Esercitazione: Correggere un set di competenze usando sessioni di debug
In Azure AI Search un set di competenze coordina le azioni delle competenze che analizzano, trasformano o creano contenuto ricercabile. Spesso, l'output di una competenza diventa l'input di un altro. Quando gli input dipendono da output, gli errori nelle definizioni dei set di competenze e nelle associazioni di campi possono comportare operazioni e dati mancanti.
Le sessioni di debug sono uno strumento del portale di Azure che fornisce una visualizzazione olistica di un set di competenze eseguito in Azure AI Search. Usando questo strumento, è possibile eseguire il drill-down in passaggi specifici per vedere facilmente dove potrebbe fallire un'azione.
In questo articolo usare le Sessioni di debug per trovare e correggere gli input e gli output mancanti. L'esercitazione è all-inclusive. Fornisce dati di esempio, un file REST che crea oggetti e istruzioni per il debug dei problemi nel set di competenze.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Azure AI Search. Creare un servizio o trovarne uno esistente nella sottoscrizione corrente. È possibile usare un servizio gratuito per questa esercitazione. Il livello gratuito non fornisce il supporto dell’identità gestita per un servizio di Azure AI Search. È necessario usare le chiavi per le connessioni ad Archiviazione di Azure.
Account di archiviazione di Azure con archiviazione BLOB, utilizzato per ospitare dati di esempio e per rendere persistenti i dati memorizzati nella cache creati durante una sessione di debug. Se si usa un servizio di ricerca gratuito, l'account di archiviazione deve avere chiavi di accesso condiviso abilitate e deve consentire l'accesso alla rete pubblica.
Visual Studio Code con un client REST.
File debug-sessions.rest di esempio usato per creare la pipeline di arricchimento.
Nota
Questa esercitazione usa anche i servizi di Azure AI per il rilevamento della lingua, il riconoscimento delle entità e l'estrazione di frasi chiave. Poiché il carico di lavoro è molto ridotto, Servizi di Azure AI lavora dietro le quinte per offrire un'elaborazione gratuita per un massimo di 20 transazioni. Ciò significa che è possibile completare questo esercizio senza dover creare una risorsa dei servizi di Azure AI fatturabile.
Configurare i dati di esempio
Questa sezione crea il set di dati di esempio in Archiviazione BLOB di Azure in modo che l'indicizzatore e il set di competenze abbiano contenuto da usare.
Scaricare i dati di esempio (clinical-trials-pdf-19), costituiti da 19 file.
Creare un account di Archiviazione di Azure o trovare un account esistente.
Per evitare addebiti dovuti alla larghezza di banda, scegliere la stessa area di Azure AI Search.
Scegliere il tipo di account Archiviazione V2 (utilizzo generico V2).
Passare alle pagine dei servizi di Archiviazione di Azure nella portale di Azure e creare un contenitore BLOB. È consigliabile specificare il livello di accesso "privato". Assegnare al contenitore il nome
clinicaltrialdataset.Nel contenitore selezionare Carica per caricare i file di esempio scaricati e decompressi nel primo passaggio.
Nel portale di Azure copiare il stringa di connessione per Archiviazione di Azure. È possibile ottenere il stringa di connessione da Impostazioni>chiavi di accesso nel portale di Azure.
Copiare una chiave e un URL
Questa esercitazione usa le chiavi API per l'autenticazione e l'autorizzazione. Sono necessari l'endpoint del servizio di ricerca e una chiave API, che è possibile ottenere dal portale di Azure.
Accedere al portale di Azure, passare alla pagina Panoramica e copiare l'URL. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni>Chiavi, copiare una chiave amministratore. Le chiavi amministratore vengono usate per aggiungere, modificare ed eliminare oggetti. Sono disponibili due chiavi amministratore intercambiabili. Copiarne una.
