Endpoint batch
Azure Machine Learning consente di implementare endpoint e distribuzioni batch per eseguire inferenze asincrone e a esecuzione prolungata con modelli e pipeline di apprendimento automatico. Quando si esegue il training di un modello o di una pipeline di apprendimento automatico, è necessario distribuirlo in modo che altri utenti possano usarlo con nuovi dati di input per generare stime. Questo processo di generazione di stime con il modello o la pipeline è detto inferenza.
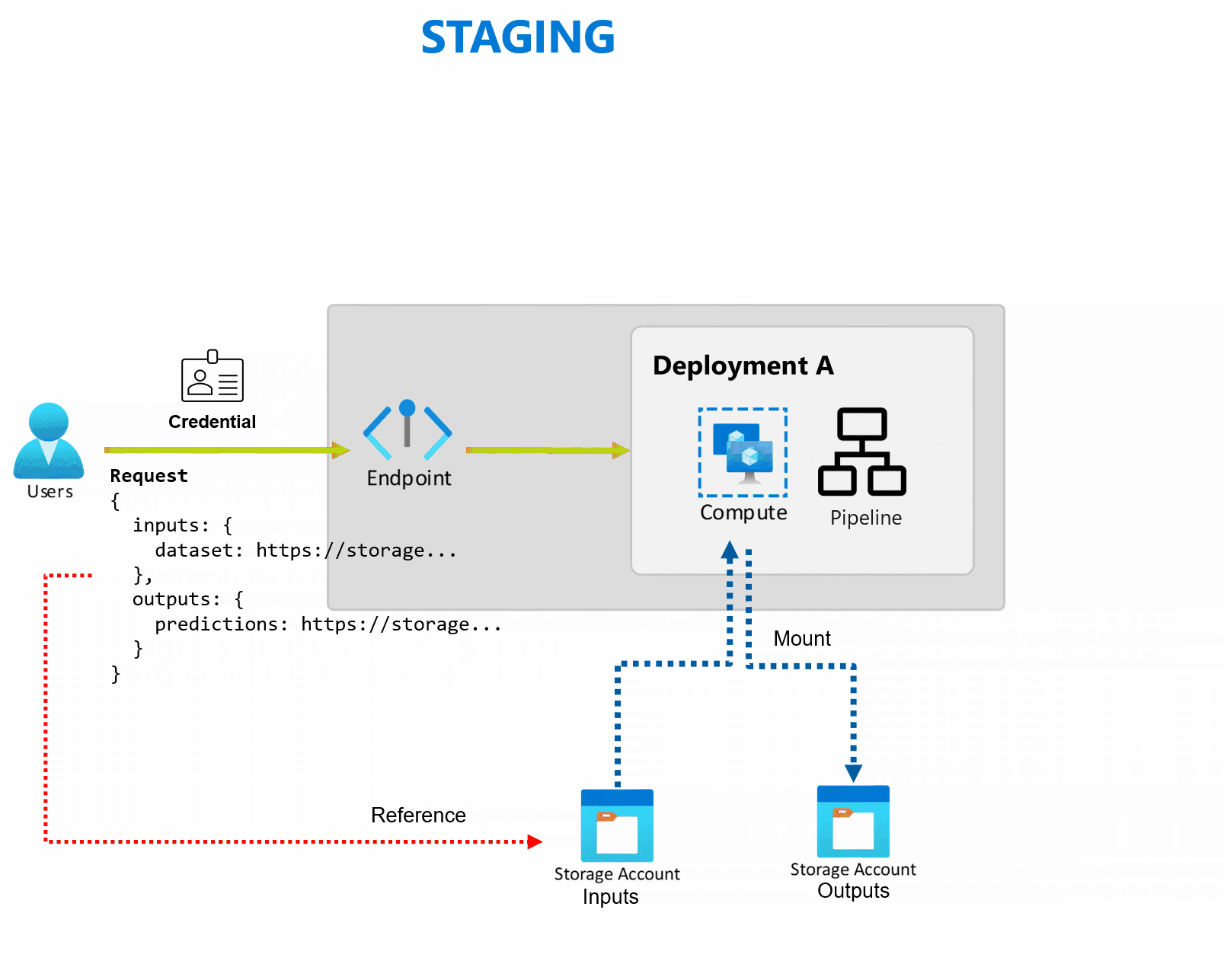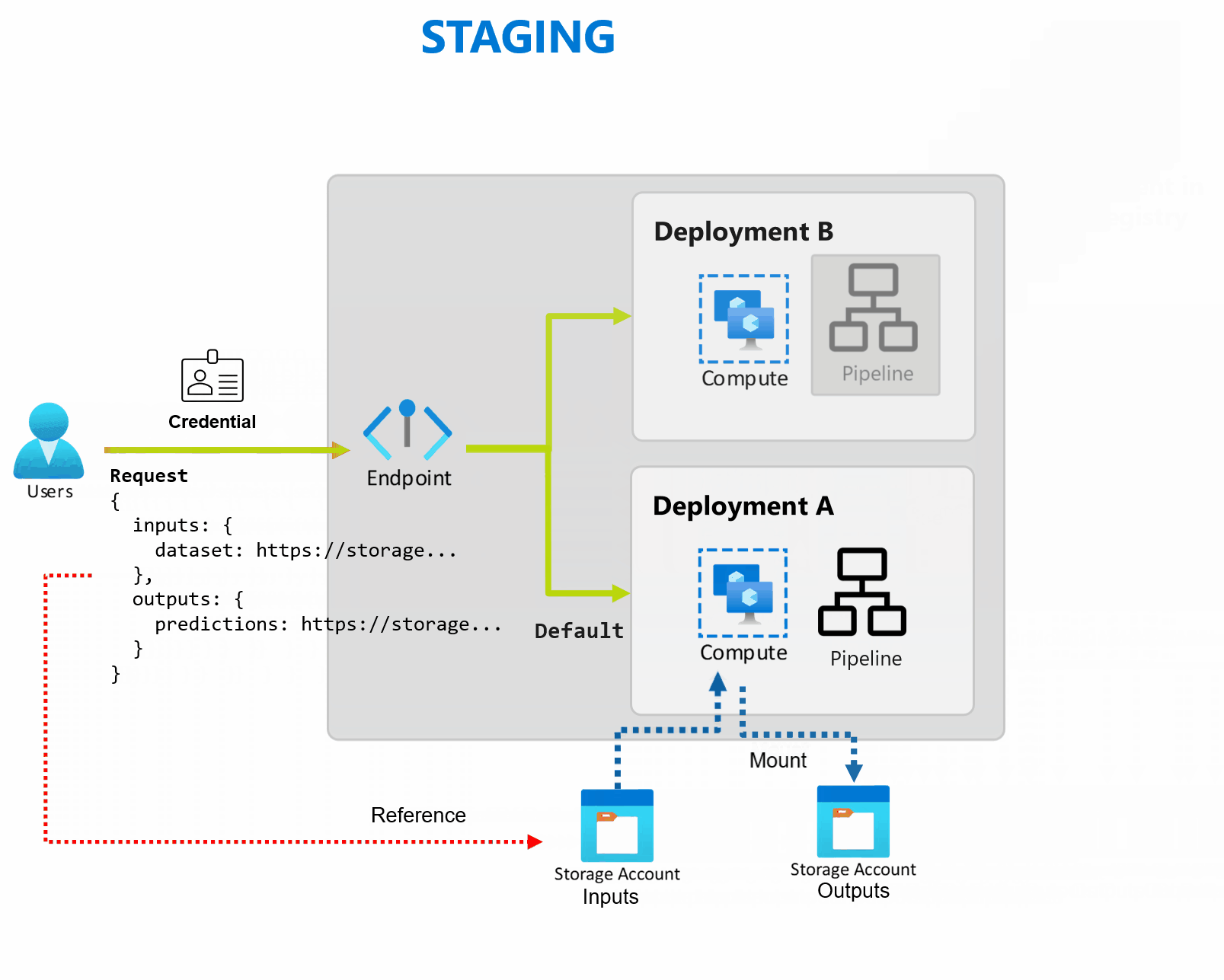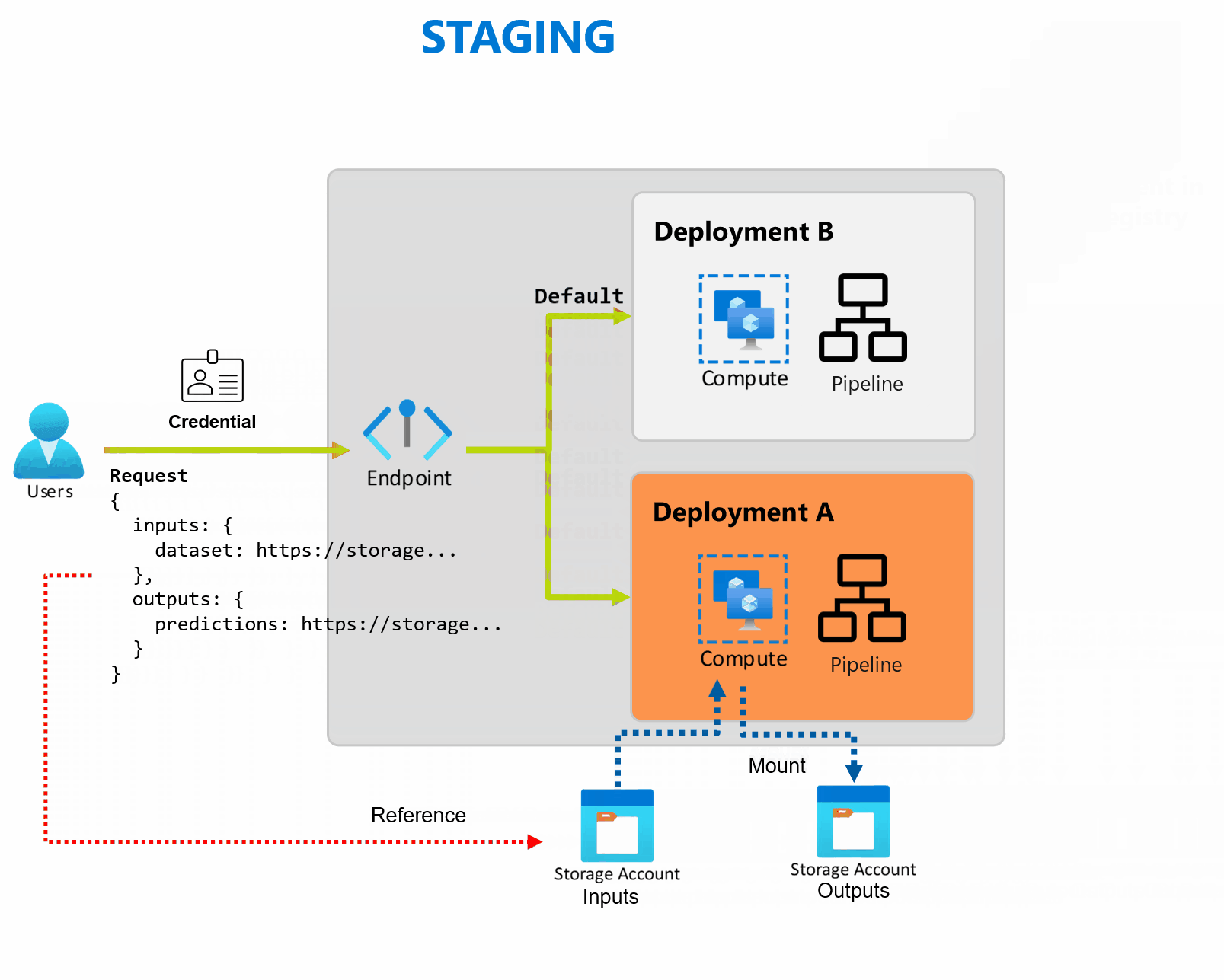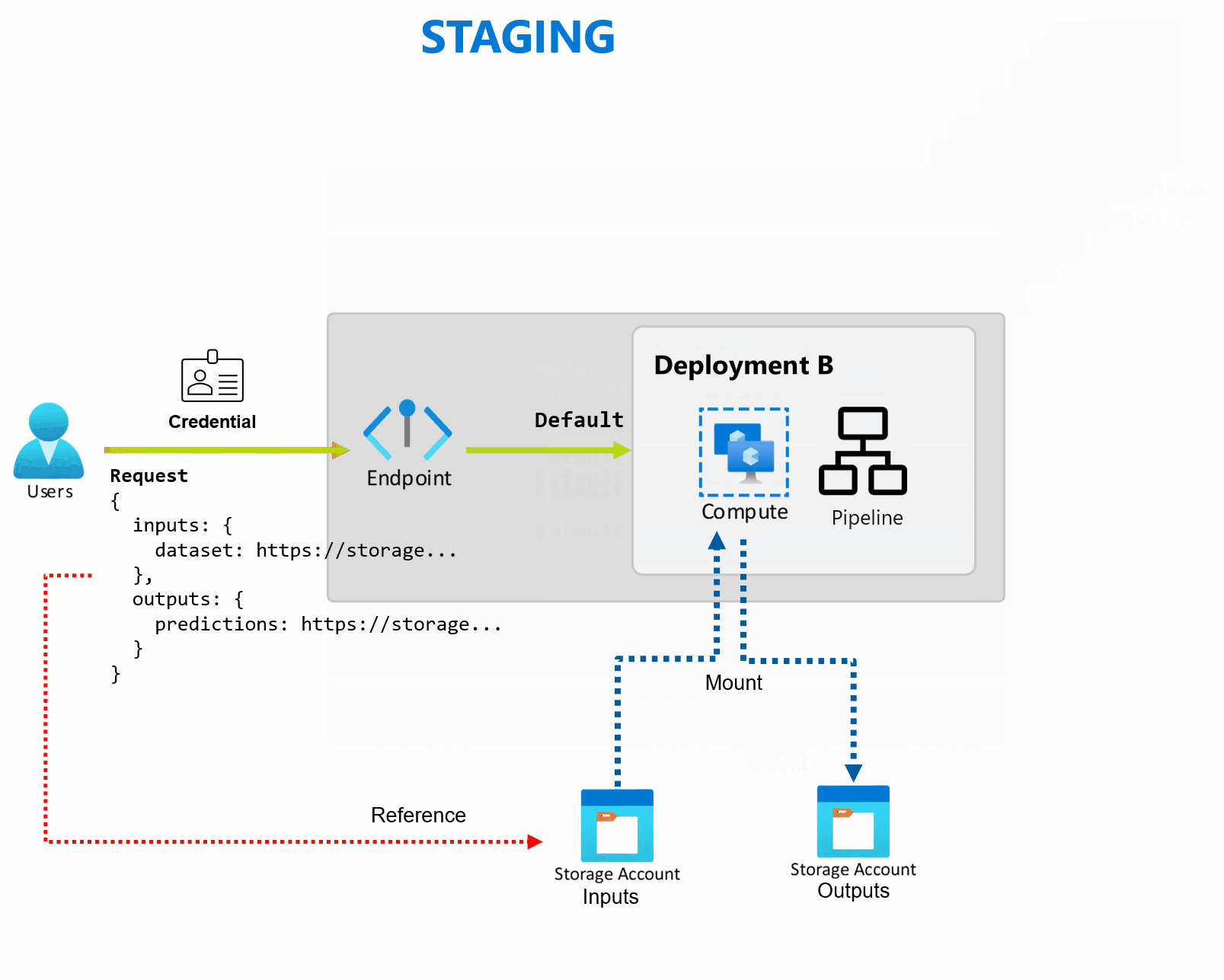
Gli endpoint batch ricevono puntatori ai dati ed eseguono processi in modo asincrono per elaborare i dati in parallelo nei cluster di