Trasformare i dati con Apache Spark ed eseguire query con SQL
Questa guida illustra le procedure per:
Caricare i dati in OneLake con Esplora file di OneLake.
Usare un notebook di Fabric per leggere i dati su OneLake e riscriverli come tabella Delta.
Analizzare e trasformare i dati con Spark usando un notebook di Fabric.
Eseguire una query su una copia dei dati in OneLake con SQL.
Prerequisiti
Prima di iniziare, è necessario eseguire queste operazioni:
Scaricare e installare Esplora file di OneLake.
Creare un'area di lavoro con un elemento Lakehouse.
Scaricare il set di dati WideWorldImportersDW. È possibile usare Azure Storage Explorer per connettersi a
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_citye scaricare il set di file CSV. In alternativa, è possibile usare i propri dati csv e aggiornare i dettagli in base alle esigenze.
Nota
Caricare o creare sempre un collegamento ai dati Delta-Parquet direttamente nella sezione Tabelle del lakehouse. Non annidare le tabelle in sottocartelle nella sezione Tabelle perché il lakehouse non le riconoscerà come tabella e le etichetterà come Non identificate.
Caricare, leggere, analizzare ed eseguire query sui dati
In Esplora file di OneLake passare al lakehouse e nella directory
/Filescreare una sottodirectory denominatadimension_city.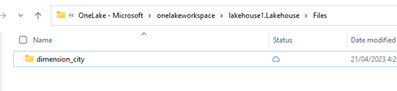
Copiare i file CSV di esempio nella directory
/Files/dimension_citydi OneLake usando Esplora file di OneLake File.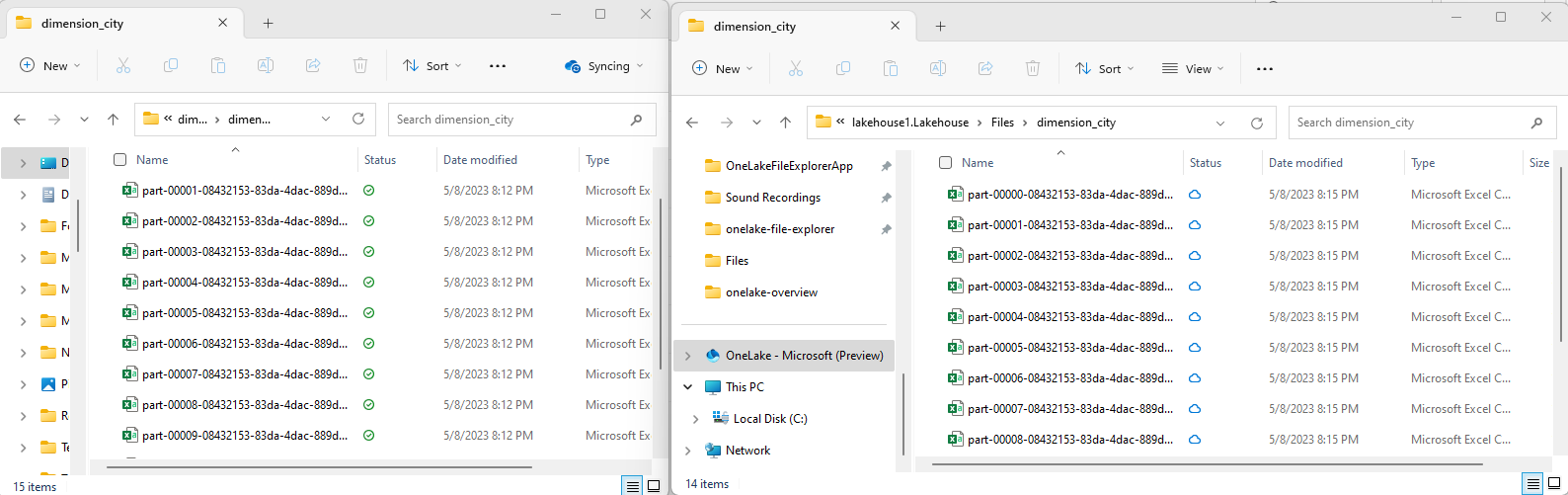
Passare al lakehouse nel servizio Power BI e visualizzare i file.
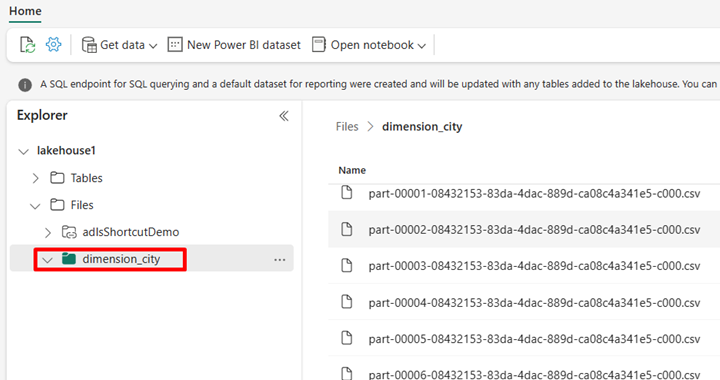
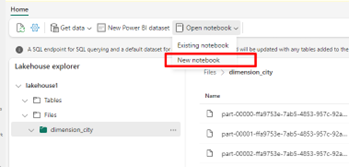
Selezionare Apri notebook, quindi Nuovo notebook per creare un notebook.
Usando il notebook di Fabric, convertire i file CSV in formato Delta. Il frammento di codice seguente legge i dati dalla directory
/Files/dimension_citycreata dall'utente e li converte in una tabella Deltadim_city.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")Per visualizzare la nuova tabella, aggiornare la visualizzazione della directory
/Tables.
Eseguire query sulla tabella con SparkSQL nello stesso notebook di Fabric.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Modificare la tabella Delta aggiungendo una nuova colonna denominata newColumn con tipo di dati intero. Impostare il valore 9 per tutti i record di questa colonna appena aggiunta.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;È inoltre possibile accedere a qualsiasi tabella Delta in OneLake tramite un endpoint di analisi SQL. Un endpoint di analisi SQL fa riferimento alla stessa copia fisica della tabella Delta in OneLake e offre l'esperienza T-SQL. Selezionare l'endpoint di analisi SQL per lakehouse1 e quindi selezionare Nuova query SQL per eseguire query sulla tabella usando T-SQL.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
