Disponibilità elevata (affidabilità) in Database di Azure per PostgreSQL - Server flessibile
SI APPLICA A: Database di Azure per PostgreSQL - Server flessibile
Database di Azure per PostgreSQL - Server flessibile
Questo articolo descrive la disponibilità elevata in Database di Azure per PostgreSQL - Server flessibile, che include zone di disponibilità e ripristino tra aree e continuità aziendale. Per una panoramica più dettagliata dell'affidabilità in Azure, vedere Affidabilità di Azure.
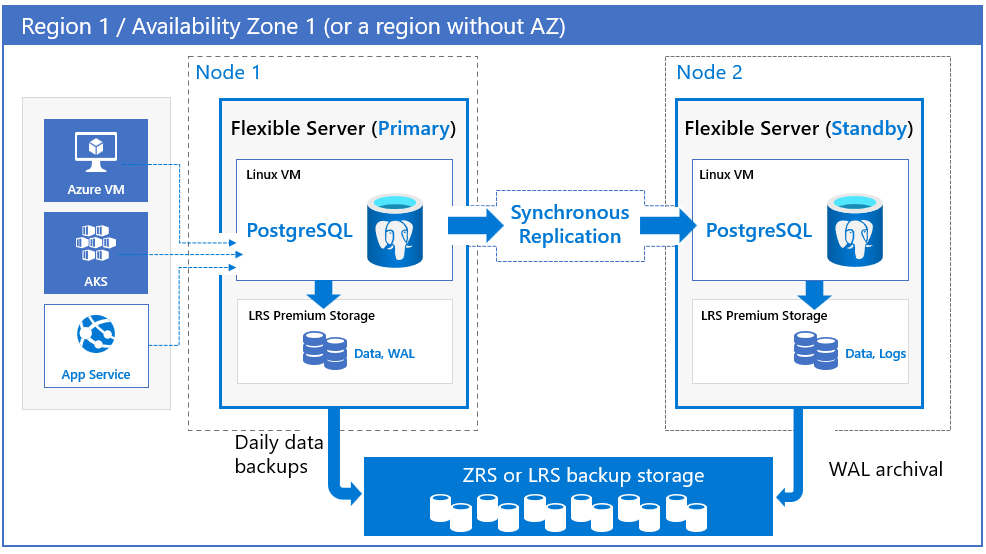
Database di Azure per PostgreSQL: il server flessibile offre un supporto a disponibilità elevata effettuando il provisioning di repliche primarie e standby separate fisicamente, all'interno della stessa zona di disponibilità (zona) o tra zone di disponibilità (con ridondanza della zona). Questo modello a disponibilità elevata è progettato per garantire che i dati di cui è stato eseguito il commit non vengano mai persi in caso di errori. In una configurazione a disponibilità elevata i dati vengono sottoposti a commit sincrono sia nei server primario che in quello di standby. Il modello è progettato in modo che il database non diventi un singolo punto di errore nell'architettura software. Per altre informazioni sul supporto per la disponibilità elevata e la zona di disponibilità, vedere Supporto della zona di disponibilità.
Supporto della zona di disponibilità
Le zone di disponibilità sono gruppi di data center separati fisicamente all'interno di ogni area di Azure. In caso di errore di una zona, i servizi possono eseguire il failover in una delle zone rimanenti.
Per altre informazioni sulle zone di disponibilità in Azure, vedere Che cosa sono le zone di disponibilità?
Database di Azure per PostgreSQL : il server flessibile supporta modelli con ridondanza della zona e di zona per configurazioni a disponibilità elevata. Entrambe le configurazioni a disponibilità elevata consentono la funzionalità di failover automatico senza perdita di dati durante gli eventi pianificati e non pianificati.
Con ridondanza della zona. La disponibilità elevata con ridondanza della zona distribuisce una replica standby in una zona diversa con funzionalità di failover automatico. La ridondanza della zona offre il massimo livello di disponibilità, ma richiede la configurazione della ridondanza dell'applicazione tra le zone. Per questo motivo, scegliere ridondanza della zona quando si vuole proteggere dagli errori a livello di zona di disponibilità e quando la latenza tra le zone di disponibilità è accettabile. Anche se può verificarsi un impatto sulla latenza sulle scritture e sui commit a causa della replica sincrona, non influisce sulle query di lettura. Questo impatto è molto specifico per i carichi di lavoro, il tipo di SKU selezionato e l'area.
