Inserire dati in OneLake e analizzarli con Azure Databricks
Questa guida illustra le procedure per:
Creare una pipeline in un'area di lavoro e inserire i dati in OneLake in formato Delta.
Leggere e modificare una tabella Delta in OneLake con Azure Databricks.
Prerequisiti
Prima di iniziare, è necessario avere:
Un'area di lavoro con un elemento Lakehouse.
Un’area di lavoro Premium di Azure Databricks. Solo le aree di lavoro Premium di Azure Databricks supportano il pass-through delle credenziali di Microsoft Entra. Quando si crea il cluster, abilitare il pass-through delle credenziali di Azure Data Lake Storage nelle Opzioni avanzate.
Un set di dati di esempio.
Inserire dati e modificare la tabella Delta
Andare sul lakehouse nel servizio Power BI e selezionare Ottieni dati e quindi selezionare Nuova pipeline di dati.
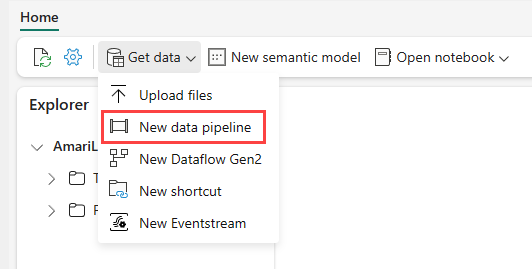
Nella richiesta Nuova pipeline, immettere un nome per la nuova pipeline e poi selezionare Crea.
Per questo esercizio, selezionare i dati di esempio NYC Taxi - Green come origine dati e quindi selezionare Avanti.
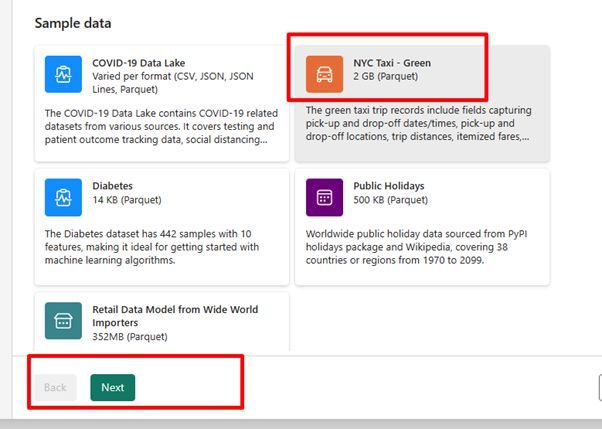
Nella schermata Anteprima, selezionare Avanti.
Per la destinazione dei dati, selezionare il nome del lakehouse da usare per archiviare i dati della tabella di OneLake Delta. È possibile scegliere un lakehouse esistente o crearne uno nuovo.
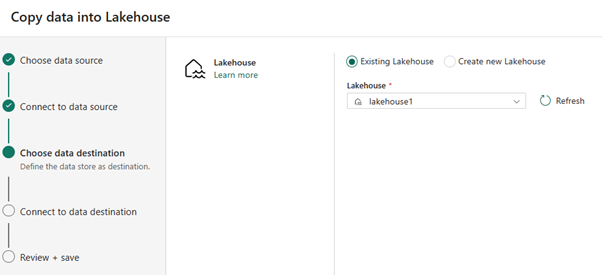
Selezionare la posizione in cui archiviare l'output. Scegliere Tabelle come cartella radice e immettere "nycsample" come nome della tabella.
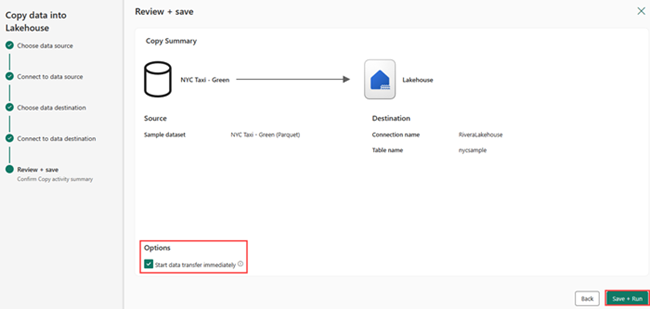
Nella schermata Rivedi e salva, selezionare Avvia trasferimento dei dati immediatamente e poi selezionare Salva ed Esegui.
Al termine del lavoro, andare al lakehouse e visualizzare la tabella Delta elencata nella cartella /Tables.
Fare clic con il pulsante destro del mouse sul nome della tabella creata, selezionare Proprietà e copiare il percorso Azure Blob File System (ABFS).
Aprire il notebook di Azure Databricks. Leggere la tabella Delta in OneLake.
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)Aggiornare i dati della tabella Delta modificando un valore del campo.
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;