Campionamento ad alta densità nei grafici a dispersione di Power BI
L'algoritmo di campionamento di Power BI migliora il modo in cui i grafici a dispersione rappresentano dati ad alta densità.
È ad esempio possibile creare un grafico a dispersione dall'attività di vendita dell'organizzazione, in cui ogni negozio ha decine di migliaia di punti dati ogni anno. Un grafico a dispersione di tali informazioni campionerebbe i dati da una rappresentazione significativa dei dati per illustrare il modo in cui le vendite si sono verificate nel tempo. I dettagli del campionamento dei dati ad alta densità sono descritti in questo articolo.

Nota
L'algoritmo Campionamento ad alta densità descritto in questo articolo è disponibile nei grafici a dispersione sia per Power BI Desktop che per il servizio Power BI.
Funzionamento dei grafici a dispersione ad alta densità
In precedenza, Power BI selezionava una raccolta di punti dati di esempio nell'intero intervallo di dati sottostanti in modo deterministico per cerare un grafico a dispersione. In particolare, Power BI seleziona la prima e l'ultima riga di dati nella serie del grafico a dispersione, quindi divide uniformemente le righe restanti in modo che un totale di 3.500 punti dati venga tracciato nel grafico a dispersione. Se ad esempio il campione ha 35.000 righe, la prima e l'ultima riga vengono selezionate per il tracciato, quindi viene tracciata anche una riga ogni dieci (35.000 / 10 = una riga ogni dieci = 3.500 punti dati). Sempre in precedenza, i punti o i valori Null che non potevano essere tracciati, come ad esempio, i valori di testo, nella serie di dati non venivano mostrati e quindi non tenuti in considerazione durante la generazione dell'oggetto visivo. Con tale campionamento, anche la densità percepita del grafico a dispersione si basava sui punti dati rappresentativi, quindi la densità implicita degli oggetti visivi era il risultato dei punti campionati, non della raccolta completa dei dati sottostanti.
Quando si abilita Campionamento ad alta densità, Power BI implementa un algoritmo che elimina la sovrapposizione dei punti e garantisce che i punti nell'oggetto visivo siano raggiungibili quando si interagisce con l'oggetto visivo stesso. L'algoritmo assicura anche che tutti i punti del set di dati vengano rappresentati nell'oggetto visivo, fornendo contesto al significato dei punti selezionati, invece di limitarsi a tracciare un campione rappresentativo.
Per definizione, i dati ad alta densità vengono campionati per creare oggetti visivi reattivi all'interattività. Troppi punti dati su un oggetto visivo possono rallentarlo e possono comportare una riduzione della visibilità delle tendenze. Il modo in cui i dati vengono campionati è ciò che comporta la creazione dell'algoritmo di campionamento per offrire la migliore esperienza di visualizzazione e garantire che tutti i dati vengano rappresentati. In Power BI, ora l'algoritmo è migliorato per fornire la combinazione migliore della velocità di risposta, della rappresentazione e della conservazione dei punti importanti nel set di dati completo.
Nota
Il modo migliore per tracciare grafici a dispersione che usano l'algoritmo di campionamento ad alta densità è, come per tutti i grafici a dispersione, usare oggetti visivi quadrati.
Funzionamento del nuovo algoritmo di campionamento dei grafici a dispersione
L’algoritmo per il campionamento ad alta densità per i grafici a dispersione usa metodi che acquisiscono e rappresentano i dati soggiacenti in modo più efficace ed elimina la sovrapposizione dei punti. L’algoritmo inizia con un raggio di piccole dimensioni per ogni punto dati, ovvero le dimensioni del cerchio dell'oggetto visivo per un determinato punto della visualizzazione. Aumenta quindi il raggio di tutti i punti dati. Quando due o più punti dati si sovrappongono, un singolo cerchio delle dimensioni del raggio aumentato rappresenta i punti dati sovrapposti. L'algoritmo continua ad aumentare il raggio dei punti dati finché il valore del raggio non restituisce un numero ragionevole di punti dati, 3.500, comparente nel grafico a dispersione.
I metodi di questo algoritmo assicurano che gli outlier vengano rappresentati nell'oggetto visivo risultante. L'algoritmo rispetta anche la scala quando determina la sovrapposizione, in modo che vengano visualizzate scale esponenziali fedeli ai punti visualizzati sottostanti.
L'algoritmo mantiene anche la forma complessiva del grafico a dispersione.
Nota
Quando si usa l'algoritmo campionamento ad alta densità per i grafici a dispersione, l'obiettivo è un'accurata distribuzione dei dati e non la densità implicita degli oggetti visivi. Ad esempio, è possibile che venga visualizzato un grafico a dispersione con un numero elevato di cerchi che si sovrappongono (densità) in una determinata area e si immagini che molti punti dati debbano essere raggruppati in tale area. Poiché l'algoritmo campionamento ad alta densità può usare un cerchio per rappresentare molti punti dati, tale densità visiva implicita o "clustering" non verrà visualizzata. Per ottenere maggiori dettagli in una determinata area, è possibile usare i filtri dei dati per fare zoom avanti.
Inoltre, i punti dati che non possono essere tracciati, come ad esempio valori Null o valori di testo, vengono ignorati, quindi viene selezionato un altro valore che può essere tracciato. In questo modo si garantisce inoltre che venga mantenuta la forma vera del grafico a dispersione.
Quando viene usato l'algoritmo standard per i grafici a dispersione
In alcuni casi non è possibile applicare il campionamento ad alta densità a un grafico a dispersione e viene quindi usato l'algoritmo originale. Tali circostanze sono:
Se si fa clic con il pulsante destro del mouse su un valore in Valori e lo si imposta su Mostra elementi senza dati nel menu, il grafico a dispersione tornerà all'algoritmo originale.
Se sono presenti valori sull'asse di riproduzione, il grafico a dispersione ripristinerà l'algoritmo originale.
Se in un grafico a dispersione mancano sia l'asse X che l'asse Y, il grafico ripristina l'algoritmo originale.
Se si usa una riga del rapporto nel riquadro Analisi, il grafico ripristina l'algoritmo originale.
Come attivare il campionamento ad alta densità per un grafico a dispersione
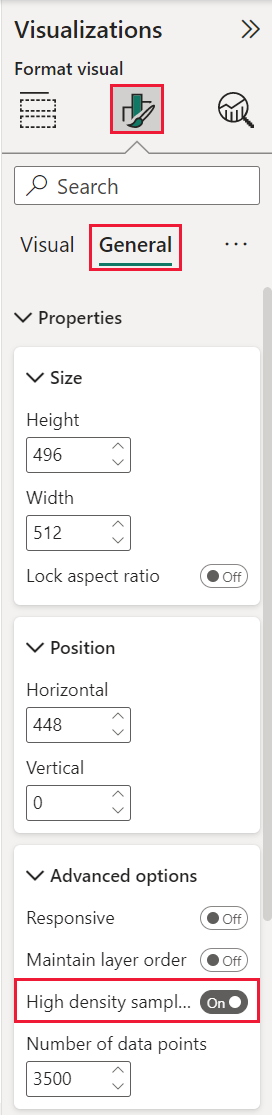
Per posizionare Campionamento ad alta densità su Sì, selezionare un grafico a dispersione, andare al riquadro Formattazione oggetto visivo, espandere la scheda Generale e nella parte inferiore della scheda posizionare il dispositivo di scorrimento Campionamento ad alta densità su Sì.
Nota
Dopo l'attivazione, Power BI proverà a usare l'algoritmo Campionamento ad alta densità ogni volta che è possibile. Quando l'algoritmo non può essere usato, come ad esempio quando si posiziona un valore nell'asse di Riproduzione, l'opzione rimane attiva anche se il grafico è stato riportato all'algoritmo standard. Se quindi si rimuove un valore dall'asse di Riproduzione, o cambiano le condizioni per abilitare l'uso dell'algoritmo di campionamento ad alta densità, il grafico userà automaticamente il campionamento ad alta densità per tale grafico, perché la funzione è attiva.
Nota
I punti dati vengono raggruppati o selezionati dall'indice. La presenza di una legenda non influisce sul campionamento per l'algoritmo. Influisce solo sull'ordinamento dell'oggetto visivo.
Considerazioni e limitazioni
L'algoritmo di campionamento ad alta densità è un miglioramento importante per Power BI. L'algoritmo Campionamento ad alta densità funziona solo con le connessioni in tempo reale ai modelli basati sul servizio Power BI, ai modelli importati o a DirectQuery.