È possibile scegliere l'area e le zone di disponibilità sia per i server primari che per i server di standby. Viene effettuato il provisioning del server di replica standby nella zona di disponibilità scelta nella stessa area con una configurazione di calcolo, archiviazione e rete simile a quella del server primario. I file di dati e i file di log delle transazioni (log write-ahead, k.a WAL) vengono archiviati nell'archiviazione con ridondanza locale all'interno di ogni zona di disponibilità, archiviando automaticamente tre copie di dati. Una configurazione con ridondanza della zona fornisce l'isolamento fisico dell'intero stack tra i server primari e di standby.

A zona. Scegliere una distribuzione a livello di zona quando si vuole ottenere il massimo livello di disponibilità all'interno di una singola zona di disponibilità, ma con la latenza di rete più bassa. È possibile scegliere l'area e la zona di disponibilità per distribuire entrambi il server di database primario. Viene eseguito automaticamente il provisioning e la gestione di un server di replica standby nella stessa zona di disponibilità, con un calcolo, un'archiviazione e una configurazione di rete simili, come server primario. Una configurazione a livello di zona protegge i database da errori a livello di nodo e consente anche di ridurre i tempi di inattività delle applicazioni durante gli eventi di inattività pianificati e non pianificati. I dati del server primario vengono replicati in modo sincrono nella replica di standby. In caso di interruzione del server primario, il server viene sottoposto automaticamente a failover nella replica di standby.


Nota
I modelli di distribuzione a ridondanza della zona e della zona si comportano in modo architetturale allo stesso modo. Le varie discussioni nelle sezioni seguenti si applicano a entrambe, a meno che non venga richiamato diversamente.
Prerequisiti
Ridondanza della zona:
L'opzione di ridondanza della zona è disponibile solo nelle aree che supportano le zone di disponibilità.
La ridondanza della zona non è supportata per:
- Database di Azure per PostgreSQL: SKU a server singolo.
- Livello di calcolo con burst.
- Aree con disponibilità a zona singola.
Zonale:
- L'opzione di distribuzione a livello di zona è disponibile in tutte le aree di Azure in cui è possibile distribuire il server flessibile.
Funzionalità di disponibilità elevata
Una replica standby viene distribuita nella stessa configurazione della macchina virtuale, inclusi vCore, archiviazione, impostazioni di rete, come server primario.
È possibile aggiungere il supporto della zona di disponibilità per un server di database esistente.
È possibile rimuovere la replica di standby disabilitando la disponibilità elevata.
È possibile scegliere le zone di disponibilità per i server di database primario e standby per la disponibilità con ridondanza della zona.
Le operazioni, quali l'arresto, l'avvio e il riavvio, vengono eseguite contemporaneamente sui server di database primari e di standby.
Nei modelli con ridondanza della zona e zona, i backup automatici vengono eseguiti periodicamente dal server di database primario. Allo stesso tempo, i log delle transazioni vengono archiviati continuamente nell'archivio di backup dalla replica di standby. Se l'area supporta le zone di disponibilità, i dati di backup vengono archiviati nell'archiviazione con ridondanza della zona. Nelle aree che non supportano le zone di disponibilità, i dati di backup vengono archiviati nell'archiviazione con ridondanza locale.
I client si connettono sempre al nome host finale del server di database primario.
Tutte le modifiche apportate ai parametri del server vengono applicate anche alla replica di standby.
Possibilità di riavviare il server per rilevare eventuali modifiche ai parametri statici del server.
Le attività di manutenzione periodiche, ad esempio gli aggiornamenti delle versioni secondarie, vengono eseguite prima in standby e, per ridurre i tempi di inattività, lo standby viene alzato di livello primario in modo che i carichi di lavoro possano continuare, mentre le attività di manutenzione vengono applicate al nodo rimanente.
