Che cos'è la pipeline di distribuzione?
Nota
Gli articoli di questa sezione descrivono come distribuire il contenuto nell'app. Per il controllo della versione, vedere la documentazione sull'integrazione di Git.
Lo strumento di pipeline di distribuzione di Microsoft Fabric fornisce ai creatori di contenuti un ambiente di produzione in cui possono collaborare con altri utenti per gestire il ciclo di vita dei contenuti dell'organizzazione. Le pipeline di distribuzione consentono ai creatori di sviluppare e testare il contenuto nel servizio prima che venga utilizzato dagli utenti. Vedere l'elenco completo dei Tipi di elementi supportati che è possibile distribuire.
Nota
- La nuova interfaccia utente della pipeline di distribuzione è attualmente in anteprima. Per attivare o usare la nuova interfaccia utente, vedere Iniziare a usare la nuova interfaccia utente.
- Alcuni degli elementi per le pipeline di distribuzione sono in anteprima. Per altre informazioni, vedere l'elenco degli elementi supportati.
Informazioni su come usare le pipeline di distribuzione
Per informazioni su come usare lo strumento pipeline di distribuzione, seguire questi collegamenti.
Creare e gestire una pipeline di distribuzione: un modulo Learn che illustra passo per passo come creare una pipeline di distribuzione.
Introduzione alle pipeline di distribuzione: un articolo che illustra come creare una pipeline e funzioni chiave come la distribuzione, il confronto del contenuto in fasi diverse e la creazione di regole di distribuzione.
Elementi supportati
