Monitorare le prestazioni dei modelli distribuiti in produzione
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Informazioni su come usare il monitoraggio del modello di Azure Machine Learning per tenere continuamente traccia delle prestazioni dei modelli di Machine Learning nell'ambiente di produzione. Il monitoraggio dei modelli offre una panoramica generale dei segnali di monitoraggio e degli avvisi per i potenziali problemi. Quando si monitorano i segnali e le metriche delle prestazioni dei modelli nell'ambiente di produzione, è possibile valutare in modo critico i rischi intrinseci associati e identificare i punti ciechi che potrebbero influire negativamente sull'azienda.
Questo articolo spiega come eseguire le attività seguenti:
- Configurare il monitoraggio predefinito e avanzato per i modelli distribuiti in endpoint online di Azure Machine Learning
- Monitorare le metriche delle prestazioni per i modelli nell'ambiente di produzione
- Monitorare i modelli che sono distribuiti al di fuori di Azure Machine Learning o distribuiti agli endpoint batch di Azure Machine Learning
- Configurare il monitoraggio dei modelli con segnali e metriche personalizzati
- Interpretare i risultati del monitoraggio
- Integrazione del monitoraggio dei modelli di Azure Machine Learning con la Griglia di eventi di Azure
Prerequisiti
Prima di seguire la procedura descritta in questo articolo, assicurarsi di disporre dei prerequisiti seguenti:
L'interfaccia della riga di comando di Azure e l'estensione
mlper l'interfaccia della riga di comando di Azure. Per altre informazioni, vedere Installare, configurare e usare l'interfaccia della riga di comando (v2).Importante
Gli esempi dell'interfaccia della riga di comando in questo articolo presuppongono che si usi la shell Bash (o compatibile). Ad esempio, un sistema Linux o un sottosistema Windows per Linux.
Un'area di lavoro di Azure Machine Learning. Se non è disponibile, usare la procedura descritta in Installare, configurare e usare l'interfaccia della riga di comando (v2) per crearne una.
I controlli degli accessi in base al ruolo di Azure vengono usati per concedere l'accesso alle operazioni in Azure Machine Learning. Per eseguire la procedura descritta in questo articolo, all'account utente deve essere assegnato il ruolo di Proprietario o Collaboratore per l'area di lavoro di Azure Machine Learning o a un ruolo personalizzato che consente
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Per altre informazioni, vedere Gestire l'accesso a un'area di lavoro di Azure Machine Learning.Per monitorare un modello che è stato distribuito su un endpoint online di Azure Machine Learning (endpoint online gestito o endpoint online Kubernetes), assicurarsi di:
Avere già un modello distribuito su un endpoint online di Azure Machine Learning. Sono supportati sia l'endpoint online gestito che l'endpoint online Kubernetes. Se non si dispone di un modello distribuito su un endpoint online di Azure Machine Learning, vedere Distribuire e valutare un modello di Machine Learning utilizzando un endpoint online.
Abilitare la raccolta dati per la distribuzione del modello. È possibile abilitare la raccolta dati durante la fase di distribuzione per gli endpoint online di Azure Machine Learning. Per altre informazioni, vedere Raccogliere dati di produzione da modelli distribuiti su un endpoint in tempo reale.
Per monitorare un modello che è stato distribuito su un endpoint batch di Azure Machine Learning o distribuito al di fuori di Azure Machine Learning, assicurarsi di:
- Avere un mezzo per raccogliere dati di produzione e registrarli come asset di dati di Azure Machine Learning.
- Aggiornare continuamente l'asset di dati registrato per il monitoraggio dei modelli.
- (Scelta consigliata) Registrare il modello in un'area di lavoro di Azure Machine Learning, per il tracciamento della linea di derivazione.
