Esercitazione su C#: Usare set di competenze per generare contenuto ricercabile in Azure AI Search
Questa esercitazione illustra come usare Azure SDK per .NET per creare una pipeline di arricchimento tramite intelligenza artificiale per l'estrazione e le trasformazioni del contenuto durante l'indicizzazione.
I set di competenze aggiungono l'elaborazione dell'intelligenza artificiale al contenuto non elaborato, rendendolo più uniforme e ricercabile. Una volta appreso il funzionamento dei set di competenze, è possibile supportare un'ampia gamma di trasformazioni: dall'analisi delle immagini all'elaborazione del linguaggio naturale, fino all'elaborazione personalizzata fornita esternamente.
In questa esercitazione si apprenderà come:
- Definire oggetti in una pipeline di arricchimento.
- Generare un set di competenze. Richiamare OCR, rilevamento lingua, riconoscimento entità ed estrazione di frasi chiave.
- Eseguire la pipeline. Creare e caricare un indice di ricerca.
- Controllare i risultati usando la ricerca full-text.
Se non si ha una sottoscrizione di Azure, aprire un account gratuito prima di iniziare.
Panoramica
Questa esercitazione usa C# e la libreria client Azure.Search.Documents per creare un'origine dati, un indice, un indicizzatore e un set di competenze.
L'indicizzatore guida ogni passaggio nella pipeline, a partire dall'estrazione del contenuto di dati di esempio (immagini e testo non strutturato) in un contenitore BLOB in Archiviazione di Azure.
Una volta estratto il contenuto, il set di competenze esegue competenze predefinite da Microsoft per trovare ed estrarre informazioni. Queste competenze includono il riconoscimento ottico dei caratteri (OCR) nelle immagini, il rilevamento lingua nel testo, l’estrazione di frasi chiave e il riconoscimento di entità (organizzazioni). Le nuove informazioni create dal set di competenze vengono inviate ai campi in un indice. Dopo aver popolato l'indice, è possibile usare i campi in query, facet e filtri.
Prerequisiti
Nota
Per questa esercitazione è possibile usare un servizio di ricerca gratuito. Il livello gratuito consente di usare solo tre indici, tre indicizzatori e tre origini dati. Questa esercitazione crea un elemento per ogni tipo. Prima di iniziare, assicurarsi che lo spazio nel servizio sia sufficiente per accettare le nuove risorse.
Scaricare i file
Scaricare un file ZIP del repository di dati di esempio ed estrarre i contenuti. Procedura
Caricare i dati di esempio in Archiviazione di Azure
In Archiviazione di Azure, creare un nuovo contenitore e assegnargli il nome cog-search-demo.
Ottenere una stringa di connessione di archiviazione in modo da poter formulare una connessione in Azure AI Search.
A sinistra, selezionare Chiavi di accesso.
Copiare la stringa di connessione per la chiave uno o la chiave due. La stringa di connessione è simile all'esempio seguente:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Servizi di Azure AI
L'arricchimento tramite intelligenza artificiale predefinito è supportato dai Servizi di Azure AI, inclusi Servizio lingua e Visione di Azure AI per l'elaborazione del linguaggio naturale e delle immagini. Per carichi di lavoro di piccole dimensioni come in questa esercitazione, è possibile usare l'allocazione gratuita di 20 transazioni per indicizzatore. Per carichi di lavoro di dimensioni maggiori, collegare una risorsa multiarea di Servizi di Azure AI a un set di competenze per i prezzi con pagamento in base al consumo.