Quando si distribuisce contenuto da una fase della pipeline a un'altra, il contenuto copiato può contenere gli elementi seguenti:
- Attivatore
- Dashboard
- Pipeline didati (anteprima)
- flussi di dati gen2(anteprima)
- datamarts(anteprima)
- ambiente (anteprima)
- Eventhouse e databaseKQL (anteprima)
- EventStream (anteprima)
- Lakehouse(anteprima)
del database con mirroring (anteprima) - Notebook
- delle app dell'organizzazione (anteprima)
- Report impaginati
- Flussi di dati di Power BI
- Report (basati su modelli semantici supportati)
- Modelli semantici (che hanno origine da file con estensione pbix e non sono set di dati PUSH)
- Database SQL (anteprima)
- Magazzini (anteprima)
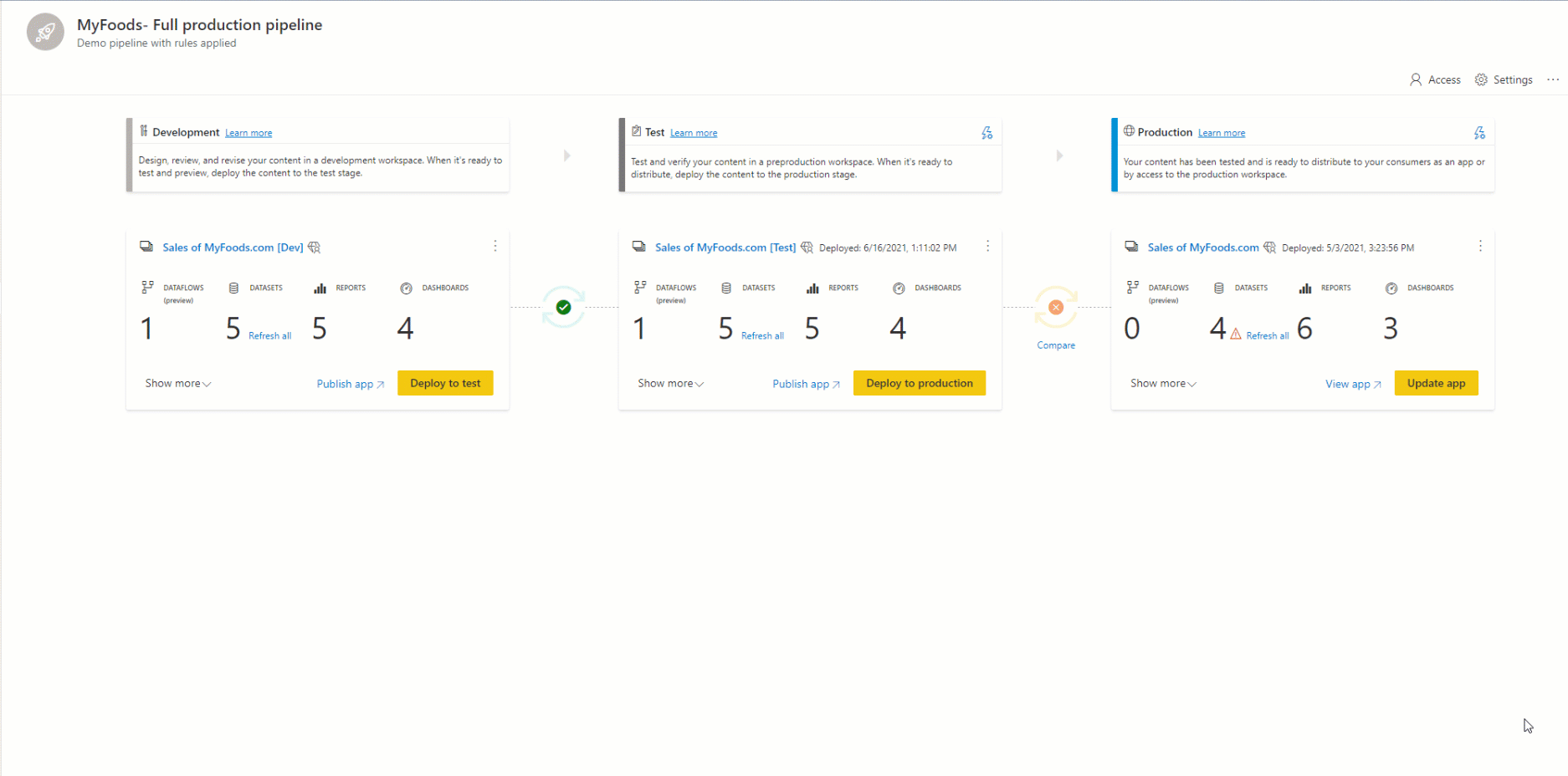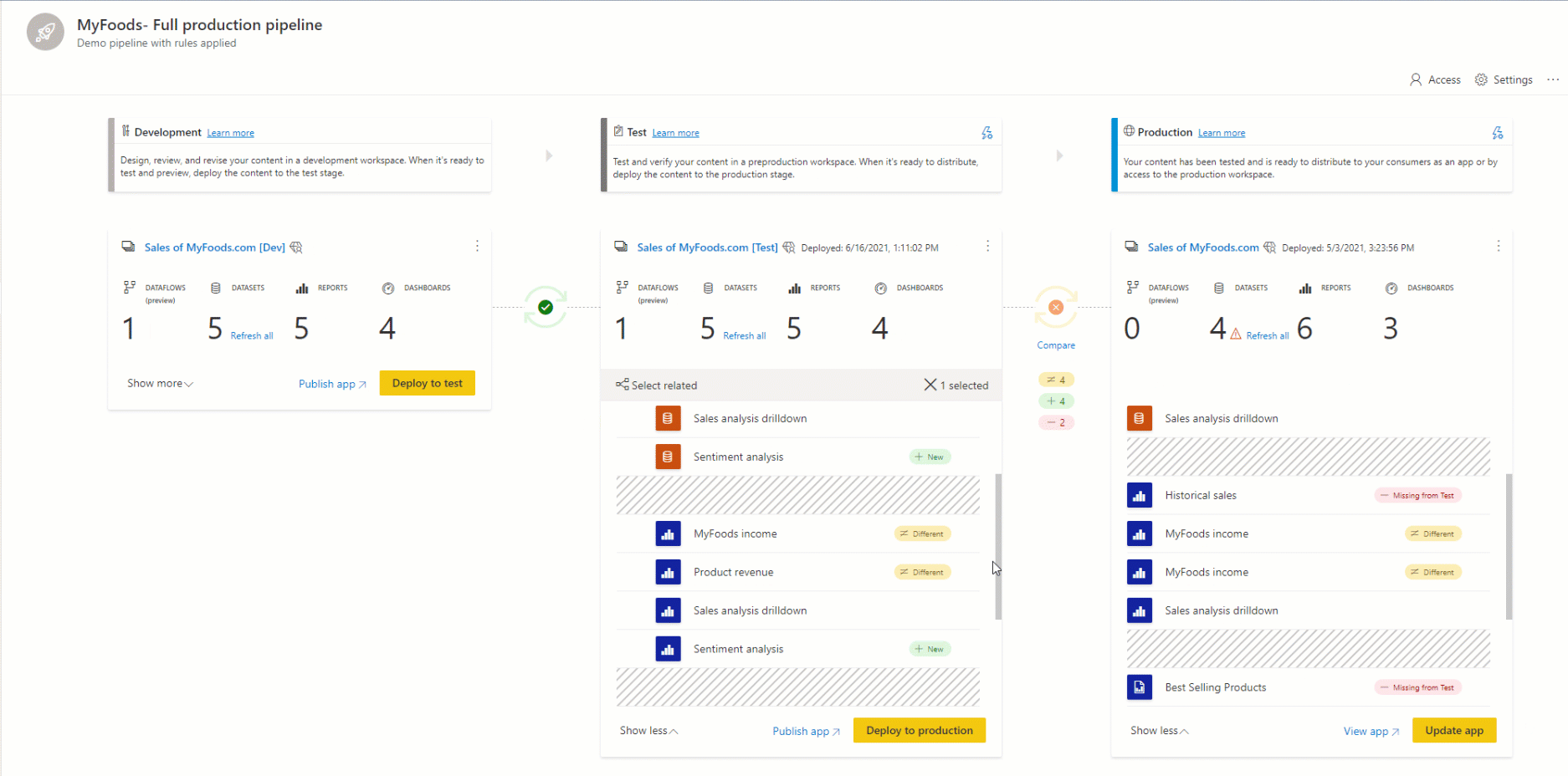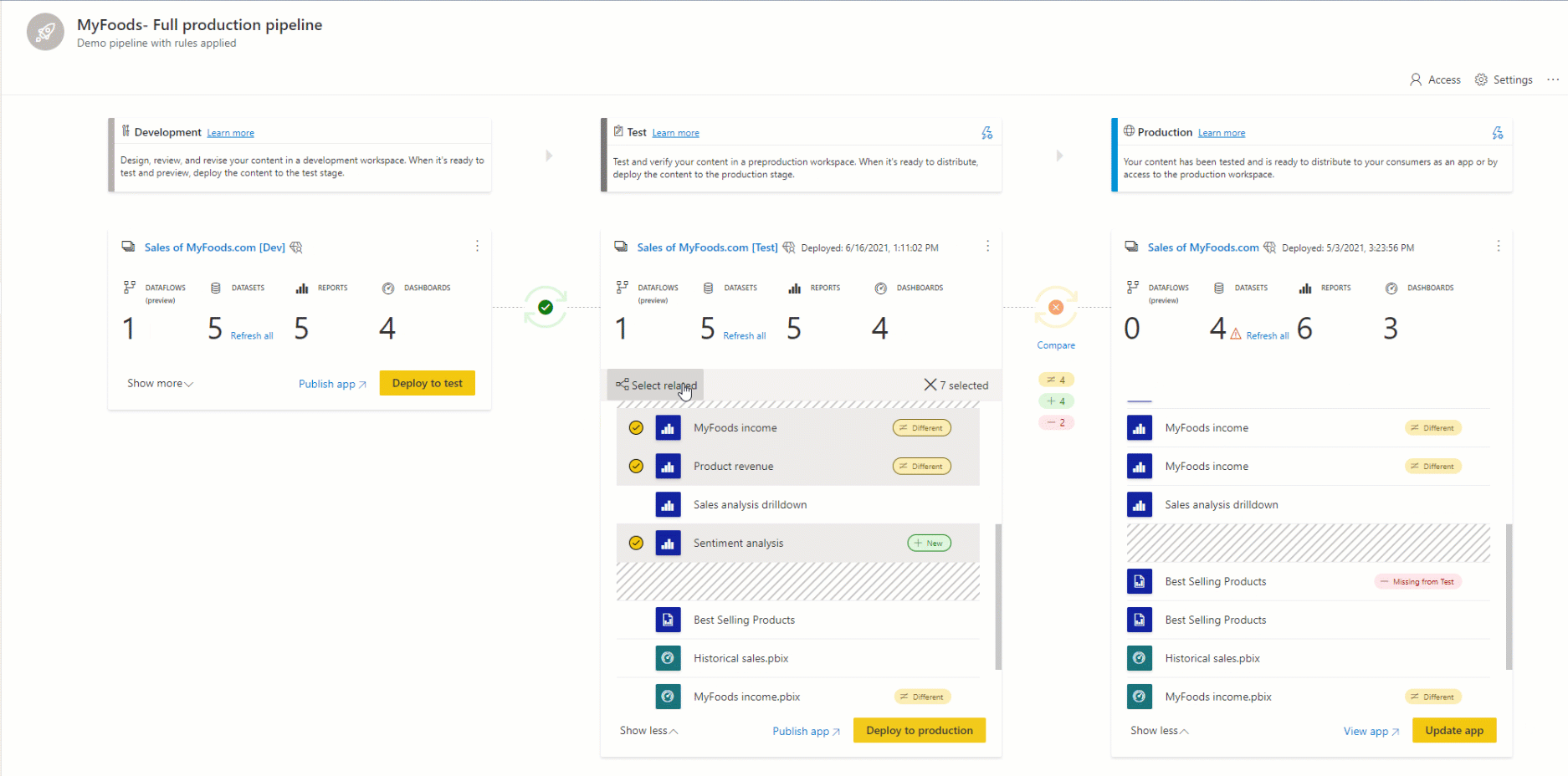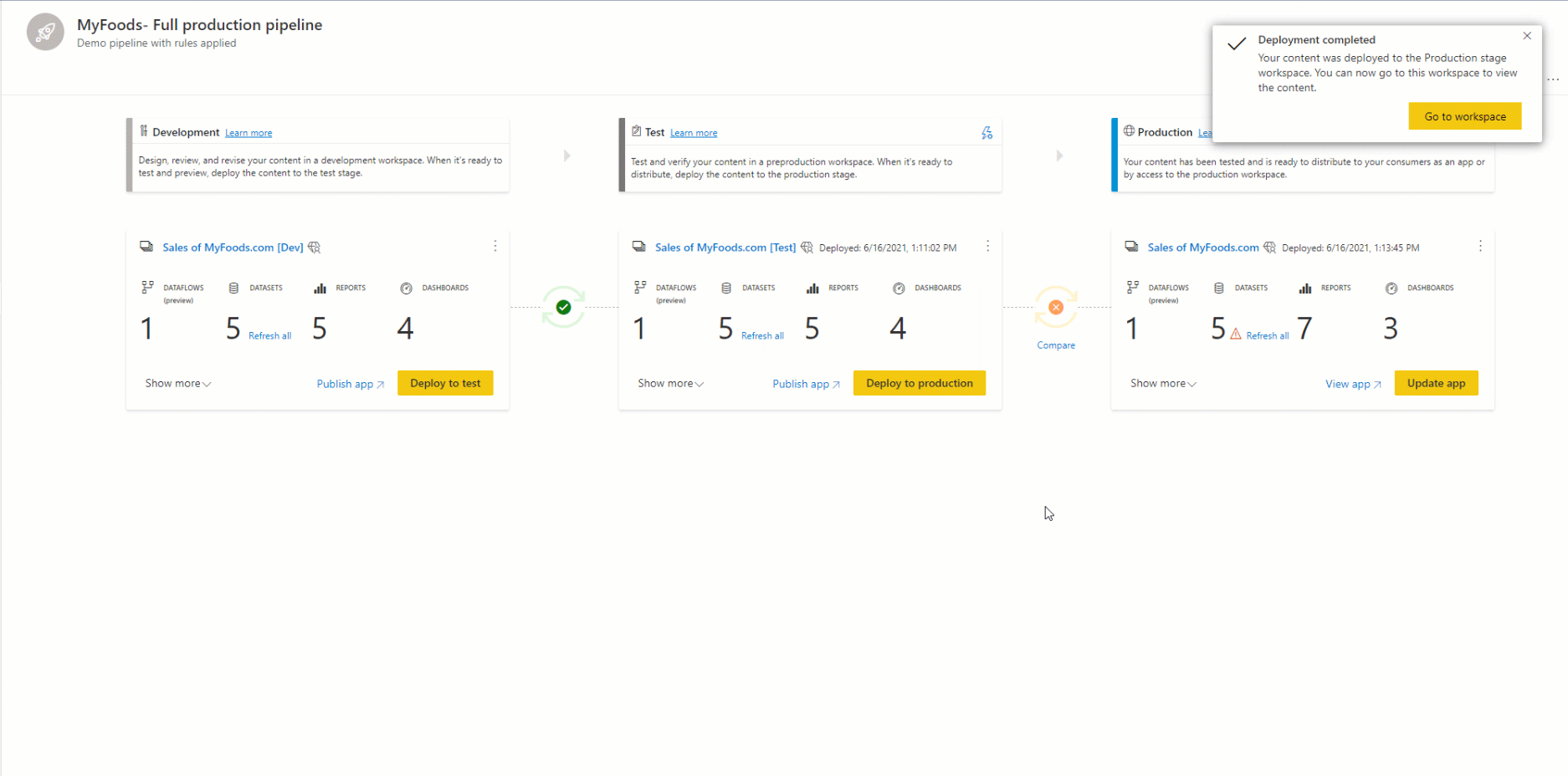
