Analizzare le prestazioni in Azure AI Search
Questo articolo descrive gli strumenti, i comportamenti e gli approcci per l'analisi delle prestazioni di query e indicizzazione in Azure AI Search.
Raccogliere dati di riferimento
In qualsiasi implementazione di grandi dimensioni, è fondamentale eseguire un test di benchmark delle prestazioni del servizio Azure AI Search prima di distribuirlo nell'ambiente di produzione. È consigliabile testare il carico delle query di ricerca previsto, ma anche i carichi di lavoro di inserimento dati previsti (se possibile, eseguire entrambi i carichi di lavoro contemporaneamente). La disponibilità di dati di benchmark consente di convalidare il livello di ricerca appropriato, la configurazione del servizio e la latenza delle query prevista.
Per isolare gli effetti di un'architettura del servizio distribuita, provare a testare le configurazioni del servizio di una replica e una partizione.
Nota
Per i livelli Ottimizzato per l'archiviazione (L1 e L2), sono previste una velocità effettiva delle query inferiore e una latenza superiore rispetto ai livelli Standard.
Usare la registrazione delle risorse
Lo strumento di diagnostica più importante a disposizione di un amministratore è la registrazione delle risorse. La registrazione delle risorse è la raccolta di dati operativi e metriche relativi al servizio di ricerca. La registrazione delle risorse viene abilitata tramite Monitoraggio di Azure. Esistono costi associati all'uso di Monitoraggio di Azure e all'archiviazione dei dati, ma l'abilitazione di questo strumento per il servizio può essere fondamentale per analizzare i problemi di prestazioni.
L'immagine seguente mostra la catena di eventi in una richiesta e risposta di query. La latenza può verificarsi in corrispondenza di qualsiasi evento, sia durante un trasferimento di rete, l'elaborazione del contenuto nel livello dei servizi app o in un servizio di ricerca. Un vantaggio fondamentale della registrazione delle risorse è che le attività vengono registrate dal punto di vista del servizio di ricerca, il che significa che il log può essere utile per determinare se il problema di prestazioni è dovuto a problemi con la query o l'indicizzazione o a un altro punto di guasto.
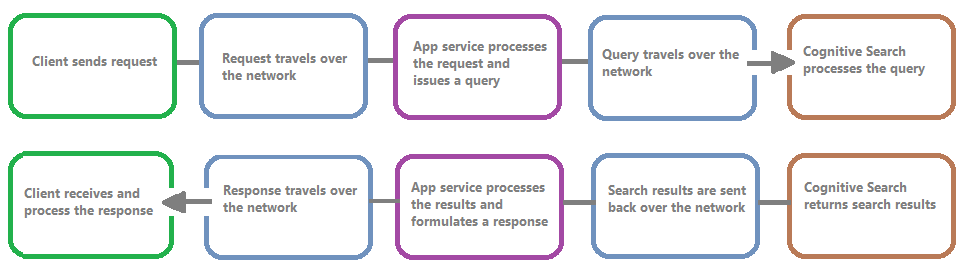
La registrazione delle risorse offre varie opzioni per l'archiviazione delle informazioni registrate. È consigliabile usare Log Analytics in modo da poter eseguire query Kusto avanzate sui dati per ottenere risposte a molte domande sull'utilizzo e sulle prestazioni.
Nelle pagine del portale del servizio di ricerca è possibile abilitare la registrazione tramite le impostazioni di diagnostica e quindi eseguire query Kusto su Log Analytics scegliendo Log. Per informazioni su come inviare i log delle risorse a un'area di lavoro Log Analytics in cui è possibile analizzarli con query di log, vedere Raccogliere e analizzare i log delle risorse da una risorsa di Azure.
Comportamenti di limitazione
La limitazione viene applicata quando il servizio di ricerca è al massimo della capacità. La limitazione può verificarsi durante le query o l'indicizzazione. Dal lato client, una chiamata API genera una risposta HTTP 503 quando è stata limitata. Durante l'indicizzazione, è anche possibile ricevere una risposta HTTP 207, che indica che uno o più elementi non sono stati indicizzati. Questo errore è un segnale che il servizio di ricerca sta per raggiungere la capacità massima.
