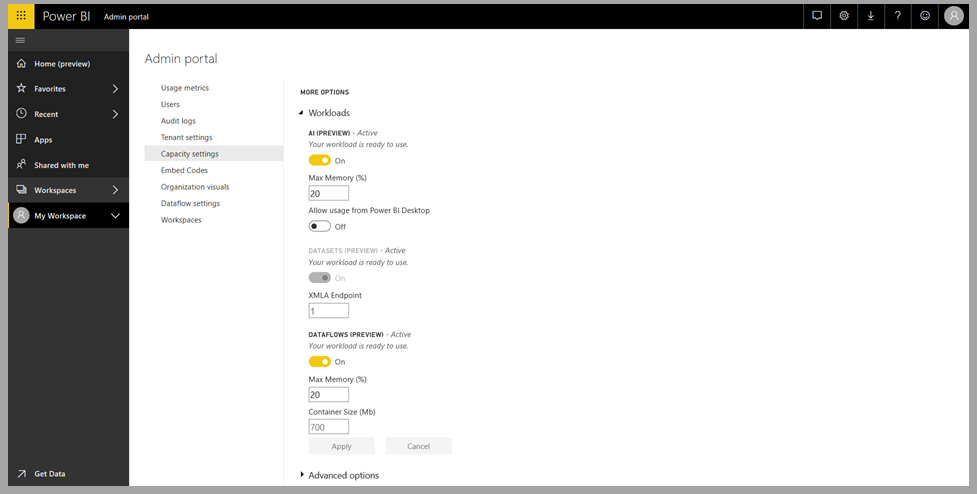
Introduzione a Servizi cognitivi in Power BI
Le trasformazioni di Servizi cognitivi fanno parte della preparazione dei dati self-service per i flussi di dati. Per arricchire i dati con Servizi cognitivi, iniziare con la modifica di un flusso di dati.
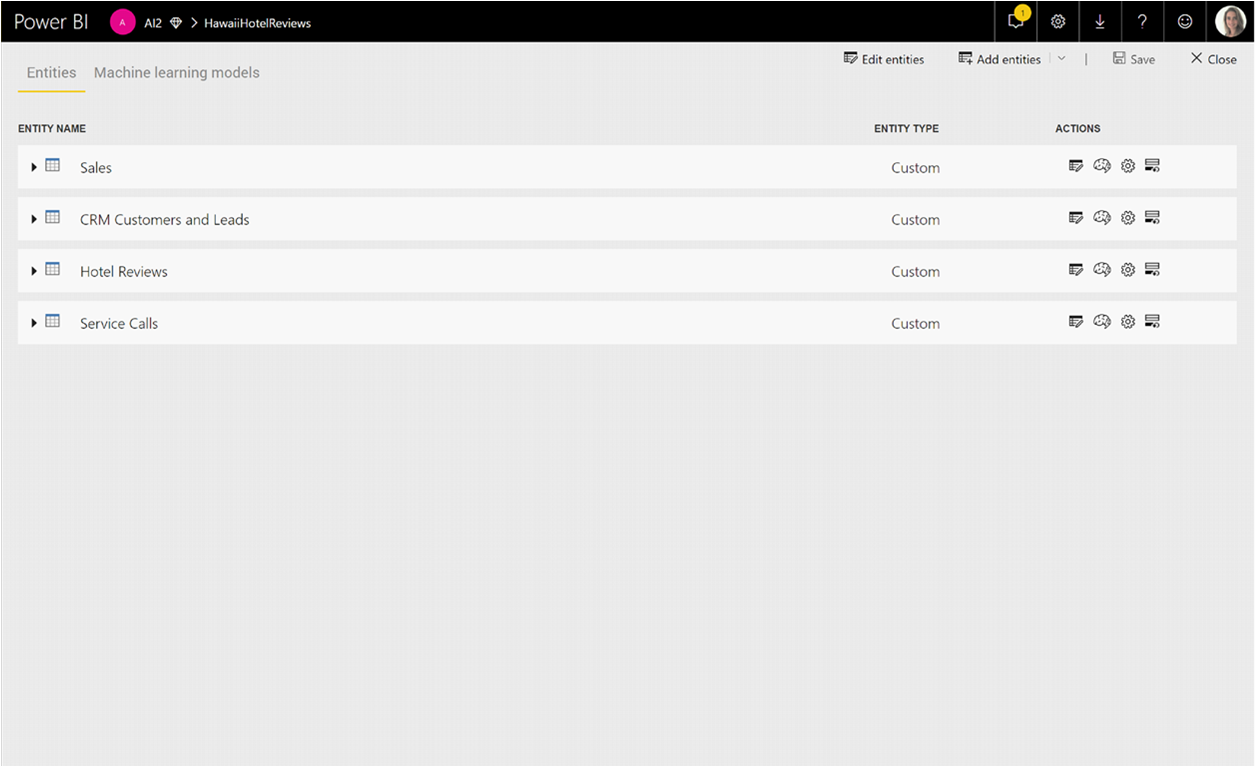
Selezionare il pulsante Informazioni dettagliate sull'intelligenza artificiale nella barra multifunzione superiore dell'editor di Power Query.
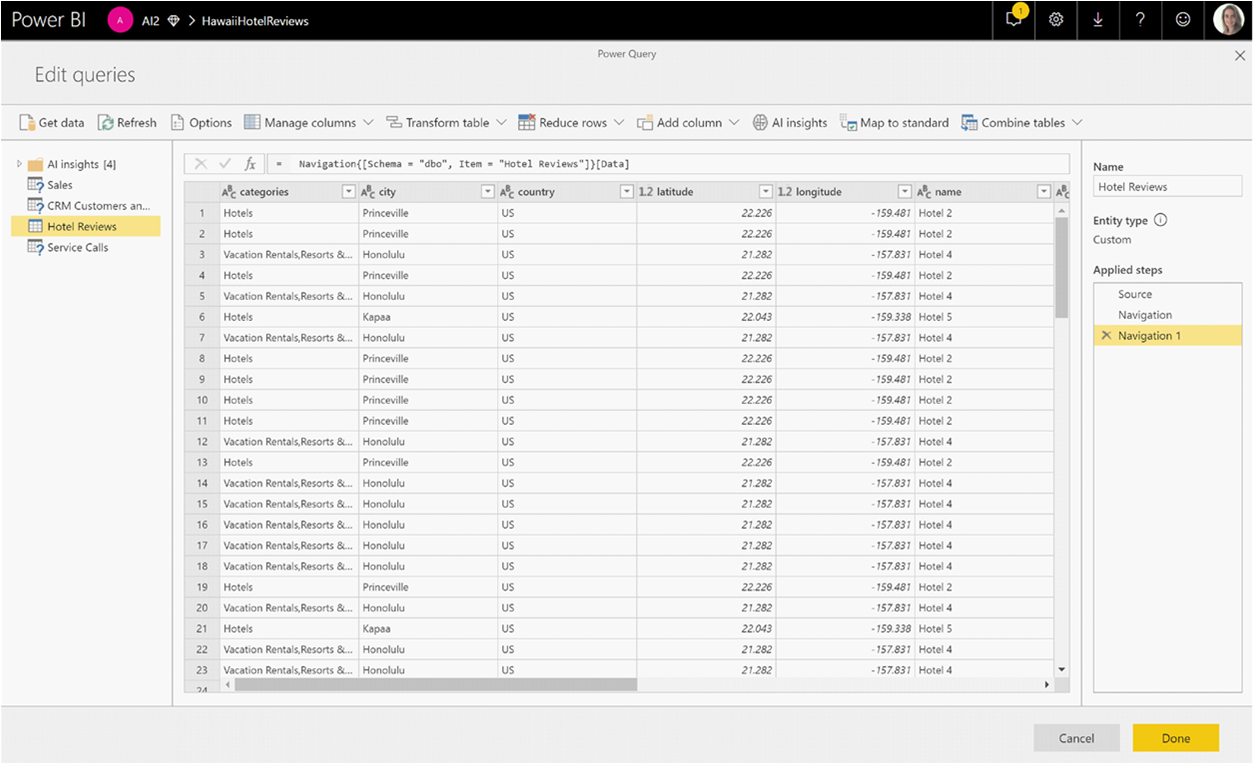
Nella finestra popup selezionare la funzione da usare e i dati da trasformare. Questo esempio assegna un punteggio al sentiment di una colonna contenente testo di revisione.
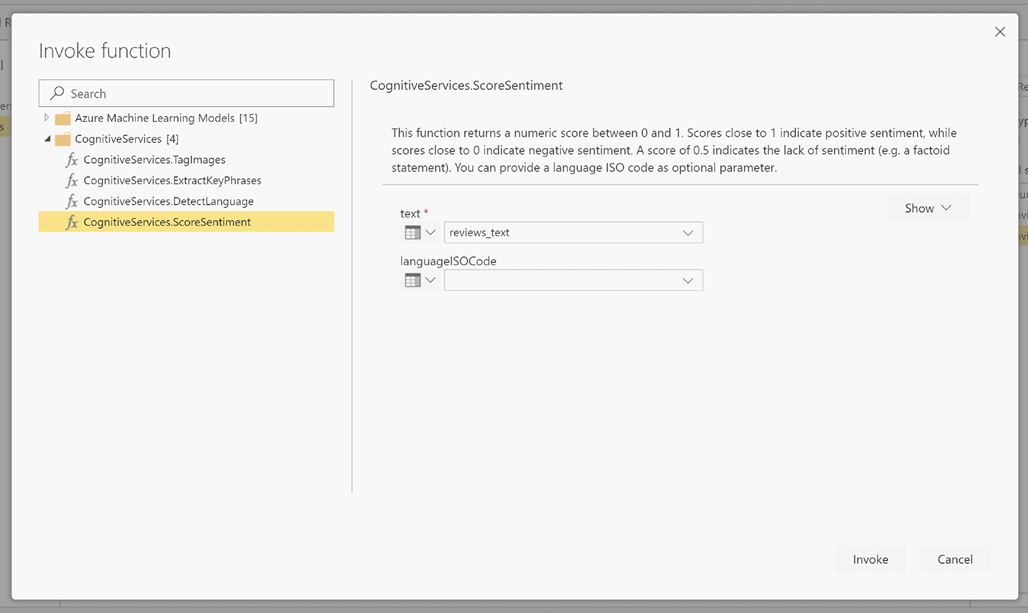
LanguageISOCode è un input facoltativo per specificare la lingua del testo. Questa colonna prevede un codice ISO. È possibile usare una colonna come input per LanguageISOCode oppure usare una colonna statica. In questo esempio la lingua scelta è l'inglese, specificato come "en" per l'intera colonna. Se si lascia vuota questa colonna, Power BI rileva automaticamente la lingua prima di applicare la funzione. Selezionare quindi Richiama.
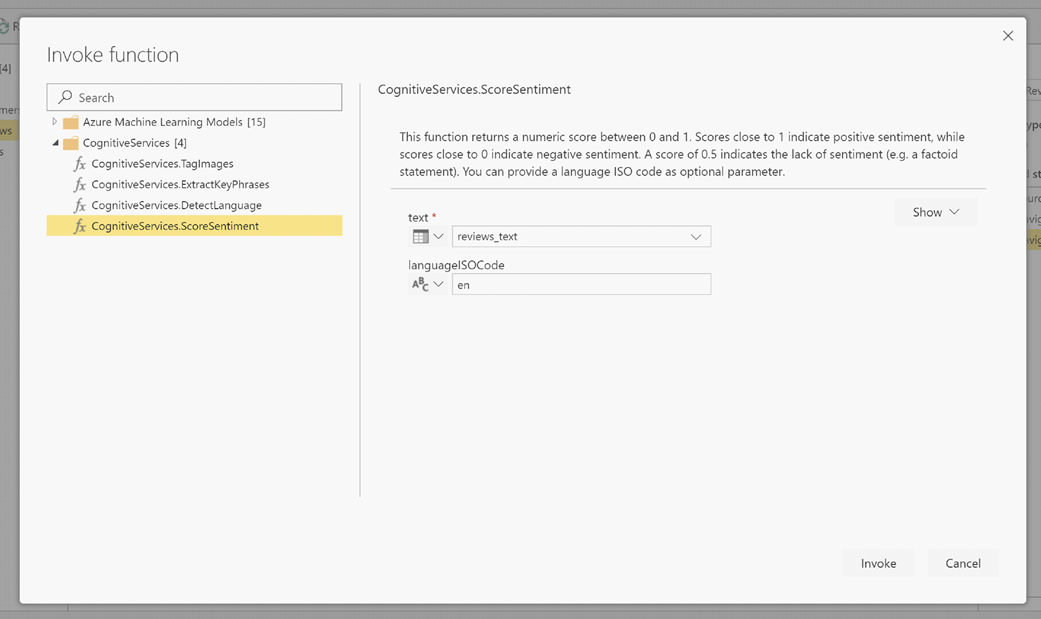
Dopo aver richiamato la funzione, il risultato viene aggiunto come nuova colonna alla tabella. Anche la trasformazione viene aggiunta come passaggio applicato nella query.
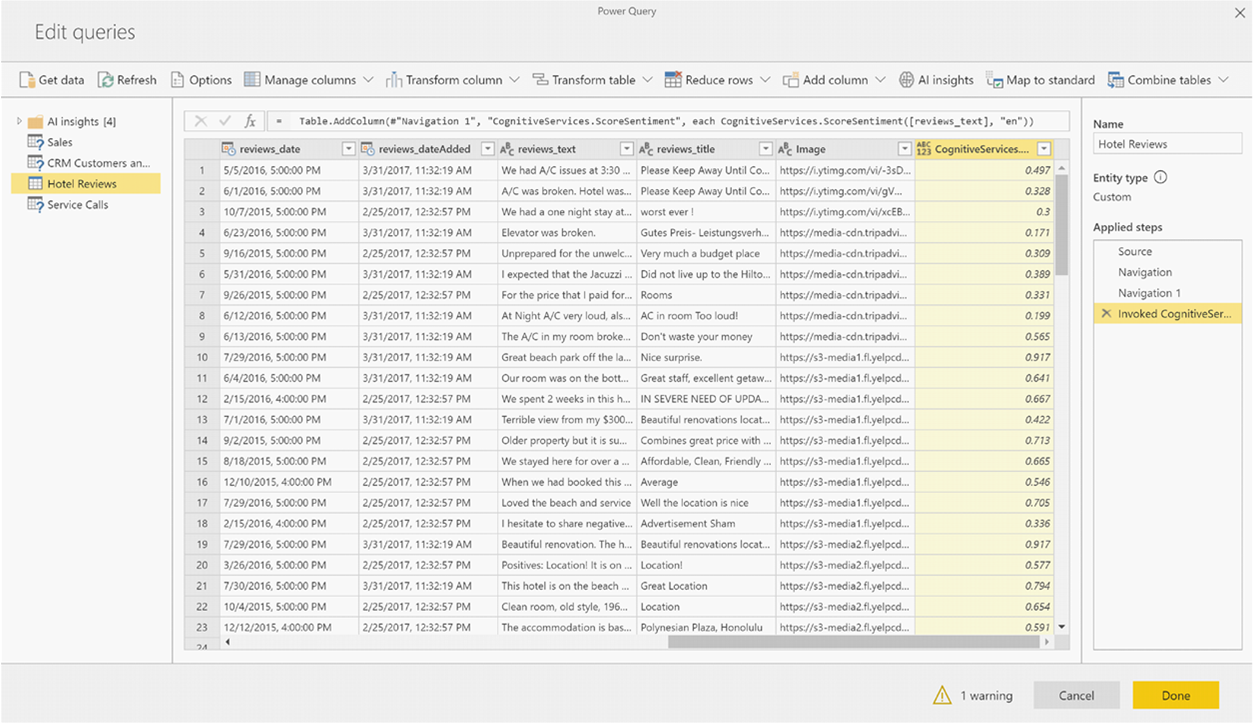
Se la funzione restituisce più colonne di output, richiamare la funzione aggiunge una nuova colonna con una riga delle più colonne di output.