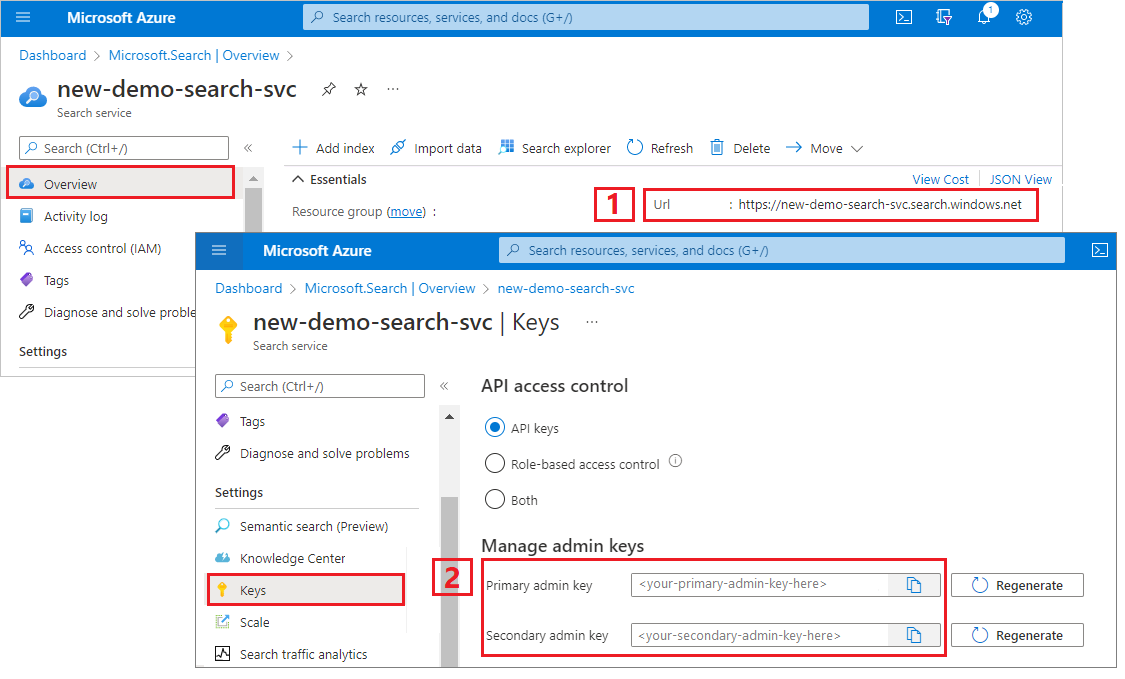
La presenza di una chiave API valida stabilisce una relazione di trust, a livello di singole richieste, tra l'applicazione che invia la richiesta e il servizio di ricerca che la gestisce.
Creare l'origine dati, il set di competenze, l'indice e l'indicizzatore
In questa sezione creare un flusso di lavoro "buggy" che è possibile poi correggere in questa esercitazione.
Avviare Visual Studio Code e aprire il file
debug-sessions.rest.Specificare le variabili seguenti: URL del servizio di ricerca, chiave API amministratore dei servizi di ricerca, stringa di connessione di archiviazione e nome del contenitore BLOB che archivia i PDF.
Inviare ogni richiesta a sua volta. Il completamento della creazione dell'indicizzatore richiede alcuni minuti.
Chiudere il file .
Controllare i risultati nel portale di Azure
Il codice di esempio crea intenzionalmente un indice buggy (con errori) come conseguenza dei problemi che si sono verificati durante l'esecuzione del set di competenze. Il problema è che l'indice non contiene dati.
Nella pagina Panoramica del servizio di ricerca del portale di Azure selezionare la scheda Indici.
Selezionare studi-clinici.
Immettere questa stringa di query JSON nella visualizzazione JSON di Esplora ricerche. Restituisce campi per documenti specifici (identificati dal campo univoco
metadata_storage_path)."search": "*", "select": "metadata_storage_path, organizations, locations", "count": trueEsegui la query. Verranno visualizzati valori vuoti per
organizationselocations.Questi campi dovrebbero essere stati popolati tramite la competenza Riconoscimento entità del set di competenze, usata per rilevare organizzazioni e posizioni ovunque all'interno del contenuto del BLOB. Nell'esercizio successivo si eseguirà il debug del set di competenze per determinare l'errore.
Un altro modo per analizzare gli errori e gli avvisi consiste nel portale di Azure.
Aprire la scheda Indicizzatori e selezionare clinical-trials-idxr.
Si noti che, mentre il processo dell'indicizzatore è riuscito complessivamente, sono stati visualizzati avvisi.
Selezionare Operazione riuscita per visualizzare gli avvisi (se si sono verificati errori per lo più, il collegamento di dettaglio sarà Non riuscito). Verrà visualizzato un lungo elenco di tutti gli avvisi generati dall'indicizzatore.

Avviare la sessione di debug
Nel riquadro di spostamento sinistro del servizio di ricerca, in Gestione ricerca selezionare Sessioni di debug.
Selezionare + Aggiungi sessione di debug.
Assegnare un nome alla sessione.
