Distribuire un modello come endpoint online
SI APPLICA A:  Python SDK azure-ai-ml v2 (corrente)
Python SDK azure-ai-ml v2 (corrente)
Informazioni su come distribuire un modello in un endpoint online usando Azure Machine Learning Python SDK v2.
In questa esercitazione si distribuisce e si usa un modello che stima la probabilità di insolvenza di un cliente per un pagamento con carta di credito.
I passaggi da eseguire sono:
- Registrare il modello
- Creare un endpoint e una prima distribuzione
- Distribuire un'esecuzione di prova
- Inviare manualmente i dati di test alla distribuzione
- Ottenere i dettagli della distribuzione
- Creare una seconda distribuzione
- Dimensionare manualmente la seconda distribuzione
- Aggiornare l'allocazione del traffico di produzione tra entrambe le distribuzioni
- Ottenere i dettagli della seconda distribuzione
- Implementare la nuova distribuzione ed eliminare la prima
Questo video illustra come iniziare a usare lo studio di Azure Machine Learning in modo da poter seguire i passaggi dell'esercitazione. Il video mostra come creare un notebook, creare un'istanza di ambiente di calcolo e clonare il notebook. I passaggi sono descritti anche nelle sezioni seguenti.
Prerequisiti
-
Per usare Azure Machine Learning, è necessaria un'area di lavoro. Se non è disponibile, completare Creare le risorse necessarie per iniziare creare un'area di lavoro e ottenere maggiori informazioni su come usarla.
-
Accedere allo studio e selezionare l'area di lavoro, se non è già aperta.
-
Aprire o creare un notebook nell'area di lavoro:
- Se si vuole copiare e incollare il codice nelle celle, creare un nuovo notebook.
- In alternativa, aprire tutorials/get-started-notebooks/deploy-model.ipynb dalla sezione Esempi dello studio. Selezionare quindi Clona per aggiungere il notebook in File. Per trovare notebook di esempio, vedere Learn from sample notebooks (Informazioni sui notebook di esempio).
Esaminare la propria quota di VM e assicurarsi di disporre di una quota sufficiente per creare distribuzioni online. In questa esercitazione sono necessari almeno 8 core di
STANDARD_DS3_v2e 12 core diSTANDARD_F4s_v2. Per visualizzare la quota di VM e richiedere aumenti di quota, vedere Gestire le quote di risorse.
Impostare il kernel e aprirlo in Visual Studio Code (VS Code)
Nella barra superiore sopra il notebook aperto creare un'istanza di ambiente di calcolo, se non ne è già disponibile una.

Se l'istanza di ambiente di calcolo viene arrestata, selezionare Avviare ambiente di calcolo e attendere fino a quando non è in esecuzione.

Attendere che l'istanza di calcolo sia in esecuzione. Assicurarsi quindi che il kernel, trovato in alto a destra, sia
Python 3.10 - SDK v2. In caso contrario, usare l'elenco a discesa per selezionare questo kernel.
Se questo kernel non viene visualizzato, verificare che l'istanza di calcolo sia in esecuzione. In caso affermativo, selezionare il pulsante Aggiorna in alto a destra del notebook.
Se viene visualizzato un banner che indica che è necessario eseguire l'autenticazione, selezionare Autentica.
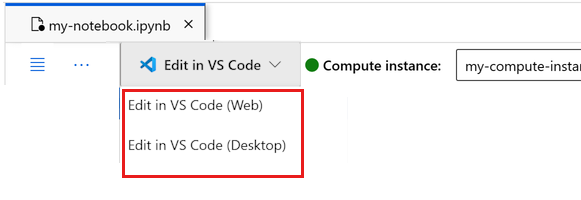
È possibile eseguire il notebook qui o aprirlo in VS Code per usare un ambiente di sviluppo integrato (IDE) completo con la potenza delle risorse di Azure Machine Learning. Selezionare Apri in VS Code, quindi selezionare l'opzione Web o desktop. Quando viene avviato in questo modo, VS Code viene collegato all'istanza di ambiente di calcolo, al kernel e al file system dell'area di lavoro.