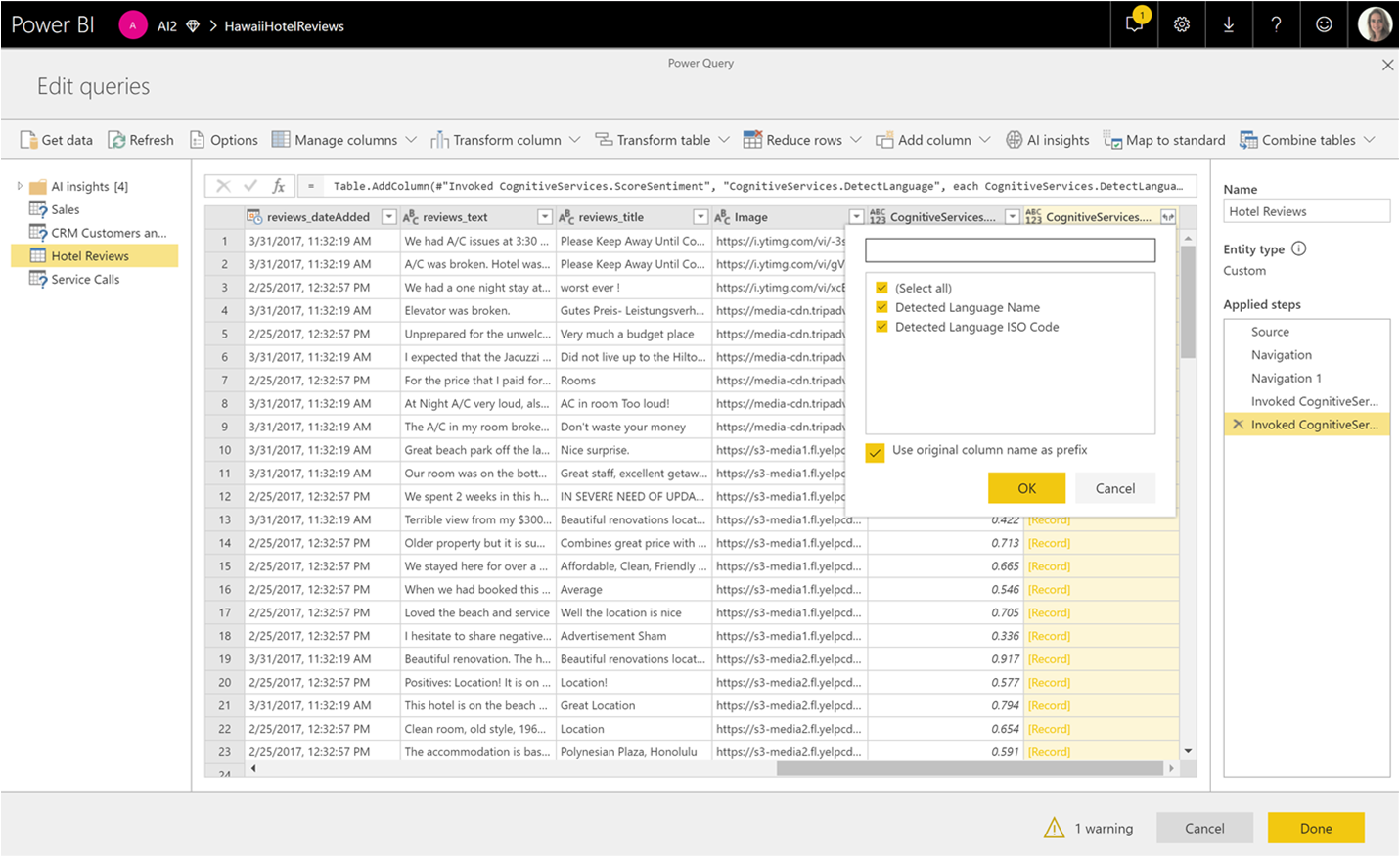
Usare l'opzione di espansione per aggiungere uno o entrambi i valori come colonne ai dati.
Funzioni disponibili
Questa sezione descrive le funzioni disponibili in Servizi cognitivi in Power BI.
Rilevare la lingua
La funzione di rilevamento della lingua valuta l'input di testo e, per ogni colonna, restituisce il nome della lingua e l'identificatore ISO. Questa funzione è utile per le colonne di dati che raccolgono testo arbitrario, la cui lingua è sconosciuta. La funzione accetta come input dati in formato testo.
Analisi del testo riconosce fino a 120 lingue. Per altre informazioni, vedere Che cos'è il rilevamento lingua in Servizio cognitivo di Azure per la lingua.
Estrazione frasi chiave
La funzione Estrazione frasi chiave valuta il testo non strutturato e, per ogni colonna di testo, restituisce un elenco di frasi chiave. La funzione richiede una colonna di testo come input e accetta un input facoltativo per LanguageISOCode. Per altre informazioni, vedere Introduzione.
L'estrazione di frasi chiave funziona meglio quando si assegnano blocchi di testo più grandi su cui lavorare, opposto dall'analisi del sentiment. L'analisi del sentiment offre prestazioni migliori in blocchi di testo più piccoli. Per ottenere risultati ottimali da entrambe le operazioni, provare a ristrutturare gli input di conseguenza.
Analisi del sentiment
La funzione Analisi del sentiment valuta l'input di testo e restituisce un punteggio del sentiment per ogni documento, compreso tra 0 (negativo) e 1 (positivo). Questa funzione è utile per rilevare il sentiment positivo e negativo in social media, recensioni dei clienti e forum di discussione.
La funzione Analisi del testo usa un algoritmo di classificazione basato sull'apprendimento automatico per generare un punteggio di sentiment compreso tra 0 e 1. I punteggi più vicini a 1 indicano un sentiment positivo. I punteggi più vicini a 0 indicano un sentiment negativo. Il modello è stato precedentemente sottoposto a training con un corpo di testo di grandi dimensioni con associazioni di sentiment. Attualmente non è possibile fornire dati di training personali. Durante l'analisi del testo il modello usa una combinazione di tecniche, tra cui l'elaborazione del testo, l'analisi di parti del discorso nonché la posizione e l'associazione delle parole. Per altre informazioni sull'algoritmo, vedere Machine Learning e Analisi del testo.
L'analisi del sentiment viene eseguita sull'intera colonna di input, anziché estrarre il sentiment per una determinata tabella nel testo. Nella pratica, la precisione nell'assegnazione del punteggio tende a essere maggiore quando i documenti contengono una o due frasi anziché un blocco di testo di grandi dimensioni. Durante una fase di valutazione dell'obiettività, il modello determina se una colonna di input nel suo insieme è obiettiva o contiene sentiment. Una colonna di input che è principalmente obiettiva non avanza fino alla frase di rilevamento del sentiment, con conseguente punteggio di 0,50, senza ulteriore elaborazione. Per le colonne di input che continuano nella pipeline, la fase successiva genera un punteggio maggiore o minore di 0,50, a seconda del grado di sentiment rilevato nella colonna di input.
La funzione Analisi del sentiment supporta attualmente le lingue inglese, tedesco, spagnolo e francese. Altre lingue sono disponibili in anteprima. Per altre informazioni, vedere Che cos'è il rilevamento lingua in Servizio cognitivo di Azure per la lingua.
Assegnazione di tag alle immagini
La funzione Assegnazione di tag alle immagini restituisce tag sulla base di più di 2.000 oggetti, esseri viventi, paesaggi e azioni riconoscibili. Quando i tag sono ambigui o non sono comunemente noti, l'output fornisce suggerimenti per chiarire il significato del tag nel contesto di un'ambientazione nota. I tag non sono organizzati come tassonomia e non esistono gerarchie di ereditarietà. Una raccolta di tag di contenuto costituisce la base per la descrizione di un'immagine visualizzata come linguaggio leggibile dall'utente e formattata in frasi complete.
Dopo il caricamento di un'immagine o la definizione di un URL di immagine, gli algoritmi di Visione artificiale generano tag in base agli oggetti, alle azioni e agli esseri umani identificati nell'immagine. L'assegnazione di tag non è limitata al soggetto principale, ad esempio una persona in primo piano, ma include anche scenari (interni o esterni), arredamenti, strumenti, piante, animali, accessori, gadget e così via.
Questa funzione richiede un URL immagine o una colonna abase-64 come input. Attualmente la funzione di assegnazione di tag alle immagini supporta le lingue seguenti: inglese, spagnolo, giapponese, portoghese e cinese semplificato. Per altre informazioni, vedere Interfaccia ComputerVision.
Machine Learning automatizzato in Power BI
Machine Learning automatizzato (AutoML) per i flussi di dati consente agli analisti aziendali di eseguire il training, convalidare e richiamare i modelli di Machine Learning (ML) direttamente in Power BI. Include un'esperienza semplice per la creazione di un nuovo modello di ML in cui gli analisti possono usare i propri flussi di dati per specificare i dati di input per il training del modello. Il servizio estrae automaticamente le caratteristiche più rilevanti, seleziona un algoritmo appropriato e ottimizza e convalida il modello di ML. Dopo aver eseguito il training di un modello, Power BI genera automaticamente un report prestazioni che include i risultati della convalida. Il modello può quindi essere richiamato per tutti i dati nuovi o aggiornati all'interno del flusso di dati.
Machine Learning automatizzato (AutoML) è disponibile per i flussi di data ospitati solo in Power BI Premium e nelle capacità incorporate.
Usare AutoML
L'apprendimento automatico e l'IA stanno vedendo un aumento senza precedenti della popolarità dei settori e dei campi di ricerca scientifica. Le aziende cercano anche modi per integrare queste nuove tecnologie nelle loro operazioni.
I flussi di dati offrono la preparazione dei dati self-service per i Big Data. AutoML è integrato nei flussi di dati e consente di usare le attività di preparazione dei dati per la creazione di modelli di Machine Learning, direttamente all'interno di Power BI.
AutoML in Power BI consente agli analisti di dati di usare i flussi di dati per creare modelli di Machine Learning con un'esperienza semplificata, usando solo competenze di Power BI. Power BI automatizza la maggior parte della data science alla base della creazione dei modelli di Machine Learning. Sono disponibili controlli che assicurano la buona qualità del modello prodotto e la visibilità sul processo usato per creare il modello di ML.
AutoML supporta la creazione di modelli di previsione per dati binari, classificazione e regressione per i flussi di dati. Queste funzionalità sono tipi di tecniche di Machine Learning con supervisione, ovvero l'apprendimento si basa sui risultati noti delle osservazioni precedenti al fine di stimare i risultati di altre osservazioni. Il modello semantico di input per il training di un modello AutoML è un set di righe etichettate con i risultati noti.
AutoML in Power BI integra la funzionalità Machine Learning automatizzato da Azure Machine Learning per creare i modelli di Machine Learning. Tuttavia, non è necessaria una sottoscrizione di Azure per usare AutoML in Power BI. Il servizio Power BI gestisce interamente il processo di training e l'hosting dei modelli di Machine Learning.
Dopo aver eseguito il training di un modello di Machine Learning, AutoML genera automaticamente un report di Power BI in cui vengono spiegate le prestazioni probabili del modello di Machine Learning. AutoML rende più comprensibile la spiegazione evidenziando i fattori di influenza chiave tra gli input che influenzano le stime restituite dal modello. Il report include anche le metriche chiave per il modello.
Altre pagine del report generato contengono un riepilogo statistico del modello e i dettagli del training. Il riepilogo statistico è di particolare interesse per gli utenti che vogliono visualizzare le misure di data science standard delle prestazioni del modello. I dettagli del training riepilogano tutte le iterazioni eseguite per creare il modello, con i parametri di modellazione associati. Viene inoltre descritto il modo in cui è stato usato ogni input per creare il modello di Machine Learning.
È quindi possibile applicare il modello di Machine Learning ai dati per l'assegnazione dei punteggi. Quando si aggiorna il flusso di dati, i dati vengono aggiornati con le stime del modello di ML. Power BI include anche una spiegazione specifica per ogni stima prodotta dal modello di Machine Learning.
Creare un modello di Machine Learning
Questa sezione descrive la procedura di creazione di un modello AutoML.
Preparazione dei dati per la creazione di un modello di Machine Learning
Per creare un modello di Machine Learning in Power BI, è necessario prima creare un flusso di dati per i dati contenenti le informazioni relative ai risultati cronologici, da usare per il training del modello di Machine Learning. È inoltre necessario aggiungere colonne calcolate per eventuali metriche aziendali che possono essere elementi predittivi solidi del risultato che si sta tentando di prevedere. Per informazioni dettagliate sulla configurazione dei flussi di dati, vedere Configurare e usare un flusso di dati.
AutoML presenta requisiti specifici in termini di dati per eseguire il training di un modello di Machine Learning. Questi requisiti sono descritti nelle sezioni seguenti, in base ai rispettivi tipi di modello.
Configurare gli input del modello di Machine Learning
Per creare un modello AutoML, selezionare l'icona ML nella colonna Azioni dell'entità del flusso di dati e selezionare Aggiungi un modello di Machine Learning.