Importante
I processi di monitoraggio dei modelli sono programmati per essere eseguiti su pool di calcolo Spark serverless con supporto per i seguenti tipi di istanza VM: Standard_E4s_v3, Standard_E8s_v3, Standard_E16s_v3, Standard_E32s_v3 e Standard_E64s_v3. È possibile selezionare il tipo di istanza VM con la proprietà create_monitor.compute.instance_type nella configurazione YAML o dal menu a discesa nello studio di Azure Machine Learning.
Configurare il monitoraggio del modelli preconfigurati
Supponiamo di distribuire il modello in produzione su un endpoint online di Azure Machine Learning e di abilitare la raccolta dati al momento della distribuzione. In questo scenario, Azure Machine Learning raccoglie i dati di inferenza di produzione e li archivia automaticamente in Archiviazione BLOB di Microsoft Azure. È possibile quindi utilizzare il monitoraggio dei modelli di Azure Machine Learning per monitorare continuamente questi dati di inferenza di produzione.
È possibile utilizzare l'interfaccia della riga di comando di Azure, Python SDK o lo studio per una configurazione preconfigurata del monitoraggio dei modelli. La configurazione del monitoraggio dei modelli preconfigurati fornisce le seguenti capacità di monitoraggio:
- Azure Machine Learning rileva automaticamente il dataset di inferenza di produzione associato a una distribuzione online di Azure Machine Learning e utilizza il dataset per il monitoraggio dei modelli.
- Il dataset di riferimento per il confronto è impostato come il dataset di inferenza di produzione recente e passato.
- La configurazione del monitoraggio include automaticamente e traccia i segnali di monitoraggio predefiniti: deriva dei dati, deriva delle previsioni e qualità dei dati. Per ogni segnale di monitoraggio, Azure Machine Learning utilizza:
- il dataset di inferenza di produzione recente e passato come dataset di riferimento per il confronto.
- impostazioni predefinite intelligenti per metriche e soglie.
- Un processo di monitoraggio è programmato per essere eseguito quotidianamente alle 3:15 (per questo esempio) con la finalità di acquisire segnali di monitoraggio e valutare ogni risultato delle metriche rispetto alla soglia corrispondente. Per impostazione predefinita, quando una soglia viene superata, Azure Machine Learning invia un'email di avviso all'utente che ha configurato il monitoraggio.
Il monitoraggio dei modelli di Azure Machine Learning utilizza az ml schedule per programmare un processo di monitoraggio. È possibile creare il monitoraggio dei modelli preconfigurati con il seguente comando dell'interfaccia della riga di comando e definizione YAML:
az ml schedule create -f ./out-of-box-monitoring.yaml
La seguente YAML contiene la definizione per il monitoraggio dei modelli preconfigurato.
# out-of-box-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: credit_default_model_monitoring
display_name: Credit default model monitoring
description: Credit default model monitoring setup with minimal configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute: # specify a spark compute for monitoring job
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification # model task type: [classification, regression, question_answering]
endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id
alert_notification: # emails to get alerts
emails:
- abc@example.com
- def@example.com


Configurare il monitoraggio avanzato dei modelli
Azure Machine Learning offre numerose capacità per il monitoraggio continuo dei modelli. Vedere Capacità di monitoraggio di modelli per un elenco completo di queste capacità. In molti casi, è necessario configurare il monitoraggio dei modelli con capacità di monitoraggio avanzate. Nelle sezioni seguenti, si configura il monitoraggio dei modelli con queste capacità:
- Uso di molteplici segnali di monitoraggio per una visione ampia.
- Uso dei dati cronologici di training dei modelli o dei dati di convalida come dataset di riferimento per il confronto.
- Monitoraggio delle prime N caratteristiche più importanti e delle singole caratteristiche.
Configurare l'importanza delle caratteristiche
L'importanza delle caratteristiche rappresenta l'importanza relativa di ogni caratteristica di input rispetto all'output di un modello. Ad esempio, la temperatura temperature potrebbe essere più importante per la previsione di un modello rispetto all'elevazione elevation. Abilitare l'importanza delle caratteristiche può offrire visibilità su quali caratteristiche non si desidera che subiscano derive o abbiano problemi di qualità dei dati in produzione.