Importante
La parte rimanente di questa esercitazione contiene le celle del notebook dell'esercitazione. Copiarli e incollarli nel nuovo notebook oppure passare ora al notebook se è stato clonato.
Nota
- L'ambiente di calcolo Spark serverless non ha
Python 3.10 - SDK v2installato per impostazione predefinita. È consigliabile creare un'istanza di ambiente di calcolo e selezionarla prima di procedere con l'esercitazione.
Creare un handle all'area di lavoro
Prima di passare ai dettagli del codice, è necessario un modo per fare riferimento all'area di lavoro. Creare ml_client per un handle nell'area di lavoro e usare ml_client per gestire risorse e processi.
Nella cella successiva immettere l'ID sottoscrizione, il nome del gruppo di risorse e il nome dell'area di lavoro. Per trovare questi valori:
- In alto a destra nella barra degli strumenti dello studio di Azure Machine Learning selezionare il nome dell'area di lavoro.
- Copiare i valori per l'area di lavoro, il gruppo di risorse e l'ID sottoscrizione nel codice.
- È necessario copiare un valore, chiudere l'area e incollarlo, quindi tornare indietro per quello successivo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Nota
La creazione di MLClient non stabilità una connessione all'area di lavoro. L'inizializzazione del client avviene in modo differito e attende la prima volta in cui è necessario effettuare una chiamata (questo avviene nella cella di codice successiva).
Registrare il modello
Se è già stata completata l'esercitazione sul training precedente, Eseguire il training di un modello, come parte dello script di training è stato registrato un modello MLflow e quindi è possibile passare alla sezione successiva.
Se l'esercitazione di training non è stata completata, è necessario registrare il modello. Registrare il modello prima della distribuzione è una procedura consigliata.
Il codice seguente specifica path (da cui caricare i file) inline. Se si è clonata la cartella delle esercitazioni, eseguire il codice seguente così com'è. In caso contrario, scaricare i file e i metadati per il modello dalla cartella credit_defaults_model. Salvare i file scaricati in una versione locale della cartella credit_defaults_model nel computer e aggiornare il percorso nel codice seguente al percorso dei file scaricati.
L'SDK carica automaticamente i file e registra il modello.
Per altre informazioni sulla registrazione del modello come asset, vedere Registrare il modello come asset in Machine Learning usando l'SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Verificare che il modello sia registrato
È possibile esaminare la pagina Modelli nello studio di Azure Machine Learning per identificare l'ultima versione del modello registrato.
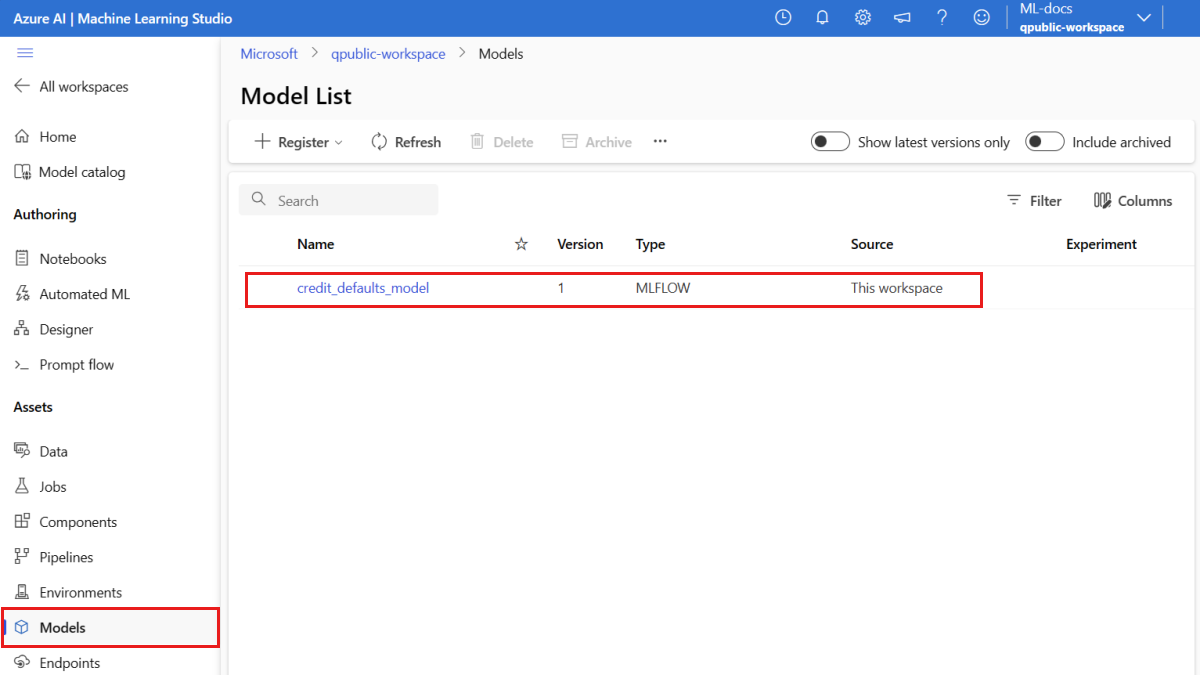
