Campionamento di linee ad alta densità in Power BI
L'algoritmo di campionamento in Power BI migliora gli oggetti visivi che campionano dati ad alta densità. Ad esempio, è possibile creare un grafico a linee a partire dai risultati delle vendite dei negozi, ciascuno dei quali con più di 10.000 ricevute di vendita all'anno. Un grafico a linee di tali informazioni sulle vendite campionerebbe i dati dai dati di ogni negozio, creando un grafico a linee multiserie che quindi rappresenta i dati soggiacenti. Accertarsi di selezionare una rappresentazione significativa dei dati per illustrare la variazione delle vendite nel tempo. Si tratta di una pratica comune nella visualizzazione dei dati ad alta densità. I dettagli del campionamento dei dati ad alta densità sono descritti in questo articolo.
Nota
L'algoritmo Campionamento ad alta densità descritto in questo articolo è disponibile sia in Power BI Desktop che nel servizio Power BI.
Come funziona il campionamento di linee ad alta densità
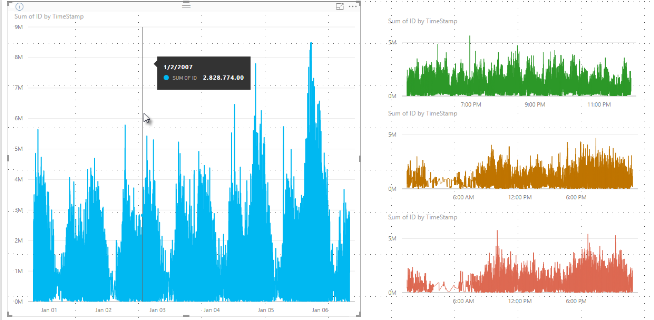
In precedenza, Power BI selezionava una raccolta di punti dati di esempio nell'intero intervallo di dati soggiacenti in modo deterministico. Ad esempio, con i dati ad alta densità su un oggetto visivo che si estendeva su un anno di calendario, potevano esserci 350 punti dati di esempio mostrati nell'oggetto visivo, ognuno dei quali era stato selezionato per garantire che l'intera gamma di dati fosse rappresentata nell'oggetto visivo. Per comprenderne il funzionamento, si immagini di tracciare il prezzo di un'azione nel periodo di un anno e di selezionare 365 punti dati per creare un oggetto visivo di grafico a linee. Vale a dire, un punto dati per ogni giorno.
In tal caso, esistono molti valori per un prezzo azionario nell'ambito di ogni giorno. Naturalmente esistono un valore massimo e minimo giornaliero, ma questi possono verificarsi in qualsiasi momento del giorno quando il mercato azionario è aperto. Per il campionamento di linee ad alta densità, se il campione di dati soggiacente è stato acquisito alle 10:30 e alle 12:00 ogni giorno, si otterrebbe uno snapshot rappresentativo dei dati soggiacenti, come ad esempio il prezzo alle 10:30 e alle 12:00. Tuttavia, lo snapshot potrebbe non acquisire gli effettivi valori massimo e minimo del prezzo azionario per il punto dati rappresentativo di quel giorno. In questa e in altre situazioni, il campionamento è rappresentativo dei dati soggiacenti, ma non sempre acquisisce i punti importanti, che in questo caso sarebbero i valori massimi e minimi del prezzo azionario giornaliero.
Per definizione, verranno campionati i dati ad alta densità per creare abbastanza rapidamente le visualizzazioni disponibili all'interattività. Troppi punti dati su un oggetto visivo possono bloccarlo e possono comportare una riduzione della visibilità delle tendenze. Il modo in cui i dati vengono campionati è ciò che comporta la creazione dell'algoritmo di campionamento per offrire la migliore esperienza di visualizzazione. In Power BI Desktop, l'algoritmo fornisce la combinazione migliore della velocità di risposta, della rappresentazione e della conservazione dei punti importanti in ogni intervallo di tempo.
Funzionamento del nuovo algoritmo di campionamento di linee
L'algoritmo per il campionamento di linee ad alta densità è disponibile per gli oggetti visivi grafico a linee e grafico ad aree con un asse x continuo.