Per abilitare l'importanza delle caratteristiche con uno qualsiasi dei segnali (come la deriva dei dati o la qualità dei dati), è necessario fornire:
- Il dataset di training come dataset di
reference_data. - La proprietà
reference_data.data_column_names.target_column, che è il nome della colonna di output/previsione del modello.
Dopo aver abilitato l'importanza delle caratteristiche, sarà possibile visualizzare l'importanza assegnata a ciascuna caratteristica monitorata nell'interfaccia utente dello studio di monitoraggio dei modelli di Azure Machine Learning.
È possibile utilizzare l'interfaccia della riga di comando di Azure CLI, Python SDK o lo studio per una configurazione avanzata del monitoraggio dei modelli.
Creare una configurazione avanzata di monitoraggio del modello con il seguente comando dell'interfaccia della riga di comando e definizione YAML:
az ml schedule create -f ./advanced-model-monitoring.yaml
Il seguente YAML contiene la definizione per il monitoraggio avanzato dei modelli.
# advanced-model-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with advanced configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:credit-default:main
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1 # use training data as comparison reference dataset
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
features:
top_n_feature_importance: 10 # monitor drift for top 10 features
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_data_quality:
type: data_quality
# reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
features: # monitor data quality for 3 individual features only
- SEX
- EDUCATION
metric_thresholds:
numerical:
null_value_rate: 0.05
categorical:
out_of_bounds_rate: 0.03
feature_attribution_drift_signal:
type: feature_attribution_drift
# production_data: is not required input here
# Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data
# Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
metric_thresholds:
normalized_discounted_cumulative_gain: 0.9
alert_notification:
emails:
- abc@example.com
- def@example.com






Configurare il monitoraggio delle prestazioni del modello
Il monitoraggio dei modelli di Azure Machine Learning consente di tenere traccia delle prestazioni dei modelli nell'ambiente di produzione calcolando le metriche delle prestazioni. Sono attualmente supportate le metriche delle prestazioni del modello seguenti:
Per i modelli di classificazione:
- Precisione
- Accuratezza
- Richiamo
Per i modelli di regressione:
- Errore assoluto medio (MAE)
- Errore quadratico medio
- Radice errore quadratico medio (RMSE)
Altri prerequisiti per il monitoraggio delle prestazioni del modello
Per configurare il segnale di prestazioni del modello, è necessario soddisfare i requisiti seguenti:
Avere i dati di output per il modello di produzione (stime del modello) con un ID univoco per ogni riga. Se si raccolgono dati di produzione con l'agente di raccolta dati di Azure Machine Learning, viene fornito un
correlation_idper ogni richiesta di inferenza. Con l'agente di raccolta dati è anche possibile registrare il proprio ID univoco dall'applicazione.Nota
Per il monitoraggio delle prestazioni del modello di Azure Machine Learning, è consigliabile registrare l'ID univoco nella propria colonna usando l'agente di raccolta dati di Azure Machine Learning.
Avere dati ground truth (effettivi) con un ID univoco per ogni riga. L'ID univoco per una determinata riga deve corrispondere all'ID univoco per gli output del modello per la richiesta di inferenza specifica. Questo ID univoco viene usato per unire il set di dati ground truth agli output del modello.
Senza avere dati reali, non è possibile eseguire il monitoraggio delle prestazioni del modello. Poiché i dati di verità a livello di applicazione vengono rilevati a livello di applicazione, è responsabilità dell'utente raccoglierli man mano che diventano disponibili. È anche consigliabile gestire un asset di dati in Azure Machine Learning che contiene questi dati ground truth.
(Facoltativo) Avere un set di dati tabulare pre-aggiunto con output del modello e dati ground truth già uniti.
