Esercitazione per Lakehouse: preparare e trasformare i dati nel lakehouse
In questa esercitazione si usano notebook con il runtimeSpark per trasformare e preparare dati non elaborati nel lakehouse.
Prerequisiti
Se non esiste un lakehouse che contiene dati, è necessario:
Preparazione dei dati
Nei passaggi precedenti dell'esercitazione sono stati inseriti dati non elaborati dall'origine alla sezione File del lakehouse. Ora è possibile trasformare i dati e prepararli per la creazione di tabelle Delta.
Scaricare i notebook dalla cartella Codice sorgente dell’esercitazione Lakehouse.
Dall'area di lavoro, seleziona Importa>Notebook>Da questo computer.
Selezionare Importa notebook nella sezione Nuovo nella parte superiore della pagina di destinazione.
Selezionare Carica nel riquadro Stat importazione che si apre sul lato destro della schermata.
Selezionare tutti i notebook scaricati nel primo passaggio di questa sezione.
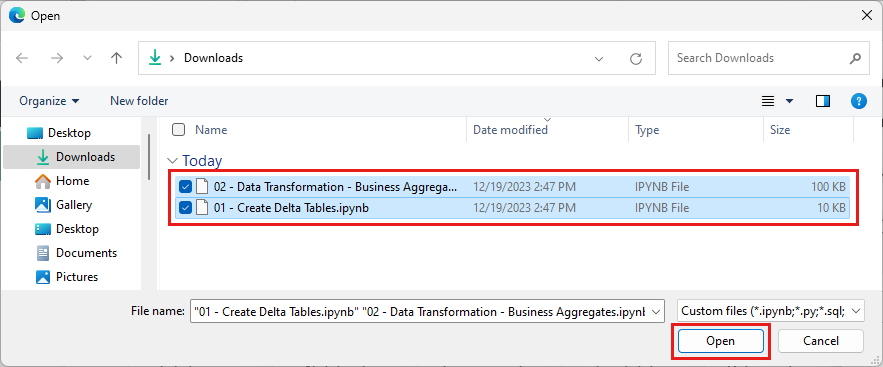
Selezionare Apri. Viene visualizzata una notifica che indica lo stato dell'importazione nell'angolo superiore destro della finestra del browser.
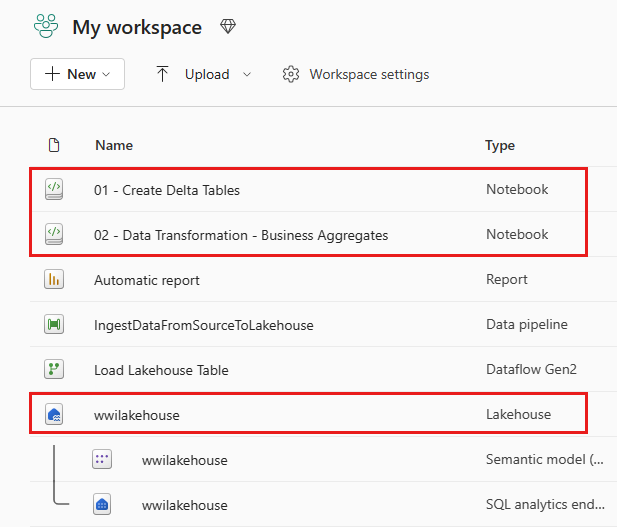
Al termine dell'importazione, passare alla visualizzazione degli elementi dell'area di lavoro e visualizzare i notebook appena importati. Selezionare il lakehouse wwilakehouse per aprirlo.
Una volta aperto il lakehouse wwilakehouse, selezionare Apri notebook>Noteboox esistente dal menu di spostamento in alto.
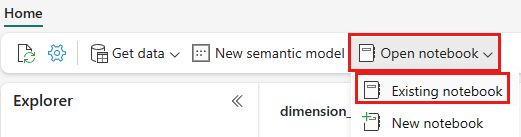
Nell'elenco dei notebook esistenti, selezionare il notebook 01 - Crea tabelle delta e scegliere Apri.
