Esercitazione: Usare le funzioni di aggregazione
Si applica a: ✅Microsoft Fabric✅Azure Esplora dati✅ Azure Monitor✅Microsoft Sentinel
Le funzioni di aggregazione consentono di raggruppare e combinare dati da più righe in un valore di riepilogo. Il valore di riepilogo dipende dalla funzione scelta, ad esempio un conteggio, un valore massimo o medio.
Questa esercitazione illustra come:
Gli esempi in questa esercitazione usano la StormEvents tabella, disponibile pubblicamente nel cluster della Guida. Per esplorare con i propri dati, creare un cluster gratuito.
Gli esempi in questa esercitazione usano la StormEvents tabella, disponibile pubblicamente nei dati di esempio di Analisi meteo.
Questa esercitazione si basa sulle basi della prima esercitazione, gli operatori comuni di Learn.
Prerequisiti
Per eseguire le query seguenti, è necessario un ambiente di query con accesso ai dati di esempio. È possibile usare uno dei seguenti elementi:
- Un account Microsoft o un'identità utente di Microsoft Entra per accedere al cluster della Guida
- Un account Microsoft o un'identità utente di Microsoft Entra
- Un'area di lavoro infrastruttura con capacità abilitata per Microsoft Fabric
Usare l'operatore summarize
L'operatore summarize è essenziale per eseguire aggregazioni sui dati. L'operatore summarize raggruppa le righe in base alla by clausola e quindi usa la funzione di aggregazione fornita per combinare ogni gruppo in una singola riga.
Trovare il numero di eventi in base allo stato usando summarize con la funzione di aggregazione count .
StormEvents
| summarize TotalStorms = count() by State
Output
| Provincia | TotalStorms |
|---|---|
| TEXAS | 4701 |