Come regola generale, cercare di quantificare la quantità di limitazione ed eventuali modelli. Ad esempio, se viene limitata una sola query di ricerca su 500.000, probabilmente non vale la pena indagare ulteriormente. Tuttavia, se una grande percentuale di query viene limitata per un certo periodo, si tratta di un problema maggiore. Esaminando la limitazione nel corso di un periodo è anche possibile identificare gli intervalli di tempo in cui è più probabile che si verifichi la limitazione e decidere come è meglio affrontare il problema.
Una semplice correzione per la maggior parte dei problemi di limitazione consiste nell'attivare più risorse nel servizio di ricerca (in genere repliche per la limitazione relativa alle query o partizioni per quella relativa all'indicizzazione). Tuttavia, l'aumento delle repliche o delle partizioni comporta costi aggiuntivi ed è per questo che è importante comunque conoscere il motivo della limitazione. L'analisi delle condizioni che causano la limitazione sarà l'argomento delle sezioni successive.
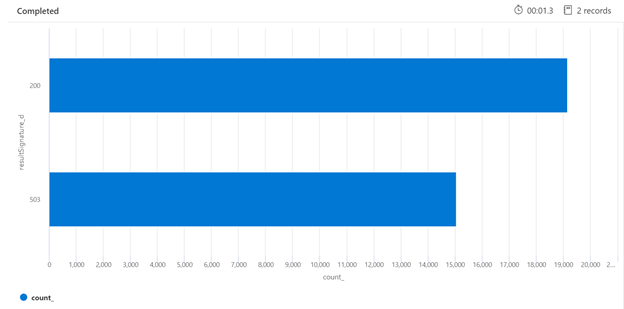
Di seguito è riportato un esempio di query Kusto che consente di identificare la suddivisione delle risposte HTTP dal servizio di ricerca sottoposto a un carico elevato. In un periodo di 7 giorni, il grafico a barre illustrato di seguito mostra che una percentuale relativamente elevata delle query di ricerca è stata limitata, rispetto al numero di risposte riuscite (200).
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
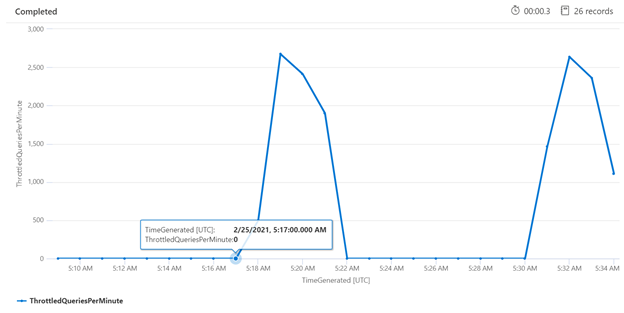
Analizzare la limitazione in un periodo di tempo specifico può essere utile per identificare gli orari in cui la limitazione potrebbe verificarsi più frequentemente. Nell'esempio seguente viene usato un grafico di serie temporale per mostrare il numero di query limitate che si sono verificate in un intervallo di tempo specificato. In questo caso, le query limitate in correlazione ai tempi in cui è stato eseguito il benchmark delle prestazioni.
let ['_startTime']=datetime('2024-02-25T20:45:07Z');
let ['_endTime']=datetime('2024-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Misurare singole query
In alcuni casi, può essere utile testare singole query per esaminarne le prestazioni. A tale scopo, è importante essere in grado di vedere quanto tempo richiede il servizio di ricerca per completare il lavoro, nonché il tempo necessario per la richiesta di round trip dal client e per la restituzione della risposta al client. I log di diagnostica possono essere usati per cercare singole operazioni, ma potrebbe essere più semplice eseguire questa operazione da un client REST.