calcolo. Gli endpoint batch archiviano gli output in un archivio dati per un'ulteriore analisi. Usare gli endpoint batch quando:
- Si dispone di modelli o pipeline dispendiosi che richiedono tempi di esecuzione più lunghi.
- Si vogliono rendere operative le pipeline di Machine Learning e riutilizzare i componenti.
- È necessario eseguire l'inferenza su grandi quantità di dati, distribuiti in più file.
- Non si dispone di requisiti di bassa latenza.
- Gli input del modello vengono archiviati in un account di archiviazione o in un asset di dati di Azure Machine Learning.
- È possibile sfruttare la parallelizzazione.
Distribuzioni batch
Una distribuzione è costituita da un set di risorse e calcoli necessari per implementare la funzionalità fornita dall'endpoint. Ogni endpoint può ospitare diverse distribuzioni con configurazioni diverse e questa funzionalità contribuisce a separare l'interfaccia dell'endpoint dai dettagli di implementazione definiti dalla distribuzione. Quando viene richiamato un endpoint batch, instrada automaticamente il client alla distribuzione predefinita. Questa distribuzione predefinita può essere configurata e modificata in qualsiasi momento.

Sono possibili due tipi di distribuzioni negli endpoint batch di Azure Machine Learning:
Distribuzione di modelli
La distribuzione del modello consente di rendere operativa l'inferenza del modello su larga scala, consentendo di elaborare grandi quantità di dati in modo a bassa latenza e asincrona. La scalabilità viene instrumentata automaticamente da Azure Machine Learning fornendo la parallelizzazione dei processi di inferenza in più nodi di un cluster di elaborazione.
Usare la Distribuzione modello quando:
- Si dispone di modelli dispendiosi che richiedono più tempo per l'esecuzione dell'inferenza.
- È necessario eseguire l'inferenza su grandi quantità di dati, distribuiti in più file.
- Non si dispone di requisiti di bassa latenza.
- È possibile sfruttare la parallelizzazione.
Il vantaggio principale delle distribuzioni di modelli è che è possibile usare gli stessi asset distribuiti per l'inferenza in tempo reale agli endpoint online; tuttavia, ora è possibile eseguirli su larga scala in batch. Se il modello richiede una semplice operazione di pre- o post-elaborazione, è possibile creare uno script di assegnazione dei punteggi che esegua le trasformazioni dei dati necessarie.