Nel modello indicizzatore specificare il nome dell'indicizzatore. L'indicizzatore contiene riferimenti all'origine dati, al set di competenze e all'indice.
Selezionare l'account di archiviazione.
Selezionare Salva per salvare la sessione.
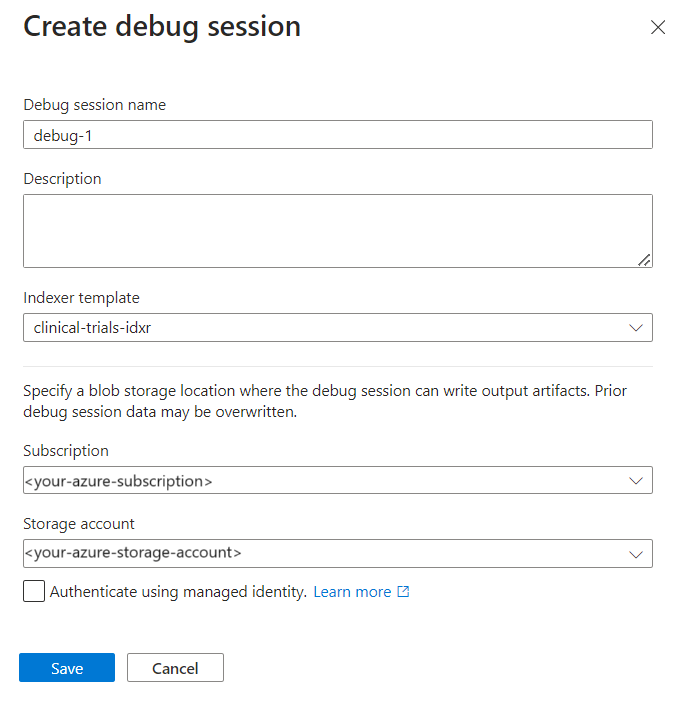
Viene aperta una sessione di debug nella pagina delle impostazioni. È possibile apportare modifiche alla configurazione iniziale ed eseguire l'override di tutte le impostazioni predefinite. Una sessione di debug funziona solo con un singolo documento. L'impostazione predefinita consiste nell'accettare il primo documento nella raccolta come base delle sessioni di debug. È possibile scegliere un documento specifico di cui eseguire il debug specificando l'URI in Archiviazione di Azure.
Al termine dell'inizializzazione della sessione di debug, dovrebbe essere visualizzato un flusso di lavoro di competenze con mapping e un indice di ricerca. La struttura dei dati del documento arricchiti viene visualizzata in un riquadro dei dettagli sul lato. È stata esclusa dallo screenshot seguente in modo che sia possibile visualizzare più del flusso di lavoro.
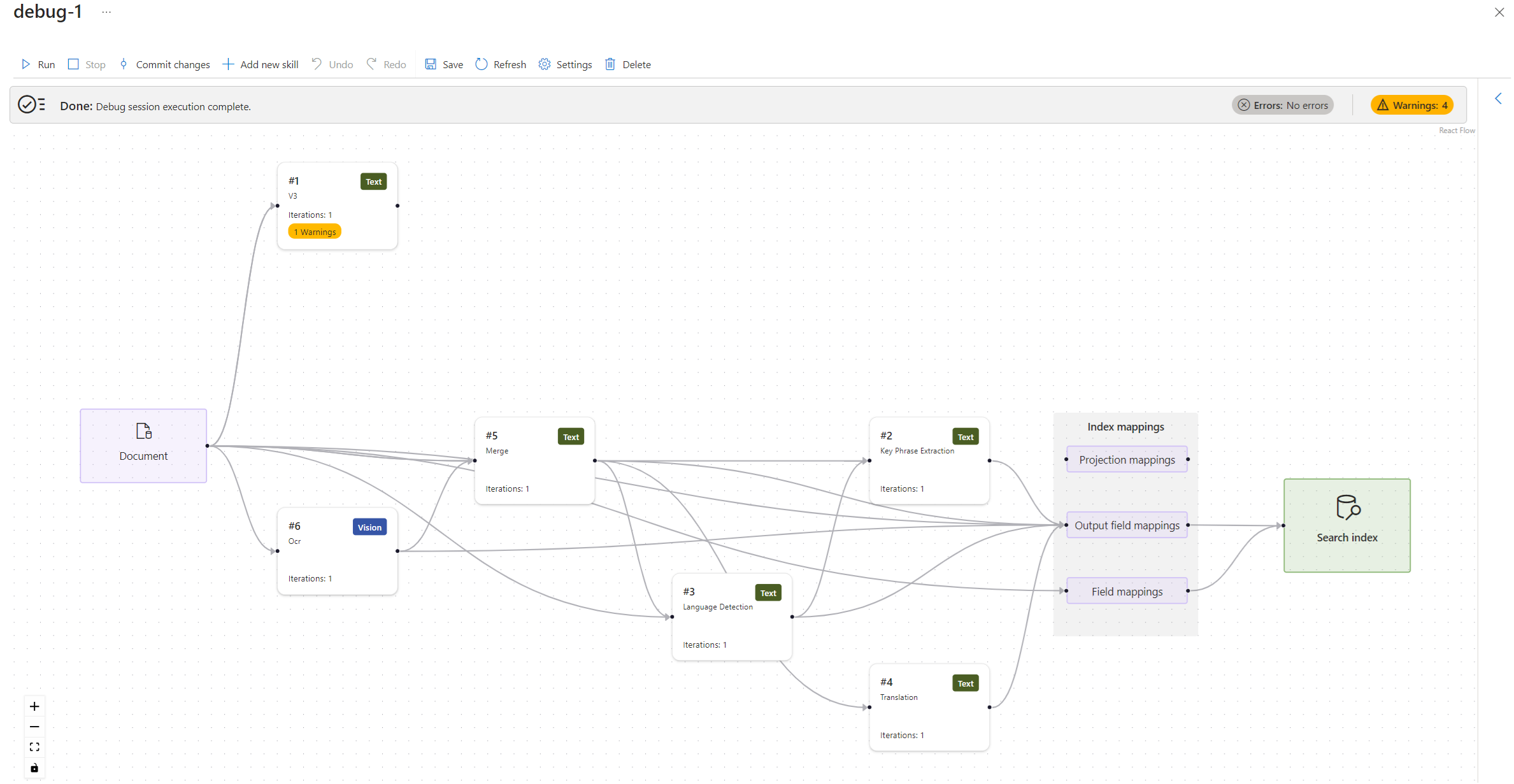


Individuare problemi con il set di competenze
Eventuali problemi segnalati dall'indicizzatore sono indicati come errori e avvisi.
Si noti che il numero di errori e avvisi è un elenco molto più piccolo di quello visualizzato in precedenza perché questo elenco descrive in dettaglio solo gli errori per un singolo documento. Analogamente all'elenco visualizzato dall'indicizzatore, è possibile selezionare un messaggio di avviso e visualizzare i dettagli di questo avviso.
Selezionare Avvisi per esaminare le notifiche. Dovrebbero essere visualizzati quattro elementi:
"Impossibile eseguire la competenza perché uno o più input di competenza non sono validi. L'input della competenza richiesto non è presente. Nome: 'text', Origine: '/document/content'."