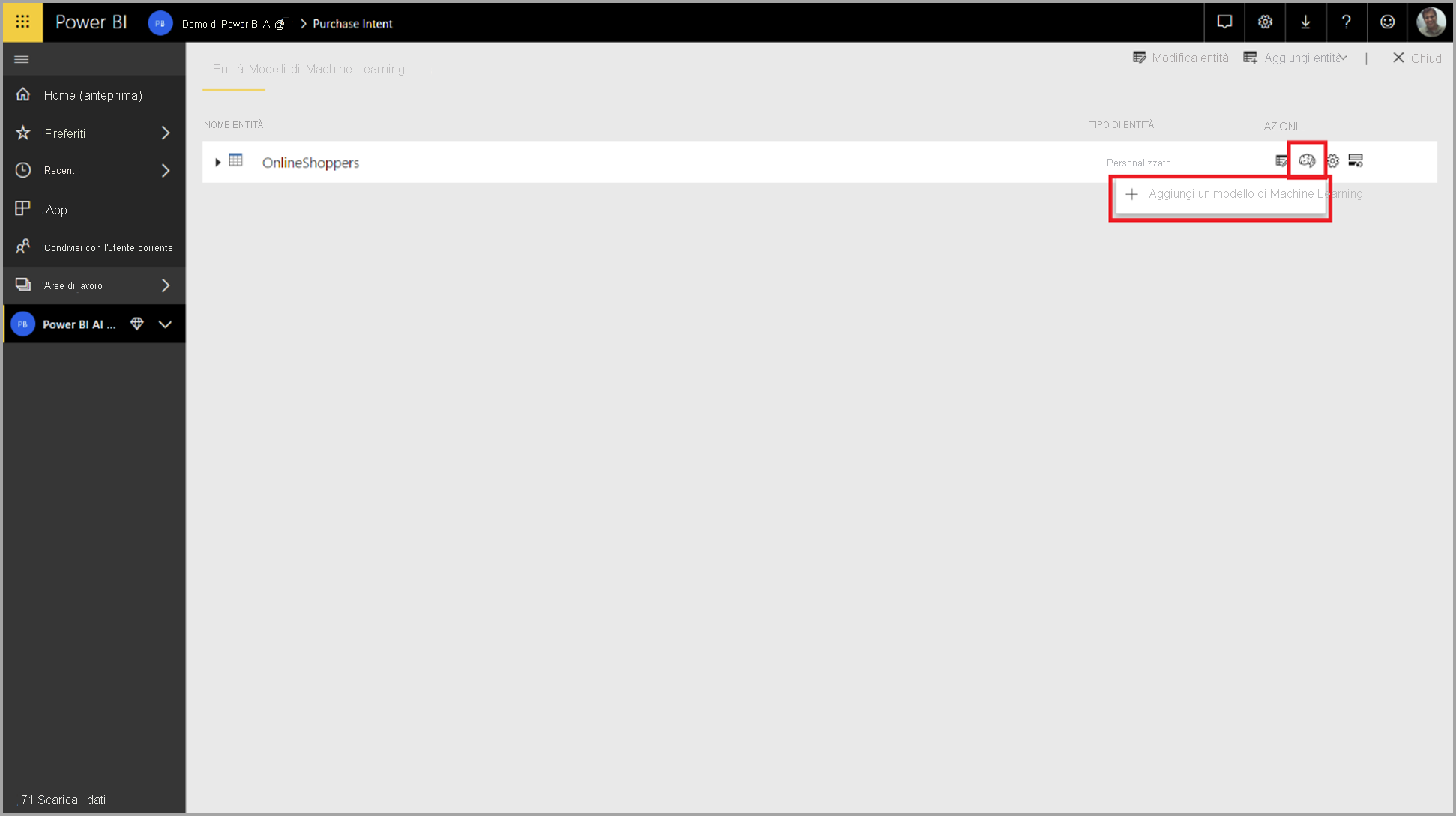
Viene avviata un'esperienza semplificata, costituita da una procedura guidata che illustra il processo di creazione del modello di Machine Learning. La procedura guidata include i semplici passaggi riportati di seguito.
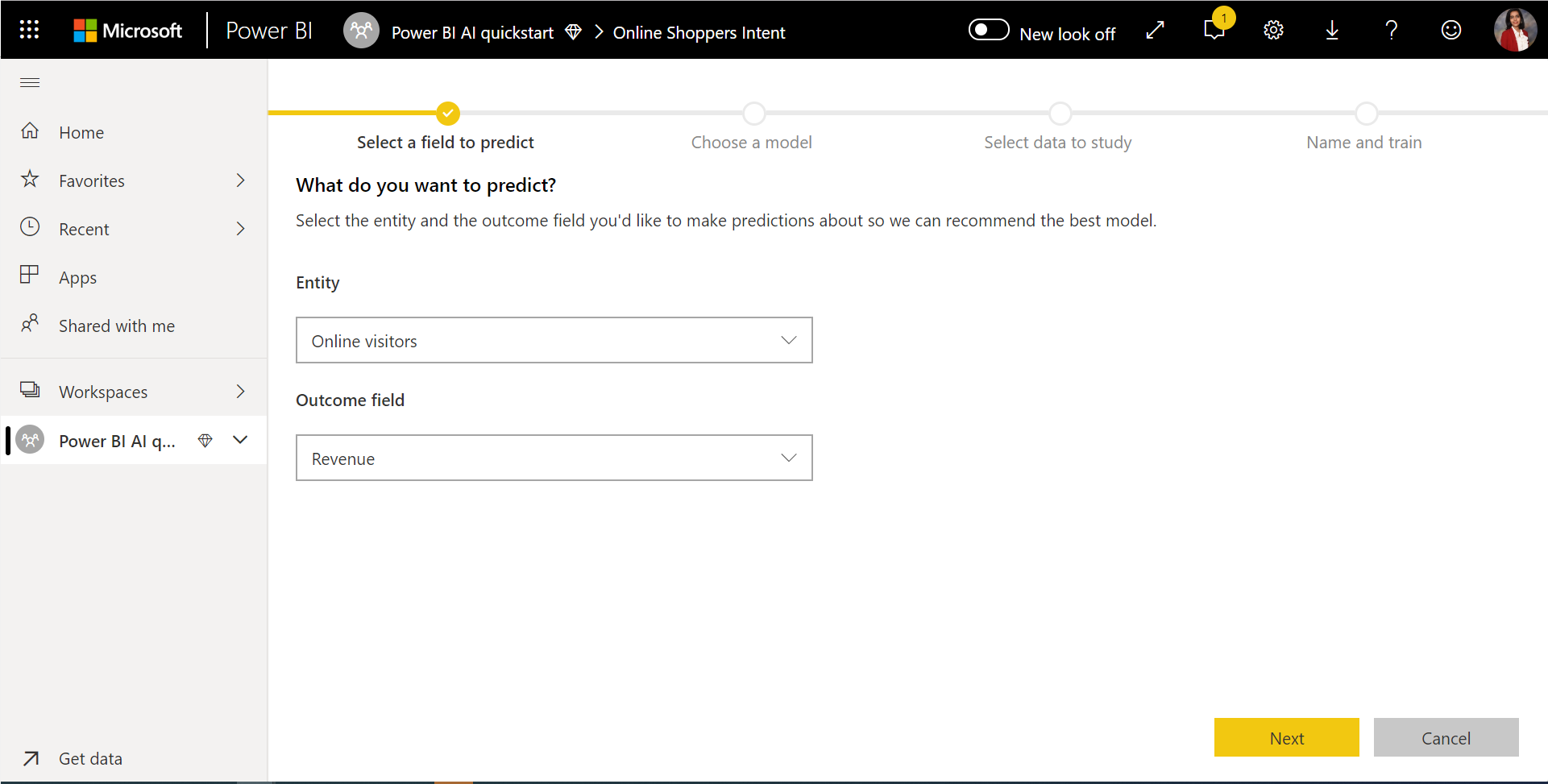
1. Selezionare la tabella con i dati cronologici e scegliere la colonna del risultato per la quale si vuole ottenere una stima
La colonna del risultato identifica l'attributo label per il training del modello di Machine Learning, illustrato nell'immagine seguente.
2. Scegliere un tipo di modello
Quando si specifica il campo del risultato, AutoML analizza i dati dell'etichetta per consigliare il tipo di modello di ML più adatto per il training. È possibile selezionare un tipo di modello diverso, come illustrato nell'immagine seguente facendo clic su Scegli un modello.
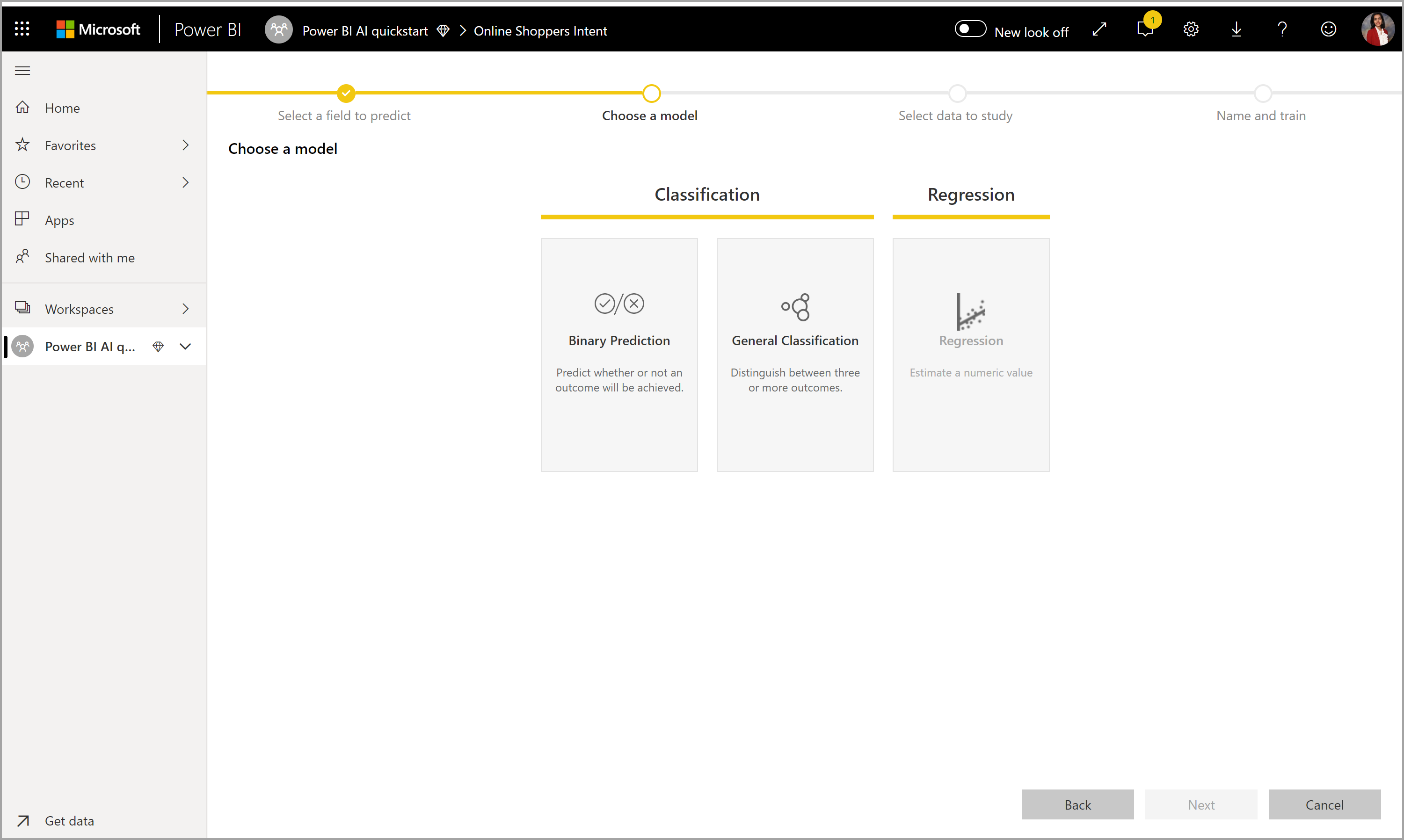
Nota
Alcuni tipi di modello potrebbero non essere supportati per i dati selezionati e quindi verranno disabilitati. Nell'esempio precedente la regressione è disabilitata perché una colonna di testo è selezionata come colonna risultato.
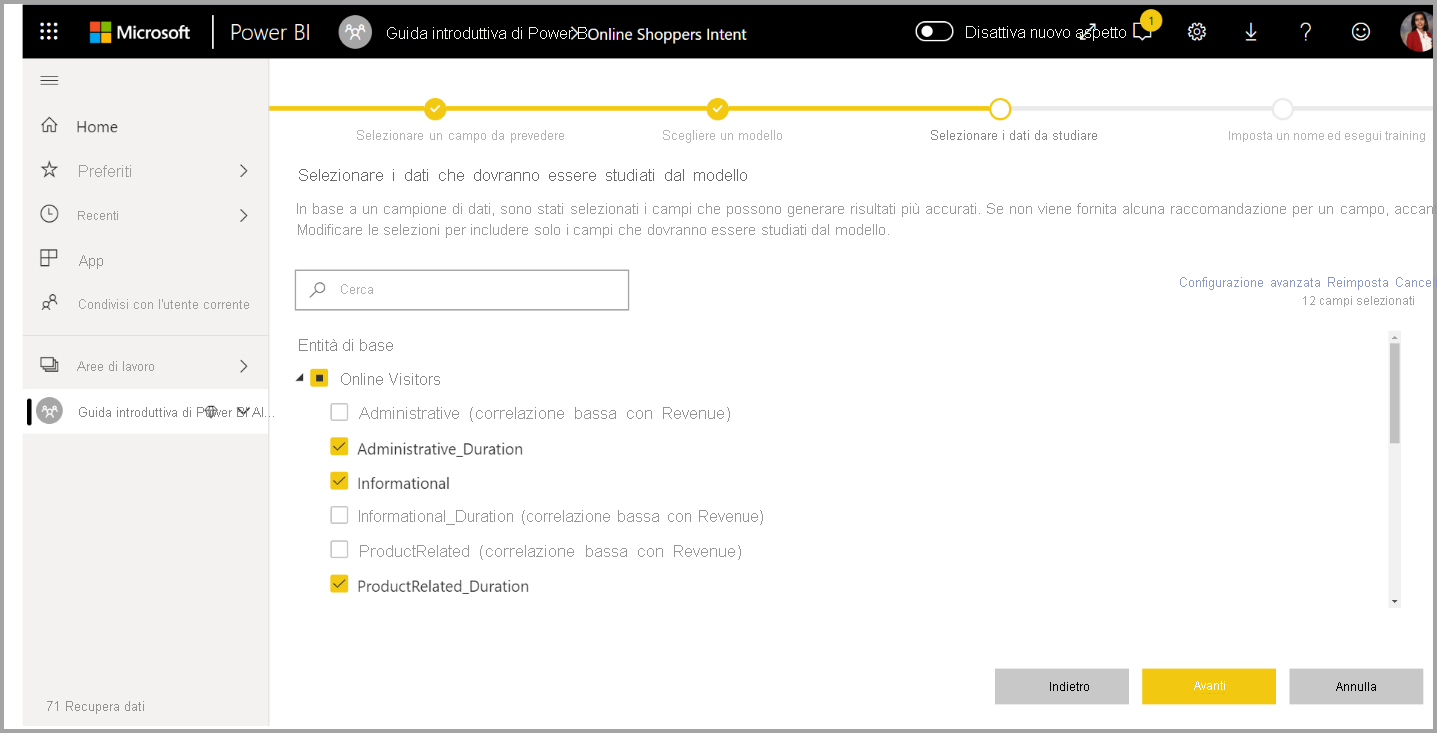
3. Selezionare gli input che il modello dovrà usare come segnali predittivi
AutoML analizza un campione della tabella selezionata per suggerire gli input che possono essere usati per il training del modello di Machine Learning. Accanto alle colonne non selezionate vengono fornite spiegazioni. Se una colonna specifica contiene troppi valori distinti o un solo valore o una correlazione bassa o elevata con la colonna di output, non è consigliabile.