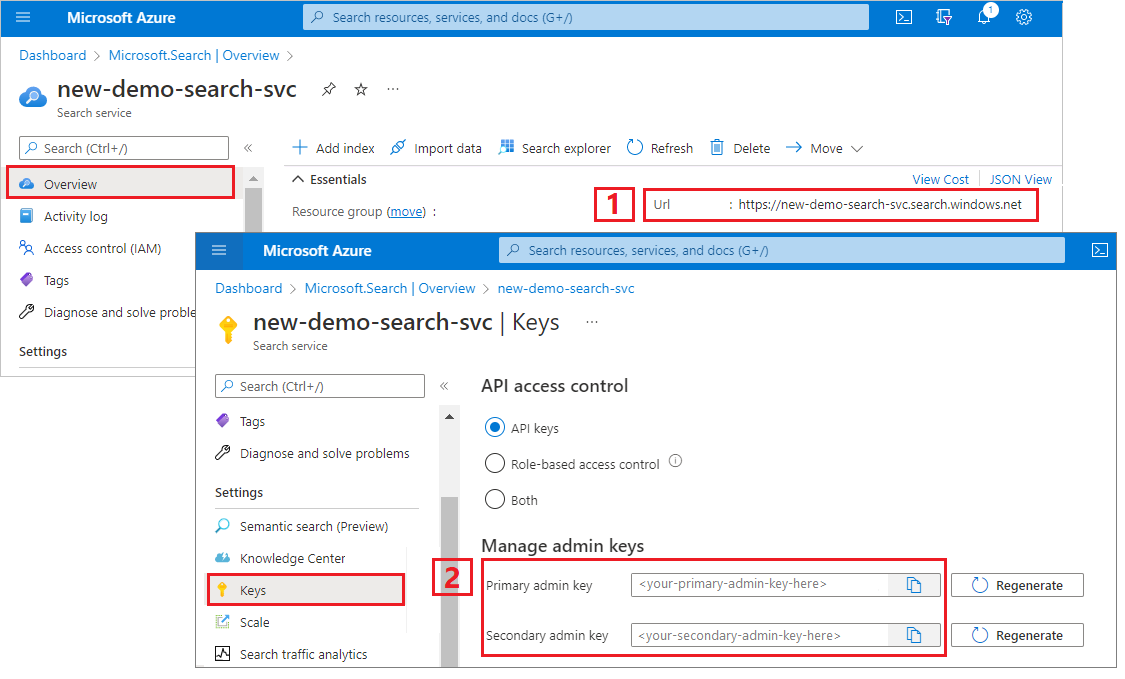
Copiare l'URL del servizio di ricerca e la chiave API
Per questa esercitazione, le connessioni ad Azure AI Search richiedono un endpoint e una chiave API. È possibile ottenere questi valori dal portale di Azure.
Accedere al portale di Azure, passare alla pagina Panoramica del servizio di ricerca e quindi copiare l'URL. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni>Chiavi, copiare una chiave amministratore. Le chiavi amministratore vengono usate per aggiungere, modificare ed eliminare oggetti. Sono disponibili due chiavi amministratore intercambiabili. Copiarne una.
Configurazione dell'ambiente
Iniziare aprendo Visual Studio e creando un nuovo progetto di app console che può essere eseguito in .NET Core.
Installare Azure.Search.Documents
Azure AI Search .NET SDK consiste in una libreria client che consente di gestire indici, origini dati, indicizzatori e set di competenze, nonché di caricare e gestire documenti ed eseguire query, il tutto senza doversi occupare dei dettagli di HTTP e JSON. Questa libreria client viene distribuita come pacchetto NuGet.
Per questo progetto, installare la versione 11 o successiva di Azure.Search.Documents e l'ultima versione di Microsoft.Extensions.Configuration.
In Visual Studio selezionare Strumenti>Gestione pacchetti NuGet>Gestisci pacchetti NuGet per la soluzione.
Cercare Azure.Search.Document.
Selezionare l'ultima versione e quindi scegliere Installa.
Ripetere i passaggi precedenti per installare Microsoft.Extensions.Configuration e Microsoft.Extensions.Configuration.Json.
Aggiungere le informazioni di connessione del servizio
Fare clic con il pulsante destro del mouse sul progetto in Esplora soluzioni e scegliere Aggiungi>Nuovo elemento.
Assegnare un nome al file
appsettings.jsone selezionare Aggiungi.Includere questo file nella directory di output.