Struttura della pipeline
Si decide il numero di fasi desiderate nella pipeline di distribuzione. È possibile avere un numero di fasi compreso tra due e dieci. Quando si crea una pipeline, le tre fasi tipiche per impostazione predefinita vengono fornite come punto di partenza, ma è possibile aggiungere, eliminare o rinominare le fasi in base alle proprie esigenze. Indipendentemente dal numero di fasi disponibili, i concetti generali sono gli stessi:
-
La prima fase della distribuzione è la posizione in cui si caricano nuovi contenuti con i colleghi creatori. È possibile progettare build e sviluppare qui o in una fase diversa.
-
Dopo avere apportato tutte le modifiche necessarie al contenuto, si è pronti per passare alla fase di test. Caricare il contenuto modificato in modo che possa essere spostato in questa fase di test. Di seguito sono riportati tre esempi di operazioni possibili nell'ambiente di test:
Condividere il contenuto con tester e revisori
Caricare ed eseguire test con volumi di dati più elevati
Testare l'app per vedere come viene visualizzata dagli utenti finali
-
Dopo aver testato il contenuto, usare la fase di produzione per condividere la versione finale del contenuto con gli utenti aziendali all'interno dell'organizzazione.
Associazione elemento
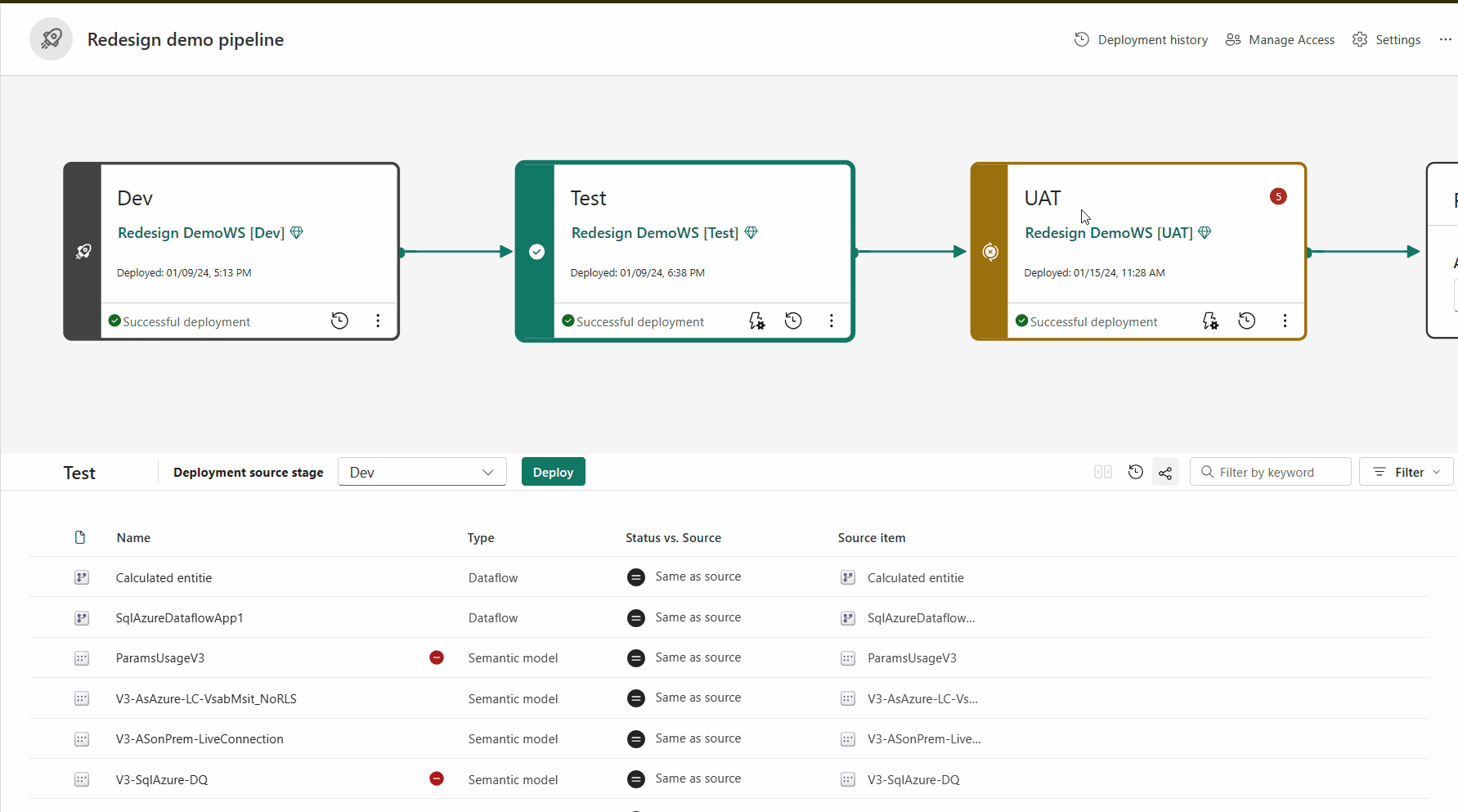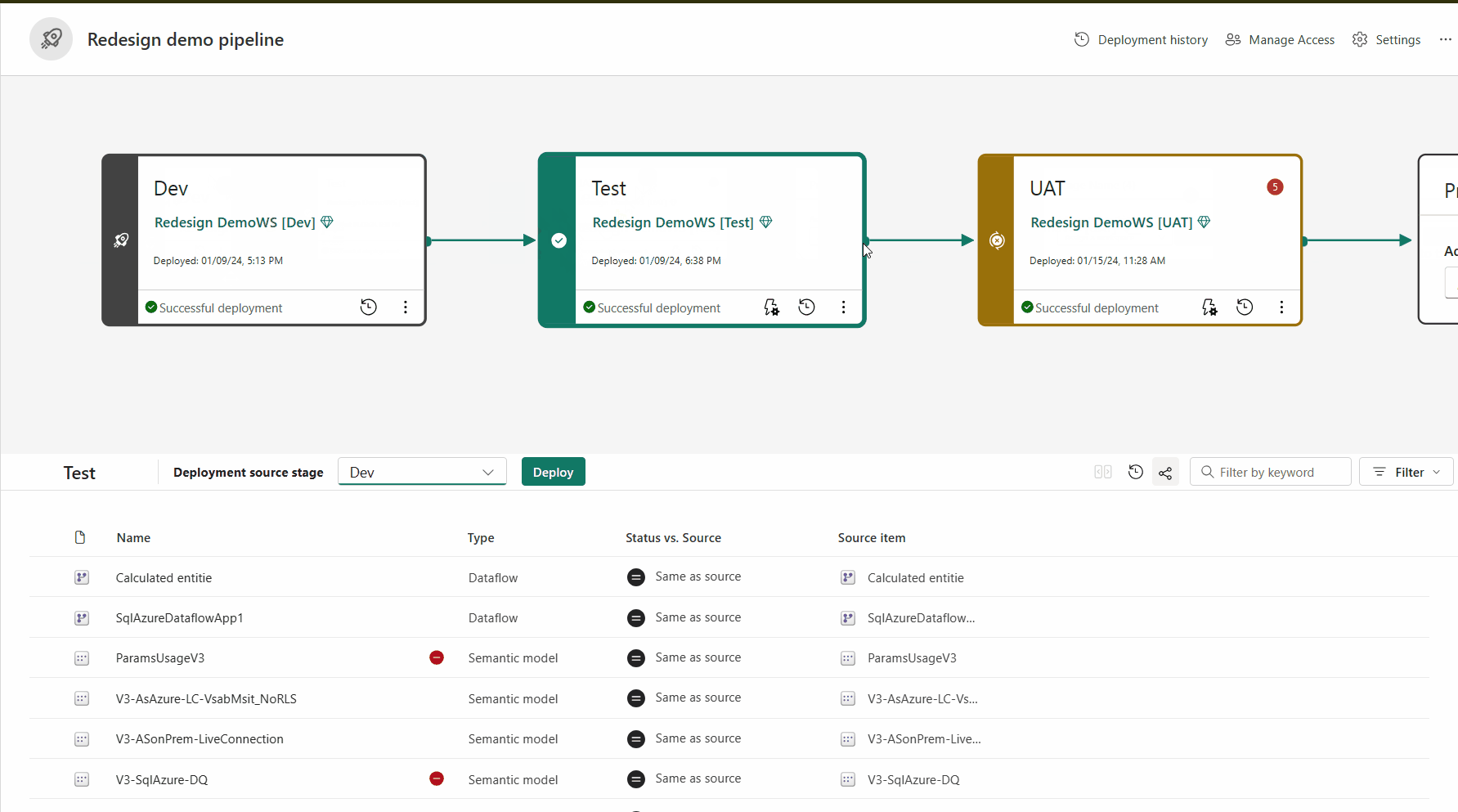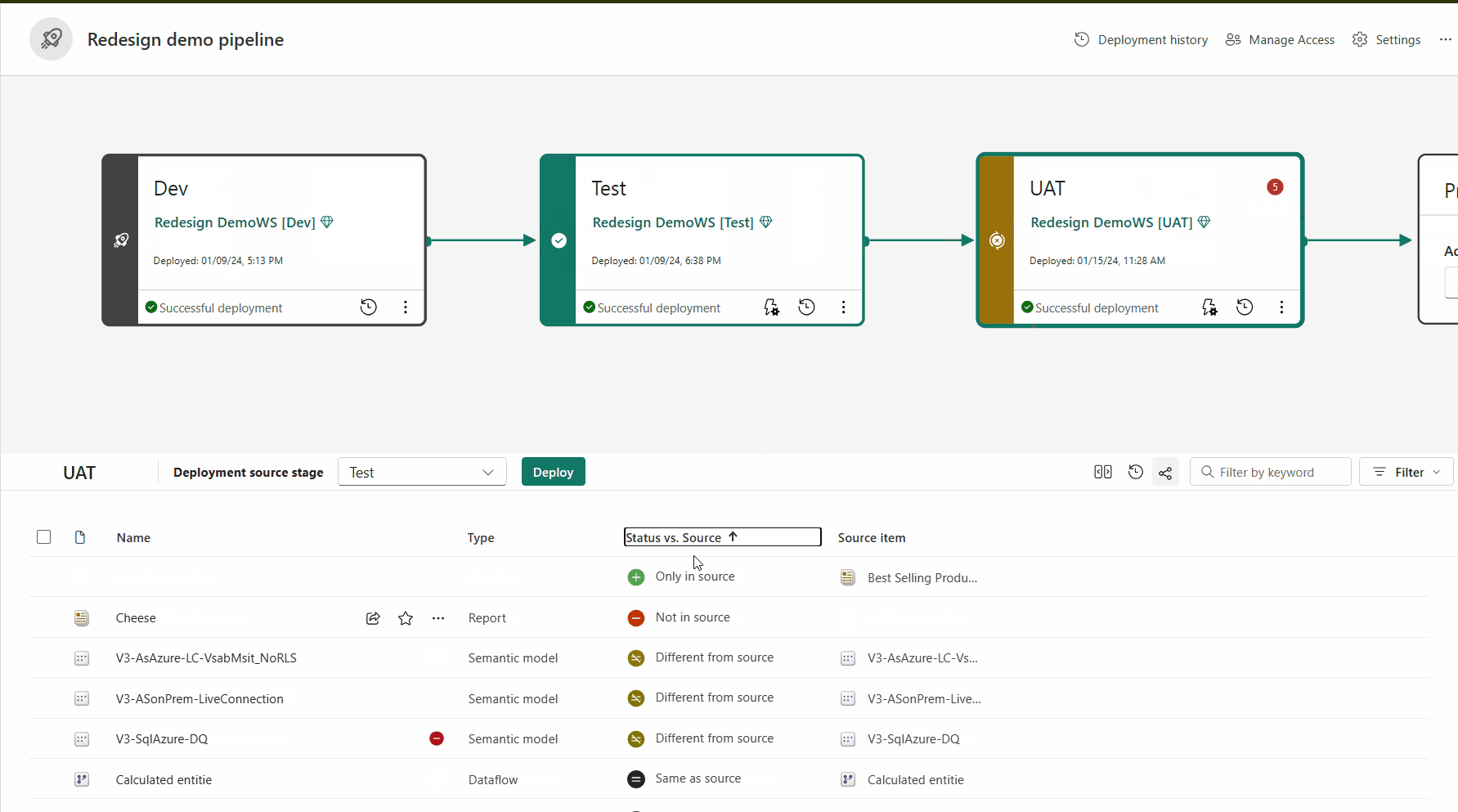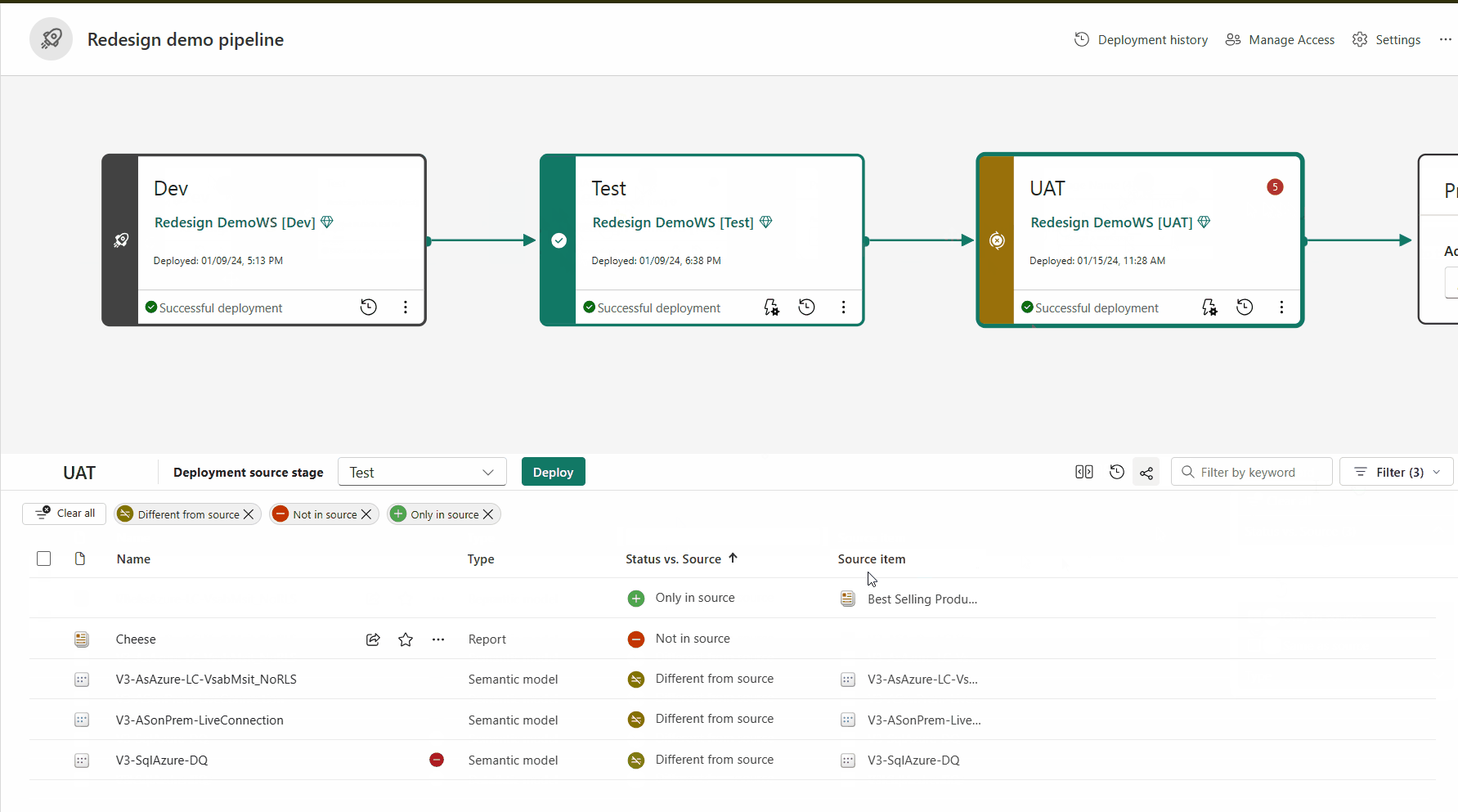
L'associazione è il processo in base al quale un elemento (ad esempio un report, un dashboard o un modello semantico) in una fase della pipeline di distribuzione è associato