Per un oggetto visivo ad alta densità, Power BI suddivide in modo intelligente i dati in blocchi ad alta risoluzione e quindi rileva punti importanti per rappresentare ogni blocco. Questo processo di suddivisione dei dati ad alta risoluzione è ottimizzato per garantire che il grafico risultante sia visivamente indistinguibile dal rendering di tutti i punti dati soggiacenti, ma molto più veloce e più interattivo.
Valori minimo e massimo per oggetti visivi a linee ad alta densità
Per qualsiasi visualizzazione, si applicano le limitazioni seguenti:
3.500 è il numero massimo di punti dati mostrati nella maggior parte degli oggetti visivi, indipendentemente dal numero dei punti dati o delle serie soggiacenti. Vedere le eccezioni nell'elenco seguente. Di conseguenza, se si hanno 10 serie con 350 punti dati ciascuna, l'oggetto visivo ha raggiunto il limite di punti dati complessivo massimo. Se si ha una sola serie, può contenere fino a 3.500 punti dati se il nuovo algoritmo lo ritiene il miglior campionamento per i dati soggiacenti.
Esiste un massimo di 60 serie per ciascun oggetto visivo. Se si hanno più di 60 serie, suddividere i dati e creare più oggetti visivi con massimo 60 serie ciascuno. È consigliabile usare un filtro dei dati per mostrare solo segmenti di dati (solo per alcune serie). Ad esempio, se tutte le sottocategorie sono visualizzate nella legenda, è possibile usare un filtro dei dati per filtrare in base alla categoria generale nella stessa pagina del report.
Il numero massimo di soglie dei dati è superiore per i tipi di oggetti visivi seguenti, che rappresentano eccezioni al limite di 3.500 punti dati:
- 150.000 punti dati per gli oggetti visivi R.
- 30.000 punti dati per gli oggetti visivi di Mappe di Azure.
- 10.000 punti dati per alcune configurazioni del grafico a dispersione (i grafici a dispersione per impostazione predefinita sono 3.500).
- 3.500 per tutti gli altri oggetti visivi usando il campionamento ad alta densità. Altri oggetti visivi potrebbero visualizzare più dati, ma non useranno il campionamento.
Questi parametri garantiscono che il rendering degli oggetti visivi in Power BI Desktop avvenga rapidamente, che gli oggetti rispondano all'interazione con gli utenti e non comportino un overhead di elaborazione superfluo nel computer di rendering dell'oggetto visivo.
Valutazione di punti dati rappresentativi per gli oggetti visivi a linee ad alta densità
Quando il numero di punti dati soggiacenti supera il numero massimo di punti dati che possono essere rappresentati nell'oggetto visivo, inizia un processo denominato binning. Binning suddivide i dati soggiacenti in gruppi denominati bin e quindi affina in modo iterativo tali bin.
L'algoritmo crea tanti contenitori quanti sono possibili in modo creare la granularità maggiore per l'oggetto visivo. All'interno di ogni bin, l'algoritmo rileva i valori di dati minimo e massimo per garantire che i valori importanti e significativi, come gli outlier, vengano acquisiti e mostrati nell'oggetto visivo. In base ai risultati del binning e alla valutazione successiva dei dati da parte di Power BI, viene determinata la risoluzione minima per l'asse x per l'oggetto visivo, per poter garantire la massima granularità per l'oggetto visivo.
Come accennato in precedenza, la granularità minima per ogni serie è 350 punti, la massima è 3.500 per la maggior parte degli oggetti visivi. Le eccezioni sono elencate nei paragrafi precedenti.
Ogni contenitore è rappresentato da due punti dati, che diventano i punti dati rappresentativi del contenitore nell'oggetto visivo. I punti dati sono i valori alto e basso per il bin. Selezionando i valori alto e basso, il processo di binning garantisce che qualsiasi valore elevato importante o valore basso significativo venga acquisito e sottoposto a rendering nell'oggetto visivo.
Se tutto ciò suggerisce una gran quantità di analisi per garantire di acquisire un outlier occasionale e di mostrarlo correttamente nell'oggetto visivo, è proprio così. Questo è il motivo esatto dell'algoritmo e del processo di binning.
Descrizioni comandi e campionamento di linee ad alta densità
È importante notare che tale processo di binning, che consente l'acquisizione e la visualizzazione dei valori minimo e massimo in un determinato bin, può influire sul modo in cui le descrizioni comando mostrano i dati al passaggio del mouse sui punti dati. Per illustrare come e perché ciò accade, si userà di nuovo l'esempio dei prezzi delle azioni.
Si supponga che si stia creando un oggetto visivo in base al prezzo azionario e che si stia eseguendo il confronto tra due azioni diverse, che usano entrambe Campionamento ad alta densità. I dati soggiacenti per ogni serie hanno numerosi punti dati. Ad esempio, forse si acquisisce il prezzo azionario ogni secondo del giorno. L'algoritmo di campionamento di linee ad alta densità esegue il binning per ogni serie indipendentemente dall'altra.
Ora supponiamo che il prezzo della prima azione aumenti improvvisamente alle 12:02, quindi diminuisca rapidamente dieci secondi dopo. Si tratta di un punto dati importante. Durante la creazione di bin per tale azione, il valore alto delle 12:02 sarà un punto dati rappresentativo per lo stesso.
Tuttavia, per la seconda azione, le 12:02 non corrispondevano a un valore alto né a un valore basso nel bin che comprendeva tale orario. Forse il valore alto e basso per il bin che include le 12:02 si è registrato tre minuti dopo. In questo caso, quando viene creato il grafico a linee e si passa il puntatore del mouse su 12:02, verrà visualizzato un valore nella descrizione comando per la prima azione. Questo perché è saltato alle 12:02 e tale valore è stato selezionato come punto dati elevato del bin. Tuttavia, non verrà visualizzato nessun valore nella descrizione comando alle 12:02 per il secondo titolo. Questo perché il secondo titolo non aveva un valore alto o basso per il bin che includeva 12:02. Pertanto, non sono presenti dati da mostrare per la seconda azione alle 12:02 e, di conseguenza, non verranno mostrati dati di descrizione comandi.
Questa situazione si verifica frequentemente con le descrizioni comandi. I valori alto e basso per un determinato bin potrebbero non corrispondere perfettamente ai punti di valore dell'asse x con scalabilità uniforme e la descrizione comando non mostrerà il valore.
Come abilitare il campionamento di linee ad alta densità
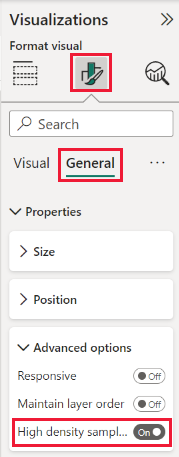
Per impostazione predefinita, l'algoritmo è Attivo. Per modificare questa impostazione, passare al riquadro Formattazione nella scheda Generale e nella parte inferiore sarà visibile il dispositivo di scorrimento Campionamento ad alta densità. Selezionare il dispositivo di scorrimento per attivare o disattivare.
Considerazioni e limitazioni
L'algoritmo per il campionamento di linee ad alta densità è un miglioramento importante per Power BI, ma è necessario tenere conto di alcuni aspetti quando si elaborano dati e valori ad alta densità.
A causa di una maggiore granularità e del processo di creazione di bin, le Descrizioni comandi potrebbero mostrare un valore solo se i dati rappresentativi sono allineati con il cursore. Per ulteriori informazioni, vedere la sezione Descrizioni comandi e campionamento di linee ad alta densità in questo articolo.
Quando le dimensioni di un'origine di dati complessiva sono troppo grandi, l'algoritmo elimina le serie (gli elementi della legenda) per soddisfare il vincolo massimo di importazione di dati.
- In questo caso, il nuovo algoritmo ordina la legenda delle serie alfabeticamente, iniziando dal basso l'elenco di elementi della legenda in ordine alfabetico fino a quando non raggiunge il massimo di importazione di dati e non importa serie aggiuntive.
Quando un set di dati soggiacenti contiene più di 60 serie, il numero massimo di serie, l'algoritmo ordina le serie alfabeticamente ed elimina le serie oltre la sessantesima in ordine alfabetico.
Se i valori nei dati non sono di tipo numerico o data/ora, Power BI non userà il nuovo algoritmo e ripristinerà l'algoritmo precedente (campionamento non ad alta densità).
L'impostazione Mostra elementi senza dati non è supportata con il nuovo algoritmo.
L'algoritmo non è supportato quando si usa una connessione dinamica a un modello ospitato in SQL Server Analysis Services (versione 2016 o precedenti). È supportato nei modelli ospitati in Power BI o Azure Analysis Services.