"Impossibile eseguire il mapping del campo di output 'locations' all'indice di ricerca. Controllare la proprietà 'outputFieldMappings' dell'indicizzatore. Valore mancante '/document/merged_content/locations'."
"Impossibile eseguire il mapping del campo di output 'organizations' in relazione all'indice di ricerca. Controllare la proprietà 'outputFieldMappings' dell'indicizzatore. Valore mancante '/document/merged_content/organizations'."
"La competenza è stata eseguita ma potrebbe avere risultati imprevisti perché uno o più input di competenza non sono validi. Manca l'input della competenza facoltativo. Nome: 'languageCode', Origine: '/document/languageCode'. Problemi di analisi del linguaggio delle espressioni: valore mancante '/document/languageCode'."
Molte competenze presentano un parametro "languageCode". Esaminando l'operazione, è possibile notare che questo input del codice del linguaggio non è presente in EntityRecognitionSkill.#1, che è la stessa competenza di riconoscimento delle entità che presenta problemi con l'output "locations" e "organizations".
Poiché tutte e quattro le notifiche riguardano questa competenza, il passaggio successivo consiste nell’eseguire il debug di questa competenza. Se possibile, iniziare risolvendo i problemi di input prima di passare ai problemi di output.
Correggere i valori di input della competenza mancante
Nell'area di lavoro selezionare la competenza che segnala gli avvisi. In questa esercitazione si tratta della competenza di riconoscimento delle entità.
Il riquadro Dettagli competenza si apre a destra con sezioni per le iterazioni e i rispettivi input e output, le impostazioni della competenza per la definizione JSON della competenza e i messaggi per eventuali errori e avvisi che questa competenza genera.