Gli input dipendenti dalla colonna del risultato (o dalla colonna etichetta) non devono essere usati per il training del modello di Machine Learning, in quanto influiscono sulle prestazioni. Tali colonne vengono contrassegnate come "correlazione sospettosamente elevata con la colonna di output". L'introduzione di queste colonne nei dati di training causa la perdita di etichette, per cui il modello offre prestazioni ottimali rispetto ai dati di convalida o di test, ma non riesce a uguagliare tali prestazioni quando viene usato nell'ambiente di produzione per l'assegnazione dei punteggi. La perdita di etichette può costituire un possibile problema nei modelli AutoML, quando le prestazioni del modello di training sono troppo positive per essere vere.
La raccomandazione di questa caratteristica è basata su un campione di dati, pertanto è necessario esaminare gli input usati. È possibile modificare le selezioni in modo da includere solo le colonne che si vuole studiare dal modello. È anche possibile selezionare tutte le colonne selezionando la casella di controllo accanto al nome della tabella.
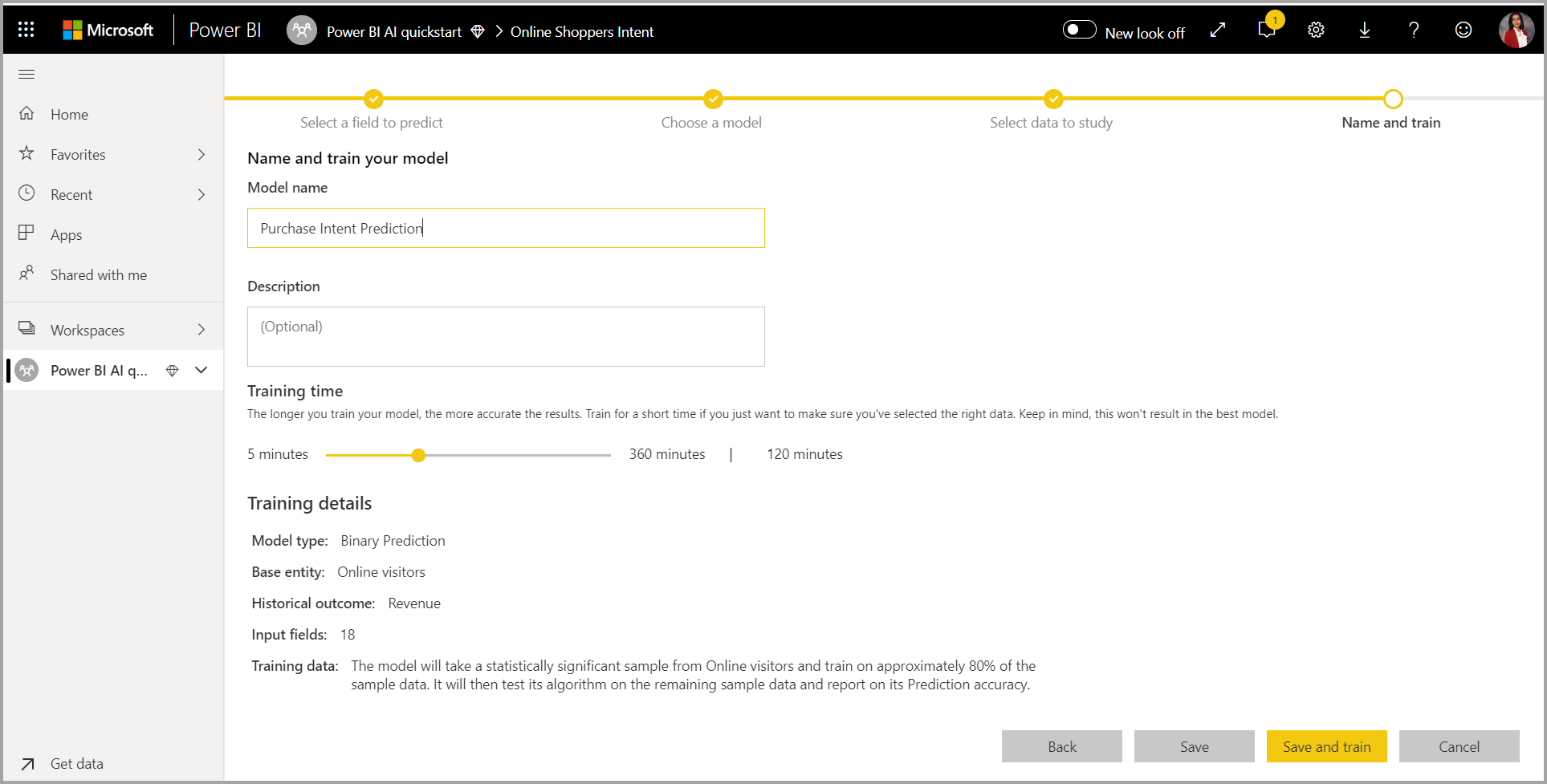
4. Assegnare un nome al modello e salvare la configurazione
Nel passaggio finale è possibile denominare il modello, selezionare Salva e scegliere quale inizia il training del modello di Machine Learning. È possibile scegliere di ridurre il tempo di training per visualizzare risultati rapidi o aumentare la quantità di tempo impiegato per il training per ottenere il modello migliore.
Training del modello di Machine Learning
Il training dei modelli AutoML fa parte dell'aggiornamento del flusso di dati. AutoML prima prepara i dati per il training. AutoML suddivide i dati cronologici forniti in modelli semantici di training e test. Il modello semantico di test è un set di controllo usato per convalidare le prestazioni del modello dopo il training. Questi set vengono realizzati come tabelle di training e test nel flusso di dati. AutoML usa la convalida incrociata per convalidare il modello.
Ogni colonna di input viene quindi analizzata e viene applicata l'imputazione, che sostituisce eventuali valori mancanti con valori sostituiti. AutoML usa due strategie di imputazione diverse. Per gli attributi di input trattati come caratteristiche numeriche, per l'imputazione viene usata la media dei valori della colonna. Per gli attributi di input trattati come caratteristiche categoriche, per l'imputazione AutoML usa la modalità dei valori della colonna. Il framework AutoML calcola la media e la modalità dei valori usati per l'imputazione nel modello semantico di training sottocampionato.
Vengono quindi applicati ai dati i campionamenti e le normalizzazioni in base alle esigenze. Per i modelli di classificazione, AutoML esegue i dati di input tramite il campionamento stratificato e bilancia le classi per garantire che i conteggi delle righe siano uguali per tutti.
AutoML applica diverse trasformazioni in ogni colonna di input selezionata in base al tipo di dati e alle proprietà statistiche. AutoML usa queste trasformazioni per estrarre le funzionalità da usare per il training del modello di Machine Learning.
Il processo di training per i modelli AutoML è costituito da un massimo di 50 iterazioni con algoritmi di modellazione e impostazioni di iperparametri diversi per trovare il modello con le migliori prestazioni. Il training può terminare in anticipo con meno iterazioni se AutoML rileva che non è stato osservato alcun miglioramento delle prestazioni. AutoML valuta le prestazioni di ognuno di questi modelli convalidandolo con il modello semantico di test di controllo. Durante questo passaggio del training, AutoML crea diverse pipeline per il training e la convalida di queste iterazioni. Il processo di valutazione delle prestazioni dei modelli può richiedere tempo, da diversi minuti a un paio di ore, fino al tempo di training configurato nella procedura guidata. Il tempo impiegato dipende dalle dimensioni del modello semantico e dalle risorse di capacità disponibili.
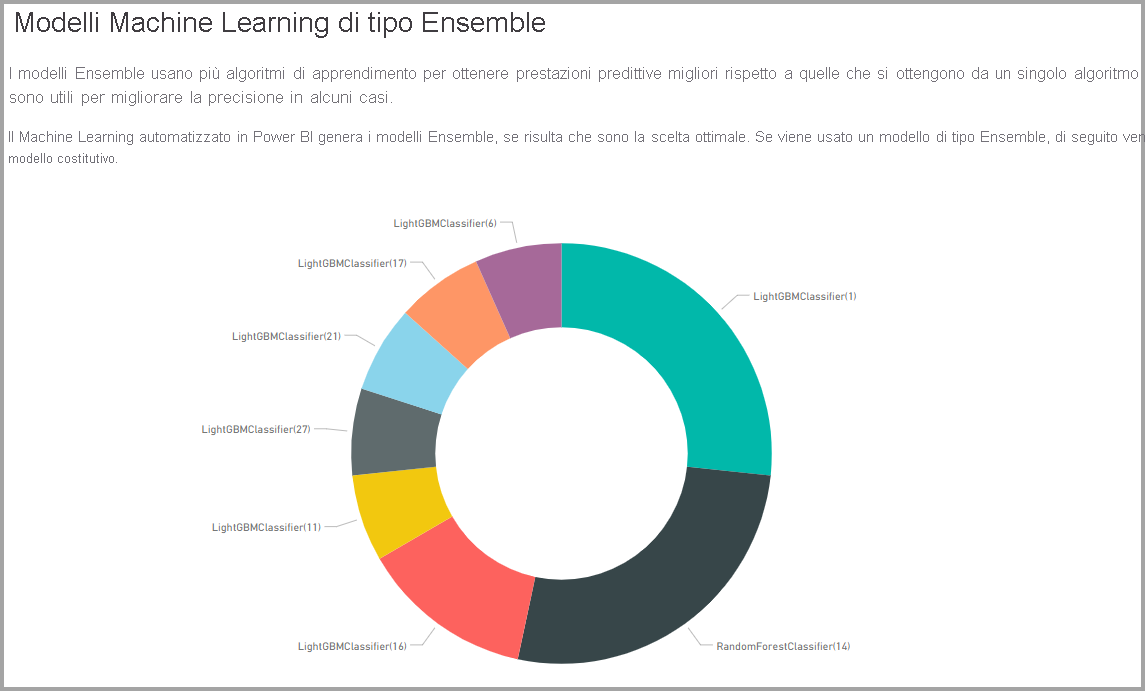
In alcuni casi il modello finale generato può usare l'apprendimento di tipo ensemble, in cui vengono usati più modelli per ottimizzare le prestazioni predittive.
Spiegazione del modello AutoML
Dopo aver eseguito il training del modello, AutoML analizza la relazione tra le funzionalità di input e l'output del modello. Valuta la grandezza della modifica all'output del modello per il modello semantico di test di controllo per ogni funzionalità di input. Questa relazione è nota come importanza della caratteristica. Questa analisi viene eseguita come parte dell'aggiornamento al termine del training. Di conseguenza, l'aggiornamento potrebbe richiedere più tempo rispetto al tempo di training configurato nella procedura guidata.
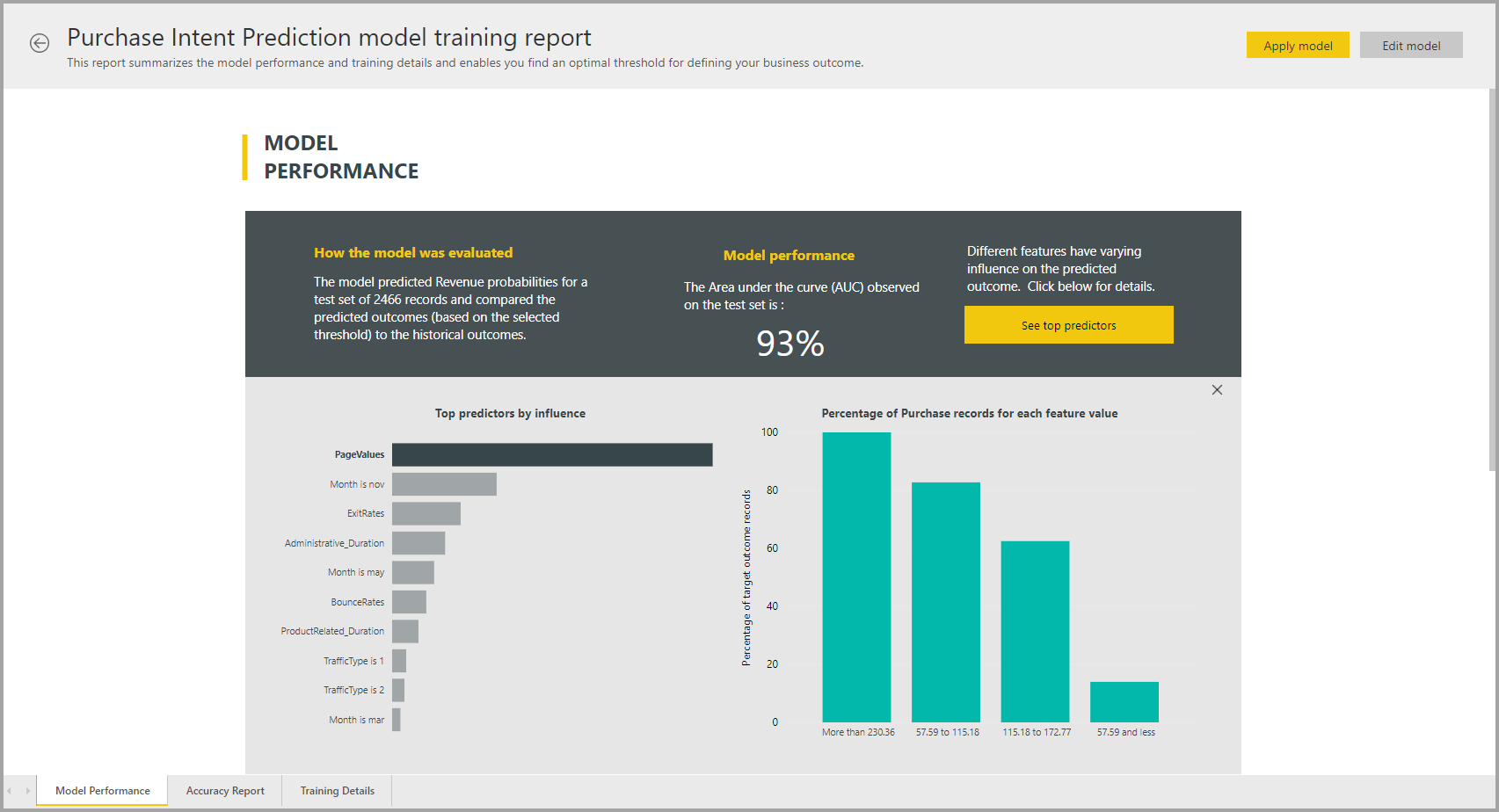
Report sul modello AutoML
AutoML genera un report di Power BI che contiene un riepilogo delle prestazioni del modello durante la convalida e indica la priorità della funzionalità globale. È possibile accedere a questo report dalla scheda Modelli di Machine Learning dopo l'aggiornamento del flusso di dati. Il report riepiloga i risultati dell'applicazione del modello di Machine Learning ai dati del test dei dati di controllo e del confronto tra le previsioni e i valori dei risultati noti.