Monitorare i requisiti di prestazioni del modello quando si usa l'agente di raccolta dati
Se si usa l'agente di raccolta dati di Azure Machine Learning per raccogliere dati di inferenza di produzione senza specificare il proprio ID univoco per ogni riga come colonna separata, verrà generato automaticamente un correlationid che sarà incluso nell'oggetto JSON registrato. Tuttavia, l'agente di raccolta dati eseguirà il batch di righe inviate entro brevi intervalli di tempo l'uno dall'altro. Le righe soggette batch rientrano nello stesso oggetto JSON e avranno quindi lo stesso correlationid.
Per distinguere le righe nello stesso oggetto JSON, il monitoraggio delle prestazioni del modello di Azure Machine Learning usa l'indicizzazione per determinare l'ordine delle righe nell'oggetto JSON. Ad esempio, se tre righe vengono raggruppate in batch e correlationid è test, la riga 1 avrà un ID test_0, la riga 2 avrà un ID test_1 e la riga 3 avrà un ID test_2. Per assicurarsi che il set di dati ground truth contenga ID univoci che corrispondono agli output del modello di inferenza di produzione raccolti, assicurarsi di indicizzare ogni correlationid in modo appropriato. Se l'oggetto JSON registrato ha una sola riga, correlationid sarà correlationid_0.
Per evitare di usare questa indicizzazione, è consigliabile registrare l'ID univoco nella propria colonna all'interno del DataFrame Pandas che si sta registrando con l'agente di raccolta dati di Azure Machine Learning. Nella configurazione di monitoraggio del modello specificare quindi il nome di questa colonna per unire i dati di output del modello ai dati ground truth. Purché gli ID per ogni riga in entrambi i set di dati siano uguali, il monitoraggio del modello di Azure Machine Learning può eseguire il monitoraggio delle prestazioni del modello.
Flusso di lavoro di esempio per il monitoraggio delle prestazioni del modello
Per comprendere i concetti associati al monitoraggio delle prestazioni del modello, prendere in considerazione questo flusso di lavoro di esempio. Si supponga di distribuire un modello per stimare se le transazioni con carta di credito sono fraudolente o meno, è possibile seguire questa procedura per monitorare le prestazioni del modello:
- Configurare la distribuzione in modo da usare l'agente di raccolta dati per raccogliere i dati di inferenza di produzione del modello (dati di input e output). Si supponga che i dati di output vengano archiviati in una colonna
is_fraud. - Per ogni riga dei dati di inferenza raccolti, registrare un ID univoco. L'ID univoco può provenire dall'applicazione oppure è possibile usare il
correlationidgenerato in modo univoco da Azure Machine Learning per ogni oggetto JSON registrato. - Successivamente, quando i dati
is_frauddi base reali (o effettivi) diventano disponibili, sono registrati e mappati allo stesso ID univoco registrato con gli output del modello. - Questi dati
is_frauddi base vengono raccolti, gestiti e registrati in Azure Machine Learning come asset di dati. - Creare un segnale di monitoraggio delle prestazioni del modello che unisce l'inferenza di produzione del modello e gli asset di dati ground truth usando le colonne ID univoche.
- Infine, calcolare le metriche delle prestazioni del modello.
Una volta soddisfatti i prerequisiti per il monitoraggio delle prestazioni del modello, è possibile impostare il monitoraggio del modello con il seguente comando dell'interfaccia della riga di comando e la definizione YAML:
az ml schedule create -f ./model-performance-monitoring.yaml
Il seguente YAML contiene la definizione per il monitoraggio del modello con i dati di inferenza produttivi raccolti.