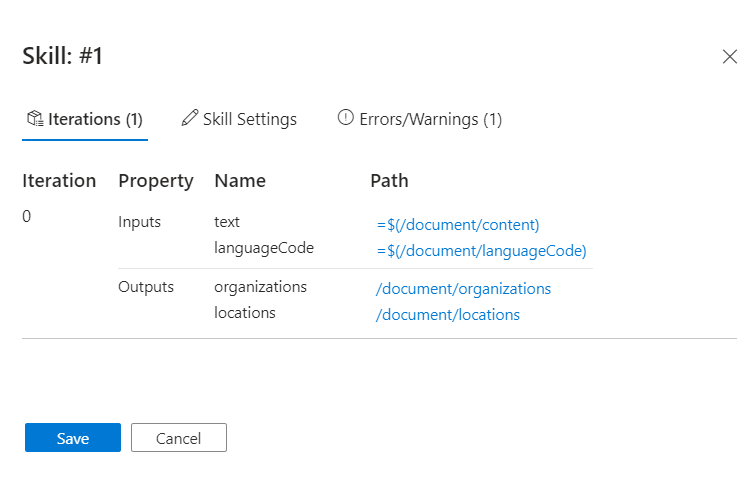
Passare il puntatore del mouse su ogni input (o selezionare un input) per visualizzare i valori nell'analizzatore di espressioni. Si noti che il risultato visualizzato per questo input non è simile a un input di testo. Sembra una serie di nuovi caratteri di riga
\n \n\n\n\nanziché testo. La mancanza di testo indica che non è possibile identificare alcuna entità, pertanto questo documento non soddisfa i prerequisiti della competenza oppure è necessario usare un altro input.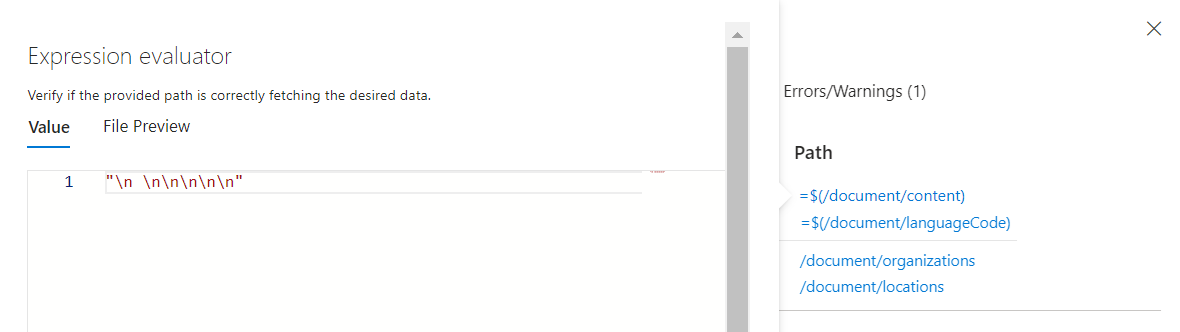
Tornare alla struttura dei dati arricchiti ed esaminare i nodi di arricchimento per questo documento. Si noti che
\n \n\n\n\nper "content" non è presente alcuna origine, ma un altro valore per "merged_content" ha output OCR. Sebbene non vi sia alcuna indicazione, il contenuto di questo PDF sembra essere un file JPEG, come evidenziato dal testo estratto ed elaborato in "merged_content".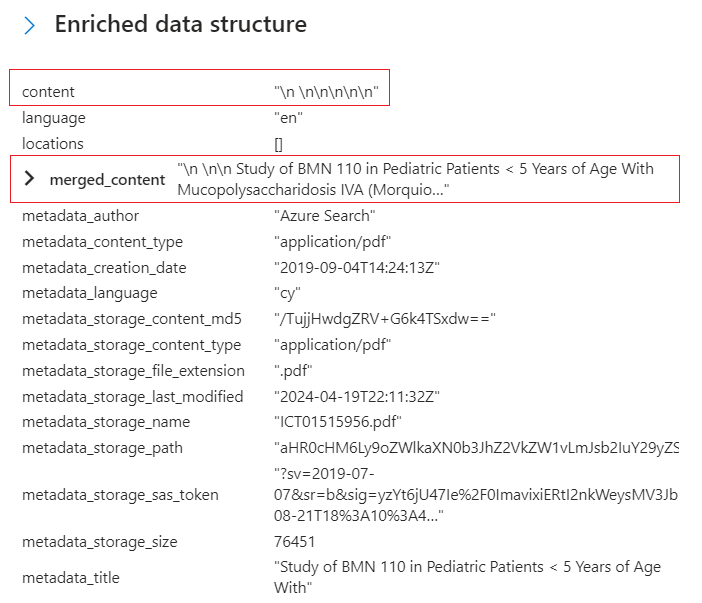
Tornare alla competenza e selezionare Impostazioni set di competenze per aprire la definizione JSON.