Monitorare l'integrità della disponibilità elevata
Monitoraggio dello stato di integrità a disponibilità elevata in Database di Azure per PostgreSQL - Server flessibile offre una panoramica continua dell'integrità e dell'idoneità delle istanze abilitate per la disponibilità elevata. Questa funzionalità di monitoraggio sfrutta il framework Integrità risorse Check (RHC) di Azure per rilevare e segnalare eventuali problemi che potrebbero influire sulla disponibilità complessiva o sulla disponibilità complessiva del failover del database. Valutando le metriche chiave, ad esempio lo stato della connessione, lo stato di failover e l'integrità della replica dei dati, il monitoraggio dello stato di integrità a disponibilità elevata consente la risoluzione proattiva dei problemi e consente di mantenere il tempo di attività e le prestazioni del database.
I clienti possono usare il monitoraggio dello stato di integrità a disponibilità elevata per:
- Ottenere informazioni in tempo reale sull'integrità delle repliche primarie e standby, con indicatori di stato che rivelano potenziali problemi, ad esempio prestazioni ridotte o blocco della rete.
- Configurare avvisi per notifiche tempestive su eventuali modifiche dello stato della disponibilità elevata, assicurando un'azione immediata per risolvere potenziali interruzioni.
- Ottimizzare l'idoneità del failover identificando e risolvendo i problemi prima che influiscano sulle operazioni del database.
Per una guida dettagliata sulla configurazione e l'interpretazione degli stati di integrità a disponibilità elevata, vedere l'articolo principale Monitoraggio dello stato di integrità disponibilità elevata per Database di Azure per PostgreSQL - Server flessibile.
Limitazioni della disponibilità elevata
A causa della replica sincrona al server di standby, in particolare con una configurazione con ridondanza della zona, le applicazioni possono riscontrare una latenza di scrittura e commit elevata.
La replica di standby non può essere usata per le query di lettura.
A seconda del carico di lavoro e dell'attività nel server primario, il processo di failover potrebbe richiedere più di 120 secondi a causa del ripristino coinvolto nella replica di standby prima che possa essere alzato di livello.
Il server standby recupera in genere i file WAL a 40 MB/s. Per sku più grandi, questa velocità può aumentare fino a 200 MB/s. Se il carico di lavoro supera questo limite, è possibile riscontrare un tempo prolungato per il completamento del ripristino durante il failover o dopo aver stabilito un nuovo standby.
Il riavvio del server di database primario riavvia anche la replica di standby.
La configurazione di un standby aggiuntivo non è supportata.
La configurazione delle attività di gestione avviate dal cliente non può essere pianificata durante la finestra di manutenzione gestita.
Gli eventi pianificati, ad esempio il ridimensionamento dell'elaborazione e la scalabilità dell'archiviazione, avvengono prima in standby e quindi nel server primario. Attualmente, il server non esegue il failover per queste operazioni pianificate.
Se la decodifica logica o la replica logica è configurata con un server flessibile configurato per la disponibilità, in caso di failover nel server di standby, gli slot di replica logica non vengono copiati nel server di standby. Per mantenere gli slot di replica logica e garantire la coerenza dei dati dopo un failover, è consigliabile usare l'estensione Slot di failover PG. Per altre informazioni su come abilitare questa estensione, vedere la documentazione.
La configurazione delle zone di disponibilità tra la rete virtuale privata e l'accesso pubblico con endpoint privati non è supportata. È necessario configurare le zone di disponibilità all'interno di una rete virtuale (estesa tra zone di disponibilità all'interno di un'area) o l'accesso pubblico con endpoint privati.
Le zone di disponibilità vengono configurate solo all'interno di una singola area. Le zone di disponibilità non possono essere configurate tra aree diverse.
Contratto di servizio
Il modello di zona offre un contratto di servizio per il tempo di attività del 99,95%.
Il modello di ridondanza della zona offre un contratto di servizio con tempo di attività del 99,99%.
Creare un Database di Azure per PostgreSQL - Server flessibile con la zona di disponibilità abilitata
Per informazioni su come creare un server flessibile Database di Azure per PostgreSQL per la disponibilità elevata con zone di disponibilità, vedere Avvio rapido: Creare un server flessibile Database di Azure per PostgreSQL nel portale di Azure.
Ridistribuzione e migrazione della zona di disponibilità
Per informazioni su come abilitare o disabilitare la configurazione a disponibilità elevata nel server flessibile nei modelli di distribuzione con ridondanza della zona e zona, vedere Gestire la disponibilità elevata nel server flessibile.
Componenti e flusso di lavoro a disponibilità elevata
Completamento delle transazioni
Le operazioni di scrittura e commit attivate dalle transazioni dell'applicazione vengono prima registrate nel wal nel server primario. Questi vengono quindi trasmessi al server di standby usando il protocollo di streaming Postgres. Una volta salvati in modo permanente i log nell'archiviazione del server standby, il server primario viene riconosciuto per il completamento della scrittura. L'applicazione viene confermata solo dopo il commit della transazione. Questo round trip aggiuntivo aggiunge una maggiore latenza all'applicazione. La percentuale di impatto dipende dall'applicazione. Questo processo di riconoscimento non attende che i log vengano applicati al server di standby. Il server standby è in modalità di ripristino permanente fino a quando non viene alzato di livello.
Controllo integrità
Il monitoraggio dell'integrità del server flessibile controlla periodicamente sia l'integrità primaria che quella di standby. Dopo più ping, se il monitoraggio dell'integrità rileva che un server primario non è raggiungibile, il servizio avvia quindi un failover automatico al server di standby. L'algoritmo di monitoraggio dell'integrità si basa su più punti dati per evitare situazioni false positive.
Modalità di failover
Il server flessibile supporta due modalità di failover, failover pianificato e failover non pianificato. In entrambe le modalità, una volta interrotta la replica, il server standby esegue il ripristino prima di essere alzato di livello come primario e viene aperto per la lettura/scrittura. Con le voci DNS automatiche aggiornate con il nuovo endpoint server primario, le applicazioni possono connettersi al server usando lo stesso endpoint. Un nuovo server standby viene stabilito in background, in modo che l'applicazione possa mantenere la connettività.
Stato di disponibilità elevata
L'integrità dei server primario e standby viene monitorata continuamente e vengono eseguite azioni appropriate per correggere i problemi, incluso l'attivazione di un failover nel server di standby. La tabella seguente elenca i possibili stati di disponibilità elevata:
| Stato | Descrizione |
|---|---|
| Inizializzazione in corso | Nel processo di creazione di un nuovo server standby. |
| Replica dei dati | Dopo aver creato lo standby, viene aggiornato con il database primario. |
| Integra | La replica è in stato stabile e integra. |
| Failover | Il server di database è in corso di failover al standby. |
| Rimozione dello standby | Nel processo di eliminazione del server di standby. |
| Non abilitato | La disponibilità elevata non è abilitata. |
Nota
È possibile abilitare la disponibilità elevata durante la creazione del server o in un secondo momento. Se si abilita o si disabilita la disponibilità elevata durante la fase di post-creazione, è consigliabile operare quando l'attività del server primario è bassa.
Operazioni con stato stabile
Le applicazioni client PostgreSQL sono connesse al server primario usando il nome del server di database. Le letture delle applicazioni vengono gestite direttamente dal server primario. Allo stesso tempo, i commit e le scritture vengono confermati nell'applicazione solo dopo che i dati di log sono persistenti sia nel server primario che nella replica standby. A causa di questo round trip aggiuntivo, le applicazioni possono aspettarsi una latenza elevata per operazioni di scrittura e commit. È possibile monitorare l'integrità della disponibilità elevata nel portale.
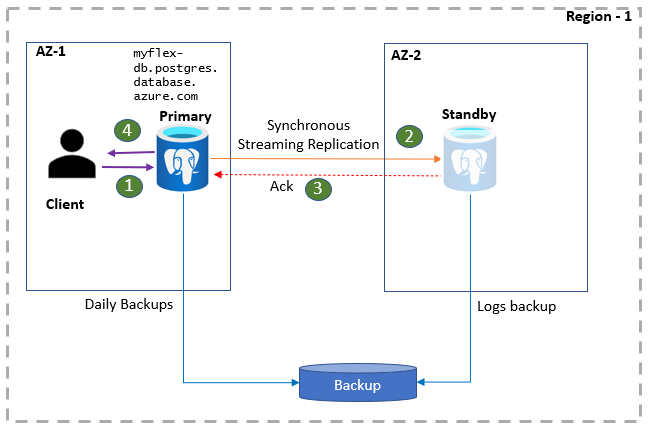
- I client si connettono al server flessibile ed eseguono operazioni di scrittura.
- Le modifiche vengono replicate nel sito di standby.
- Primary riceve un riconoscimento.
- Le scritture/commit vengono riconosciute.
Ripristino temporizzato dei server a disponibilità elevata
Per i server flessibili configurati con disponibilità elevata, i dati di log vengono replicati in tempo reale nel server di standby. Eventuali errori utente nel server primario, ad esempio un rilascio accidentale di una tabella o aggiornamenti di dati non corretti, vengono replicati nella replica di standby. Non è quindi possibile usare standby per eseguire il ripristino da tali errori logici. Per eseguire il ripristino da tali errori, è necessario eseguire un ripristino temporizzato dal backup. Usando la funzionalità di ripristino temporizzato di un server flessibile, è possibile eseguire il ripristino nel tempo prima che si sia verificato l'errore. Un nuovo server di database viene ripristinato come server flessibile a zona singola con un nuovo nome server fornito dall'utente per i database configurati con disponibilità elevata. È possibile usare il server ripristinato per alcuni casi d'uso:
È possibile usare il server ripristinato per la produzione e, facoltativamente, abilitare la disponibilità elevata con replica standby nella stessa zona o in un'altra zona nella stessa area.
Se si desidera ripristinare un oggetto, esportarlo dal server di database ripristinato e importarlo nel server di database di produzione.
Se si vuole clonare il server di database per scopi di test e sviluppo o per eseguire il ripristino per qualsiasi altro scopo, è possibile eseguire il ripristino temporizzato.
Per informazioni su come eseguire un ripristino temporizzato di un server flessibile, vedere Ripristino temporizzato di un server flessibile.
Supporto per il failover
Failover pianificato
Gli eventi di inattività pianificati includono aggiornamenti software periodici pianificati di Azure e aggiornamenti di versioni secondarie. È anche possibile usare un failover pianificato per restituire il server primario a una zona di disponibilità preferita. Se configurata in disponibilità elevata, queste operazioni vengono applicate per la prima volta alla replica standby mentre le applicazioni continuano ad accedere al server primario. Dopo l'aggiornamento della replica standby, le connessioni server primarie vengono svuotate e viene attivato un failover, che attiva la replica standby come primaria con lo stesso nome del server di database. Le applicazioni client devono riconnettersi con lo stesso nome del server di database al nuovo server primario e possono riprendere le operazioni. Viene stabilito un nuovo server standby nella stessa zona del server primario precedente.
Per altre operazioni avviate dall'utente, ad esempio il calcolo di scalabilità o l'archiviazione su larga scala, le modifiche vengono applicate prima al standby, seguito dal database primario. Attualmente, non viene eseguito il failover del servizio al server di standby, quindi durante l'esecuzione dell'operazione di ridimensionamento nel server primario si verifica un breve tempo di inattività per le applicazioni.
È anche possibile usare questa funzionalità per eseguire il failover nel server di standby con tempi di inattività ridotti. Ad esempio, il database primario potrebbe trovarsi in una zona di disponibilità diversa rispetto all'applicazione, dopo un failover non pianificato. Si vuole riportare il server primario nella zona precedente per la condivisione con l'applicazione.
Quando si esegue questa funzionalità, il server standby viene prima preparato per assicurarsi che venga intercettato con le transazioni recenti, consentendo all'applicazione di continuare a eseguire operazioni di lettura/scrittura. Lo standby viene quindi alzato di livello e le connessioni al database primario vengono interrotte. L'applicazione può continuare a scrivere nel server primario mentre viene stabilito un nuovo server di standby in background. Di seguito sono riportati i passaggi necessari per il failover pianificato:
| Step | Descrizione | Previsto tempo di inattività dell'app? |
|---|---|---|
| 1 | Attendere che il server di standby abbia preso in contatto con il server primario. | No |
| 2 | Il sistema di monitoraggio interno avvia il flusso di lavoro di failover. | No |
| 3 | Le scritture dell'applicazione vengono bloccate quando il server di standby è vicino al numero di sequenza del log primario (LSN). | Sì |
| 4 | Il server standby viene alzato di livello come server indipendente. | Sì |
| 5 | Il record DNS viene aggiornato con l'indirizzo IP del nuovo server standby. | Sì |
| 6 | Applicazione per riconnettersi e riprendere la lettura/scrittura con la nuova replica primaria. | No |
| 7 | Viene stabilito un nuovo server standby in un'altra zona. | No |
| 8 | Il server standby inizia a recuperare i log (dal BLOB di Azure) che non è stato rilevato durante la sua creazione. | No |
| 9 | Viene stabilito uno stato stabile tra il server primario e quello di standby. | No |
| 10 | Processo di failover pianificato completato. | No |
Il tempo di inattività dell'applicazione inizia al passaggio 3 e può riprendere l'operazione dopo il passaggio 5. Il resto dei passaggi avviene in background senza influire sulle operazioni di scrittura e commit dell'applicazione.
Suggerimento
Con il server flessibile, è possibile pianificare facoltativamente le attività di manutenzione avviate da Azure scegliendo una finestra di 60 minuti in un giorno della preferenza in cui le attività nei database dovrebbero essere basse. Durante tale finestra si verificherebbero attività di manutenzione di Azure, ad esempio l'applicazione di patch o gli aggiornamenti di versioni secondarie. Se non si sceglie una finestra personalizzata, per il server è selezionata una finestra di 1 ora solare allocata tra le 11 e le 7:00. Queste attività di manutenzione avviate da Azure vengono eseguite anche nella replica standby per server flessibili configurati con zone di disponibilità.
Per un elenco dei possibili eventi di inattività pianificati, vedere Eventi di inattività pianificati.
Failover non pianificato
Tempi di inattività non pianificati possono verificarsi a causa di interruzioni impreviste, ad esempio errori hardware sottostanti, problemi di rete e bug software. Se il server di database configurato con disponibilità elevata diventa inattivo in modo imprevisto, la replica di standby viene attivata e i client possono riprendere le operazioni. Se non è configurato con disponibilità elevata e se il tentativo di riavvio non riesce, viene eseguito automaticamente il provisioning di un nuovo server di database. Anche se non è possibile evitare tempi di inattività non pianificati, il server flessibile consente di ridurre i tempi di inattività eseguendo automaticamente operazioni di ripristino senza richiedere l'intervento umano.
Per informazioni sui failover non pianificati e sui tempi di inattività, inclusi i possibili scenari, vedere Mitigazione dei tempi di inattività non pianificati.
Test di failover (failover forzato)
Con un failover forzato, è possibile simulare uno scenario di interruzione non pianificato durante l'esecuzione del carico di lavoro di produzione e osservare il tempo di inattività dell'applicazione. È anche possibile usare un failover forzato quando il server primario non risponde.
Un failover forzato causa il arresto del server primario e avvia il flusso di lavoro di failover in cui viene eseguita l'operazione di promozione dello standby. Dopo che lo standby completa il processo di ripristino fino all'ultimo commit dei dati, viene alzato di livello come server primario. I record DNS vengono aggiornati e l'applicazione può connettersi al server primario alzato di livello. L'applicazione può continuare a scrivere nel server primario mentre viene stabilito un nuovo server standby in background, che non influisce sul tempo di attività.
Di seguito sono riportati i passaggi durante il failover forzato:
| Step | Descrizione | Previsto tempo di inattività dell'app? |
|---|---|---|
| 1 | Il server primario viene arrestato poco dopo aver ricevuto la richiesta di failover. | Sì |
| 2 | L'applicazione rileva tempi di inattività perché il server primario è inattivo. | Sì |
| 3 | Il sistema di monitoraggio interno rileva l'errore e avvia un failover nel server di standby. | Sì |
| 4 | Il server standby passa alla modalità di ripristino prima di essere completamente alzato di livello come server indipendente. | Sì |
| 5 | Il processo di failover attende il completamento del ripristino in standby. | Sì |
| 6 | Quando il server è attivo, il record DNS viene aggiornato con lo stesso nome host, ma usando l'indirizzo IP dello standby. | Sì |
| 7 | L'applicazione può riconnettersi al nuovo server primario e riprendere l'operazione. | No |
| 8 | Viene stabilito un server standby nella zona preferita. | No |
| 9 | Il server standby inizia a recuperare i log (dal BLOB di Azure) che non è stato rilevato durante la sua creazione. | No |
| 10 | Viene stabilito uno stato stabile tra il server primario e quello di standby. | No |
| 11 | Il processo di failover forzato è stato completato. | No |
Il tempo di inattività dell'applicazione dovrebbe essere avviato dopo il passaggio 1 e persiste fino al completamento del passaggio 6. Il resto dei passaggi avviene in background senza influire sulle operazioni di scrittura e commit dell'applicazione.
Importante
Il processo di failover end-to-end include (a) il failover nel server di standby dopo l'errore primario e (b) la creazione di un nuovo server di standby in uno stato stabile. Quando l'applicazione comporta tempi di inattività fino al completamento del failover in standby, misurare il tempo di inattività dal punto di vista dell'applicazione/client anziché del processo di failover end-to-end complessivo.
Considerazioni durante l'esecuzione di failover forzati
L'ora complessiva dell'operazione end-to-end può essere considerata più lunga del tempo di inattività effettivo riscontrato dall'applicazione.
Importante
Osservare sempre il tempo di inattività dal punto di vista dell'applicazione.
Non eseguire failover immediati e back-to-back. Attendere almeno 15-20 minuti tra i failover, consentendo di stabilire completamente il nuovo server di standby.
È consigliabile eseguire un failover forzato durante un periodo di attività ridotto per ridurre i tempi di inattività.
Procedure consigliate per le statistiche di PostgreSQL dopo il failover
Dopo un failover di PostgreSQL, il meccanismo principale per mantenere prestazioni ottimali del database comporta la comprensione dei ruoli distinti delle tabelle pg_statistic e pg_stat_ * . La pg_statistic tabella ospita le statistiche di Optimizer, fondamentali per Query Planner. Queste statistiche includono le distribuzioni dei dati all'interno delle tabelle e rimangono intatte dopo un failover, assicurandosi che Query Planner possa continuare a ottimizzare l'esecuzione delle query in modo efficace in base a informazioni di distribuzione dei dati accurate e cronologiche.
Al contrario, le pg_stat_* tabelle, che registrano statistiche sulle attività, ad esempio il numero di analisi, tuple lette e aggiornamenti, vengono reimpostate al failover. Un esempio di tale tabella è pg_stat_user_tables, che tiene traccia dell'attività per le tabelle definite dall'utente. Questa reimpostazione è progettata per riflettere in modo accurato lo stato operativo del nuovo primario, ma significa anche la perdita di metriche di attività cronologiche che potrebbero informare il processo autovacuum e altre efficienze operative.
Data questa distinzione, la procedura consigliata dopo un failover postgreSQL consiste nell'eseguire ANALYZE. Questa azione aggiorna le pg_stat_* tabelle, ad esempio pg_stat_user_tables, con statistiche di attività aggiornate, consentendo il processo autovacuum e garantendo che le prestazioni del database rimangano ottimali nel nuovo ruolo. Questo passaggio proattivo consente di colmare il divario tra il mantenimento delle statistiche essenziali dell'utilità di ottimizzazione e l'aggiornamento delle metriche delle attività per allinearsi allo stato corrente del database.
Esperienza di zona inattiva
Zonal: per eseguire il ripristino da un errore a livello di zona, è possibile eseguire il ripristino temporizzato usando il backup. È possibile scegliere un punto di ripristino personalizzato con l'ora più recente per ripristinare i dati più recenti. Un nuovo server flessibile viene distribuito in un'altra zona non infettata. Il tempo necessario per il ripristino dipende dal backup precedente e dal volume dei log delle transazioni da ripristinare.
Per altre informazioni sul ripristino temporizzato, vedere Backup e ripristino nel server flessibile Database di Azure per PostgreSQL.
Ridondanza della zona: il server flessibile viene eseguito automaticamente il failover nel server di standby entro 60-120 secondi senza perdita di dati.