- Fare clic con il pulsante destro del mouse su
appsettings.jsone scegliere Proprietà. - Modificare il valore di Copia nella directory di output impostandolo su Copia se più recente.
- Fare clic con il pulsante destro del mouse su
Copiare il codice JSON seguente nel nuovo file JSON.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Aggiungere le informazioni dell'account per il servizio di ricerca e l'archivio BLOB. Tenere presente che è possibile ottenere queste informazioni dalla procedura di provisioning del servizio indicata nella sezione precedente.
Per SearchServiceUri, immettere l'URL completo.
Aggiungere spazi dei nomi
In Program.cs aggiungere gli spazi dei nomi seguenti.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Creare un client
Creare un'istanza di SearchIndexClient e di SearchIndexerClient in Main.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Nota
I client si connettono al servizio di ricerca. Per evitare l'apertura di un numero eccessivo di connessioni, se possibile è consigliabile provare a condividere una singola istanza nell'applicazione. I metodi per abilitare tale condivisione sono thread-safe.
Aggiungere una funzione per uscire dal programma in caso di errore
Questa esercitazione ha lo scopo di semplificare la comprensione di ogni passaggio della pipeline di indicizzazione. Se si verifica un problema critico che impedisce al programma di creare l'origine dati, il set di competenze, l'indice o l'indicizzatore, il programma restituirà il messaggio di errore e verrà chiuso per consentire a comprensione e la gestione del problema.
Aggiungere ExitProgram a Main per gestire gli scenari che richiedono la chiusura del programma.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Creare la pipeline
In Azure AI Search, l'elaborazione IA viene eseguita durante l'indicizzazione o l'inserimento dati. In questa parte della procedura dettagliata vengono creati quattro oggetti: origine dati, definizione dell'indice, set di competenze e indicizzatore.
Passaggio 1: Creare un'origine dati
SearchIndexerClient include una proprietà DataSourceName che è possibile impostare su un oggetto SearchIndexerDataSourceConnection. Questo oggetto fornisce tutti i metodi necessari per creare, elencare, aggiornare o eliminare origini dati di Azure AI Search.
Creare una nuova istanza di SearchIndexerDataSourceConnection chiamando indexerClient.CreateOrUpdateDataSourceConnection(dataSource). Il codice seguente crea un'origine dati di tipo AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
Per una richiesta corretta, il metodo restituisce l'origine dati che è stata creata. Se si verifica un problema con la richiesta, ad esempio un parametro non valido, il metodo genererà un'eccezione.
A questo punto aggiungere una riga in Main per chiamare la funzione CreateOrUpdateDataSource appena aggiunta.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Compilare ed eseguire la soluzione. Siccome questa è la prima richiesta, controllare il portale di Azure per assicurarsi che l'origine dati sia stata creata in Azure AI Search. Nella pagina di panoramica del servizio di ricerca verificare che l'elenco Origini dati contenga un nuovo elemento. Potrebbe essere necessario attendere alcuni minuti prima che la pagina portale di Azure venga aggiornata.

Passaggio 2: creare un set di competenze
In questa sezione viene definito un set di passaggi di arricchimento da applicare ai dati. Ogni passaggio di arricchimento è noto come competenza e il set di passaggi di arricchimento è un set di competenze. Questa esercitazione usa competenze predefinite per il set di competenze:
Riconoscimento ottico dei caratteri per riconoscere testo stampato e scritto a mano nei file di immagine.
Text Merger per consolidare il testo da una raccolta di campi in un singolo campo di "contenuti uniti".
Rilevamento della lingua per identificare la lingua del contenuto.
Riconoscimento di entità per estrarre i nomi di organizzazioni dal contenuto nel contenitore BLOB.
Divisione del testo per suddividere il contenuto di grandi dimensioni in blocchi più piccoli prima di chiamare la competenza di estrazione di frasi chiave e la competenza di riconoscimento di entità. L'estrazione di frasi chiave e il riconoscimento di entità accettano input composti al massimo da 50.000 caratteri. Alcuni dei file di esempio devono essere suddivisi per rispettare questo limite.
