Eseguire il debug di un set di competenze di Azure AI Search nel portale di Azure
Avviare una sessione di debug basata sul portale per identificare e risolvere gli errori, convalidare le modifiche ed eseguire il push delle modifiche in un set di competenze esistente nel servizio Azure AI Search.
Una sessione di debug consiste nell’esecuzione di un indicizzatore memorizzato nella cache e di un set di competenze, con ambito limitato a un singolo documento, che è possibile usare per modificare e testare le modifiche al set di competenze in modo interattivo. Al termine del debug, è possibile salvare le modifiche apportate al set di competenze.
Per informazioni sul funzionamento di una sessione di debug, vedere Eseguire il debug di sessioni in Azure AI Search. Per esercitarsi a usare un flusso di lavoro di debug con un documento di esempio, vedere Esercitazione: Sessioni di debug.
Prerequisiti
Un servizio di Azure AI Search. È consigliabile usare un'identità gestita assegnata dal sistema e assegnazioni di ruolo che consentono a Ricerca di intelligenza artificiale di Azure di scrivere in Archiviazione di Azure e chiamare le risorse di Intelligenza artificiale di Azure usate nel set di competenze.
Account di archiviazione di Azure per salvare lo stato della sessione.
Una pipeline di arricchimento esistente, che include un'origine dati, un set di competenze, un indicizzatore e un indice.
Per le assegnazioni di ruolo, l'identità del servizio di ricerca deve avere:
Autorizzazioni utente di Servizi cognitivi per l'account multiservizio di Intelligenza artificiale di Azure usato dal set di competenze.
Autorizzazioni Collaboratore ai dati dei BLOB di archiviazione per Archiviazione di Azure. In caso contrario, pianificare l'uso di una stringa di connessione di accesso completa per la connessione della sessione di debug ad Archiviazione di Azure.
Se l'account di archiviazione di Azure è protetto da un firewall, configurarlo per consentire l'accesso al servizio di ricerca.
Limiti
Le sessioni di debug funzionano con tutte le origini dati indicizzatore disponibili a livello generale e la maggior parte delle origini dati di anteprima, con le eccezioni seguenti:
Indicizzatore di SharePoint online.
Indicizzatore di Azure Cosmos DB per MongoDB.
Per Azure Cosmos DB per NoSQL: se si verifica un errore in una riga durante l'indicizzazione e non sono presenti metadati corrispondenti, la sessione di debug potrebbe non selezionare la riga corretta.
Per l'API SQL di Azure Cosmos DB: se una raccolta partizionata in precedenza non è stata partizionata, la sessione di debug non troverà il documento.
Per le competenze personalizzate: non è possibile usare un'identità gestita assegnata dall'utente per connettere una sessione di debug ad Archiviazione di Azure. Come indicato nei prerequisiti, è possibile usare un'identità gestita dal sistema o specificare una stringa di connessione di accesso completo che include una chiave. Per altre informazioni, vedere Connettere un servizio di ricerca ad altre risorse di Azure tramite un'identità gestita.
Attualmente, la possibilità di selezionare il documento di cui eseguire il debug non è disponibile. Questa limitazione non è permanente e verrà rimossa presto. Al momento, le sessioni di debug selezionano il primo documento nel contenitore o nella cartella dati di origine.
Creare una sessione di debug
Accedere al portale di Azure e trovare il servizio di ricerca.
Nel menu a sinistra selezionare Gestione ricerca>Sessioni di debug.
Nella barra delle azioni in alto selezionare Aggiungi sessione di debug.
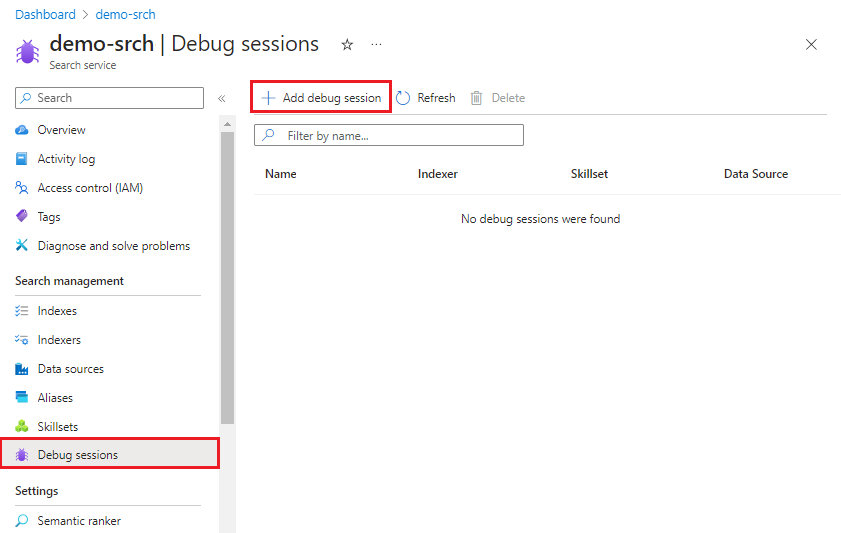
In Nome della sessione di debug specificare un nome che consenta di ricordare il set di competenze, l'indicizzatore e l'origine dati interessati dalla sessione di debug.
Nel modello Indicizzatore selezionare l'indicizzatore su cui si basa il set di competenze di cui si vuole eseguire il debug. Le copie dell'indicizzatore e del set di competenze vengono usate per inizializzare la sessione.
In account di archiviazione, trovare un account di archiviazione per utilizzo generico per la memorizzazione nella cache della sessione di debug.
Selezionare Autentica usando l'identità gestita se in precedenza sono state assegnate autorizzazioni collaboratore ai dati dei BLOB di archiviazione per l'identità gestita dal sistema del servizio di ricerca.
Seleziona Salva.
- Ricerca di intelligenza artificiale di Azure crea un contenitore BLOB in Archiviazione di Azure denominato ms-az-cognitive-search-debugsession.
- All'interno di tale contenitore viene creata una cartella usando il nome specificato per il nome della sessione.
- Avvia la sessione di debug.
Viene aperta una sessione di debug nella pagina delle impostazioni. È possibile apportare modifiche alla configurazione iniziale ed eseguire l'override di tutte le impostazioni predefinite.
In stringa di connessione archiviazione è possibile specificare la stringa di connessione o modificare l'account di archiviazione.
Facoltativamente, nelle impostazioni dell'indicizzatore specificare le impostazioni di esecuzione dell'indicizzatore usate per creare la sessione. Le impostazioni devono eseguire il mirroring delle impostazioni usate dall'indicizzatore effettivo. Le opzioni dell'indicizzatore specificate in una sessione di debug non hanno alcun effetto sull'indicizzatore stesso.
Se sono state apportate delle modifiche, selezionare Salva sessione, quindi Esegui.

La sessione di debug inizia con l'esecuzione del set di competenze nel documento selezionato. Il contenuto e i metadati del documento saranno visibili e disponibili nella sessione.
È possibile annullare una sessione di debug mentre è in corso usando il pulsante Annulla. Se si preme il pulsante Annulla è in genere possibile analizzare i risultati parziali.
È previsto che l'esecuzione di una sessione di debug richieda più tempo rispetto all'indicizzatore perché include un'elaborazione aggiuntiva.
Iniziare con errori e avvisi
La cronologia di esecuzione dell'indicizzatore nel portale fornisce l'elenco completo degli errori e degli avvisi per tutti i documenti. In una sessione di debug gli errori e gli avvisi sono limitati a un documento. È possibile esaminare l’elenco, apportare le modifiche e quindi tornare all’elenco per verificare se i problemi sono stati risolti.
Tenere presente che una sessione di debug si basa su un documento dall'intero indice. Se un input o un output ha un aspetto errato, il problema potrebbe essere specifico per tale documento. È possibile scegliere un documento diverso per verificare se gli errori e gli avvisi sono diffusi o specifici di un singolo documento.
Selezionare Errori o avvisi per un elenco di problemi.

Come procedura consigliata, risolvere i problemi relativi agli input prima di passare agli output.
Per confermare che una modifica risolve un errore, seguire questa procedura:
Selezionare Salva nel riquadro dei dettagli della competenza per mantenere le modifiche.
Selezionare Esegui nella finestra della sessione per richiamare l'esecuzione del set di competenze usando la definizione modificata.
Tornare a Errori o Avvisiper verificare se il conteggio è ridotto.
Visualizzare contenuti arricchiti o generati
Le pipeline di arricchimento tramite intelligenza artificiale estraggono o deducono informazioni e la struttura dai documenti di origine, creando un documento arricchito nel processo. Un documento arricchito viene creato inizialmente durante il cracking del documento e popolato con un nodo radice (/document), oltre che con i nodi di qualsiasi contenuto rimosso direttamente dall'origine dati, ad esempio metadati e chiave del documento. Altri nodi vengono creati dalle competenze durante l'esecuzione delle competenze, in cui ogni output della competenza aggiunge un nuovo nodo all'albero di arricchimento.
Tutto il contenuto creato o usato da un set di competenze viene visualizzato nell'analizzatore di espressioni. È possibile passare il puntatore del mouse sui collegamenti per visualizzare ogni valore di input o output nell'albero dei documenti arricchiti. Per visualizzare l'input o l'output di ogni competenza, seguire questa procedura:
In una sessione di debug espandere la freccia blu per visualizzare i dettagli sensibili al contesto. Per impostazione predefinita, il dettaglio è la struttura dei dati del documento arricchita. Tuttavia, se si seleziona una competenza o un mapping, il dettaglio riguarda tale oggetto.

Selezionare una competenza.
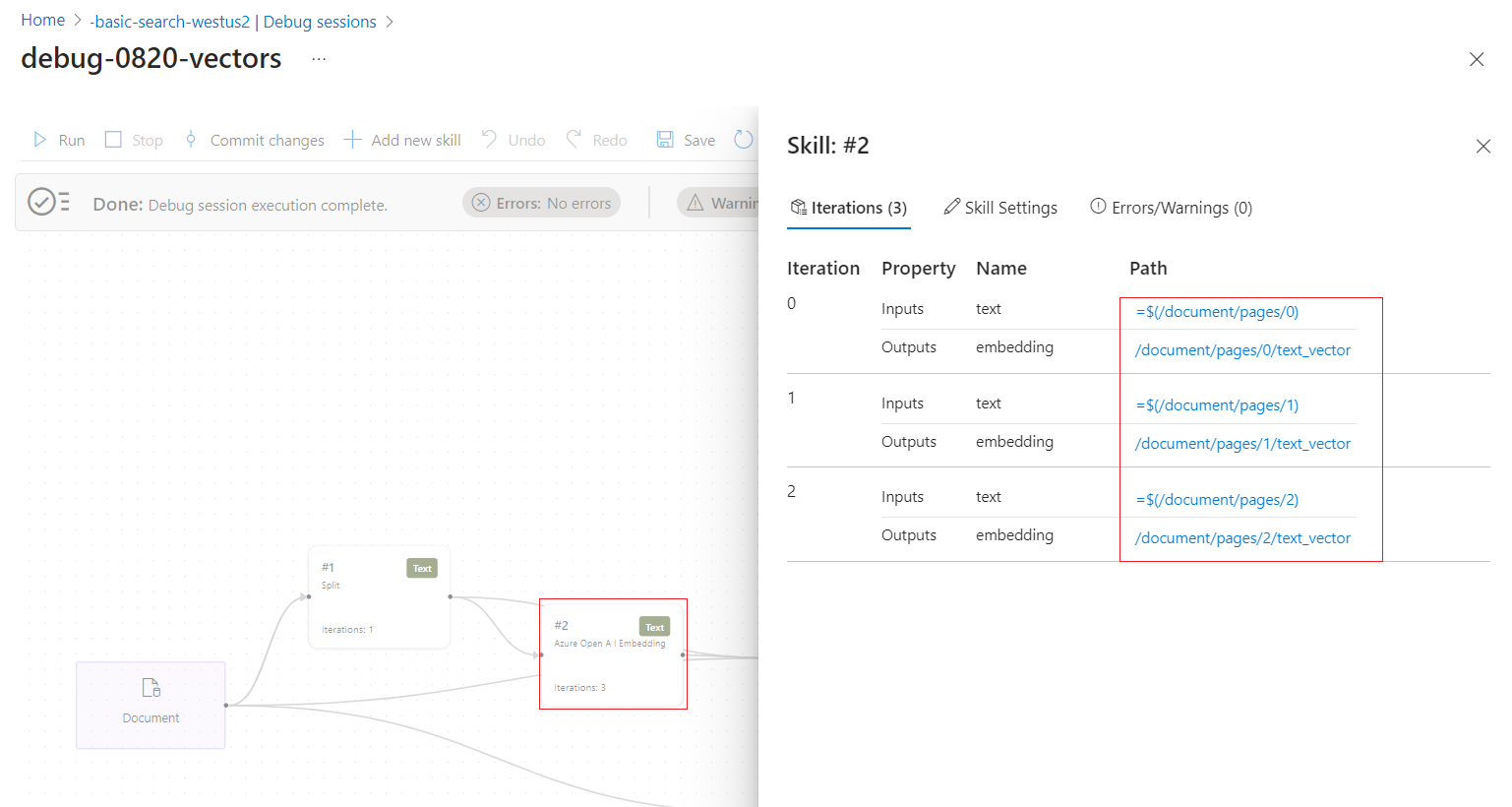
Seguire i collegamenti per approfondire l'elaborazione delle competenze. Ad esempio, lo screenshot seguente mostra l'output della prima iterazione della competenza Divisione testo.




Controllare i mapping degli indici
Se le competenze producono un output ma l'indice di ricerca è vuoto, controllare i mapping dei campi. I mapping dei campi specificano il modo in cui il contenuto viene spostato dalla pipeline in un indice di ricerca.
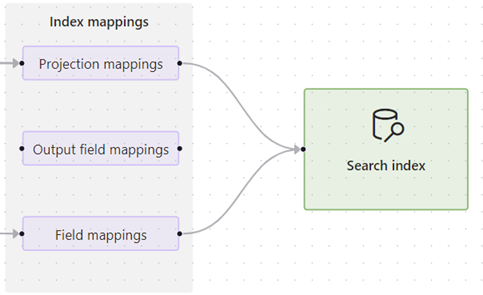
Selezionare una delle opzioni di mapping ed espandere la visualizzazione dettagli per esaminare le definizioni di origine e di destinazione.
I mapping di proiezione sono disponibili nei set di competenze che forniscono vettorizzazione integrata, ad esempio le competenze create dalla procedura guidata importare e vettorizzare i dati. Questi mapping determinano i mapping dei campi padre-figlio (blocco) e se viene creato un indice secondario solo per il contenuto in blocchi
I mapping dei campi di output sono disponibili negli indicizzatori e vengono usati quando i set di competenze richiamano competenze predefinite o personalizzate. Questi mapping vengono usati per impostare il percorso dati da un nodo nell'albero di arricchimento a un campo nell'indice di ricerca. Per altre informazioni sui percorsi, vedere sintassi del percorso del nodo di arricchimento.
I mapping dei campi sono disponibili nelle definizioni dell'indicizzatore e stabiliscono il percorso dei dati dal contenuto non elaborato nell'origine dati e un campo nell'indice. È possibile usare i mapping dei campi per aggiungere anche i passaggi di codifica e decodifica.
Questo esempio mostra i dettagli per un mapping di proiezione. È possibile modificare il codice JSON per risolvere eventuali problemi di mapping.

Modificare le definizioni delle competenze
Se i mapping dei campi sono corretti, controllare le singole competenze per la configurazione e il contenuto. Se una competenza non riesce a produrre l’output, potrebbe non essere presente una proprietà o un parametro,condizione che può essere determinata tramite i messaggi di errore e convalida.
Altri problemi, ad esempio un contesto o un'espressione di input non validi, possono essere più difficili da risolvere perché l'errore indica il problema ma non fornisce indicazioni su come risolverlo. Per informazioni sul contesto e sulla sintassi di input, vedere Arricchimenti di riferimento in un set di competenze di Azure AI Search. Per informazioni sui singoli messaggi, vedere Risoluzione degli errori e degli avvisi comuni dell'indicizzatore.
La procedura seguente mostra come ottenere informazioni su una competenza.
Selezionare una competenza nell'area di lavoro. Il riquadro Dettagli competenza si apre a destra.
Modificare una definizione di competenza usando Le impostazioni delle competenze. È possibile modificare direttamente il codice JSON.
Controllare la sintassi del percorso per fare riferimento ai nodi in un albero di arricchimento. Di seguito sono riportati alcuni dei percorsi di input più comuni:
/document/contentper blocchi di testo. Il nodo viene popolato dalla proprietà del contenuto del BLOB./document/merged_contentper blocchi di testo nei set di competenze che includono la competenza Unione testo./document/normalized_images/*per il testo riconosciuto o dedotto dalle immagini.
Eseguire il debug di una competenza personalizzata in locale
Eseguire il debug delle competenze personalizzate può essere più complesso perché il codice viene eseguito esternamente, quindi non è possibile usare la sessione di debug per eseguire il debug di tali competenze. Questa sezione descrive come eseguire il debug locale della competenza dell'API Web personalizzata, eseguire il debug della sessione, tramite Visual Studio Code e ngrok o Tunnelmole. Questa tecnica funziona con competenze personalizzate eseguite in Funzioni di Azure o in qualsiasi altro framework Web eseguito in locale, ad esempio FastAPI.
Ottenere un URL pubblico
Questa sezione descrive due approcci per ottenere un URL pubblico a una competenza personalizzata.
Usare Tunnelmole
Tunnelmole è uno strumento di tunneling open source che permette di creare un URL pubblico che inoltra le richieste al computer locale tramite un tunnel.
Installare Tunnelmole:
- npm:
npm install -g tunnelmole - Linux:
curl -s https://tunnelmole.com/sh/install-linux.sh | sudo bash - Mac:
curl -s https://tunnelmole.com/sh/install-mac.sh --output install-mac.sh && sudo bash install-mac.sh - Windows: eseguire l'installazione con npm. In alternativa, se NodeJS non è installato, scaricare il file .exe precompilato per Windows e inserirlo in un punto qualsiasi del PERCORSO.
- npm:
Eseguire questo comando per creare un nuovo tunnel:
tmole 7071Verrà visualizzato un risultato simile al seguente:
http://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071 https://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071Nell'esempio precedente,
https://m5hdpb-ip-49-183-170-144.tunnelmole.netesegue l’inoltro alla porta7071nel computer locale, che è la porta predefinita in cui vengono esposte le funzioni di Azure.
Usare ngrok
ngrok è un'applicazione multipiattaforma closed source popolare che permette di creare un URL di tunneling o inoltro, in modo che le richieste Internet raggiungano il computer locale. Usare ngrok per inoltrare le richieste da una pipeline di arricchimento nel servizio di ricerca al computer per consentire il debug locale.
Installare ngrok.
Aprire un terminale e passare alla cartella con l'eseguibile ngrok.
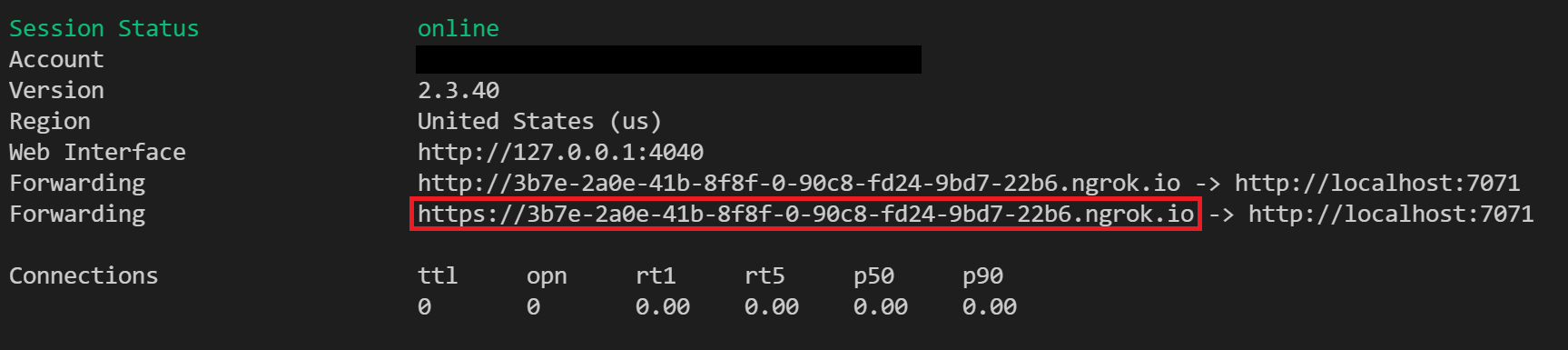
Eseguire ngrok con il comando seguente per creare un nuovo tunnel:
ngrok http 7071Nota
Per impostazione predefinita, le funzioni di Azure vengono esposte nella porta 7071. Altri strumenti e configurazioni potrebbero richiedere la specifica di una porta diversa.
All'avvio di ngrok copiare e salvare l'URL di inoltro pubblico per il passaggio successivo. L'URL di inoltro viene generato in modo casuale.
Configurare nel portale di Azure
Dopo aver creato un URL pubblico per la competenza personalizzata, modificare l'URI della competenza dell'API Web personalizzata all'interno di una sessione di debug per chiamare l'URL di inoltro tunnelmole o ngrok. Assicurarsi di aggiungere "/api/FunctionName" quando si usa la funzione di Azure per eseguire il codice del set di competenze.
È possibile modificare la definizione della competenza nella sezione Impostazioni competenza del riquadro Dettagli della competenza.
Eseguire test del codice
A questo punto, le nuove richieste dalla sessione di debug vengono in genere inviate alla funzione di Azure locale. È possibile usare i punti di interruzione in Visual Studio Code per eseguire il debug del codice o eseguire l’operazione un passaggio alla volta.
Passaggi successivi
Dopo aver compreso il layout e le funzionalità dell'editor visivo Sessioni di debug, provare l'esercitazione per fare un'esperienza pratica.