Configurazioni senza zone di disponibilità
Anche se non è consigliabile, è possibile configurare il server flessibile senza disponibilità elevata abilitata. Per i server flessibili configurati senza disponibilità elevata, il servizio fornisce l'archiviazione con ridondanza locale con tre copie dei dati, il backup con ridondanza della zona (nelle aree in cui è supportato) e la resilienza predefinita del server per riavviare automaticamente un server arrestato in modo anomalo e rilocare il server in un altro nodo fisico. Il contratto di servizio per il tempo di attività del 99,9% è disponibile in questa configurazione. Durante gli eventi di failover pianificati o non pianificati, se il server diventa inattivo, il servizio mantiene la disponibilità dei server usando la procedura automatizzata seguente:
- Viene eseguito il provisioning di una nuova VM Linux di calcolo.
- L'archiviazione con i file di dati viene mappata alla nuova macchina virtuale.
- Il motore di database PostgreSQL viene portato online nella nuova macchina virtuale.
L'immagine seguente illustra la transizione tra una macchina virtuale e un errore di archiviazione.

Ripristino di emergenza e continuità aziendale tra aree
In caso di emergenza a livello di area, Azure può fornire protezione da emergenze geografiche a livello di area o di grandi dimensioni con il ripristino di emergenza usando un'altra area. Per altre informazioni sull'architettura del ripristino di emergenza di Azure, vedere Architettura del ripristino di emergenza da Azure ad Azure.
Il server flessibile offre funzionalità che proteggono i dati e riduce i tempi di inattività per i database cruciali durante gli eventi di tempo di inattività pianificati e non pianificati. Basato sull'infrastruttura di Azure che offre resilienza e disponibilità affidabili, il server flessibile offre funzionalità di continuità aziendale che offrono protezione dagli errori, soddisfare i requisiti di tempo di ripristino e ridurre l'esposizione alla perdita di dati. Quando si progettano le applicazioni, è consigliabile considerare la tolleranza al tempo di inattività, ovvero l'obiettivo del tempo di ripristino (RTO) e l'esposizione alla perdita di dati, ovvero l'obiettivo del punto di ripristino (RPO). Ad esempio, il database business critical richiede tempi di attività più rigorosi rispetto a un database di test.
Ripristino di emergenza nella geografia in più aree
Backup e ripristino con ridondanza geografica
Il backup e il ripristino con ridondanza geografica consentono di ripristinare il server in un'area diversa in caso di emergenza. Inoltre, in questo modo si ottiene almeno il 99,99999999999999% (16 nove) di durabilità degli oggetti di backup nell'arco di un anno specifico.
Il backup con ridondanza geografica può essere configurato solo al momento della creazione del server. Quando il server è configurato con il backup con ridondanza geografica, i dati di backup e i log delle transazioni vengono copiati nell'area abbinata in modo asincrono tramite la replica di archiviazione.
Per altre informazioni sul backup e il ripristino con ridondanza geografica, vedere Backup e ripristino con ridondanza geografica.
Repliche in lettura
Le repliche in lettura tra aree possono essere distribuite per proteggere i database da errori a livello di area. Le repliche in lettura vengono aggiornate in modo asincrono usando la tecnologia di replica fisica di PostgreSQL e possono ritardarsi nel database primario. Le repliche in lettura sono supportate nei livelli di calcolo per utilizzo generico e ottimizzato per la memoria.
Per altre informazioni sulle funzionalità di replica in lettura e sulle considerazioni, vedere Repliche in lettura.
Rilevamento, notifica e gestione di interruzioni
Se il server è configurato con il backup con ridondanza geografica, è possibile eseguire il ripristino geografico nell'area abbinata. Vengono eseguiti il provisioning e il ripristino di un nuovo server agli ultimi dati disponibili copiati in questa area.
È anche possibile usare repliche in lettura tra aree. In caso di errore dell'area, è possibile eseguire un'operazione di ripristino di emergenza promuovendo la replica in lettura come server scrivibile in lettura autonomo. È previsto che l'RPO arrivi a 5 minuti (possibile perdita di dati) tranne nel caso di un errore a livello di area grave, dove l'RPO può essere vicino al ritardo della replica al momento dell'errore.
Per altre informazioni sulla mitigazione e il ripristino dei tempi di inattività non pianificati dopo un'emergenza a livello di area, vedere Mitigazione dei tempi di inattività non pianificati.