Estrazione di frasi chiave per estrarre le frasi chiave principali.
Durante l'elaborazione iniziale, Azure AI Search esegue il cracking di ogni documento per estrarre il contenuto da formati di file diversi. Il testo trovato nel file di origine viene inserito in un campo content generato, uno per ogni documento. Impostare quindi l'input come "/document/content" per usare questo testo. Il contenuto dell'immagine viene inserito in un campo normalized_images generato, specificato in un set di competenze come /document/normalized_images/*.
Gli output possono essere mappati a un indice, usati come input per una competenza a valle, o entrambi, come nel caso del codice di lingua. Nell'indice, un codice di lingua è utile per le operazioni di filtro. Come input, il codice di lingua viene usato dalle competenze di analisi del testo per la selezione delle regole linguistiche per la separazione delle parole.
Per altre informazioni sui concetti di base dei set di competenze, vedere How to create a skillset (Come creare un set di competenze).
OCR skill (Competenza OCR)
OcrSkill estrae testo dalle immagini. Questa competenza presuppone che esista un campo normalized_images. Per generare questo campo, più avanti nell'esercitazione si imposterà la configurazione "imageAction" nella definizione dell'indicizzatore su "generateNormalizedImages".
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Competenza di unione
In questa sezione viene creata una MergeSkill che unisce il campo di contenuto del documento con il testo prodotto dalla competenza OCR.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Competenza di rilevamento lingua
La LanguageDetectionSkill rileva la lingua del testo di input e restituisce un codice lingua singolo per ogni documento inviato nella richiesta. Viene usato l'output della competenza Rilevamento lingua come parte dell'input per la competenza Divisione testo.
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Competenza di divisione del testo
La SplitSkill divide il testo in pagine e limita la lunghezza della pagina a 4.000 caratteri, misurata da String.Length. L'algoritmo tenta di suddividere il testo in blocchi di dimensioni massime pari a maximumPageLength. In questo caso, l'algoritmo cercherà di interrompere una frase al suo limite, quindi la dimensione del blocco potrebbe essere lievemente inferiore a maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Competenza di riconoscimento entità
Questa istanza EntityRecognitionSkill è impostata per riconoscere il tipo di categoria organization. La EntityRecognitionSkill può anche riconoscere i tipi di categoria person e location.
Si noti che il campo "context" è impostato su "/document/pages/*" con un asterisco. Questo significa che il passaggio di arricchimento viene chiamato per ogni pagina presente in "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Competenza di estrazione di frasi chiave
Come l'istanza EntityRecognitionSkill appena creata, la KeyPhraseExtractionSkill viene chiamata per ogni pagina del documento.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Compilare e creare il set di competenze
Compilare lo SearchIndexerSkillset usando le competenze create.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Aggiungere le righe seguenti a Main.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Passaggio 3: creare un indice
In questa sezione viene definito lo schema dell'indice specificando i campi da includere nell'indice di ricerca e gli attributi di ricerca per ogni campo. I campi hanno un tipo e possono accettare attributi che determinano il modo in cui viene usato il campo (searchable, sortable e così via). Non è necessario che i nomi dei campi in un indice corrispondano esattamente ai nomi dei campi nell'origine. In un passaggio successivo verranno aggiunti i mapping dei campi in un indicizzatore per collegare i campi di origine e destinazione. Per questo passaggio, definire l'indice usando le convenzioni di denominazione dei campi pertinenti per l'applicazione di ricerca in questione.
Questo esercizio usa i campi e i tipi di campi seguenti:
| Nomi dei campi | Tipi di campo |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
List<Edm.String> |
organizations |
List<Edm.String> |
Creare una classe DemoIndex
I campi per questo indice vengono definiti usando una classe modello. Ogni proprietà della classe modello contiene attributi che determinano i comportamenti correlati alla ricerca del campo di indice corrispondente.