Nel notebook aperto in Esplora lakehouser si vede che il notebook è già collegato al lakehouse aperto.
Nota
Fabric offre la funzionalità V-Order per scrivere file Delta Lake ottimizzati. V-Order spesso migliora di tre o quattro volte la compressione e fino a 10 volte l'accelerazione delle prestazioni sui file Delta Lake non ottimizzati. Spark in Fabric ottimizza in modo dinamico le partizioni durante la generazione di file con dimensioni predefinite di 128 MB. Le dimensioni del file di destinazione possono essere modificate in base ai requisiti del carico di lavoro usando le configurazioni.
Con la funzionalità ottimizza scrittura, il motore di Apache Spark riduce il numero di file scritti e mira ad aumentare le dimensioni dei singoli file dei dati scritti.
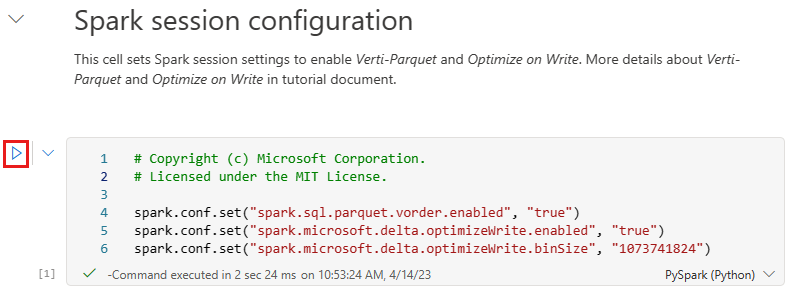
Prima di scrivere dati come tabelle Delta Lake nella sezione Tabelle del lakehouse, si usano due funzionalità di Fabric (V-order e Ottimizza scrittura) per la scrittura ottimizzata dei dati e per migliorare le prestazioni di lettura. Per abilitare queste funzionalità nella sessione, impostare queste configurazioni nella prima cella del notebook.
Per avviare il notebook ed eseguire tutte le celle in sequenza, selezionare Esegui tutto sulla barra multifunzione superiore (sotto Home). In alternativa, per eseguire codice solo da una cella specifica, selezionare l'icona Esegui che appare a sinistra della cella al passaggio del mouse oppure premere MAIUSC+INVIO sulla tastiera mentre il controllo si trova nella cella.
Quando si esegue una cella, non è necessario specificare i dettagli del cluster o del pool di Spark sottostanti, perché Fabric li fornisce tramite il pool live. Ogni area di lavoro di Fabric include un pool di Spark predefinito denominato pool live. Ciò implica che quando si creano notebook, non è necessario preoccuparsi di specificare dettagli di cluster o configurazioni di Spark. Quando si esegue il primo comando del notebook, il pool live è attivo e viene eseguito in pochi secondi. La sessione Spark viene stabilita e inizia a eseguire il codice. L'esecuzione successiva del codice è quasi istantanea in questo notebook mentre la sessione Spark è attiva.
Successivamente, si leggono i dati non elaborati dalla sezione File del lakehouse e si aggiungono altre colonne per parti di data diverse come parte della trasformazione. Infine, si usa l'API Partition By Spark per partizionare i dati prima di scriverli in formato tabella Delta in base alle colonne della parte di dati appena create (Anno e Trimestre).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Dopo il caricamento delle tabelle dei fatti, è possibile passare al caricamento dei dati per il resto delle dimensioni. La cella seguente crea una funzione per leggere dati non elaborati dalla sezione File del lakehouse per ognuno dei nomi tabella passati come parametro. Crea quindi un elenco di tabelle delle dimensioni. Infine, scorre l'elenco delle tabelle e crea una tabella Delta per ogni nome tabella letto dal parametro di input. Tenere presente che lo script elimina la colonna denominata
Photoin questo esempio, perché la colonna non viene usata.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Per convalidare le tabelle create, fare clic con il pulsante destro del mouse e selezionare Aggiorna nel lakehouse wwilakehouse. Appaiono le tabelle.