È possibile esaminare il report sul modello per comprenderne le prestazioni. È anche possibile verificare che i fattori di influenza chiave del modello siano allineati con le informazioni aziendali dettagliate sui risultati noti.
I grafici e le misure usati per descrivere le prestazioni del modello nel rapporto dipendono dal tipo di modello. I grafici e le misure delle prestazioni sono descritti nelle sezioni seguenti.
Altre pagine del report possono descrivere misure statistiche sul modello dal punto di vista di data science. Ad esempio, il report sulla previsione per dati binari include un grafico del guadagno e la curva ROC per il modello.
I report includono inoltre una pagina dei dettagli del training che contiene una descrizione del modo in cui è stato eseguito il training del modello e un grafico che descrive le prestazioni del modello per ogni esecuzione di iterazione.
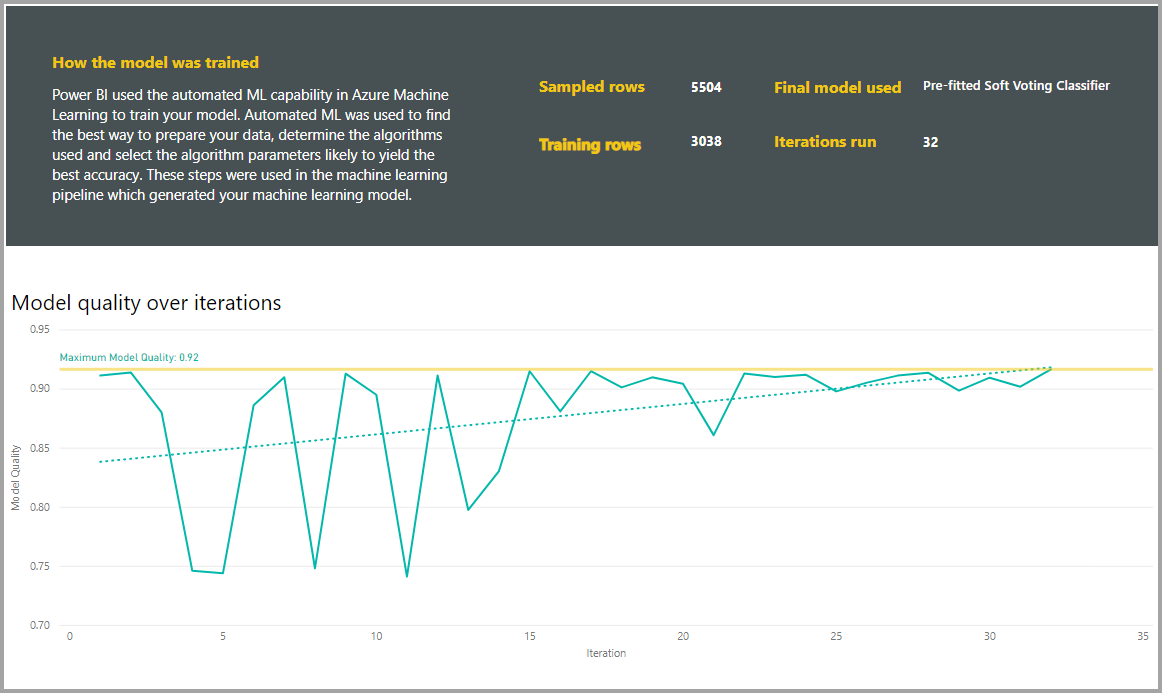
In un'altra sezione di questa pagina viene descritto il tipo rilevato della colonna di input e il metodo di imputazione usato per compilare i valori mancanti. Sono inclusi inoltre i parametri usati dal modello finale.
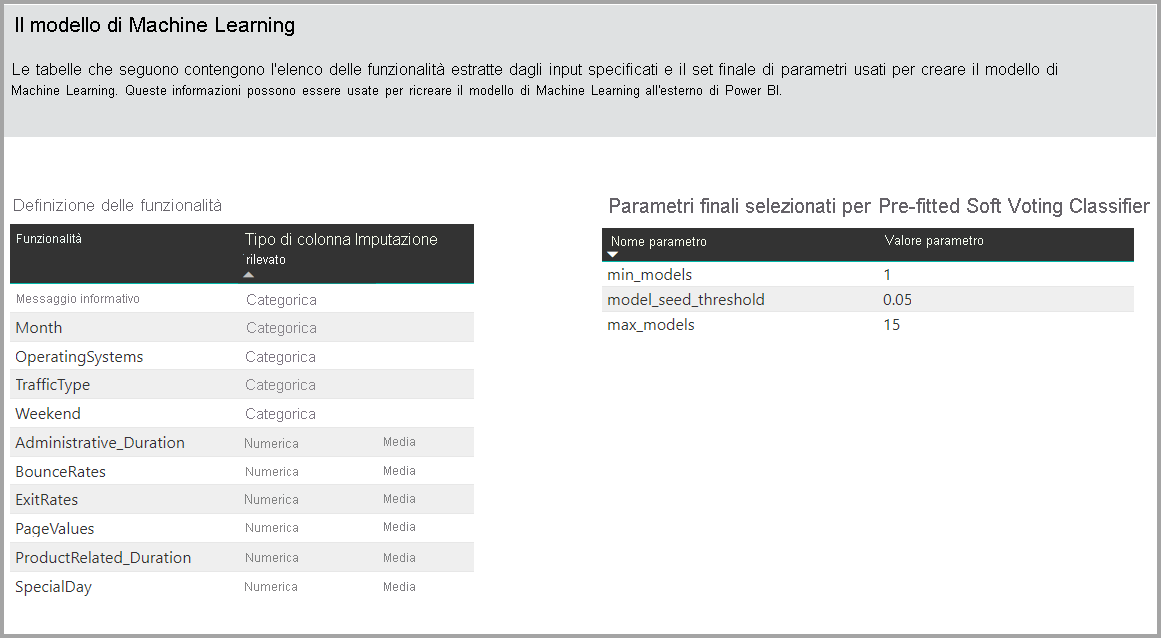
Se il modello prodotto usa l'apprendimento di tipo ensemble, la pagina Dettagli del training include anche un grafico che mostra il peso di ogni modello costituente dell'ensemble, nonché i relativi parametri.
Applicare il modello AutoML
Se si è soddisfatti delle prestazioni del modello di Machine Learning creato, è possibile applicarlo ai dati nuovi o aggiornati quando si aggiorna il flusso di dati. Nel report del modello selezionare il pulsante Applica nell'angolo superiore destro o il pulsante Applica modello di Machine Learning sotto azioni nella scheda Modelli di Machine Learning.
Per applicare il modello di Machine Learning, è necessario specificare il nome della tabella a cui deve essere applicato e un prefisso per le colonne che verranno aggiunte a questa tabella per l'output del modello. Il prefisso predefinito per i nomi delle colonne è il nome del modello. La funzione Applica può includere più parametri specifici del tipo di modello.
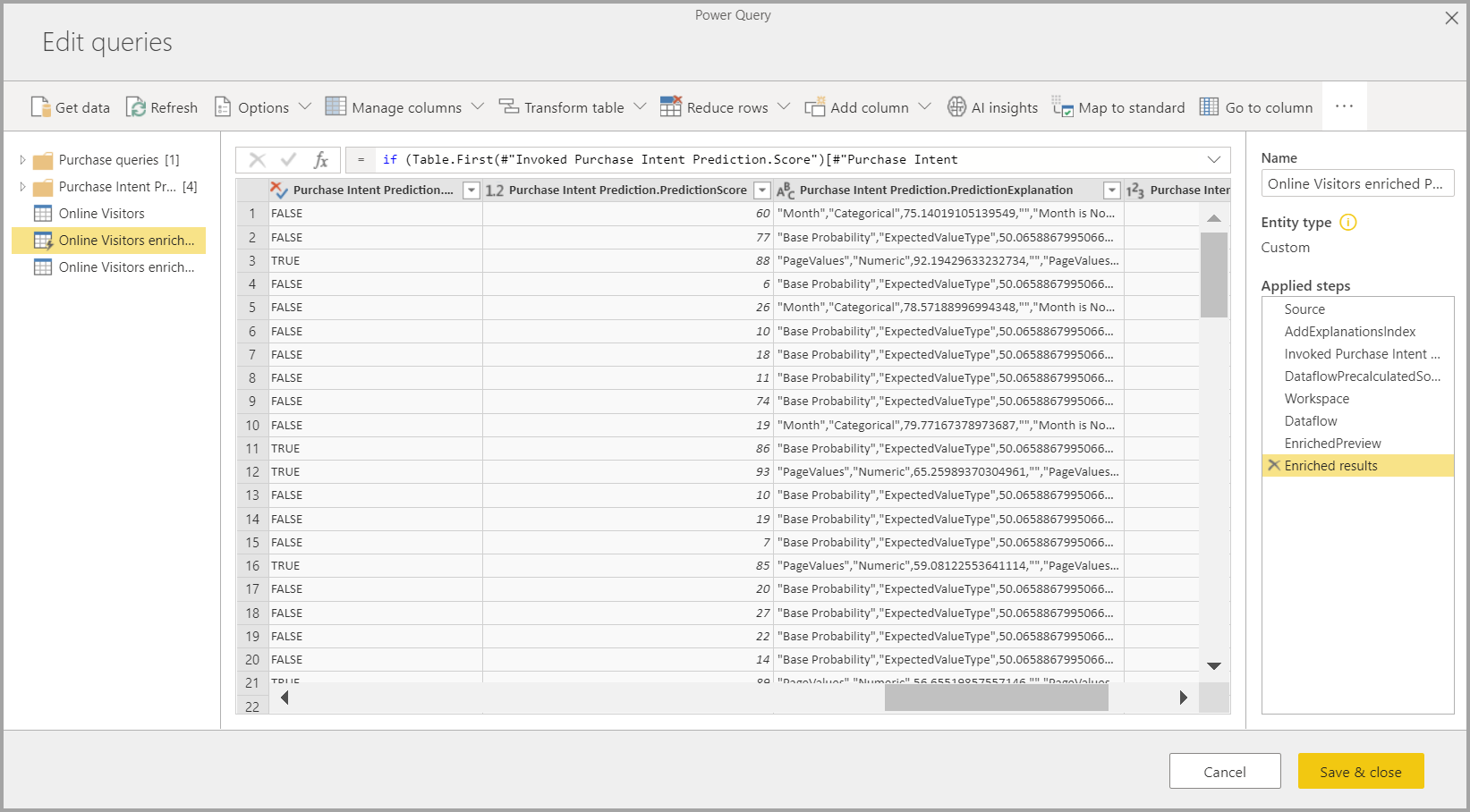
L'applicazione del modello di Machine Learning crea due nuove tabelle del flusso di dati che contengono le stime e le spiegazioni individualizzate per ogni riga che assegna punteggi alla tabella di output. Ad esempio, se si applica il modello PurchaseIntent alla tabella OnlineShoppers, l'output genera le tabelle di spiegazioni OnlineShoppers enriched PurchaseIntent e OnlineShoppers enriched PurchaseIntent explanations. Per ogni riga della tabella arricchita, le spiegazioni vengono suddivise in più righe nella tabella delle spiegazioni arricchite in base alla funzionalità di input. Un elemento ExplanationIndex consente di eseguire il mapping delle righe della tabella delle spiegazioni arricchite alla riga nella tabella arricchita.