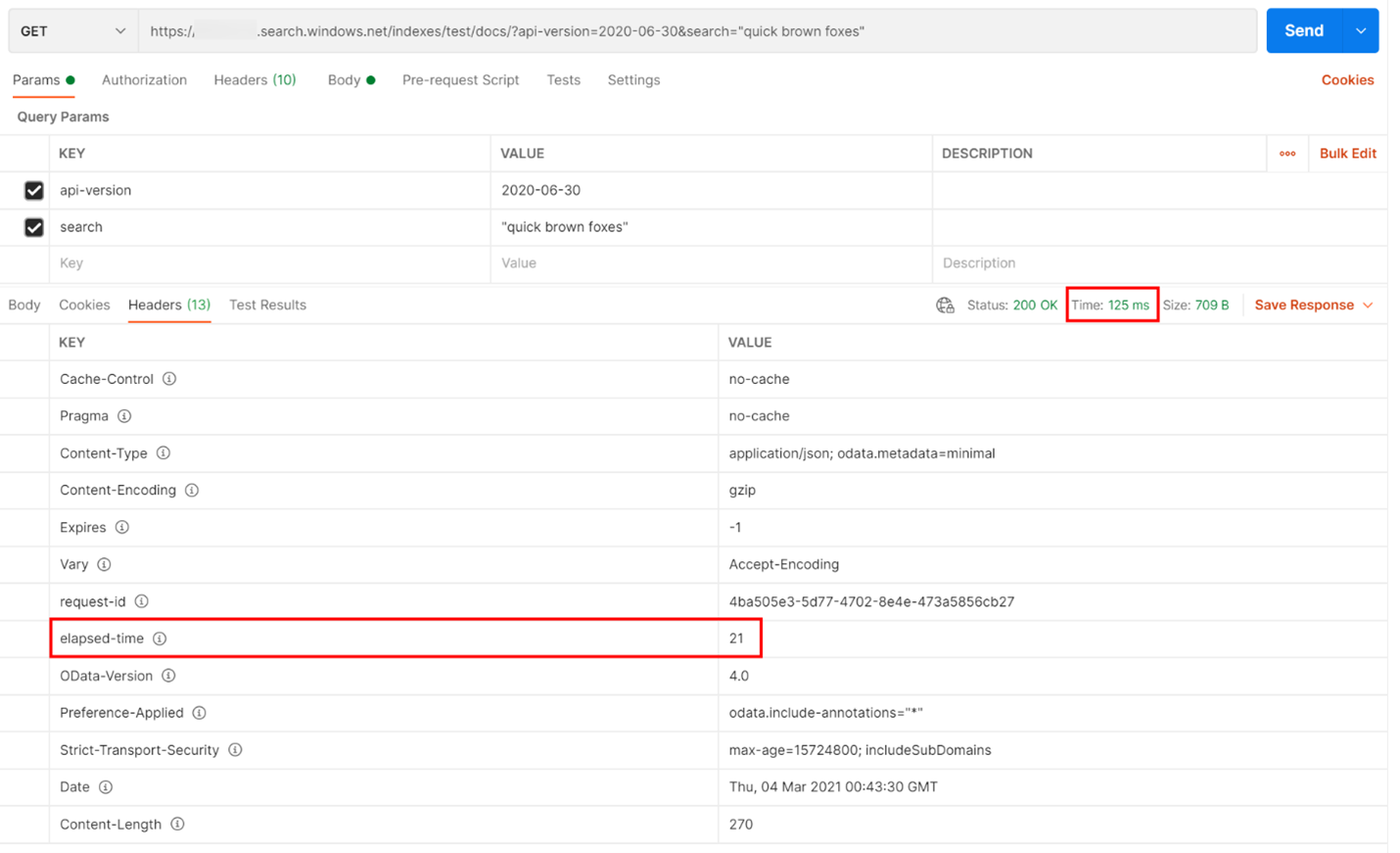
Nell'esempio seguente è stata eseguita una query di ricerca basata su REST. Azure AI Search include in ogni risposta il numero di millisecondi necessari per completare la query, indicati nella scheda Intestazioni, in "elapsed-time". Accanto a Stato nella parte superiore della risposta, si troverà la durata del round trip, in questo caso 418 millisecondi (ms). Nella sezione dei risultati è stata scelta la scheda "Intestazioni". Usando questi due valori, evidenziati con una casella rossa nell'immagine seguente, si evince che il servizio di ricerca ha richiesto 21 ms per completare la query di ricerca e l'intera richiesta di round trip del client ha richiesto 125 ms. Sottraendo questi due numeri è possibile determinare che sono necessari 104 ms di tempo aggiuntivo per trasmettere la query di ricerca al servizio di ricerca e per restituire i risultati della ricerca al client.
Questa tecnica consente di isolare le latenze di rete da altri fattori che influiscono sulle prestazioni delle query.
Frequenze query
Un potenziale motivo per cui il servizio di ricerca limita le richieste è dovuto al numero di query eseguite in cui il volume viene acquisito come query al secondo (QPS) o query al minuto (QPM). Man mano che il servizio di ricerca riceve più QPS, richiederà in genere sempre più tempo per rispondere a tali query fino a quando non riuscirà più a restare al passo, quindi invierà una risposta di limitazione HTTP 503.