Tornare alla visualizzazione degli elementi dell'area di lavoro e selezionare il lakehouse wwilakehouse per aprirlo.
Ora aprire il secondo notebook. Nella visualizzazione del lakehouse, selezionare Apri notebook>Notebook esistente dalla barra multifunzione.
Nell'elenco dei notebook esistenti, selezionare il notebook 02 - Trasformazione dati - Business per aprirlo.
Nel notebook aperto in Esplora lakehouser si vede che il notebook è già collegato al lakehouse aperto.
Un'organizzazione potrebbe avere data engineer che lavorano con Scala/Python e altri data engineer che usano SQL (Spark SQL o T-SQL), tutti che lavorano alla stessa copia dei dati. Fabric consente a questi diversi gruppi, con esperienze e preferenze diverse, di lavorare e collaborare. I due diversi approcci trasformano e generano aggregazioni aziendali. È possibile scegliere quello adatto o mescolare e abbinare questi approcci in base alle preferenze senza compromettere le prestazioni:
Approccio 1: usare PySpark per unire e aggregare i dati per generare aggregazioni aziendali. Questo approccio è preferibile per gli utenti con un background di programmazione (Python o PySpark).
Approccio 2: usare Spark SQL per unire e aggregare i dati per generare aggregazioni aziendali. Questo approccio è preferibile per gli utenti con background SQL che passano a Spark.
Approccio 1 (sale_by_date_city): usare PySpark per unire e aggregare i dati per generare aggregazioni aziendali. Con il codice seguente si creano tre DataFrame Spark diversi, ognuno dei quali fa riferimento a una tabella Delta esistente. Unire quindi queste tabelle usando i DataFrame, eseguire il raggruppamento per generare aggregazioni, rinominare alcune colonne e infine scriverla come tabella Delta nella sezione Tabelle del lakehouse per rendere persistenti i dati.
In questa cella vengono creati tre DataFrame Spark diversi, ognuno dei quali fa riferimento a una tabella Delta esistente.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Aggiungere il codice seguente alla stessa cella per unire queste tabelle usando i DataFrame creati in precedenza. Raggruppare per generare l'aggregazione, rinominare alcune colonne e infine scriverla come tabella Delta nella sezione Tabelle del lakehouse.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Approccio 2 (sale_by_date_employee): usare Spark SQL per unire e aggregare i dati per generare aggregazioni aziendali. Con il codice seguente si crea una vista Spark temporanea unendo tre tabelle, si esegue il raggruppamento per generare l'aggregazione e si rinominano alcune colonne. Infine, si legge dalla vista Spark temporanea e si scrive come tabella Delta nella sezione Tabelle del lakehouse per rendere persistenti i dati.
In questa cella viene creata una vista Spark temporanea unendo tre tabelle, si esegue il raggruppamento per generare l'aggregazione e si rinominano alcune colonne.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCIn questa cella si legge dalla vista Spark temporanea creata nella cella precedente e infine la si scrive come tabella Delta nella sezione Tabelle del lakehouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Per convalidare le tabelle create, fare clic con il pulsante destro del mouse e selezionare Aggiorna nel lakehouse wwilakehouse. Appaiono le tabelle di aggregazione.
I due approcci producono un risultato simile. Per ridurre al minimo la necessità di apprendere una nuova tecnologia o compromettere le prestazioni, scegliere l'approccio più adatto al proprio background e alle proprie preferenze.
Si può notare che si stanno scrivendo dati come file Delta Lake. La funzionalità di individuazione e registrazione automatica delle tabelle di Fabric li preleva e li registra nel metastore. Non è necessario chiamare in modo esplicito le istruzioni CREATE TABLE per creare tabelle da usare con SQL.