In alternativa, il codice seguente recupera il numero di versione più recente da usare.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Ora che si dispone di un modello registrato, è possibile creare un endpoint e una distribuzione. La sezione successiva illustra brevemente alcuni dettagli essenziali su questi argomenti.
Endpoint e distribuzioni
Dopo aver eseguito il training di un modello di Machine Learning, è necessario distribuirlo in modo che altri utenti possano usarlo per l'inferenza. A questo scopo, Azure Machine Learning consente di creare endpoint e aggiungervi distribuzioni.
In questo contesto un endpoint è un percorso HTTPS che fornisce ai client un'interfaccia per inviare richieste (dati di input) a un modello sottoposto a training e ricevere i risultati dell'inferenza (punteggio) dal modello. Un endpoint fornisce:
- Autenticazione, con l'autenticazione basata su chiave o token
- Terminazione TLS (SSL)
- Un URI stabile per l'assegnazione del punteggio (endpoint-name.region.inference.ml.azure.com)
Una distribuzione è un set di risorse necessarie per ospitare il modello che esegue l'inferenza.
Un singolo endpoint può contenere più distribuzioni. Gli endpoint e le distribuzioni sono risorse indipendenti di Azure Resource Manager visualizzate nel portale di Azure.
Azure Machine Learning consente di implementare endpoint online per l'inferenza in tempo reale sui dati client ed endpoint batch per l'inferenza su grandi volumi di dati in un periodo di tempo.
In questa esercitazione vengono illustrati i passaggi per l'implementazione di un endpoint online gestito. Gli endpoint online gestiti funzionano con potenti macchine CPU e GPU in Azure in modo scalabile e completamente gestito, liberando l'utente dalle attività di configurazione e gestione dell'infrastruttura di distribuzione sottostante.
Creare un endpoint online
Ora che si dispone di un modello registrato, è possibile creare l'endpoint online. Il nome dell'endpoint deve essere univoco all'interno dell'area di Azure. Per questa esercitazione si crea un nome univoco usando un identificatore univoco universale UUID. Per altre informazioni sulle regole di denominazione degli endpoint, vedere i limiti degli endpoint.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Per prima cosa, definire gli endpoint usando la classe ManagedOnlineEndpoint.
Suggerimento
auth_mode: usarekeyper l'autenticazione basata su chiave. Usareaml_tokenper l'autenticazione basata su token di Azure Machine Learning. Un elementokeynon scade, mentre un elementoaml_tokenscade. Per altre informazioni sull'autenticazione, vedere Eseguire l'autenticazione di client per endpoint online.Facoltativamente, è possibile aggiungere una descrizione e tag all'endpoint.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Usando l'oggetto MLClient creato in precedenza, verrà ora creato l'endpoint nell'area di lavoro. Questo comando avvia la creazione dell'endpoint e restituisce una risposta di conferma mentre la procedura è ancora in corso.
Nota
La creazione dell'endpoint richiederà circa 2 minuti.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Dopo aver creato l'endpoint, è possibile recuperarlo come indicato di seguito:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Informazioni sulle distribuzioni online
Gli aspetti chiave di una distribuzione includono:
name: nome della distribuzione.endpoint_name: nome dell'endpoint che conterrà la distribuzione.model: modello da usare per la distribuzione. Questo valore può essere un riferimento a un modello con controllo delle versioni esistente nell'area di lavoro o a una specifica del modello inline.environment: ambiente da usare per la distribuzione (o per eseguire il modello). Questo valore può essere un riferimento a un ambiente con controllo delle versioni esistente nell'area di lavoro o a una specifica dell'ambiente inline. L'ambiente può essere un'immagine Docker con dipendenze Conda o un Dockerfile.code_configuration: configurazione per il codice sorgente e lo script di assegnazione dei punteggi.path: percorso della directory del codice sorgente per l'assegnazione dei punteggi al modello.scoring_script: percorso relativo del file di assegnazione dei punteggi nella directory del codice sorgente. Questo script esegue il modello in una richiesta di input specificata. Per un esempio di script di assegnazione dei punteggi, vedere Informazioni sullo script di assegnazione dei punteggi nell'articolo "Distribuire un modello di Machine Learning con un endpoint online".
instance_type: dimensioni della macchina virtuale da usare per la distribuzione. Per l'elenco delle dimensioni supportate, vedere l'Elenco degli SKU degli endpoint online gestiti.instance_count: numero di istanze da usare per la distribuzione.
Distribuzione con un modello MLflow
Azure Machine Learning supporta la distribuzione senza codice di un modello creato e registrato con MLflow. Questo significa che non è necessario fornire uno script di assegnazione dei punteggi o un ambiente durante la distribuzione modello, perché lo script di assegnazione dei punteggi e l'ambiente vengono generati automaticamente durante il training di un modello MLflow. Se invece si usa un modello personalizzato, è necessario specificare l'ambiente e lo script di assegnazione dei punteggi durante la distribuzione.
Importante
Se in genere si distribuiscono modelli usando script di assegnazione dei punteggi e ambienti personalizzati e si vuole ottenere la stessa funzionalità usando i modelli MLflow, è consigliabile leggere Linee guida per la distribuzione di modelli MLflow.
Distribuire il modello nell'endpoint
Iniziare creando una singola distribuzione che gestisce tutto il traffico in ingresso. Scegliere un nome di colore arbitrario (blue) per la distribuzione. Per creare la distribuzione per l'endpoint, usare la classe ManagedOnlineDeployment.
Nota
Non è necessario specificare un ambiente o uno script di assegnazione dei punteggi, perché il modello da distribuire è un modello MLflow.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Usando MLClient creato in precedenza, creare ora la distribuzione nell'area di lavoro. Questo comando avvia la creazione della distribuzione e restituisce una risposta di conferma mentre la creazione della distribuzione è ancora in corso.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Controllare lo stato dell'endpoint
È possibile controllare lo stato dell'endpoint per verificare se il modello è stato distribuito senza errori:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Testare l'endpoint con dati di esempio
Dopo aver distribuito il modello nell'endpoint, è possibile eseguire l'inferenza. Iniziare creando un file di richiesta di esempio che segue la progettazione prevista nel metodo run trovato nello script di assegnazione dei punteggi.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Creare ora il file nella directory di distribuzione. La cella di codice seguente usa un magic IPython per scrivere il file nella directory appena creata.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Usando il MLClient creato in precedenza, si ottiene un handle per l'endpoint. È possibile richiamare l'endpoint usando il comando invoke con i parametri seguenti:
endpoint_name: nome dell'endpointrequest_file: file con i dati della richiestadeployment_name: nome della distribuzione specifica da testare in un endpoint
Testare la distribuzione "blue" con i dati di esempio.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Ottenere i log della distribuzione
Controllare i log per verificare se l'endpoint o la distribuzione sono stati richiamati correttamente. Se si verificano errori, vedere Risoluzione dei problemi di distribuzione degli endpoint online.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Creare una seconda distribuzione
Distribuire il modello come seconda distribuzione denominata green. In pratica, è possibile creare diverse distribuzioni e confrontarne le prestazioni. Queste distribuzioni possono usare una versione diversa dello stesso modello, un modello diverso o un'istanza di ambiente di calcolo più potente.