Per creare una distribuzione modello in un endpoint batch è necessario specificare gli elementi seguenti:
- Modello
- Cluster di elaborazione
- Script di assegnazione dei punteggi (facoltativo per i modelli MLflow)
- Ambiente (facoltativo per i modelli MLflow)
Distribuzione di componenti della pipeline
La distribuzione dei componenti della pipeline consente di rendere operativi interi grafi di elaborazione (o pipeline) per eseguire l'inferenza batch a bassa latenza e in modo asincrono.
Usare la distribuzione software di componenti della pipeline quando:
- È necessario rendere operativi grafi di calcolo completi che possono essere scomposti in più passaggi.
- È necessario riutilizzare i componenti dalle pipeline di training nella pipeline di inferenza.
- Non si dispone di requisiti di bassa latenza.
Il vantaggio principale delle distribuzioni dei componenti della pipeline è la riutilizzabilità dei componenti già esistenti nella piattaforma e la capacità di rendere operative routine di inferenza complesse.
Per creare una distribuzione di componenti della pipeline in un endpoint batch è necessario specificare gli elementi seguenti:
- Componente pipeline
- Configurazione del cluster di elaborazione
Gli endpoint batch consentono anche di creare distribuzioni di componenti della pipeline da un processo della pipeline esistente. Quando si esegue questa operazione, Azure Machine Learning crea automaticamente un componente pipeline dal processo. Ciò semplifica l'uso di questi tipi di distribuzioni. È tuttavia consigliabile creare sempre componenti della pipeline in modo esplicito per semplificare la procedura MLOps.
Gestione costi
La chiamata di un endpoint batch attiva un processo di inferenza batch asincrono. Azure Machine Learning effettua automaticamente il provisioning delle risorse di calcolo all'avvio del processo e le dealloca automaticamente al termine del processo. In questo modo si paga l'ambiente di calcolo solo quando lo si usa.
Suggerimento
Quando si distribuiscono i modelli, è possibile eseguire l'override delle impostazioni delle risorse di calcolo (come il numero di istanze) e delle impostazioni avanzate (come la dimensione batch ridotta, la soglia di errore e così via) per ogni singolo processo di inferenza batch. Sfruttando queste configurazioni specifiche, è possibile velocizzare l'esecuzione e ridurre i costi.
È anche possibile eseguire gli endpoint batch in macchine virtuali con priorità bassa. Gli endpoint batch possono eseguire automaticamente il ripristino dalle macchine virtuali deallocate e riprendere il lavoro da dove era stato interrotto durante la distribuzione dei modelli per l'inferenza. Per altre informazioni su come usare macchine virtuali con priorità bassa per ridurre il costo dei carichi di lavoro di inferenza batch, vedere Usare macchine virtuali con priorità bassa negli endpoint batch.
Infine, Azure Machine Learning non addebita alcun costo per gli endpoint batch o le distribuzioni batch stesse, quindi è possibile organizzare gli endpoint e le distribuzioni nel modo più adatto al proprio scenario. Gli endpoint e la distribuzione possono usare cluster indipendenti o condivisi, in modo da ottenere un controllo con granularità fine sull'ambiente di calcolo utilizzato dai processi. Usare la scalabilità a zero nei cluster per assicurarsi che non vengano utilizzate risorse quando sono inattive.
Semplificare la procedura MLOps
Gli endpoint batch possono gestire più distribuzioni nello stesso endpoint, consentendo di modificare l'implementazione dell'endpoint senza modificare l'URL usato dai consumer per richiamarlo.
È possibile aggiungere, rimuovere e aggiornare le distribuzioni, senza influire sull'endpoint stesso.
Origini dati e archiviazione flessibili
Gli endpoint batch leggono e scrivono i dati direttamente dalla risorsa di archiviazione. È possibile specificare come input gli archivi dati di Azure Machine Learning, l'asset di dati di Azure Machine Learning o gli account di archiviazione. Per altre informazioni sulle opzioni di input supportate e su come specificarle, vedere Creare processi e inserire dati negli endpoint batch.
Sicurezza
Gli endpoint batch offrono tutte le funzionalità necessarie per gestire i carichi di lavoro a livello di produzione in un ambiente aziendale. Supportano la rete privata nelle aree di lavoro protette e l'autenticazione di Microsoft Entra, usando un'entità utente (come un account utente) o un'entità servizio (come un'identità gestita o non gestita). I processi generati da un endpoint batch vengono eseguiti con l'identità dell'invoker, offrendo così la flessibilità necessaria per implementare qualsiasi scenario. Per altre informazioni sull'autorizzazione durante l'uso degli endpoint batch, vedere Come eseguire l'autenticazione sugli endpoint batch.