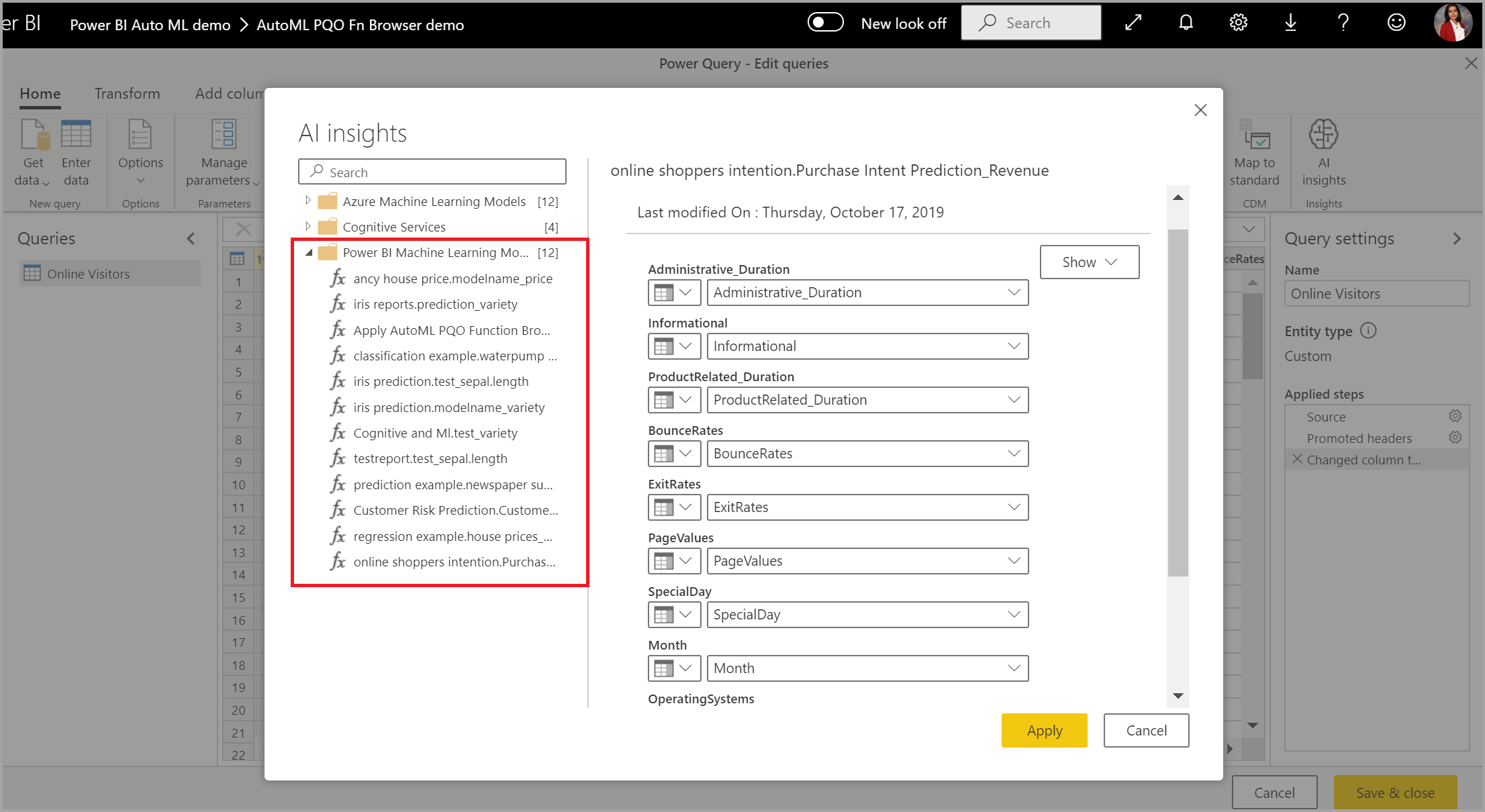
È anche possibile applicare qualsiasi modello AutoML di Power BI alle tabelle in qualsiasi flusso di dati nella stessa area di lavoro usando Informazioni dettagliate sull'intelligenza artificiale nel browser delle funzioni PQO. In questo modo è possibile usare i modelli creati da altri utenti nella stessa area di lavoro senza essere necessariamente proprietari del flusso di lavoro che possiede il modello. Power Query individua tutti i modelli di Machine Learning di Power BI nell'area di lavoro e li espone come funzioni di Power Query dinamiche. L'utente può quindi richiamare queste funzioni accedendovi dalla barra multifunzione dell'editor di Power Query o richiamando direttamente la funzione M. Questa funzionalità è attualmente supportata solo per i flussi di dati di Power BI e per Power Query Online nel servizio Power BI. Questo processo è diverso dall'applicazione di modelli di Machine Learning all'interno di un flusso di dati tramite la procedura guidata AutoML. Non esiste alcuna tabella di spiegazioni creata usando questo metodo. A meno che non si sia il proprietario del flusso di dati, non è possibile accedere ai report di training del modello o ripetere il training del modello. Inoltre, se il modello di origine viene modificato aggiungendo o rimuovendo colonne di input o il modello o il flusso di dati di origine viene eliminato, questo flusso di dati dipendente verrà interrotto.
Dopo che è stato applicato il modello, AutoML fa in modo che le stime siano sempre aggiornate ogni volta che viene aggiornato il flusso di dati.
Per usare le informazioni dettagliate e le stime del modello di Machine Learning in un report di Power BI, è possibile connettersi alla tabella di output da Power BI Desktop usando il connettore flussi di dati.
Modelli di previsione per dati binari
I modelli di stima binaria, più formalmente noti come modelli di classificazione binaria, vengono usati per classificare un modello semantico in due gruppi. Consentono di stimare gli eventi che possono avere un risultato binario, ad esempio se un'opportunità di vendita verrà convertita, se un account passa a un'altra azienda, se una fattura verrà pagata in tempo, se una transazione è fraudolenta e così via.
L'output di un modello di previsione per dati binari è un punteggio di probabilità, che identifica la probabilità che venga ottenuto il risultato di destinazione.
Eseguire il training di un modello di stima binaria
Prerequisiti:
- Sono necessarie almeno 20 righe di dati cronologici per ogni classe di risultati
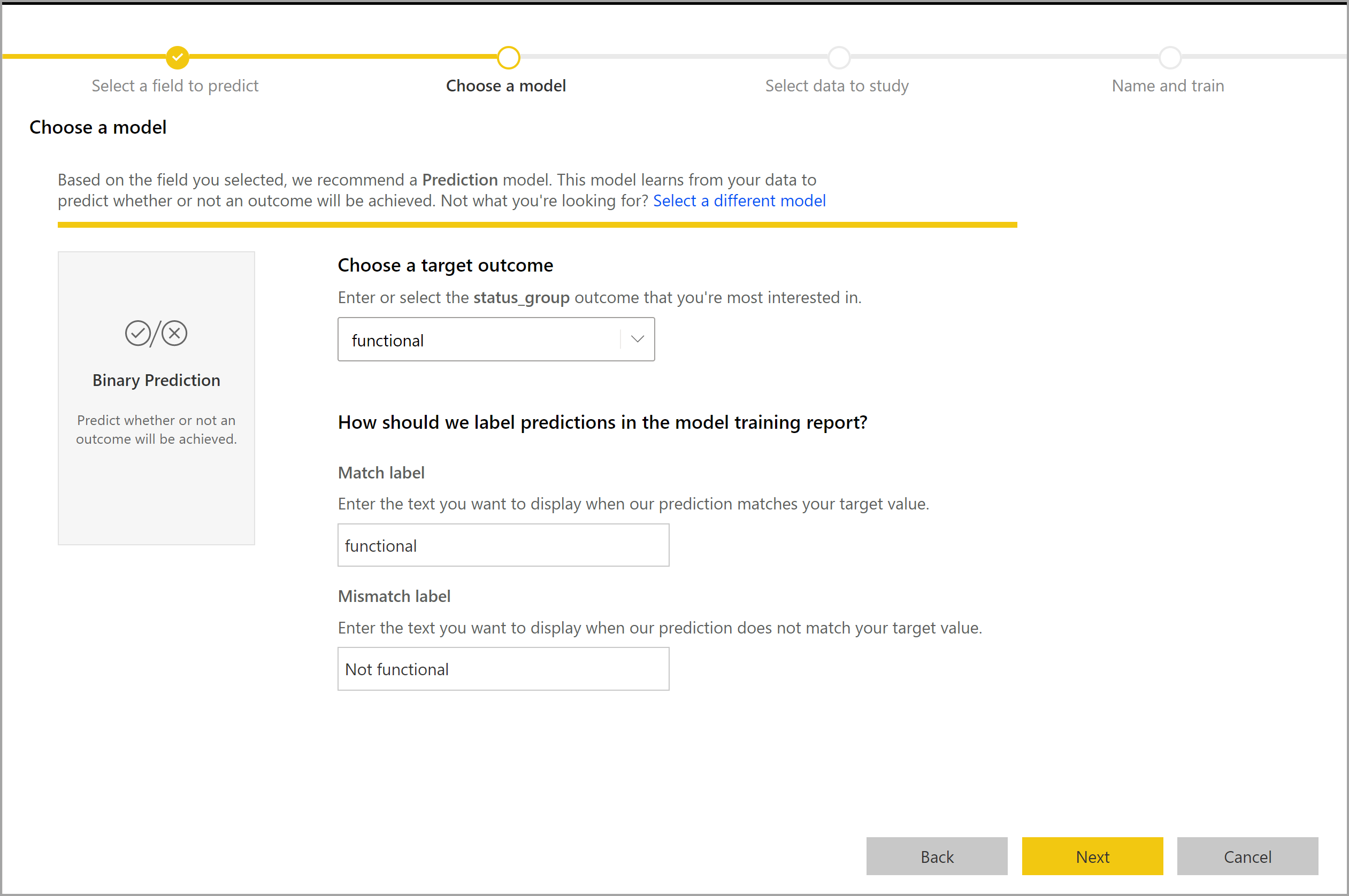
Il processo di creazione di un modello di stima binaria segue gli stessi passaggi degli altri modelli AutoML, descritti nella sezione precedente, Configurare gli input del modello di Machine Learning. L'unica differenza è nel passaggio Scegliere un modello, in cui è possibile selezionare il valore del risultato di destinazione a cui si è maggiormente interessati. È anche possibile specificare etichette descrittive per i risultati da usare nel report generato automaticamente che riepiloga i risultati della convalida del modello.
Report del modello di previsione per dati binari
Il modello di previsione per dati binari produce come output una probabilità che una riga ottenga il risultato di destinazione. Il report include un filtro dei dati per la soglia di probabilità, che influenza il modo in cui i punteggi sono maggiori e minori della soglia di probabilità vengono interpretati.
Il report descrive le prestazioni del modello in termini di veri positivi, falsi positivi, veri negativi e falsi negativi. I veri positivi e i veri negativi sono risultati previsti correttamente per le due classi nei dati del risultato. I falsi positivi sono righe che sono state stimate per avere il risultato target, ma in realtà non lo sono. Al contrario, i falsi negativi sono righe che hanno risultati di destinazione, ma sono stati stimati come non averli.
Le misure, ad esempio la precisione e il richiamo, descrivono l'effetto della soglia di probabilità sui risultati previsti. È possibile usare il filtro dei dati della soglia di probabilità per selezionare una soglia che raggiunga una compromesso equilibrato tra precisione e richiamo.

Il report include anche uno strumento di analisi costi-vantaggi che consente di identificare il subset della popolazione che dovrebbe produrre il massimo profitto. Dato un costo unitario stimato di destinazione e un vantaggio unitario derivante dal raggiungimento di un risultato di destinazione, l'analisi costi-vantaggi tenta di ottimizzare i profitti. È possibile usare questo strumento per scegliere la soglia di probabilità in base al punto massimo nel grafico per ottimizzare i profitti. È anche possibile usare il grafico per calcolare il profitto o il costo per la soglia di probabilità scelta.
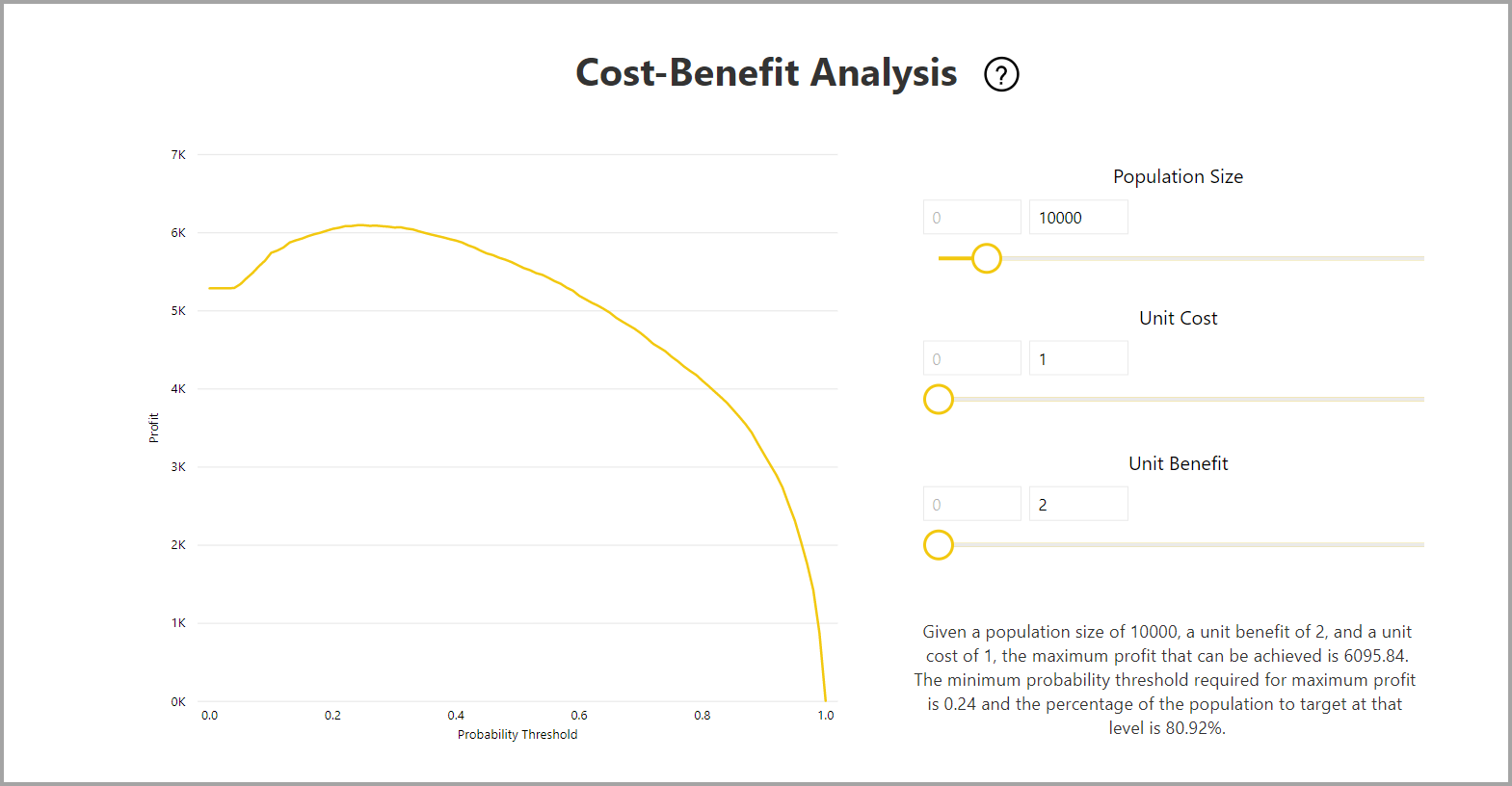
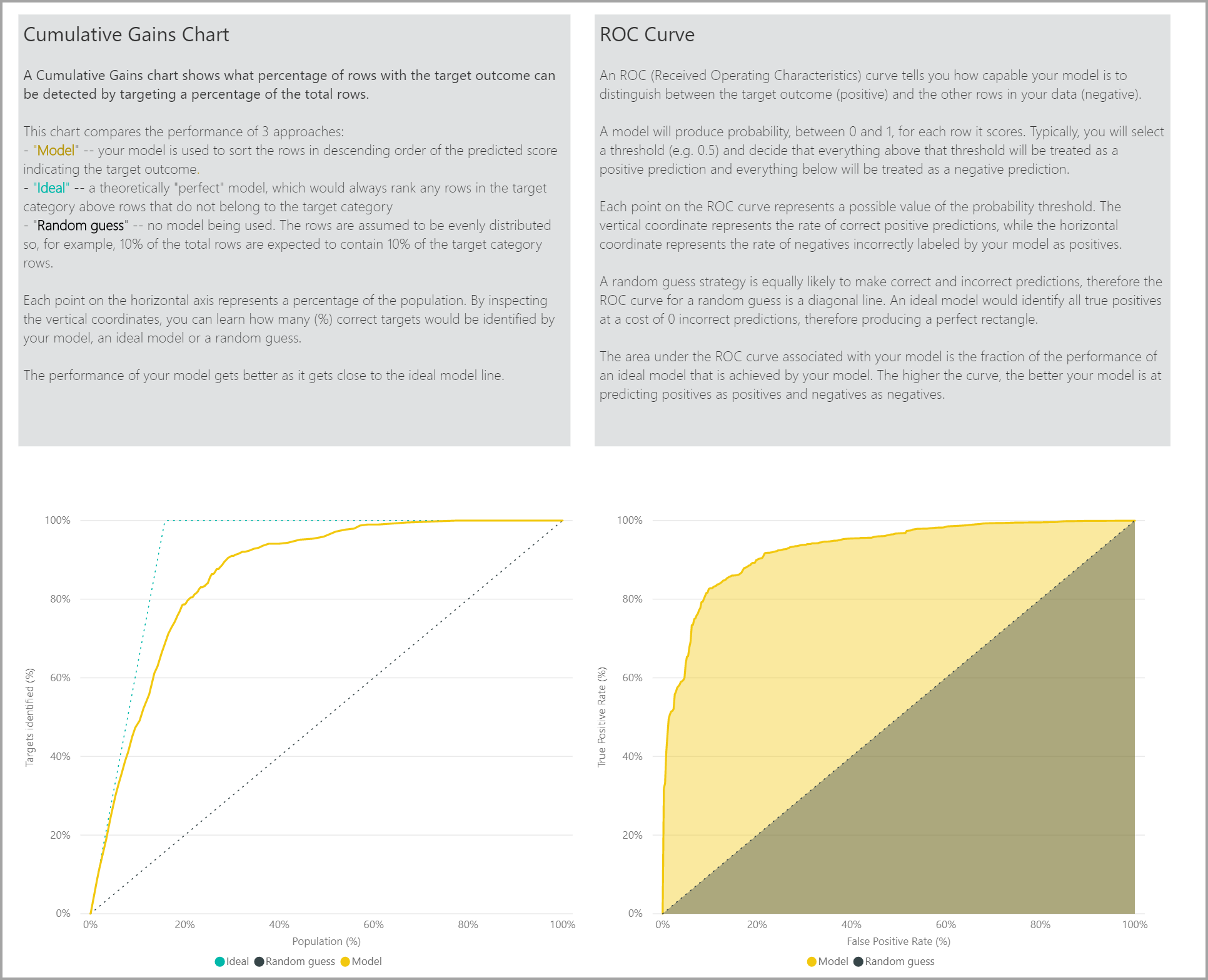
La pagina Report di accuratezza del report sul modello include il grafico dei guadagni cumulativi e la curva ROC per il modello. Questi dati forniscono misure statistiche delle prestazioni del modello. Nei report sono incluse le descrizioni dei grafici illustrati.