allo stesso elemento nella fase adiacente. L'associazione si verifica quando si assegna un'area di lavoro a una fase di distribuzione o quando si distribuisce nuovo contenuto non associato da una fase a un'altra (una distribuzione pulita).
È importante comprendere il funzionamento dell'associazione, per comprendere quando gli elementi vengono copiati, quando vengono sovrascritti e quando una distribuzione ha esito negativo quando si usa la funzione di distribuzione.
Se gli elementi non sono associati, anche se sembrano essere uguali (hanno lo stesso nome, tipo e cartella), non si sovrascrivono in una distribuzione. Viene invece creata una copia duplicata e abbinata all'elemento nella fase precedente.
Gli elementi associati vengono visualizzati nella stessa riga nell'elenco di contenuto della pipeline. Gli elementi non associati vengono visualizzati in una riga da soli:
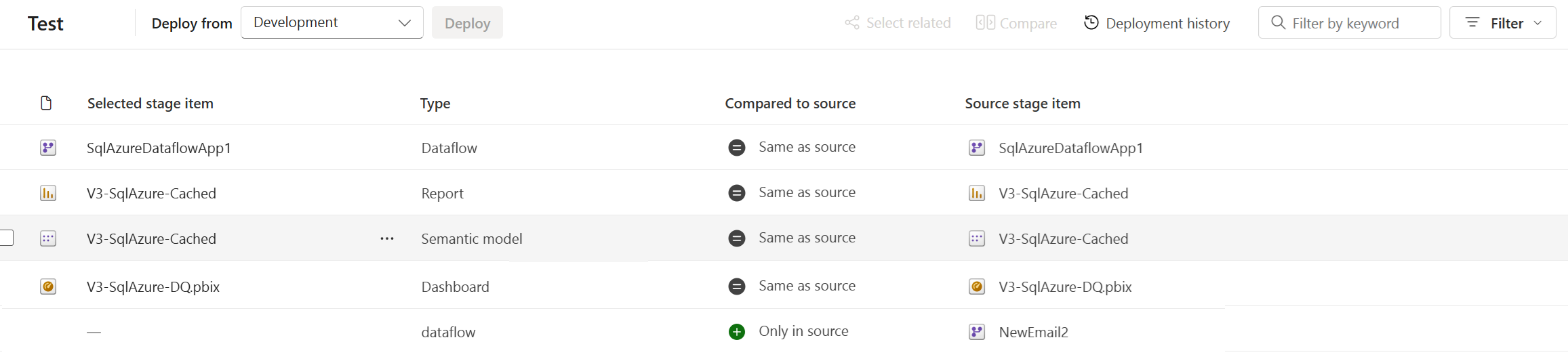
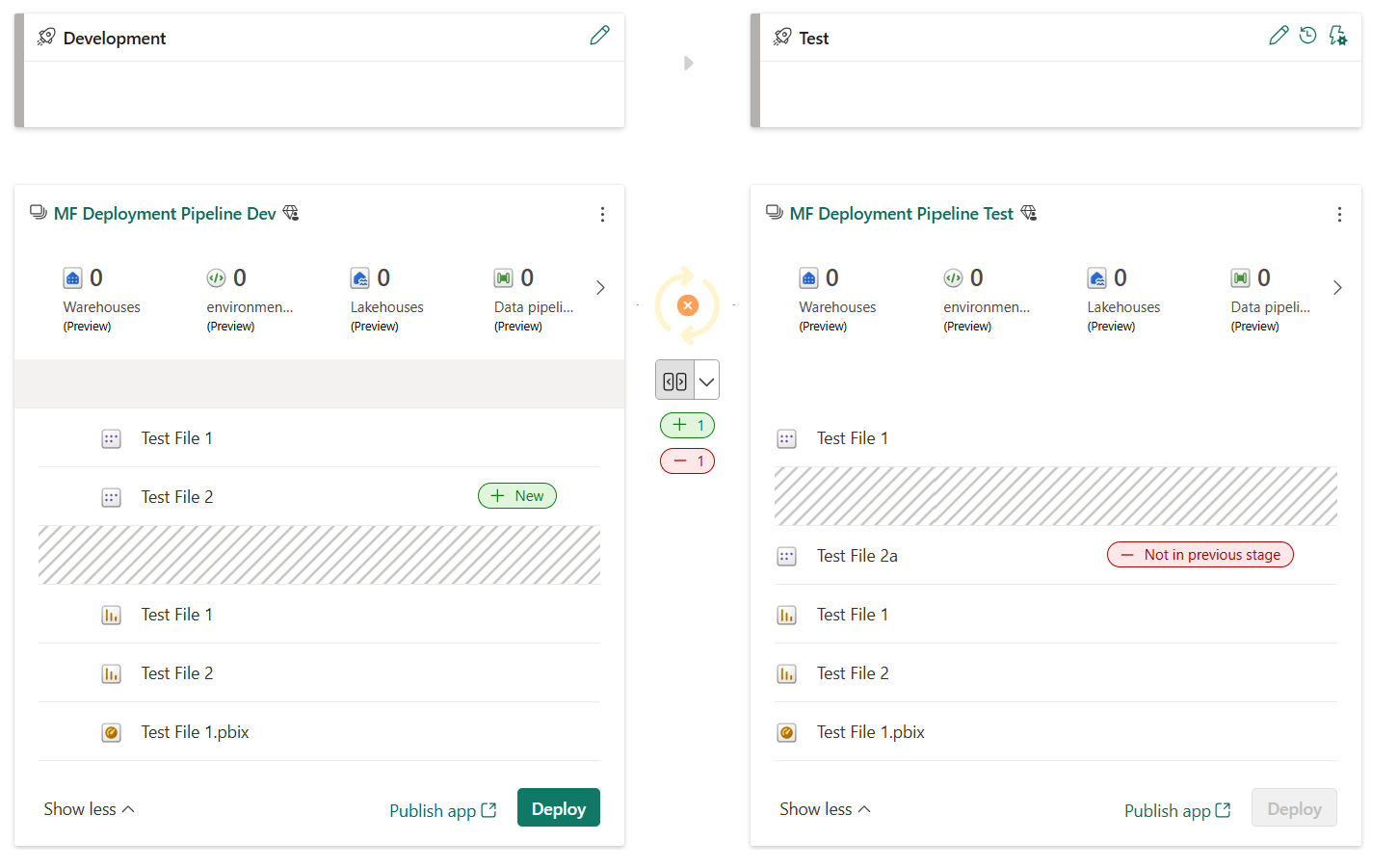
- Gli elementi associati rimangono associati anche se si modificano i nomi. Pertanto, gli elementi associati possono avere nomi diversi.
- Gli elementi aggiunti dopo l'assegnazione dell'area di lavoro a una pipeline non vengono associati automaticamente. Pertanto, è possibile avere elementi identici in aree di lavoro adiacenti che non sono associati.
Per una spiegazione dettagliata degli elementi associati e del funzionamento dell'associazione, vedere Associazione di elementi.
Metodo di distribuzione
Per distribuire il contenuto in un'altra fase, è necessario selezionare almeno un elemento. Quando si distribuisce il contenuto da una fase a un'altra, gli elementi copiati dalla fase di origine sovrascrivono l'elemento associato nella fase in cui ci si trova in base alle regole di associazione. Gli elementi che non esistono nella fase di origine rimangono invariati.
Dopo aver selezionato Distribuisci, viene visualizzato un messaggio di conferma.
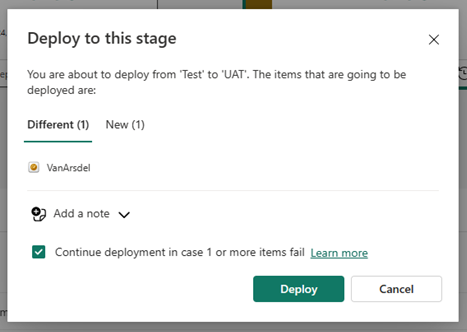
È possibile ottenere altre informazioni su quali elementi vengono copiati nella fase successiva e quali elementi non vengono copiati, in Informazioni sul processo di distribuzione.
Automation
È anche possibile distribuire il contenuto a livello di codice usando le API REST delle pipeline di distribuzione. Per ulteriori informazioni su questo processo di automazione, vedere Automatizzare la pipeline di distribuzione usando le API e DevOps.