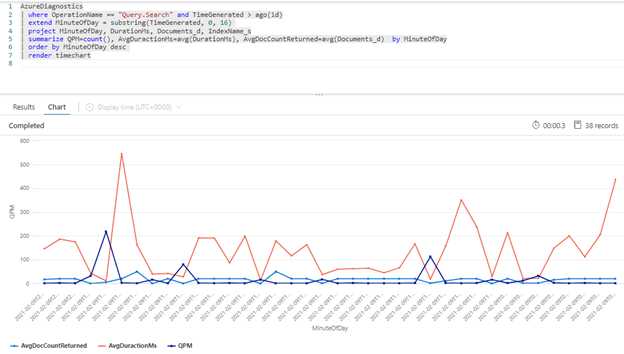
La query Kusto seguente mostra il volume di query misurato in QPM, insieme alla durata media di una query in millisecondi (AvgDurationMS) e al numero medio di documenti (AvgDocCountReturned) restituiti per ognuna.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
Suggerimento
Per visualizzare i dati dietro questo grafico, rimuovere la riga | render timechart e quindi eseguire di nuovo la query.
Impatto dell'indicizzazione sulle query
Un fattore importante da considerare quando si esaminano le prestazioni è che l'indicizzazione usa le stesse risorse delle query di ricerca. Se si esegue l'indicizzazione di una grande quantità di contenuto, è possibile aspettarsi un aumento della latenza man mano che il servizio tenta di gestire entrambi i carichi di lavoro.
Se le query rallentano, esaminare la tempistica dell'attività di indicizzazione per verificare se coincide con la riduzione delle prestazioni delle query. Ad esempio, potrebbe esserci un indicizzatore che esegue un processo ogni giorno o ogni ora correlato alle prestazioni ridotte delle query di ricerca.
Questa sezione fornisce un set di query che consentono di visualizzare la frequenza di esecuzione di ricerca e indicizzazione. Per questi esempi, l'intervallo di tempo è impostato nella query. Assicurarsi di indicare Imposta nella query durante l'esecuzione delle query nel portale di Azure.
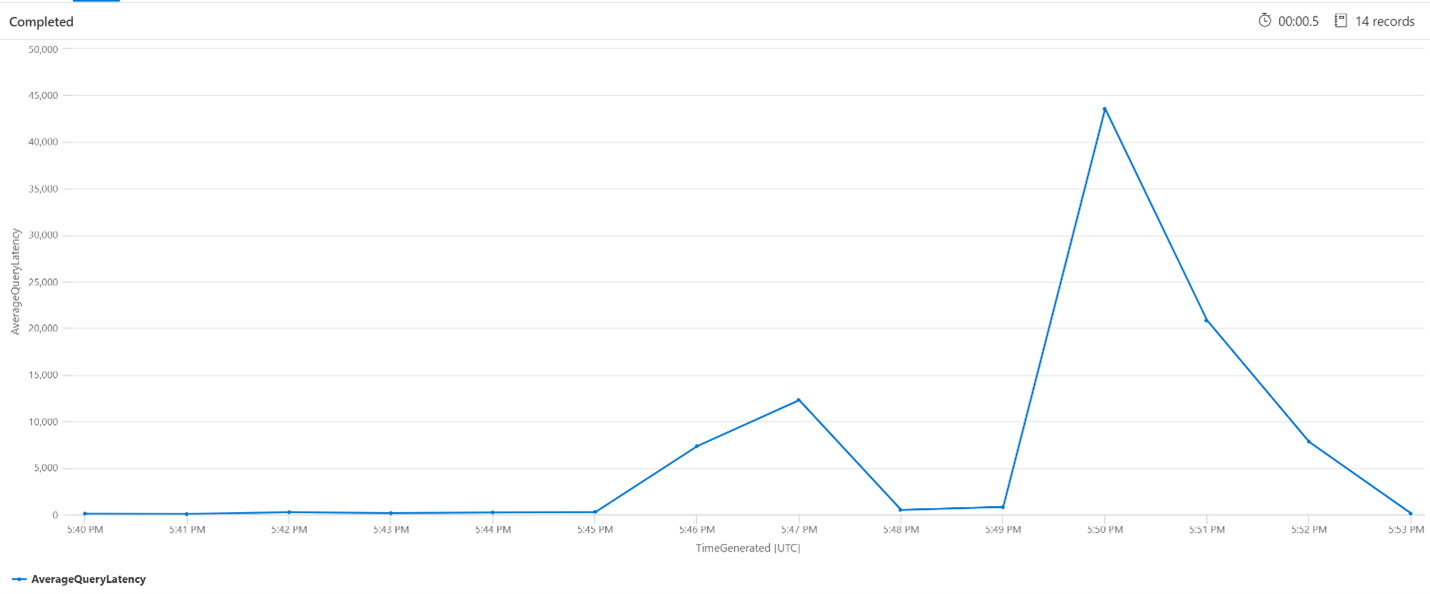
Latenza media query
Nella query seguente viene usato un intervallo di 1 minuto per mostrare la latenza media delle query di ricerca. Dal grafico è possibile osservare che la latenza media è stata bassa fino alle 17:45 ed è rimasta tale fino alle 17:53.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
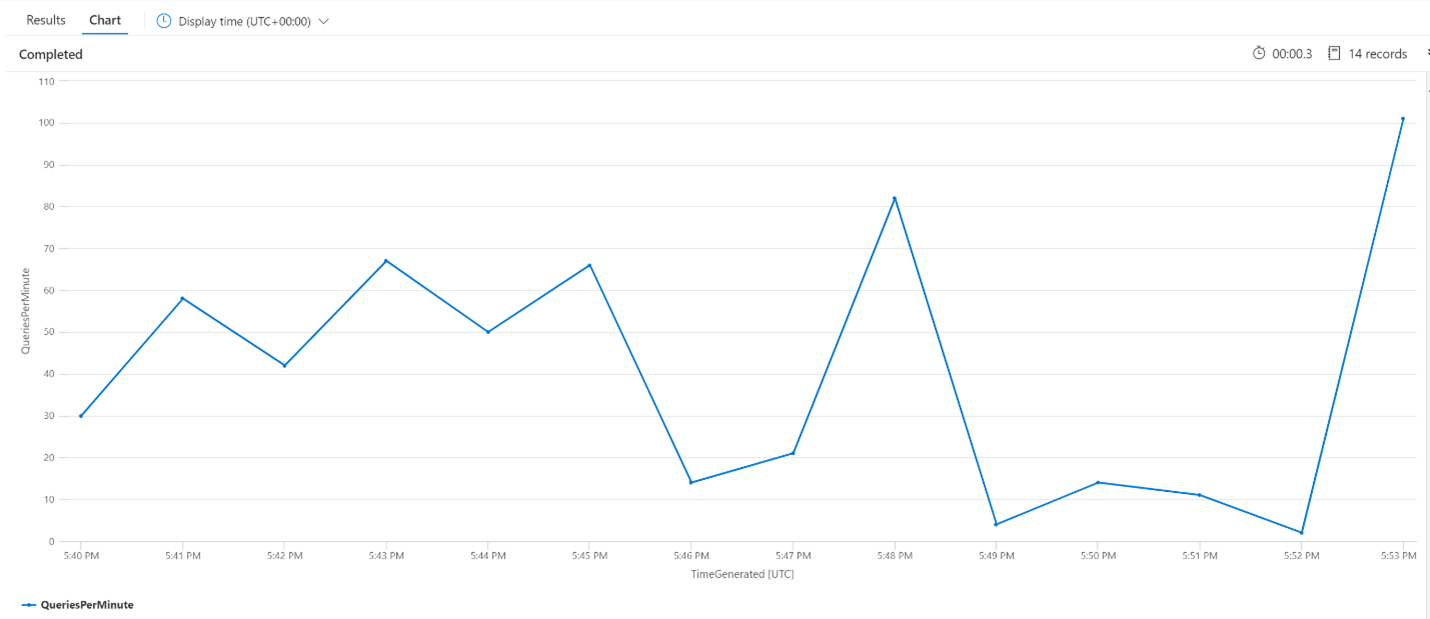
Numero medio di query al minuto
La query seguente esamina il numero medio di query al minuto per assicurarsi che non si sia verificato un picco nelle richieste di ricerca con potenziali effetti sulla latenza. Dal grafico è possibile osservare che c'è una varianza, ma nulla che indichi un picco nel numero delle richieste.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
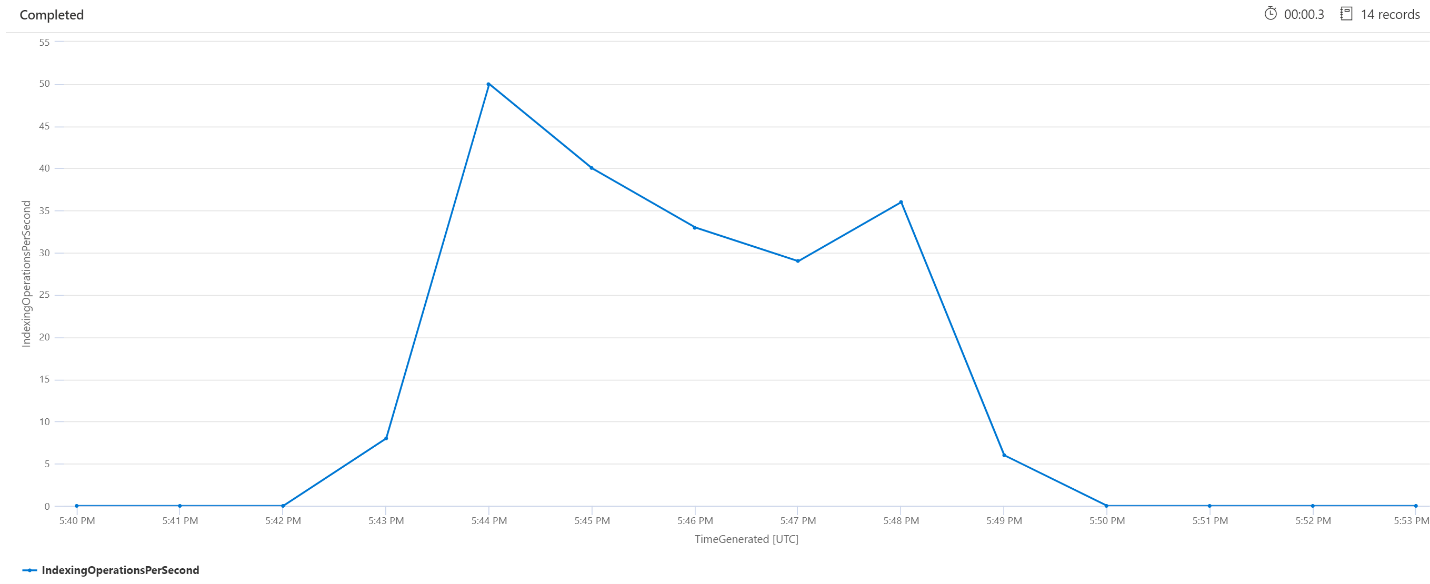
Operazioni di indicizzazione al minuto
Di seguito verrà esaminato il numero di operazioni di indicizzazione al minuto. Dal grafico è possibile notare che l'indicizzazione di una grande quantità di dati è iniziata alle 17:42 e terminata alle 17:50. L'indicizzazione è iniziata 3 minuti prima che le query di ricerca iniziassero a diventare latenti ed è terminata 3 minuti prima che le query di ricerca non fossero più latenti.
Da queste informazioni dettagliate si evince che sono trascorsi circa 3 minuti prima che il servizio di ricerca diventasse sufficientemente occupato da causare effetti sulla latenza delle query dovuti all'indicizzazione. È anche possibile notare che, dopo il completamento dell'indicizzazione, sono serviti altri 3 minuti per il completamento di tutto il lavoro del servizio di ricerca dal contenuto appena indicizzato e per la risoluzione della latenza delle query.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Elaborazione del servizio in background
È comune vedere picchi occasionali nella latenza di query o indicizzazione. I picchi possono verificarsi in seguito all'indicizzazione o a frequenze di query elevate, ma possono verificarsi anche durante le operazioni di unione. Gli indici di ricerca vengono archiviati in blocchi o extent. Periodicamente, il sistema unisce extent più piccoli in extent di grandi dimensioni, che consentono di ottimizzare le prestazioni del servizio. Questo processo di unione pulisce anche i documenti contrassegnati in precedenza per l'eliminazione dall'indice, con conseguente recupero di spazio di archiviazione.
L'unione degli extent è veloce, ma implica anche un uso intensivo delle risorse, quindi può compromettere le prestazioni del servizio. Se si notano brevi picchi di latenza di query e tali picchi coincidono con modifiche recenti al contenuto indicizzato, è possibile dedurre che la latenza sia dovuta a operazioni di unione degli extent.
Passaggi successivi
Esaminare questi articoli relativi all'analisi delle prestazioni del servizio.