Modificare l'espressione da
/document/contenta/document/merged_contente quindi selezionare Salva. Si noti che l'avviso non è più elencato.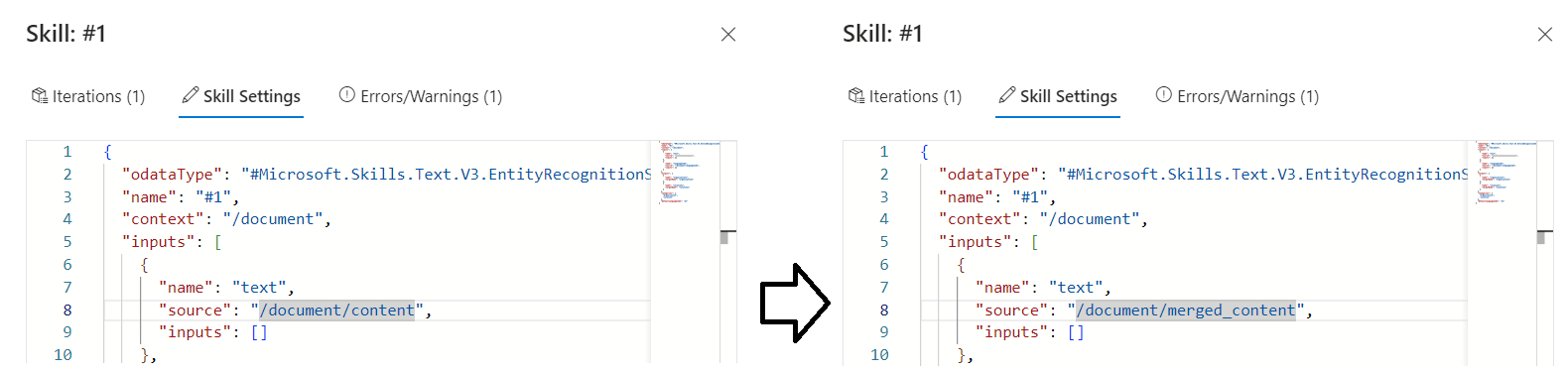
Selezionare Esegui nel menu della finestra della sessione. Verrà avviata un'altra esecuzione del set di competenze usando il documento.
Al termine dell'esecuzione della sessione di debug, si noti che il conteggio degli avvisi è ridotto di uno. Gli avvisi indicano che l'errore per l'input di testo non è presente, ma gli altri avvisi rimangono. Il passaggio successivo consiste nell'affrontare l'avviso relativo al valore mancante o vuoto
/document/languageCode.
Selezionare la competenza e passare il puntatore del mouse su
/document/languageCode. Il valore per questo input è Null, che non è un input valido.Come per il problema precedente, iniziare esaminando la struttura dei dati arricchiti per verificare i relativi nodi. Si noti che non esiste un nodo "languageCode", ma ne esiste uno per "language". Quindi, c'è un errore di digitazione nelle impostazioni della competenza.
Copiare l'espressione
/document/language.Nel riquadro Dettagli competenze selezionare Impostazioni competenze per la competenza n. 1 e incollare il nuovo valore,
/document/language.Seleziona Salva.
Selezionare Esegui.
Al termine dell'esecuzione della sessione di debug, è possibile controllare i risultati nel riquadro Dettagli competenze. Quando si passa il puntatore del mouse su
/document/language, viene visualizzatoencome valore nell'analizzatore di espressioni.
Si noti che gli avvisi di input non sono più presenti. Ora rimangono solo i due avvisi relativi ai campi di output per le organizzazioni e le posizioni.
Correggere i valori di output della competenza mancanti
I messaggi indicano di controllare la proprietà 'outputFieldMappings' dell'indicizzatore, quindi consente di iniziare da lì.
Selezionare Mapping dei campi di output nell'area di lavoro. Si noti che mancano i mapping dei campi di output.