Applicare un modello di stima binaria
Per applicare un modello di previsione per dati binari, è necessario specificare la tabella con i dati a cui verranno applicate le previsioni dal modello di Machine Learning. Altri parametri includono il prefisso del nome della colonna di output e la soglia di probabilità per la classificazione del risultato previsto.
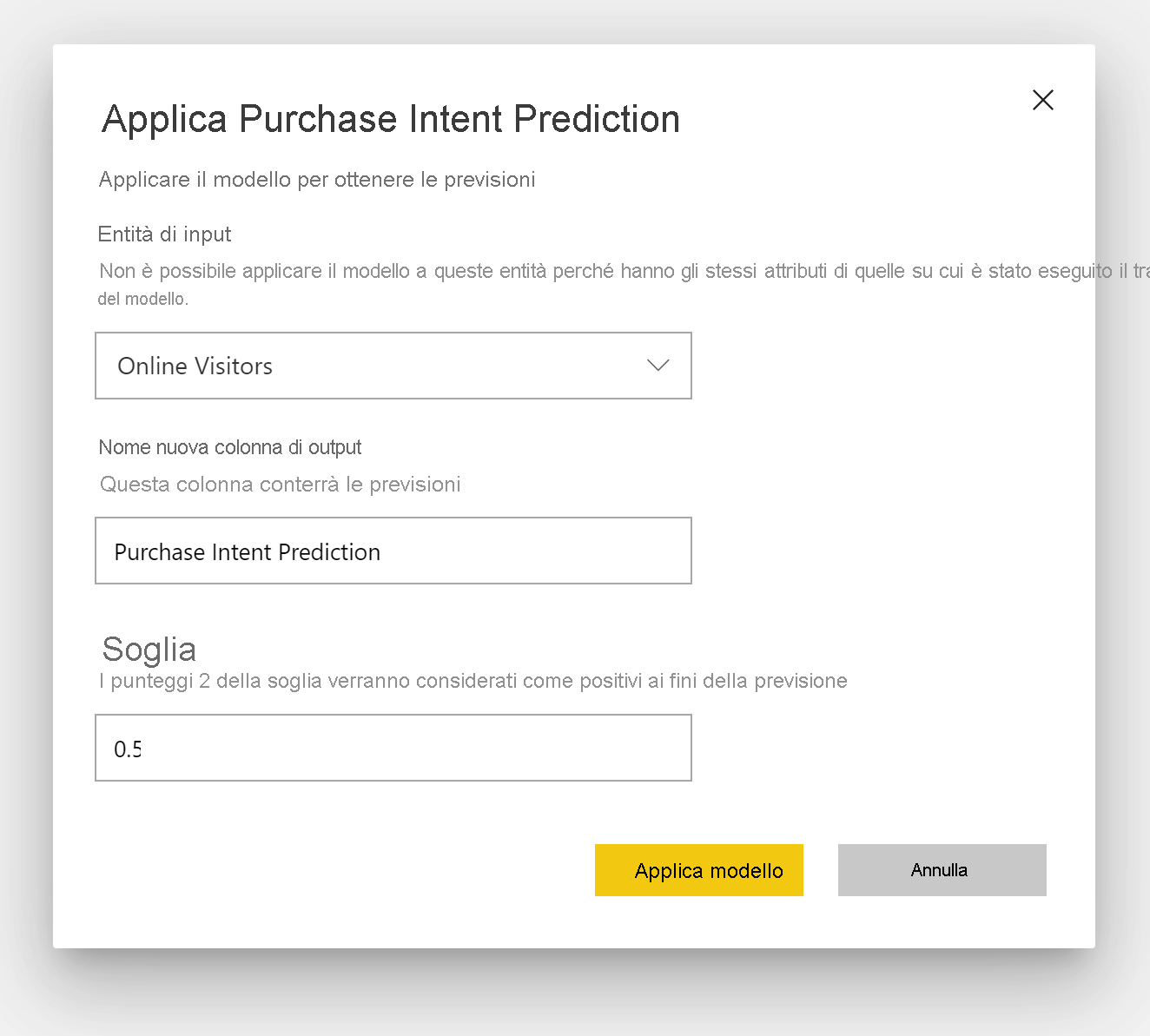
Quando viene applicato un modello di stima binaria, aggiunge quattro colonne di output alla tabella di output arricchita: Outcome, PredictionScore, PredictionExplanation ed ExplanationIndex. I nomi di colonna nella tabella hanno il prefisso specificato quando viene applicato il modello.
PredictionScore è una probabilità percentuale, che identifica la probabilità che venga ottenuto il risultato di destinazione.
La colonna Outcome contiene l'etichetta del risultato stimato. Se le probabilità dei record superano la soglia, probabilmente il risultato di destinazione verrà raggiunto e i record saranno etichettati come True. I record inferiori alla soglia vengono stimati come improbabili per ottenere il risultato e vengono etichettati come False.
La colonna PredictionExplanation contiene una spiegazione con l'influenza specifica delle funzionalità di input su PredictionScore.
Modelli di classificazione
I modelli di classificazione vengono usati per classificare un modello semantico in più gruppi o classi. Si usano per stimare gli eventi che possono avere uno di più risultati possibili, Ad esempio, se è probabile che un cliente abbia un valore di durata elevato, medio o basso. Possono anche prevedere se il rischio predefinito è elevato, moderato, basso e così via.
L'output di un modello di classificazione è un punteggio di probabilità, che identifica la probabilità che una riga raggiunga i criteri per una determinata classe.
Eseguire il training di un modello di classificazione
La tabella di input contenente i dati di training per un modello di classificazione deve avere una colonna stringa o un numero intero come colonna del risultato, che identifica i risultati noti precedenti.
Prerequisiti:
- Sono necessarie almeno 20 righe di dati cronologici per ogni classe di risultati
Il processo di creazione per un modello di classificazione segue gli stessi passaggi degli altri modelli AutoML, descritti nella sezione precedente, Configurare gli input del modello di Machine Learning.
Report sul modello di classificazione
Power BI crea il report del modello di classificazione applicando il modello di Machine Learning ai dati di test di controllo. Confronta quindi la classe stimata per una riga con la classe nota effettiva.
Il report sul modello include un grafico che illustra la suddivisione delle righe classificate in modo corretto e non corretto per ogni classe nota.
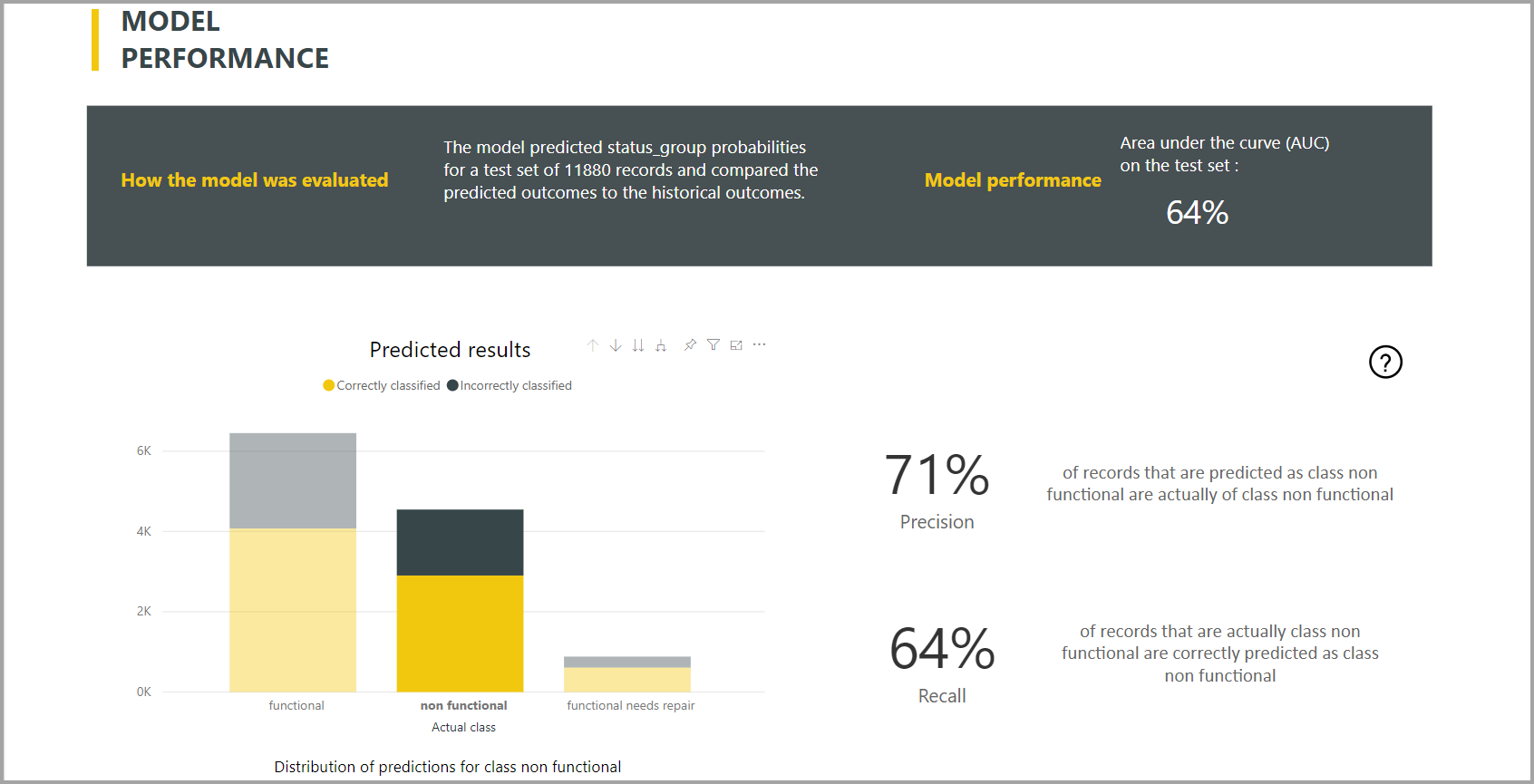
Un'ulteriore azione di drill-down specifica della classe consente di analizzare il modo in cui vengono distribuite le stime per una classe nota. Questa analisi mostra le altre classi in cui è probabile che le righe di quella classe nota vengano classificate in modo errato.
La spiegazione del modello nel report include anche i predittori principali per ogni classe.
Il report del modello di classificazione include anche una pagina Dettagli training simile alle pagine per altri tipi di modello, come descritto in precedenza, nel report del modello AutoML.
Applicare un modello di classificazione
Per applicare un modello di classificazione di Machine Learning, è necessario specificare la tabella con i dati di input e il prefisso del nome della colonna di output.
Quando viene applicato un modello di classificazione, questo aggiunge cinque colonne di output alla tabella di output arricchita: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities ed ExplanationIndex. I nomi di colonna nella tabella hanno il prefisso specificato quando viene applicato il modello.
La colonna ClassProbabilities contiene l'elenco dei punteggi di probabilità per la riga per ogni classe possibile.
ClassificationScore è la probabilità percentuale, che identifica la probabilità che una riga raggiunga i criteri per una determinata classe.
La colonna ClassificationResult contiene la classe stimata con maggiore probabilità per la riga.
La colonna ClassificationExplanation contiene una spiegazione con l'influenza specifica delle caratteristica di input su ClassificationScore.
Modelli di regressione
Dei modelli di regressione vengono usati per stimare un valore numerico e possono essere usati in scenari come la determinazione:
- È probabile che i ricavi vengano realizzati da un accordo di vendita.
- Valore di durata di un account.
- Importo di una fattura che è probabile che venga pagata
- Data in cui potrebbe essere pagata una fattura e così via.
L'output di un modello di regressione è il valore previsto.
Training di un modello di regressione
La tabella di input contenente i dati di training per un modello di regressione deve avere una colonna numerica come colonna risultato, che identifica i valori dei risultati noti.
Prerequisiti:
- Sono necessarie almeno 100 righe di dati cronologici per un modello di regressione.
Il processo di creazione per un modello di regressione segue gli stessi passaggi degli altri modelli AutoML, descritti nella sezione precedente, Configurare gli input del modello di Machine Learning.
Report sul modello di regressione
Analogamente agli altri report sui modelli AutoML, il report di regressione si basa sui risultati dell'applicazione del modello ai dati di test dei dati di controllo.
Il report sul modello include un grafico che confronta i valori stimati con quelli effettivi. In questo grafico la distanza dalla diagonale indica l'errore nella previsione.
Il grafico degli errori residui mostra la distribuzione della percentuale di errore medio per valori diversi nel modello semantico di test di controllo. L'asse orizzontale rappresenta la media del valore effettivo per il gruppo. La dimensione della bolla mostra la frequenza o il conteggio dei valori in tale intervallo. L'asse verticale è l'errore residuo medio.
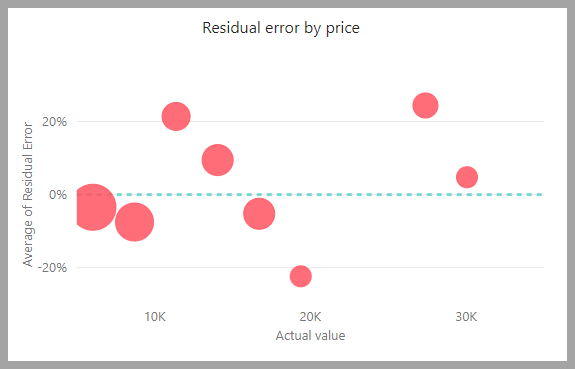
Il report sul modello di regressione include anche una pagina di dettagli del training come i report su altri tipi di modello, come descritto nella precedente sezione Report sul modello AutoML.
Applicare un modello di regressione
Per applicare un modello di regressione di Machine Learning, è necessario specificare la tabella con i dati di input e il prefisso del nome della colonna di output.
Quando viene applicato un modello di regressione, aggiunge tre colonne di output alla tabella di output arricchita: RegressionResult, RegressionExplanation ed ExplanationIndex. I nomi di colonna nella tabella hanno il prefisso specificato quando viene applicato il modello.
La colonna RegressionResult contiene il valore stimato per la riga in base alle colonne di input. La colonna RegressionExplanation contiene una spiegazione con l'influenza specifica delle caratteristiche di input su RegressionResult.
Integrazione di Azure Machine Learning in Power BI
Numerose organizzazioni usano modelli di Machine Learning per ottenere informazioni dettagliate e stime migliori sulle proprie attività aziendali. È possibile usare Machine Learning con report, dashboard e altri elementi analitici per ottenere queste informazioni dettagliate. La possibilità di visualizzare e richiamare informazioni dettagliate da questi modelli può aiutare a diffondere queste informazioni agli utenti aziendali che ne hanno più bisogno. Ora con Power BI è facile incorporare le informazioni dettagliate dei modelli ospitati in Azure Machine Learning, usando semplici movimenti di puntamento e clic.
Per usare questa funzionalità, un data scientist può concedere l'accesso al modello di Azure Machine Learning all'analista BI usando il portale di Azure. Quindi, all'inizio di ogni sessione, Power Query individua tutti i modelli di Azure Machine Learning a cui l'utente ha accesso e li espone come funzioni dinamiche di Power Query. L'utente può quindi richiamare queste funzioni accedendovi dalla barra multifunzione dell'editor di Power Query o richiamando direttamente la funzione M. Power BI invia automaticamente in batch le richieste di accesso quando si richiama il modello di Azure Machine Learning per un set di righe per ottenere prestazioni migliori.
Questa funzionalità è attualmente supportata solo per i flussi di dati di Power BI e per Power Query online nel servizio Power BI.
Per altre informazioni sui flussi di dati, vedere Introduzione ai flussi di dati e alla preparazione dei dati self-service.
Per altre informazioni su Azure Machine Learning, vedere:
- Panoramica: Che cos'è Azure Machine Learning?
- Guide introduttive ed esercitazioni per Azure Machine Learning: documentazione di Azure Machine Learning
Concedere l'accesso al modello di Azure Machine Learning a un utente di Power BI
Per accedere a un modello di Azure Machine Learning da Power BI, l'utente deve avere accesso in lettura alla sottoscrizione di Azure e all'area di lavoro di Machine Learning.
La procedura descritta in questo articolo descrive come concedere a un utente di Power BI l'accesso a un modello ospitato nel servizio Azure Machine Learning per accedere a questo modello come funzione di Power Query. Per ulteriori informazioni, vedi Assegnare ruoli di Azure usando il portale di Azure.
Accedere al portale di Azure.
Passare alla pagina Sottoscrizioni. La pagina Sottoscrizioni è disponibile nell'elenco Tutti i servizi nel menu del riquadro di spostamento del portale di Azure.
Selezionare la propria sottoscrizione.

Selezionare Controllo di accesso (IAM) e quindi scegliere il pulsante Aggiungi.
Selezionare Lettore come ruolo. Scegliere quindi l'utente di Power BI a cui si vuole concedere l'accesso al modello di Azure Machine Learning.
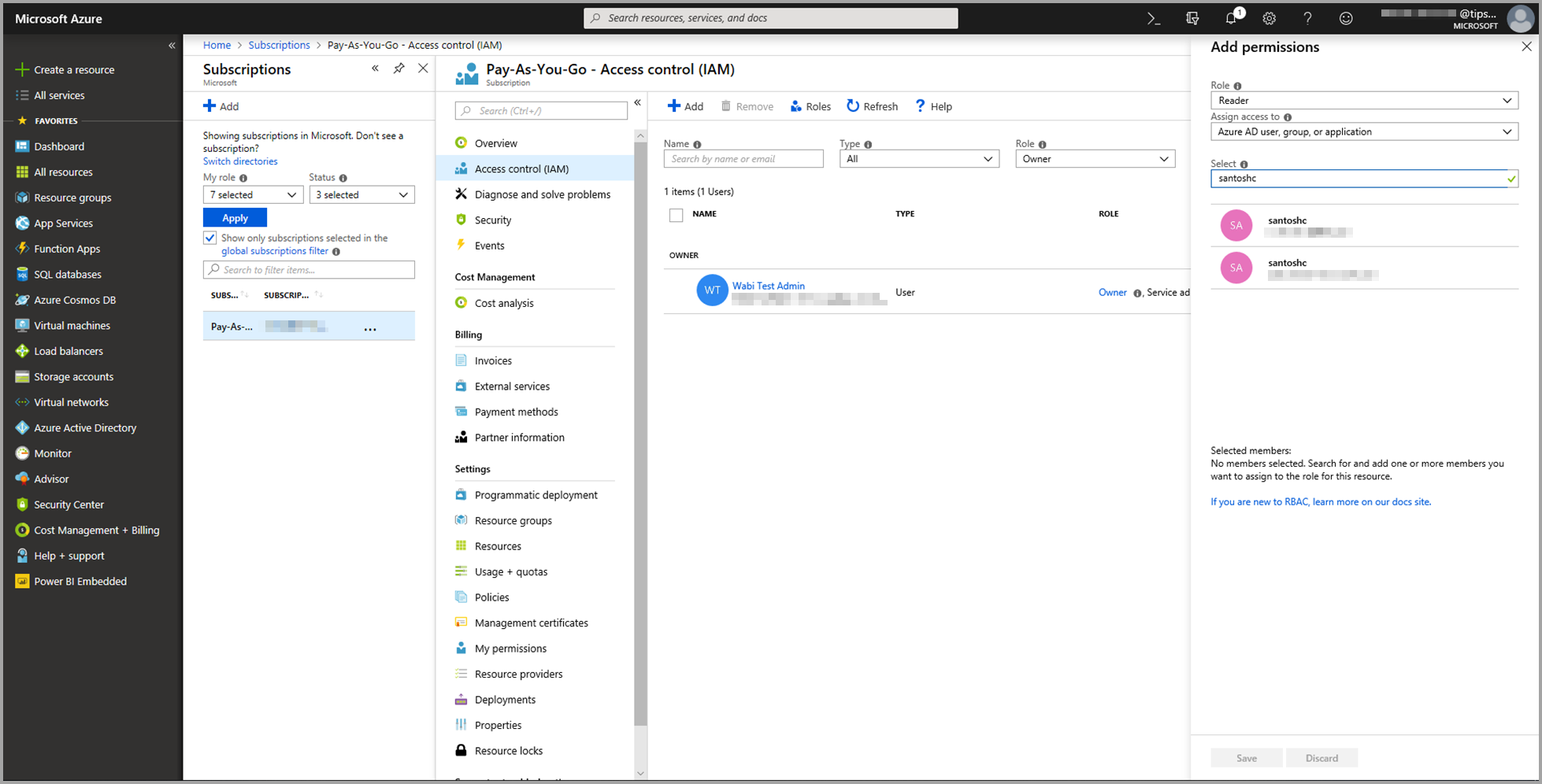
Seleziona Salva.
Ripetere i passaggi da tre a sei per concedere l'accesso come Lettore all'utente per l'area di lavoro di Machine Learning specifica che ospita il modello.




Individuazione dello schema per i modelli di Machine Learning
I data scientist usano principalmente Python per sviluppare, e persino per distribuire, i modelli di Machine Learning per Machine Learning. Il data scientist deve generare in modo esplicito il file di schema usando Python.
Questo file di schema deve essere incluso nel servizio Web distribuito per i modelli di Machine Learning. Per generare automaticamente lo schema per il servizio Web, è necessario fornire un esempio di input/output nello script di ingresso per il modello distribuito. Per altre informazioni, vedere Distribuire e assegnare punteggi a un modello di Machine Learning usando un endpoint online. Il collegamento include lo script di ingresso di esempio con le istruzioni per la generazione dello schema.
In particolare, le funzioni @input_schema e @output_schema nello script di immissione fanno riferimento ai formati di esempio di input e output nelle variabili input_sample e output_sample. Le funzioni usano questi esempi per generare una specifica OpenAPI (Swagger) per il servizio Web durante la distribuzione.
Le istruzioni per la generazione dello schema tramite l'aggiornamento dello script di ingresso devono essere applicate anche ai modelli creati con gli esperimenti di Machine Learning automatizzati e usando l'SDK di Azure Machine Learning.
Nota
I modelli creati con l'interfaccia visiva di Azure Machine Learning non supportano attualmente la generazione dello schema, ma verranno rilasciati nelle versioni successive.
Richiamo del modello di Azure Machine Learning in Power BI
È possibile richiamare qualsiasi modello di Azure Machine Learning a cui è stato concesso l'accesso, direttamente dall'editor di Power Query nel flusso di dati. Per accedere ai modelli di Azure Machine Learning, selezionare il pulsante Modifica tabella per la tabella da arricchire con informazioni dettagliate dal modello di Azure Machine Learning, come illustrato nell'immagine seguente.

Se si seleziona il pulsante Modifica tabella, viene aperto l'editor di Power Query per le tabelle nel flusso di dati.

Selezionare il pulsante Informazioni dettagliate sull'intelligenza artificiale sulla barra multifunzione e quindi selezionare la cartella Azure Machine Learning Models (Modelli di Azure Machine Learning) nel menu del riquadro di spostamento. Tutti i modelli di Azure Machine Learning a cui si ha accesso sono elencati qui come funzioni di Power Query. Inoltre, i parametri di input per il modello di Azure Machine Learning vengono mappati automaticamente come parametri della funzione di Power Query corrispondente.
Per richiamare un modello di Azure Machine Learning, è possibile specificare una delle colonne della tabella selezionata come input dall'elenco a discesa. Si può anche specificare un valore di costante da usare come input attivando l'icona della colonna a sinistra della finestra di dialogo di input.

Selezionare Richiama per visualizzare l'anteprima dell'output del modello di Azure Machine Learning come nuova colonna nella tabella. La chiamata al modello viene visualizzata come passaggio applicato per la query.

Se il modello restituisce più parametri di output, questi vengono raggruppati come riga nella colonna di output. È possibile espandere la colonna per produrre singoli parametri di output in colonne separate.

Dopo aver salvato il flusso di dati, il modello viene richiamato automaticamente quando il flusso di dati viene aggiornato per le righe nuove o aggiornate nella tabella.
Considerazioni e limitazioni
- I flussi di dati Gen2 non si integrano attualmente con Machine Learning automatizzato.
- Le informazioni dettagliate sull'intelligenza artificiale (servizi cognitivi e modelli di Azure Machine Learning) non sono supportate nei computer con la configurazione dell'autenticazione proxy.
- I modelli di Azure Machine Learning non sono supportati per gli utenti guest.
- Esistono alcuni problemi noti relativi all'uso del gateway con AutoML e Servizi cognitivi. Se è necessario usare un gateway, è consigliabile creare prima un flusso di dati che importa i dati necessari tramite gateway. Creare quindi un altro flusso di dati che faccia riferimento al primo flusso di dati per creare o applicare questi modelli e funzioni di intelligenza artificiale.
- Se l'intelligenza artificiale non funziona con i flussi di dati, potrebbe essere necessario abilitare la combinazione rapida quando si usa l'intelligenza artificiale con i flussi di dati. Dopo aver importato la tabella e prima di iniziare ad aggiungere funzionalità di intelligenza artificiale, selezionare Opzioni dalla barra multifunzione Home e nella finestra visualizzata selezionare la casella di controllo accanto a Consenti combinazione di dati da più origini per abilitare la funzionalità, quindi selezionare OK per salvare la selezione. È quindi possibile aggiungere funzionalità di intelligenza artificiale al flusso di dati.
Contenuto correlato
Questo articolo ha offerto una panoramica su Machine Learning automatizzato per i flussi di dati nel servizio Power BI. Anche gli articoli seguenti potrebbero essere utili.
- Esercitazione: Creare un modello di Machine Learning in Power BI
- Esercitazione: Usare Servizi cognitivi in Power BI
Gli articoli seguenti contengono altre informazioni sui flussi di dati e su Power BI:
- Introduzione ai flussi di dati e alla preparazione dei dati self-service
- Creazione di un flusso di dati
- Configurazione e uso di un flusso di dati
- Configurare la risorsa di archiviazione del flusso di dati per usare Azure Data Lake Gen 2
- Funzionalità Premium dei flussi di dati
- Considerazioni e limitazioni per i flussi di dati
- Procedure consigliate per i flussi di dati