In questo esempio si distribuisce la stessa versione del modello usando un'istanza di ambiente di calcolo più potente, che potrebbe potenzialmente migliorare le prestazioni.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Dimensionare la distribuzione per gestire più traffico
Usando il MLClient creato in precedenza, è possibile ottenere un handle per la distribuzione green. È quindi possibile ridimensionarlo aumentando o riducendo instance_count.
Nel codice seguente si aumenta manualmente il numero di istanze di VM. Tuttavia, è anche possibile ridimensionare automaticamente gli endpoint online. La scalabilità automatica usa automaticamente la quantità corretta di risorse per gestire il carico dell'applicazione. Gli endpoint online gestiti supportano la scalabilità automatica tramite l'integrazione con la funzionalità di scalabilità automatica di Monitoraggio di Azure. Per configurare la scalabilità automatica, vedere Scalabilità automatica degli endpoint online.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Aggiornare l'allocazione del traffico per le distribuzioni
È possibile suddividere il traffico di produzione tra le distribuzioni. Per prima cosa, è consigliabile testare la distribuzione green con dati di esempio, proprio come si è fatto per la distribuzione blue. Dopo aver testato la distribuzione green, allocare una piccola percentuale di traffico a tale distribuzione.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Testare l'allocazione del traffico richiamando l'endpoint varie volte:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Visualizzare i log della distribuzione green per verificare che ci siano state richieste in ingresso e che al modello sia stato correttamente assegnato un punteggio.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Visualizzare le metriche con Monitoraggio di Azure
È possibile visualizzare varie metriche (numero di richieste, latenza delle richieste, byte di rete, utilizzo di CPU/GPU/disco/memoria e altro ancora) per un endpoint online e le relative distribuzioni seguendo i collegamenti della pagina Dettagli dell'endpoint nello studio. Questi collegamenti consentono di passare alla pagina esatta delle metriche nel portale di Azure per l'endpoint o la distribuzione.

Se si aprono le metriche per l'endpoint online, è possibile configurare la pagina in modo da visualizzare metriche come la latenza media delle richieste, come illustrato nella figura seguente.

Per altre informazioni su come visualizzare le metriche degli endpoint online, vedere Monitorare gli endpoint online.
Inviare tutto il traffico alla nuova distribuzione
Quando la distribuzione green soddisfa appieno le proprie esigenze, instradarvi tutto il traffico.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Eliminare la distribuzione precedente
Rimuovere la distribuzione precedente (blue):
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Pulire le risorse
Se non si intende usare l'endpoint e la distribuzione dopo aver completato questa esercitazione, eliminarli.
Nota
L'eliminazione completa può richiedere circa 20 minuti.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Eliminare tutto
Usare questa procedura per eliminare l'area di lavoro di Azure Machine Learning e tutte le risorse di calcolo.
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e procedure dettagliate per Azure Machine Learning.
Se le risorse create non servono più, eliminarle per evitare addebiti:
Nella casella di ricerca della portale di Azure immettere Gruppi di risorse e selezionarlo nei risultati.
Nell'elenco selezionare il gruppo di risorse creato.
Nella pagina Panoramica selezionare Elimina gruppo di risorse.
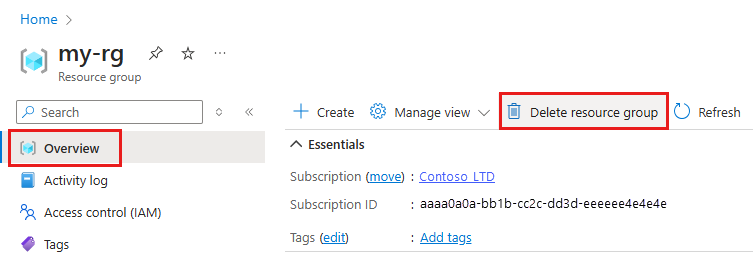
Immettere il nome del gruppo di risorse. Quindi seleziona Elimina.