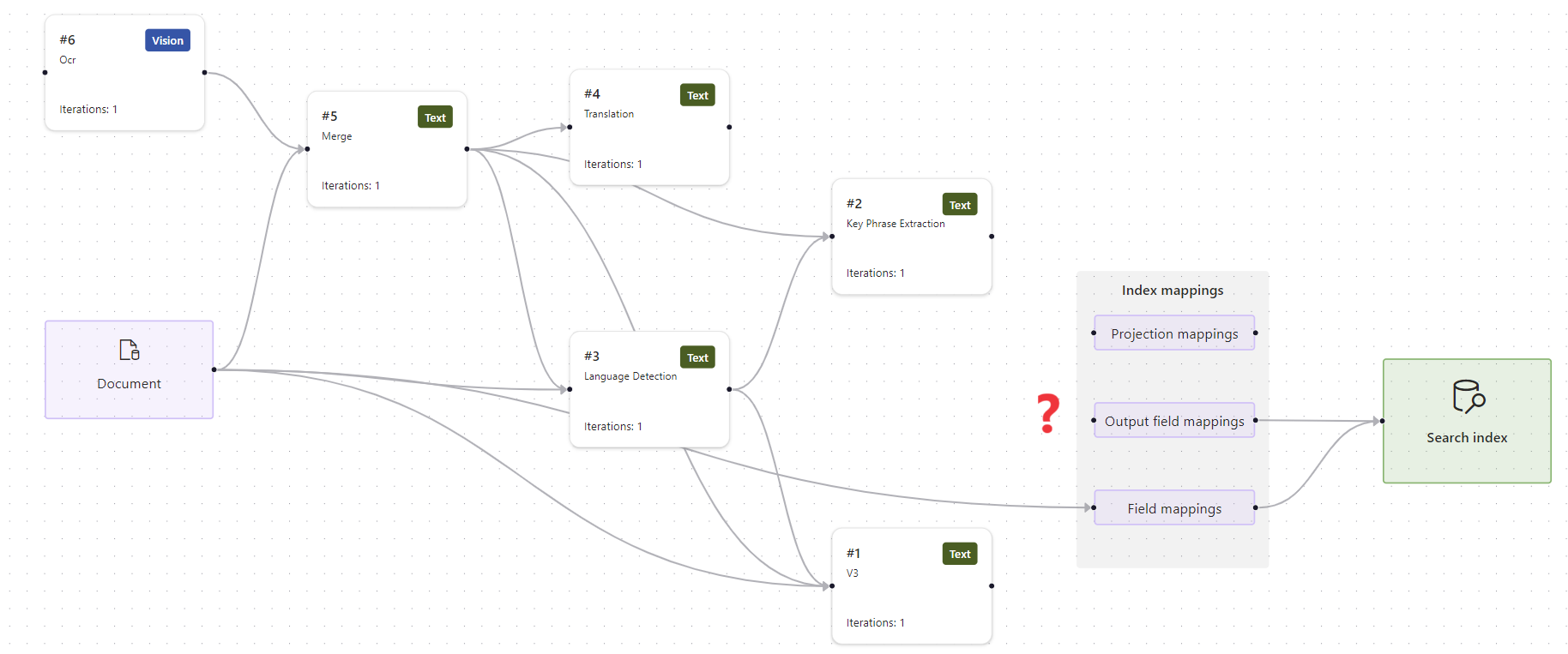
Come primo passaggio, verificare che l'indice di ricerca contenga i campi previsti. In questo caso, l'indice include i campi relativi a "locations" (posizioni) e "organizations" (organizzazioni).
Se non si verificano problemi con l'indice, il passaggio successivo consiste nel controllare gli output delle competenze. Come in precedenza, selezionare la struttura dei dati arricchiti e scorrere i nodi per trovare "posizioni" e "organizzazioni". Si noti che l'elemento padre è "content" (contenuto) anziché "merged_content". Il contesto non è corretto.
Tornare al riquadro Dettagli competenze per la competenza di riconoscimento delle entità.