La classe modello verrà aggiunta a un nuovo file C#. Fare clic con il pulsante destro del mouse sul progetto e scegliere Aggiungi>Nuovo elemento..., selezionare "Classe", assegnare al file il nome DemoIndex.cs e quindi selezionare Aggiungi.
Indicare che si vogliono usare i tipi degli spazi dei nomi Azure.Search.Documents.Indexes e System.Text.Json.Serialization.
Aggiungere la definizione della classe del modello seguente a DemoIndex.cs e includerla nello stesso spazio dei nomi in cui viene creato l'indice.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Dopo aver definito una classe modello, di nuovo in Program.cs è possibile creare una definizione di indice in modo molto semplice. Il nome di questo indice sarà demoindex. Se esiste già un indice con tale nome, viene eliminato.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Durante i test, è possibile che si tenti di creare l'indice più di una volta. Per questo motivo verificare se l'indice che si sta per creare esiste già prima di tentare di crearlo.
Aggiungere le righe seguenti a Main.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Aggiungere l'istruzione using seguente per risolvere il riferimento di disambiguazione.
using Index = Azure.Search.Documents.Indexes.Models;
Per altre informazioni sui concetti degli indici, vedere Creare un indice (API REST).
Passaggio 4: creare ed eseguire un indicizzatore
Finora sono stati creati un'origine dati, un set di competenze e un indice. Questi tre componenti diventano parte di un indicizzatore che riunisce tutti i dati in un'unica operazione in più fasi. Per unire questi elementi in un indicizzatore, è necessario definire mapping dei campi.
Gli oggetti fieldMappings vengono elaborati prima del set di competenze, eseguendo il mapping dei campi di origine dall'origine dati ai campi di destinazione in un indice. Se i nomi e i tipi di campo sono uguali alle due estremità, non è necessario alcun mapping.
Gli oggetti outputFieldMappings vengono elaborati dopo il set di competenze facendo riferimento agli oggetti sourceFieldNames che non esistono fino a quando non vengono creati dall'individuazione o dall'arricchimento dei documenti. L'oggetto targetFieldName è un campo in un indice.
Oltre ad associare gli input agli output, è anche possibile usare i mapping dei campi per rendere flat le strutture dei dati. Per altre informazioni, vedere Come eseguire il mapping dei campi migliorati a un indice ricercabile.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Aggiungere le righe seguenti a Main.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
L'elaborazione dell'indicizzatore richiederà del tempo. Anche se il set di dati è piccolo, le competenze analitiche prevedono un utilizzo elevato delle risorse di calcolo. Alcune competenze, ad esempio l'analisi delle immagini, hanno un'esecuzione prolungata.
Suggerimento
La creazione di un indicizzatore richiama la pipeline. Eventuali problemi a raggiungere i dati, per il mapping di input e output o nell'ordine delle operazioni vengono visualizzati in questa fase.
Esaminare la creazione dell'indicizzatore
Il codice imposta "maxFailedItems" su -1, che indica al motore di indicizzazione di ignorare gli errori durante l'importazione dei dati. Ciò è utile dato che l'origine dati di esempio include pochi documenti. Per un'origine dati più grande sarebbe necessario impostare un valore maggiore di 0.
Si noti inoltre che "dataToExtract" è impostato su "contentAndMetadata". Questa istruzione indica all'indicizzatore di estrarre automaticamente il contenuto dai vari formati di file, oltre ai metadati correlati a ogni file.
Quando viene estratto il contenuto, è possibile impostare imageAction per estrarre il testo dalle immagini trovate nell'origine dati. L'impostazione di "imageAction" su "generateNormalizedImages", unita alla competenza OCR e alla competenza di unione del testo, indica all'indicizzatore di estrarre il testo dalle immagini (ad esempio, la parola "stop" da un segnale stradale di stop) e incorporarlo come parte del campo del contenuto. Questo comportamento si applica sia alle immagini incorporate nei documenti, ad esempio un'immagine all'interno di un PDF, che alle immagini trovate nell'origine dati, ad esempio un file JPG.
Monitorare l'indicizzazione
Dopo averlo definito, l'indicizzatore viene eseguito automaticamente quando si invia la richiesta. A seconda delle competenze definite, l'indicizzazione può richiedere più tempo del previsto. Per scoprire se l'indicizzatore è ancora in esecuzione, usare il metodo GetStatus.
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo rappresenta lo stato corrente e la cronologia di esecuzione di un indicizzatore.
Gli avvisi sono comuni con alcune combinazioni di file di origine e competenze e non sempre indicano un problema. In questa esercitazione, gli avvisi sono innocui (ad esempio, nessun input di testo dai file JPEG).
Aggiungere le righe seguenti a Main.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Ricerca
Nelle app console dell'esercitazione di Azure AI Search, generalmente viene aggiunto un ritardo di 2 secondi prima dell'esecuzione delle query che restituiscono risultati, ma poiché il completamento dell'arricchimento richiede diversi minuti, l'app console verrà chiusa e verrà usato un altro approccio.
L'opzione più semplice è Esplora ricerche nel portale di Azure. È possibile eseguire prima una query vuota che restituisce tutti i documenti oppure una ricerca più mirata che restituisce il nuovo contenuto del campo creato dalla pipeline.
Nel portale di Azure, nella pagina di panoramica della ricerca, selezionare Indici.
Trovare
demoindexnell'elenco. Dovrebbero essere presenti 14 documenti. Se il numero di documenti è zero, significa l'indicizzatore è ancora in esecuzione o che la pagina non è stata ancora aggiornata.Selezionare
demoindex. Esplora ricerche è la prima scheda.È possibile iniziare a eseguire ricerche nel contenuto subito dopo il caricamento del primo documento. Per verificare se esiste contenuto, eseguire una query non specificata facendo clic su Cerca. Questa query restituisce tutti i documenti attualmente indicizzati, offrendo un'idea del contenuto dell'indice.
Incollare quindi la stringa seguente per ottenere risultati più gestibili:
search=*&$select=id, languageCode, organizations
Reimpostare ed eseguire di nuovo
Nelle prime fasi di sviluppo sperimentali, l'approccio più pratico per l'iterazione di progetto consiste nell'eliminare gli oggetti da Azure AI Search e consentire al codice di ricompilarli. I nomi di risorsa sono univoci. L'eliminazione di un oggetto consente di ricrearlo usando lo stesso nome.
Il codice di esempio per questa esercitazione verifica la presenza di oggetti esistenti e li elimina in modo da poter eseguire nuovamente il codice. È anche possibile usare il portale di Azure per eliminare indici, indicizzatori, origini dati e set di competenze.
Risultati
Questa esercitazione ha illustrato i passaggi di base per la creazione di una pipeline di indicizzazione arricchita tramite la creazione delle parti componenti: un'origine dati, un set di competenze, un indice e un indicizzatore.
Sono state presentate le competenze predefinite, oltre alla definizione del set di competenze e ai meccanismi di concatenamento delle competenze tramite input e output. Si è anche appreso che outputFieldMappings nella definizione dell'indicizzatore è obbligatorio per il routing dei valori arricchiti dalla pipeline in un indice cercabile in un servizio Azure AI Search.
Infine, è stato descritto come testare i risultati e reimpostare il sistema per ulteriori iterazioni. Si è appreso che l'esecuzione di query sull'indice consente di restituire l'output creato dalla pipeline di indicizzazione arricchita. È stato inoltre descritto come controllare lo stato dell'indicizzatore e quali oggetti eliminare prima di eseguire di nuovo una pipeline.
Pulire le risorse
Quando si lavora nella propria sottoscrizione, alla fine di un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile trovare e gestire le risorse nella portale di Azure, usando il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Passaggi successivi
Ora che si ha familiarità con tutti gli oggetti in una pipeline di arricchimento tramite intelligenza artificiale, verranno esaminate in dettaglio le definizioni dei set di competenze e le singole competenze.