| KANSAS | 3166 |
| IOWA | 2337 |
| ILLINOIS | 2022 |
| MISSOURI | 2016 |
| ... | ... |
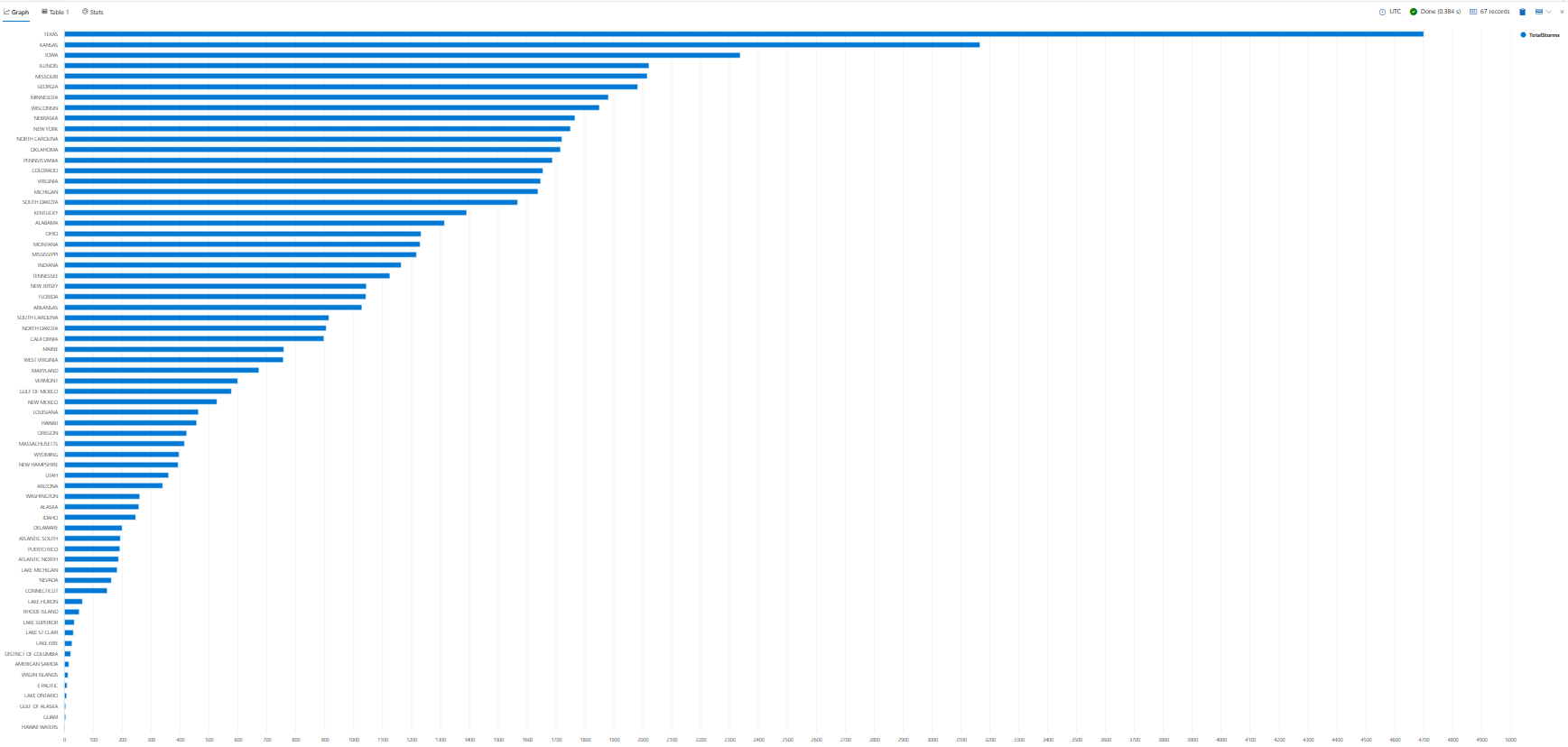
Visualizzare i risultati delle query
La visualizzazione dei risultati delle query in un grafico o in un grafico consente di identificare modelli, tendenze ed outlier nei dati. È possibile eseguire questa operazione con l'operatore render .
In tutta l'esercitazione verranno illustrati esempi di come usare render per visualizzare i risultati. Per il momento, si userà render per visualizzare i risultati della query precedente in un grafico a barre.
StormEvents
| summarize TotalStorms = count() by State
| render barchart
Conteggio condizionale delle righe
Quando si analizzano i dati, usare countif() per contare le righe in base a una condizione specifica per comprendere il numero di righe che soddisfano i criteri specificati.
La query seguente usa countif() per contare le tempeste che hanno causato danni. La query usa quindi l'operatore top per filtrare i risultati e visualizzare gli stati con la quantità più elevata di danni alle colture causati da tempeste.
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
Output
| Provincia | StormsWithCropDamage |
|---|---|
| IOWA | 359 |
| NEBRASKA | 201 |
| MISSISSIPPI | 105 |
| NORTH CAROLINA | 82 |
| MISSOURI | 78 |
Raggruppare i dati in contenitori
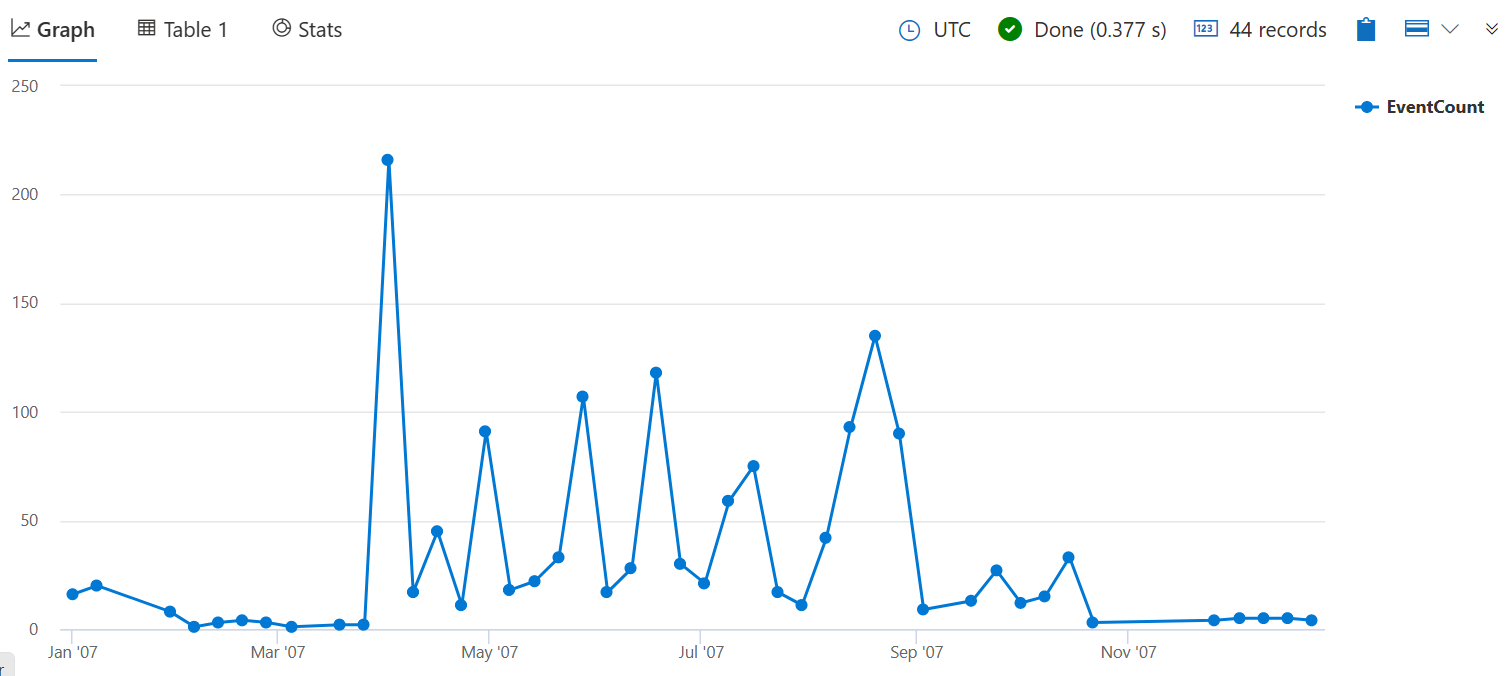
Per aggregare in base a valori numerici o temporali, è necessario innanzitutto raggruppare i dati in contenitori usando la funzione bin(). L'uso bin() di consente di comprendere in che modo i valori vengono distribuiti all'interno di un determinato intervallo ed eseguire confronti tra periodi diversi.
La query seguente conta il numero di tempeste che hanno causato danni alle colture per ogni settimana nel 2007. L'argomento 7d rappresenta una settimana, perché la funzione richiede un valore timepan valido.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
Output
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
Aggiungere | render timechart alla fine della query per visualizzare i risultati.
Nota
bin() è simile alla floor() funzione in altri linguaggi di programmazione. Riduce ogni valore al multiplo più vicino del modulo fornito e consente di summarize assegnare le righe ai gruppi.
Calcolare min, max, avg e sum
Per altre informazioni sui tipi di tempeste che causano danni alle colture, calcolare il danno di ritaglio min(),max()e avg() per ogni tipo di evento e quindi ordinare il risultato in base al danno medio.
Si noti che è possibile usare più funzioni di aggregazione in un singolo summarize operatore per produrre diverse colonne calcolate.
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
Output
| EventType | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| Brina/Ghiaccio | 568600000 | 3000 | 9106087.5954198465 |
| Wildfire | 21000000 | 10000 | 7268333.333333333 |
| Siccità | 700000000 | 2000 | 6763977.8761061952 |
| Alluvione | 500000000 | 1000 | 4844925.23364486 |
| Vento di tempesta | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
I risultati della query precedente indicano che gli eventi Frost/Freeze hanno causato la maggior parte dei danni di ritaglio in media. Tuttavia, la query bin() ha mostrato che gli eventi con danni alle colture si sono verificati principalmente nei mesi estivi.
Usare sum() per controllare il numero totale di colture danneggiate anziché la quantità di eventi che hanno causato alcuni danni, come nella count() query bin() precedente.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
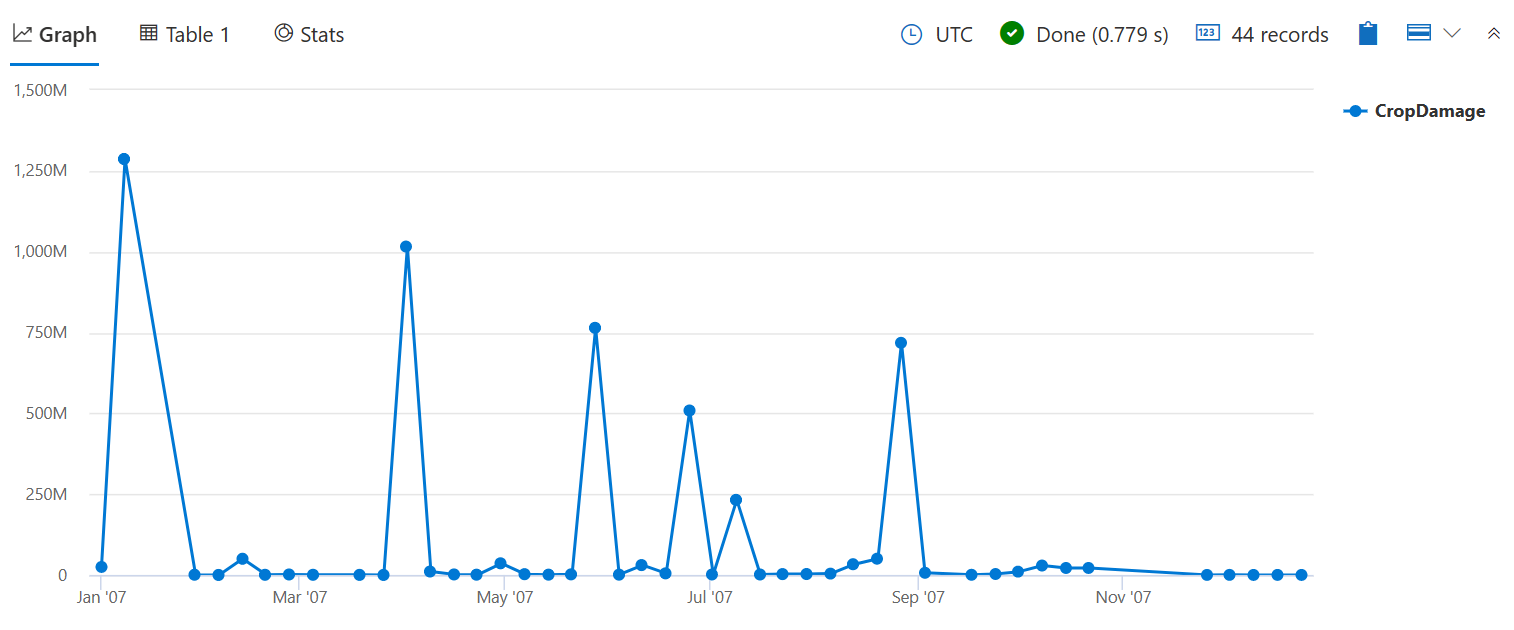
Ora si può vedere un picco di danni alle colture nel mese di gennaio, che probabilmente era dovuto a Frost/Freeze.
Suggerimento
Usare minif(), maxif(), avgif()e sumif() per eseguire aggregazioni condizionali, come quando nella sezione conteggio condizionale delle righe .
Calcolare le percentuali
Il calcolo delle percentuali consente di comprendere la distribuzione e la proporzione di valori diversi all'interno dei dati. Questa sezione illustra due metodi comuni per calcolare le percentuali con il Linguaggio di query Kusto (KQL).
Calcolare la percentuale in base a due colonne
Usare count() e countif per trovare la percentuale di eventi di tempesta che hanno causato danni alle colture in ogni stato. In primo luogo, contare il numero totale di tempeste in ogni stato. Quindi, contare il numero di tempeste che hanno causato danni alle colture in ogni stato.
Usare quindi l'estensione per calcolare la percentuale tra le due colonne dividendo il numero di tempeste con danni alle colture per il numero totale di tempeste e moltiplicando per 100.
Per assicurarsi di ottenere un risultato decimale, usare la funzione todouble() per convertire almeno uno dei valori di conteggio integer in un valore double prima di eseguire la divisione.
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
Output
| Provincia | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| IOWA | 2337 | 359 | 15.36 |
| NEBRASKA | 1766 | 201 | 11.38 |
| MISSISSIPPI | 1218 | 105 | 8.62 |
| NORTH CAROLINA | 1721 | 82 | 4.76 |
| MISSOURI | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
Nota
Quando si calcolano le percentuali, convertire almeno uno dei valori interi nella divisione con todouble() o toreal(). In questo modo si garantisce che non si ottengano risultati troncati a causa della divisione integer. Per altre informazioni, vedere Regole di tipo per le operazioni aritmetiche.
Calcolare la percentuale in base alle dimensioni della tabella
Per confrontare il numero di tempeste in base al tipo di evento con il numero totale di tempeste nel database, salvare prima il numero totale di tempeste nel database come variabile. Le istruzioni Let vengono usate per definire le variabili all'interno di una query.
Poiché le istruzioni di espressione tabulare restituiscono risultati tabulari , usare la funzione toscalar() per convertire il risultato tabulare della count() funzione in un valore scalare. Il valore numerico può quindi essere usato nel calcolo percentuale.
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
Output
| EventType | EventCount | Percentuale |
|---|---|---|
| Vento di tempesta | 13015 | 22.034673077574237 |
| Grandine | 12711 | 21.519994582331627 |
| Piena improvvisa | 3688 | 6.2438627975485055 |
| Siccità | 3616 | 6.1219652592015716 |
| Clima invernale | 3349 | 5.669928554498358 |
| ... | ... | ... |
Estrarre valori univoci
Usare make_set() per trasformare una selezione di righe in una tabella in una matrice di valori univoci.
La query seguente usa make_set() per creare una matrice dei tipi di evento che causano decessi in ogni stato. La tabella risultante viene quindi ordinata in base al numero di tipi storm in ogni matrice.
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
Output
| Provincia | StormTypesWithDeaths |
|---|---|
| CALIFORNIA | ["Vento temporale","Surf elevato","Freddo/Vento freddo","Forte vento","Rip Current","Calore","Calore eccessivo","Tempesta di polvere","Marea bassa astronomica","Nebbia densa","Meteo invernale"] |
| TEXAS | ["Flash Flood","Thunderstorm Wind","Tornado","Lightning","Flood","Ice Storm","Winter Weather","Rip Current","Excessive Heat","Dense Fog","Hurricane (Typhoon)","Cold/Wind Chill"] |
| OKLAHOMA | ["Flash Flood","Tornado","Freddo/Vento freddo","Tempesta d'inverno","Neve pesante","Calore eccessivo","Tempesta di ghiaccio","Clima invernale","Nebbia densa"] |
| NEW YORK | ["Flood","Lightning","Thunderstorm Wind","Flash Flood","Winter Weather","Ice Storm","Extreme Cold/Wind Chill","Winter Storm","Heavy Snow"] |
| KANSAS | ["Vento temporale","Pioggia pesante","Tornado","Flood","Flood Flash","Lightning","Heavy Snow","Winter Weather","Blizzard"] |
| ... | ... |
Dati del bucket per condizione
La funzione case() raggruppa i dati in bucket in base alle condizioni specificate. La funzione restituisce l'espressione di risultato corrispondente per il primo predicato soddisfatto o l'espressione else finale se nessuno dei predicati viene soddisfatto.
Questo esempio raggruppa gli stati in base al numero di lesioni correlate alle tempeste sostenute dai cittadini.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
Output
| Provincia | LesioniCount | LesioniBucket |
|---|---|---|
| ALABAMA | 494 | Grande |
| ALASKA | 0 | Nessuna ferita |
| SAMOA AMERICANE | 0 | Nessuna ferita |
| ARIZONA | 6 | Piccolo |
| ARKANSAS | 54 | Grande |
| ATLANTICO SETTENTRIONALE | 15 | Medio |
| ... | ... | ... |
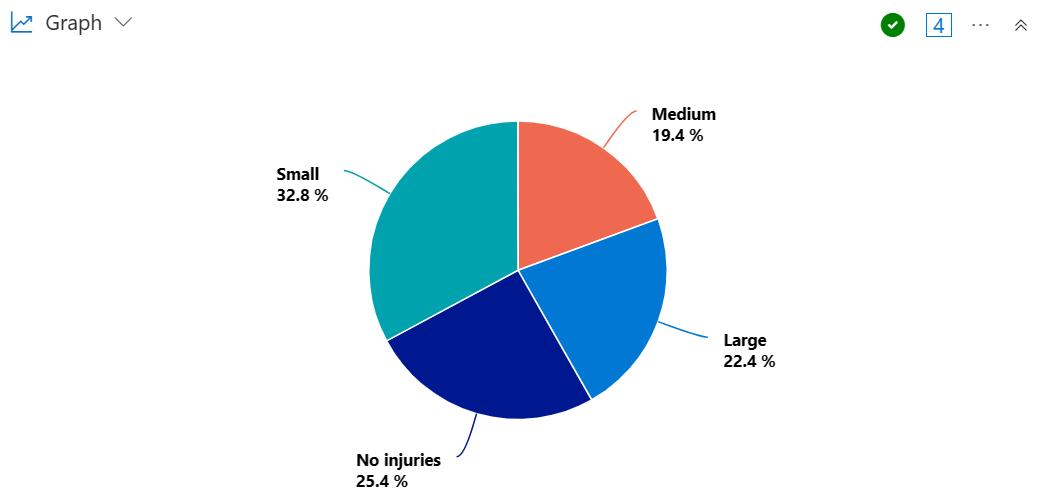
Creare un grafico a torta per visualizzare la proporzione di stati che hanno subito tempeste, causando un numero elevato, medio o ridotto di lesioni.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
Eseguire aggregazioni su una finestra temporale scorrevole
Nell'esempio seguente viene illustrato come riepilogare le colonne usando una finestra scorrevole.
La query calcola il danno minimo, massimo e medio delle proprietà dei tornado, delle inondazioni e degli incendi tramite una finestra scorrevole di sette giorni. Ogni record nel set di risultati aggrega i sette giorni precedenti e i risultati contengono un record per ogni giorno del periodo di analisi.
Ecco una spiegazione dettagliata della query:
- Binare ogni record in un singolo giorno rispetto a
windowStart. - Aggiungere sette giorni al valore bin per impostare la fine dell'intervallo per ogni record. Se il valore non è compreso nell'intervallo di
windowStartewindowEnd, modificare il valore di conseguenza. - Creare una matrice di sette giorni per ogni record, a partire dal giorno corrente del record.
- Espandere la matrice dal passaggio 3 con mv-expand per duplicare ogni record a sette record con intervalli di un giorno tra di essi.
- Eseguire le aggregazioni per ogni giorno. A causa del passaggio 4, questo passaggio riepiloga effettivamente i sette giorni precedenti.
- Escludere i primi sette giorni dal risultato finale perché non esiste un periodo di lookback di sette giorni per loro.
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
Output
La tabella dei risultati seguente viene troncata. Per visualizzare l'output completo, eseguire la query.
| Timestamp: | EventType | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | Tornado | 0 | 30000 | 6905 |
| 2007-07-08T00:00:00Z | Alluvione | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | Tornado | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | Alluvione | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | Tornado | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | Alluvione | 0 | 200000 | 12263 |
| 2007-07-10T00:00:00Z | Wildfire | 0 | 200000 | 11694 |
| ... | ... | ... |
Passaggio successivo
Ora che si ha familiarità con gli operatori di query e le funzioni di aggregazione comuni, passare all'esercitazione successiva per informazioni su come unire dati da più tabelle.