In Impostazioni competenze passare da
contextadocument/merged_content. A questo punto, è necessario apportare tre modifiche alla definizione della competenza.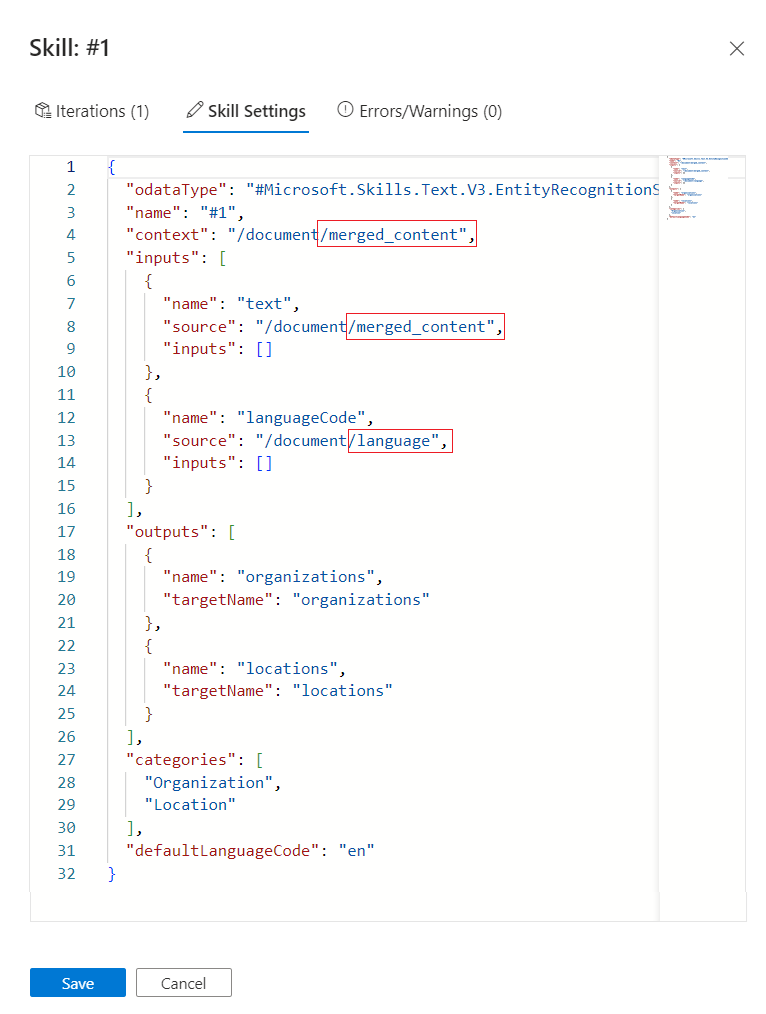
Seleziona Salva.
Selezionare Esegui.
Tutti gli errori sono stati risolti.
Eseguire il commit delle modifiche apportate al set di competenze
Quando è stata avviata la sessione di debug, il servizio di ricerca ha creato una copia del set di competenze. Questa operazione è stata eseguita per proteggere il set di competenze originale nel servizio di ricerca. Dopo aver completato il debug del set di competenze, è possibile eseguire il commit delle correzioni (sovrascrivere il set di competenze originale).
In alternativa, se non si è pronti a eseguire il commit delle modifiche, è possibile salvare la sessione di debug e riaprirla in un secondo momento.
Selezionare Esegui commit delle modifiche nel menu principale Sessioni di debug.
Selezionare OK per confermare che si vuole aggiornare il set di competenze.
Chiudere la Sessione di debug e aprire Indicizzatori dal riquadro di spostamento a sinistra.
Selezionare "clinical-trials-idxr".
Selezionare Reimposta.
Selezionare Esegui.
Selezionare Aggiorna per visualizzare lo stato dei comandi di reimpostazione ed esecuzione.
Al termine dell'esecuzione dell'indicizzatore, dovrebbe essere visualizzato un segno di spunta verde e la parola Success (Operazione riuscita) accanto al timestamp dell'esecuzione più recente nella scheda Cronologia esecuzione. Per verificare che le modifiche siano state applicate:
Nel riquadro di spostamento sinistro aprire Indici.
Selezionare l'indice "clinical-trials" e nella scheda Esplora ricerche immettere questa stringa di query:
$select=metadata_storage_path, organizations, locations&$count=trueper restituire campi per documenti specifici (identificati dal campo univocometadata_storage_path).Seleziona Cerca.
Nella finestra dei risultati si dovrebbe vedere che le entità organizations (organizzazioni) e locations (posizioni) sono ora popolate con i valori previsti.
Pulire le risorse
Quando si lavora nella propria sottoscrizione, al termine di un progetto è buona norma determinare se le risorse create sono ancora necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile trovare e gestire le risorse nella portale di Azure, usando il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Il servizio gratuito è limitato a tre indici, indicizzatori e origini dati. È possibile eliminare singoli elementi nel portale di Azure per rimanere al di sotto del limite.
Passaggi successivi
Questa esercitazione ha toccato vari aspetti della definizione e dell'elaborazione del set di competenze. Per altre informazioni sui concetti e sui flussi di lavoro, vedere gli articoli seguenti: