Sviluppare soluzioni con flussi di dati
I flussi di dati di Power BI sono una soluzione di preparazione dei dati orientata all'organizzazione che consente un ecosistema di dati pronti per l'utilizzo, il riutilizzo e l'integrazione. Questo articolo presenta alcuni scenari comuni, collegamenti ad articoli e altre informazioni che consentono di comprendere e usare i flussi di dati per il loro pieno potenziale.
Ottenere l'accesso alle funzionalità Premium dei flussi di dati
I flussi di dati di Power BI nelle capacità Premium offrono molte funzionalità chiave che consentono di ottenere maggiore scalabilità e prestazioni per i flussi di dati, ad esempio:
- Calcolo avanzato, che accelera le prestazioni ETL e offre funzionalità DirectQuery.
- Aggiornamento incrementale, che consente di caricare i dati modificati da un'origine.
- Entità collegate, che è possibile usare per fare riferimento ad altri flussi di dati.
- Entità calcolate, che è possibile usare per creare blocchi predefiniti componibili di flussi di dati che contengono più logica di business.
Per questi motivi, è consigliabile usare i flussi di dati in una capacità Premium quando possibile. I flussi di dati usati in una licenza di Power BI Pro possono essere usati per casi d'uso semplici e su scala ridotta.
Soluzione
L'accesso a queste funzionalità Premium dei flussi di dati è possibile in due modi:
- Designare una capacità Premium in una determinata area di lavoro e usare la propria licenza Pro per creare flussi di dati qui.
- Porta la tua licenza Premium per utente (PPU), che richiede agli altri membri dell'area di lavoro di possedere anch'essi una licenza PPU.
Non è possibile utilizzare flussi di dati PPU (o altri contenuti) all'esterno dell'ambiente PPU (ad esempio in SKU Premium o altre licenze).
Per le capacità Premium, gli utenti dei flussi di dati in Power BI Desktop non necessitano di licenze esplicite per consumare e pubblicare in Power BI. Tuttavia, per pubblicare in un'area di lavoro o condividere un modello semantico risultante, è necessaria almeno una licenza Pro.
Per l'ambiente PPU, tutti gli utenti che creano o usano contenuti PPU devono avere una licenza PPU. Questo requisito varia dal resto di Power BI in quanto è necessario concedere in modo esplicito la licenza a tutti gli utenti con PPU. Non è possibile combinare capacità Gratuite, Pro o anche Premium con contenuto PPU, a meno che non si esegua la migrazione dell'area di lavoro a una capacità Premium.
La scelta di un modello dipende in genere dalle dimensioni e dagli obiettivi dell'organizzazione, ma si applicano le linee guida seguenti.
| Tipo di team. | Premium per capacità | Premium per utente |
|---|---|---|
| >5.000 utenti | ✔ | |
| <5.000 utenti | ✔ |
Per i team di piccole dimensioni, PPU può colmare il divario tra Free, Pro e Premium per capacità. Se si hanno esigenze più grandi, l'uso di una capacità Premium con utenti con licenze Pro è l'approccio migliore.
Creare flussi di dati utente con sicurezza applicata
Si supponga di dover creare flussi di dati per l'utilizzo, ma con requisiti di sicurezza:
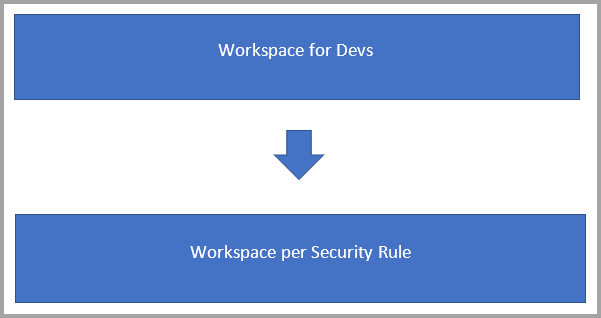
In questo scenario è probabile che si disponga di due tipi di aree di lavoro:
Aree di lavoro back-end in cui si sviluppano flussi di dati e si compila la logica di business.
Aree di lavoro utente in cui si desidera esporre alcuni flussi di dati o tabelle a un determinato gruppo di utenti per l'utilizzo:
- L'area di lavoro utente contiene tabelle collegate che puntano ai flussi di dati nell'area di lavoro back-end.
- Gli utenti hanno accesso al visualizzatore all'area di lavoro consumer e non hanno accesso all'area di lavoro back-end.
- Quando un utente usa Power BI Desktop per accedere a un flusso di dati nell'area di lavoro utente, può visualizzare il flusso di dati. Tuttavia, poiché il flusso di dati viene visualizzato vuoto nello strumento di navigazione, le tabelle collegate non vengono visualizzate.
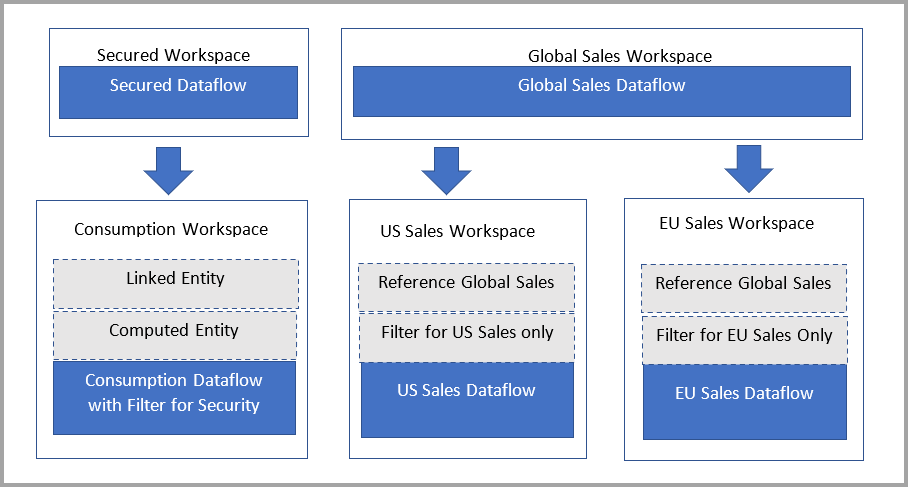
Informazioni sulle tabelle collegate
Le tabelle collegate sono semplicemente un puntatore alle tabelle del flusso di dati originali ed ereditano l'autorizzazione dell'origine. Se Power BI ha consentito alla tabella collegata di usare l'autorizzazione di destinazione, qualsiasi utente potrebbe aggirare l'autorizzazione di origine creando una tabella collegata nella destinazione che punta all'origine.
Soluzione: usare tabelle calcolate
Se si ha accesso a Power BI Premium, è possibile creare una tabella calcolata nella destinazione che fa riferimento alla tabella collegata, che include una copia dei dati dalla tabella collegata. È possibile rimuovere colonne tramite proiezioni e rimuovere righe tramite filtri. L'utente con autorizzazione per l'area di lavoro di destinazione può accedere ai dati tramite questa tabella.
La derivazione per utenti con privilegi mostra anche l'area di lavoro a cui si fa riferimento e consente agli utenti di collegarsi per comprendere appieno il flusso di dati padre. Per gli utenti che non hanno privilegi, la privacy è ancora rispettata. Viene visualizzato solo il nome dell'area di lavoro.
Nel seguente diagramma viene illustrata questa impostazione. A sinistra è il modello architettonico. A destra è riportato un esempio che mostra i dati di vendita suddivisi e protetti in base all'area.
Ridurre i tempi di aggiornamento per i flussi di dati
Si supponga di avere un flusso di dati di grandi dimensioni e di voler creare modelli semantici da tale flusso di dati e ridurre il tempo necessario per aggiornarlo. In genere, il completamento degli aggiornamenti dall'origine dati ai flussi di dati al modello semantico richiede molto tempo. Gli aggiornamenti lunghi sono difficili da gestire.
Soluzione: usare le tabelle con Abilita caricamento configurato in modo esplicito per le tabelle a cui si fa riferimento e non disabilitare il caricamento
Power BI supporta un'orchestrazione semplice per i flussi di dati, come definito per comprendere e ottimizzare l'aggiornamento dei flussi di dati. Per sfruttare i vantaggi dell'orchestrazione è necessario configurare in modo esplicito eventuali flussi di dati downstream per abilitare il caricamento.
La disabilitazione del carico è in genere appropriata solo quando il sovraccarico del caricamento di più query annulla il vantaggio dell'entità con cui si sta sviluppando.
Disabilitando il carico, Power BI non valuta la query specificata; quando utilizzata come componente, ossia quando ci si riferisce ad essa in altri flussi di dati, significa anche che Power BI non la considera come una tabella esistente a cui possiamo fornire un puntatore e eseguire folding delle query e ottimizzazioni. In questo senso, l'esecuzione di trasformazioni, come una combinazione o un'unione, è semplicemente una combinazione o un'unione di due query di dati di origine. Queste operazioni possono avere un effetto negativo sulle prestazioni, perché Power BI deve ricaricare completamente la logica già calcolata e quindi applicare qualsiasi altra logica.
Per semplificare l'elaborazione delle query del flusso di dati e assicurarsi che tutte le ottimizzazioni del motore siano in corso, abilitare il carico e assicurarsi che il motore di calcolo nei flussi di dati Power BI Premium sia impostato nell'impostazione predefinita, Ottimizzato.
L'abilitazione del carico consente anche di mantenere la visualizzazione completa della provenienza dei dati, perché Power BI considera un flusso di dati con caricamento non abilitato come un nuovo elemento. Se la derivazione è importante, non disabilitare il caricamento per entità o flussi di dati connessi ad altri flussi di dati.
Ridurre i tempi di aggiornamento per i modelli semantici
Si supponga di avere un flusso di dati di grandi dimensioni e di voler creare modelli semantici al di fuori di esso e ridurre l'orchestrazione. Il completamento degli aggiornamenti richiede molto tempo dall'origine dati ai flussi di dati ai modelli semantici, con conseguente aumento della latenza.
Soluzione: usare flussi di dati DirectQuery
DirectQuery può essere usato ogni volta che l'impostazione del motore di calcolo avanzato di un'area di lavoro (ECE) viene configurata in modo esplicito su Sì. Questa impostazione è utile quando si dispone di dati che non devono essere caricati direttamente in un modello di Power BI. Se si configura ECE in modo che sia Attivato per la prima volta, le modifiche che consentono DirectQuery verranno apportate durante l'aggiornamento successivo. È necessario aggiornarlo quando si abilita l'attivazione delle modifiche immediatamente. Gli aggiornamenti sul carico iniziale del flusso di dati possono essere più lenti perché Power BI scrive i dati sia nell'archiviazione che in un motore SQL gestito.
Per riepilogare, l'uso di DirectQuery con flussi di dati consente i miglioramenti seguenti ai processi di Power BI e dei flussi di dati:
- Evitare pianificazioni di aggiornamento separate: DirectQuery si connette direttamente a un flusso di dati, eliminando la necessità di creare un modello semantico importato. Di conseguenza, usando DirectQuery con i flussi di dati, non sono più necessarie pianificazioni di aggiornamento separate per il flusso di dati e il modello semantico per assicurarsi che i dati siano sincronizzati.
- Filtro dei dati: DirectQuery è utile per lavorare su una visualizzazione filtrata dei dati all'interno di un flusso di dati. Per filtrare i dati e usare un subset più piccolo dei dati nel flusso di dati, è possibile usare DirectQuery (e ECE) per filtrare i dati del flusso di dati e usare il subset filtrato necessario.
In genere, l'uso di DirectQuery consente di scambiare dati aggiornati nel modello semantico con prestazioni del report più lente rispetto alla modalità di importazione. Si consideri questo approccio solo quando:
- Il caso d'uso richiede dati a bassa latenza provenienti dal flusso di dati.
- I dati del flusso di dati sono di grandi dimensioni.
- Un'importazione richiede troppo tempo.
- Si è disposti a scambiare le prestazioni memorizzate nella cache per i dati aggiornati.
Soluzione: usare il connettore flussi di dati per abilitare la riduzione delle query e l'aggiornamento incrementale per l'importazione
Il connettore Dataflows unificato può ridurre significativamente il tempo di valutazione per i passaggi eseguiti su entità calcolate, ad esempio per eseguire join, distinti, filtri e operazioni di raggruppamento. Esistono due vantaggi specifici:
- Gli utenti downstream che si connettono al connettore Flussi di dati in Power BI Desktop possono sfruttare prestazioni migliori negli scenari di creazione perché il nuovo connettore supporta la riduzione delle query.
- Le operazioni di aggiornamento semantico del modello possono anche essere piegate al motore di calcolo avanzato, il che significa che anche l'aggiornamento incrementale da un modello semantico può essere piegato a un flusso di dati. Questa funzionalità migliora le prestazioni di aggiornamento e riduce potenzialmente la latenza tra cicli di aggiornamento.
Per abilitare questa funzionalità per qualsiasi flusso di dati Premium, assicurarsi che il motore di calcolo sia impostato in modo esplicito su Sì. Usare quindi il connettore Flussi di dati in Power BI Desktop. È necessario usare la versione di agosto 2021 di Power BI Desktop o versioni successive per sfruttare questa funzionalità.
Per usare questa funzionalità per le soluzioni esistenti, è necessario trovarsi in una sottoscrizione Premium o Premium per utente. Potrebbe anche essere necessario apportare alcune modifiche al flusso di dati, come descritto in Uso del motore di calcolo avanzato. È necessario aggiornare tutte le query di Power Query esistenti per usare il nuovo connettore sostituendo PowerBI.Dataflows nella sezione Origine con PowerPlatform.Dataflows.
Creazione di flussi di dati complessi in Power Query
Immagina di avere un flusso di dati che rappresenta milioni di righe di dati, ma vuoi creare una complessa logica aziendale e trasformazioni per esso. Si vogliono seguire le procedure consigliate per l'uso di flussi di dati di grandi dimensioni. Anche le anteprime del flusso di dati devono funzionare rapidamente. Tuttavia, sono presenti decine di colonne e milioni di righe di dati.
Soluzione: usare la vista Schema
È possibile usare la vista Schema, progettata per ottimizzare il flusso quando si lavora sulle operazioni a livello di schema inserendo le informazioni sulle colonne della query prima e al centro. La vista Schema fornisce interazioni contestuali per modellare la struttura dei dati. La vista Schema offre anche operazioni di latenza inferiori perché richiede solo il calcolo dei metadati di colonna e non i risultati completi dei dati.
Usare origini dati di dimensioni maggiori
Si supponga di eseguire una query nel sistema di origine, ma di non voler fornire l'accesso diretto al sistema o democratizzare l'accesso. Si prevede di inserirlo in un flusso di dati.
Soluzione 1: usare una visualizzazione per la query o ottimizzare la query
L'utilizzo di un'origine dati ottimizzata e di una consultazione efficace è la vostra opzione migliore. Spesso, l'origine dati funziona meglio con le query destinate ad essa. Power Query migliora le funzionalità di riduzione delle query per delegare questi carichi di lavoro. Power BI fornisce anche gli indicatori di piegatura dei passaggi in Power Query Online. Per ulteriori informazioni sui tipi di indicatori, vedere la documentazione relativa agli indicatori di piegatura dei passaggi.
Soluzione 2: usare una query nativa
È anche possibile usare la funzione M Value.NativeQuery(). Nel terzo parametro viene impostata l'opzione EnableFolding=true. Native Query è documentato in questo sito Web per il connettore Postgres. Funziona anche per il connettore SQL Server.
Soluzione 3: suddividere il flusso di dati in flussi di dati di inserimento e consumo per sfruttare i vantaggi delle entità ECE e collegate
Suddividendo un flusso di dati in flussi di dati di inserimento e consumo separati, è possibile sfruttare le entità ECE e Collegate. Per altre informazioni su questo modello e altri, vedere la documentazione sulle procedure consigliate.
Assicurarsi che i clienti usino i flussi di dati quando possibile
Si supponga di avere molti flussi di dati che servono scopi comuni, ad esempio dimensioni conformi come clienti, tabelle dati, prodotti e aree geografiche. I flussi di dati sono già disponibili nella barra multifunzione per Power BI. Idealmente, si vuole che i clienti usino principalmente i flussi di dati creati.
Soluzione: usare l'approvazione per certificare e promuovere i flussi di dati
Per altre informazioni sul funzionamento dell'approvazione, vedere Verifica dell'autenticità: promozione e certificazione del contenuto di Power BI.
Programmabilità e automazione nei flussi di dati di Power BI
Si supponga di avere requisiti aziendali per automatizzare importazioni, esportazioni o aggiornamenti e altre orchestrazioni e azioni all'esterno di Power BI. Sono disponibili alcune opzioni per abilitare questa operazione, come descritto nella tabella seguente.
| Tipo | Meccanismo |
|---|---|
| Usare i modelli di Power Automate . | Senza codice |
| Usare gli script di automazione in PowerShell. | Script di automazione |
| Creare una logica di business personalizzata usando le API. | API REST |
Per altre informazioni sull'aggiornamento, vedere Informazioni e ottimizzazione degli aggiornamenti dei flussi di dati.
Assicurarsi di proteggere gli asset di dati downstream
È possibile usare le etichette di riservatezza per applicare una classificazione dei dati e tutte le regole configurate sugli elementi downstream che si connettono ai flussi di dati. Per altre informazioni sulle etichette di riservatezza, vedere Etichette di riservatezza in Power BI. Per esaminare l'ereditarietà, vedere Ereditarietà downstream dell'etichetta di riservatezza in Power BI.
Supporto Multi-Geo
Molti clienti hanno oggi la necessità di soddisfare i requisiti di sovranità e residenza dei dati. È possibile completare una configurazione manuale per lo spazio di lavoro dei flussi di dati in modo che sia Multi-Geo.
I flussi di dati supportano più aree geografiche quando usano la funzionalità bring-your-own-storage-account. Questa funzionalità è descritta in Configurazione dell'archiviazione del flusso di dati per l'uso di Azure Data Lake Gen 2. L'area di lavoro deve essere vuota prima di collegarsi per questa funzionalità. Con questa configurazione specifica, è possibile archiviare i dati del flusso di dati in aree geografiche specifiche desiderate.
Assicurarsi di proteggere gli asset di dati dietro una rete virtuale
Molti clienti hanno oggi la necessità di proteggere gli asset di dati dietro un endpoint privato. A tale scopo, usare reti virtuali e un gateway per mantenere la conformità. La tabella seguente descrive il supporto della rete virtuale corrente e spiega come usare i flussi di dati per mantenere la conformità e proteggere gli asset di dati.
| Scenario | Stato |
|---|---|
| Leggi le origini dati della rete virtuale tramite un gateway locale. | Supportato tramite un gateway locale |
| Scrivere dati su un account con un'etichetta di sensibilità su una rete virtuale utilizzando un gateway locale. | Non ancora supportato |
Contenuto correlato
Gli articoli seguenti contengono altre informazioni sui flussi di dati e su Power BI:
- Introduzione ai flussi di dati e alla preparazione dei dati self-service
- Creare un flusso di dati
- Configurazione e uso di un flusso di dati
- Funzionalità Premium dei flussi di dati
- Intelligenza artificiale con i flussi di dati
- Considerazioni e limitazioni per i flussi di dati
- Procedure consigliate per i flussi di dati