Istruzioni: Servizi di Azure AI - Rilevamento anomalie multivariato
Questa ricetta illustra come usare i servizi SynapseML e Azure per intelligenza artificiale in Apache Spark per il rilevamento di anomalie multivariate. Il rilevamento delle anomalie multivariate consente il rilevamento delle anomalie tra molte variabili o serie temporali, tenendo conto di tutte le correlazioni e le dipendenze tra le diverse variabili. In questo scenario si usa SynapseML per eseguire il training di un modello per il rilevamento delle anomalie multivariate usando i servizi di intelligenza artificiale di Azure e quindi si usa per il modello per dedurre anomalie multivariate all'interno di un set di dati contenente misurazioni sintetiche da tre sensori IoT.
Importante
A partire dal 20 settembre 2023 non sarà possibile creare nuove risorse di Rilevamento anomalie. Il servizio Rilevamento anomalie verrà ritirato il 1° ottobre 2026.
Per altre informazioni su Rilevamento anomalie di Azure AI, vedere questa pagina di documentazione.
Prerequisiti
- Una sottoscrizione di Azure: creare un account gratuitamente
- Collegare il notebook a un lakehouse. Sul lato sinistro, selezionare Aggiungi per aggiungere un lakehouse esistente o creare un lakehouse.
Attrezzaggio
Seguire le istruzioni per creare una risorsa Anomaly Detector usando il portale di Azure o in alternativa, è anche possibile usare l'interfaccia della riga di comando di Azure per creare questa risorsa.
Dopo aver configurato un oggetto Anomaly Detector, è possibile esplorare i metodi di gestione dei dati di vari moduli. Il catalogo dei servizi all'interno di Intelligenza artificiale di Azure offre diverse opzioni: Visione, Riconoscimento vocale, Lingua, Ricerca Web, Decisione, Traduzione e Intelligence per i documenti.
Creare una risorsa Rilevamento anomalie
- Nella portale di Azure selezionare Crea nel gruppo di risorse e quindi digitare Rilevamento anomalie. Selezionare la risorsa di Rilevamento anomalie.
- Assegnare alla risorsa un nome e usare idealmente la stessa area del resto del gruppo di risorse. Usare le opzioni predefinite per il resto, quindi selezionare Rivedi e crea e quindi Crea.
- Dopo aver creato la risorsa Rilevamento anomalie, aprirla e selezionare il pannello
Keys and Endpointsnel riquadro di spostamento a sinistra. Copiare la chiave per la risorsa Rilevamento anomalie nella variabile di ambienteANOMALY_API_KEYoppure archiviarla nella variabileanomalyKey.
Creare una risorsa account di archiviazione
Per salvare i dati intermedi, è necessario creare un account Archiviazione BLOB di Azure. All'interno dell'account di archiviazione creare un contenitore per l'archiviazione dei dati intermedi. Prendere nota del nome del contenitore e copiare il stringa di connessione in tale contenitore. Sarà necessario in un secondo momento per popolare la variabile containerName e la variabile di ambiente BLOB_CONNECTION_STRING.
Immettere le chiavi del servizio
Per iniziare, configurare le variabili di ambiente per le chiavi del servizio. La cella successiva imposta le variabili di ambiente ANOMALY_API_KEY e BLOB_CONNECTION_STRING in base ai valori archiviati nell'insieme di credenziali delle chiavi di Azure. Se si esegue questa esercitazione nel proprio ambiente, assicurarsi di impostare queste variabili di ambiente prima di procedere.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Ora, consente di leggere le variabili di ambiente ANOMALY_API_KEY e BLOB_CONNECTION_STRING e di impostare le variabili containerName e location.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Prima di tutto ci si connette all'account di archiviazione in modo che il rilevamento anomalie possa salvare i risultati intermedi in tale posizione:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Verranno importati tutti i moduli necessari.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
A questo punto, leggere i dati di esempio in un dataframe Spark.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
È ora possibile creare un oggetto estimator usato per eseguire il training del modello. Vengono specificate le ore di inizio e di fine per i dati di training. Si specificano anche le colonne di input da usare e il nome della colonna che contiene i timestamp. Infine, si specifica il numero di punti dati da usare nella finestra temporale scorrevole di rilevamento anomalie e si imposta il stringa di connessione sull'account Archiviazione BLOB di Azure.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Ora che è stato creato estimator, è possibile adattarlo ai dati:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Quando abbiamo chiamato .show(5) nella cella precedente, ci hanno mostrato le prime cinque righe nel dataframe. I risultati erano tutti null perché non erano all'interno della finestra di inferenza.
Per visualizzare i risultati solo per i dati dedotti, è possibile selezionare le colonne necessarie. È quindi possibile ordinare le righe nel dataframe in ordine crescente e filtrare il risultato in modo da visualizzare solo le righe incluse nell'intervallo della finestra di inferenza. In questo caso inferenceEndTime è uguale all'ultima riga del dataframe, in modo da poterla ignorare.
Infine, per poter tracciare meglio i risultati, consente di convertire il dataframe Spark in un dataframe Pandas.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Formattare la colonna contributors che archivia il punteggio di contributo da ogni sensore alle anomalie rilevate. La cella successiva formatta questi dati e suddivide il punteggio di contributo di ogni sensore nella propria colonna.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Ottimo. Sono ora disponibili i punteggi di contributo dei sensori 1, 2 e 3 rispettivamente nelle colonne series_0, series_1 e series_2.
Eseguire la cella successiva per tracciare i risultati. Il parametro minSeverity specifica la gravità minima delle anomalie da tracciare.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
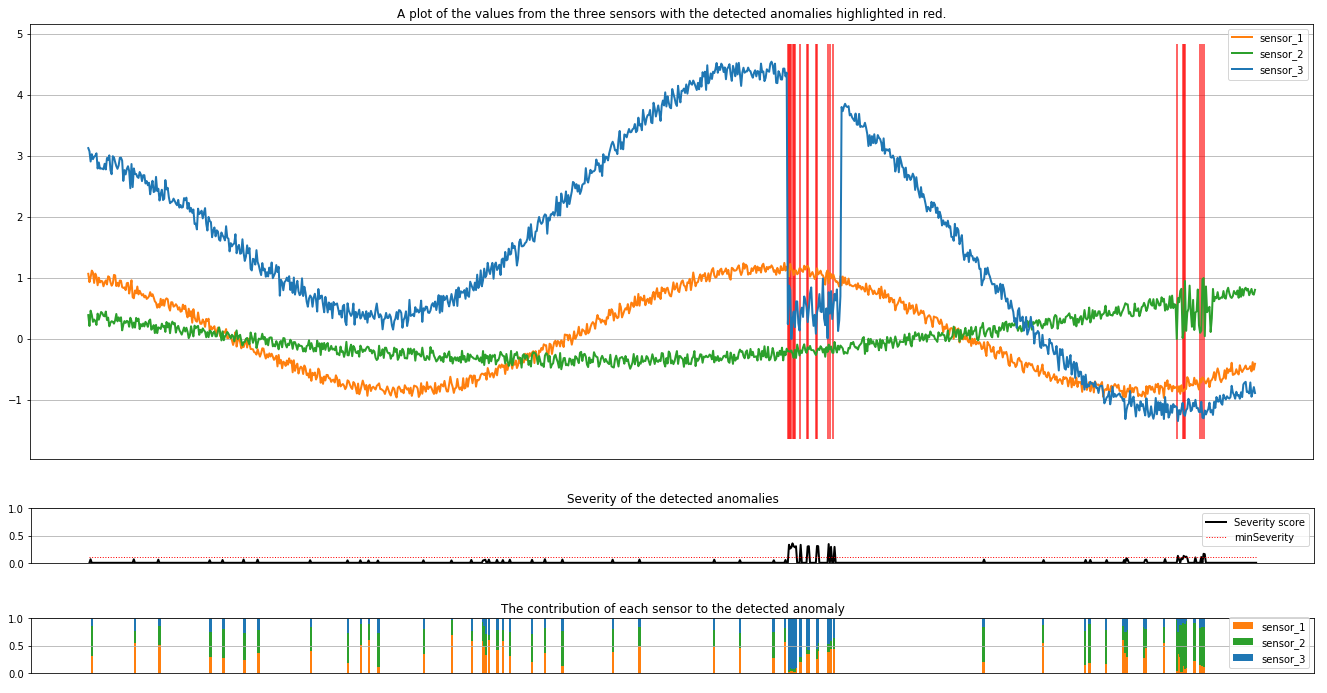
I tracciati mostrano i dati non elaborati dei sensori (all'interno della finestra di inferenza) in arancione, verde e blu. Le linee verticali rosse nella prima figura mostrano le anomalie rilevate con una gravità maggiore o uguale a minSeverity.
Il secondo grafico mostra il punteggio di gravità di tutte le anomalie rilevate, con la soglia minSeverity visualizzata nella linea rossa punteggiata.
Infine, l'ultimo tracciato mostra il contributo dei dati di ogni sensore alle anomalie rilevate. Ci aiuta a diagnosticare e comprendere la causa più probabile di ogni anomalia.