$schema: http://azureml/sdk-2-0/Schedule.json
name: model_performance_monitoring
display_name: Credit card fraud model performance
description: Credit card fraud model performance
trigger:
type: recurrence
frequency: day
interval: 7
schedule:
hours: 10
minutes: 15
create_monitor:
compute:
instance_type: standard_e8s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment
monitoring_signals:
fraud_detection_model_performance:
type: model_performance
production_data:
data_column_names:
prediction: is_fraud
correlation_id: correlation_id
reference_data:
input_data:
path: azureml:my_model_ground_truth_data:1
type: mltable
data_column_names:
actual: is_fraud
correlation_id: correlation_id
data_context: actuals
alert_enabled: true
metric_thresholds:
tabular_classification:
accuracy: 0.95
precision: 0.8
alert_notification:
emails:
- abc@example.com





Configurare il monitoraggio dei modelli portando i dati di produzione su Azure Machine Learning
È possibile anche configurare il monitoraggio per i modelli distribuiti agli endpoint batch di Azure Machine Learning o distribuiti al di fuori di Azure Machine Learning. Se non si dispone di una distribuzione, ma si hanno dati di produzione, è possibile utilizzare i dati per eseguire un monitoraggio continuo dei modelli. Per monitorare questi modelli, è necessario essere in grado di:
- Raccogliere i dati di inferenza di produzione dai modelli distribuiti in produzione.
- Registrare i dati di inferenza di produzione come asset di dati di Azure Machine Learning e garantire aggiornamenti continui dei dati.
- Fornire un componente personalizzato di pre-elaborazione dei dati e registrarlo come componente di Azure Machine Learning.
È necessario fornire un componente personalizzato di pre-elaborazione dei dati se i dati non sono raccolti con l'agente di raccolta dati. Senza questo componente personalizzato di pre-elaborazione dei dati, il sistema di monitoraggio del modello di Azure Machine Learning non saprà come elaborare i dati in forma tabellare con supporto per la windowing temporale.
Il componente di pre-elaborazione personalizzato deve disporre di queste firme di input e output:
| Input/Output | Nome della firma | Tipo | Descrizione | Valore di esempio |
|---|---|---|---|---|
| input | data_window_start |
letterale, string | ora di inizio della finestra dati nel formato ISO8601. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
letterale, string | ora di fine della finestra dati nel formato ISO8601. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | I dati di inferenza produttivi raccolti, registrati come asset di dati di Azure Machine Learning. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Un dataset tabulare, che corrisponde a un sottoinsieme dello schema dei dati di riferimento. |
Per un esempio di un componente di pre-elaborazione dei dati personalizzato, vedere custom_preprocessing in the azuremml-examples GitHub repo.
Una volta soddisfatti i requisiti precedenti, è possibile impostare il monitoraggio del modello con il seguente comando dell'interfaccia della riga di comando e la definizione YAML:
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
Il seguente YAML contiene la definizione per il monitoraggio del modello con i dati di inferenza produttivi raccolti.
# model-monitoring-with-collected-data.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with your own production data
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_inputs
pre_processing_component: azureml:production_data_preprocessing:1
reference_data:
input_data:
path: azureml:my_model_training_data:1 # use training data as comparison baseline
type: mltable
data_context: training
data_column_names:
target_column: is_fraud
features:
top_n_feature_importance: 20 # monitor drift for top 20 features
metric_thresholds:
numberical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_prediction_drift: # monitoring signal name, any user defined name works
type: prediction_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_outputs
pre_processing_component: azureml:production_data_preprocessing:1
reference_data:
input_data:
path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset
type: mltable
data_context: validation
metric_thresholds:
categorical:
pearsons_chi_squared_test: 0.02
alert_notification:
emails:
- abc@example.com
- def@example.com
Configurare il monitoraggio dei modelli con segnali e metriche personalizzati
Con il monitoraggio dei modelli di Azure Machine Learning, è possibile definire un segnale personalizzato e implementare qualsiasi metrica di propria scelta per monitorare il proprio modello. È possibile registrare questo segnale personalizzato come componente di Azure Machine Learning. Quando il processo di monitoraggio del modello di Azure Machine Learning viene eseguito secondo la programmazione specificata, calcola la o le metriche definite all'interno del segnale personalizzato, proprio come fa per i segnali predefiniti (deriva dei dati, deriva delle previsioni e qualità dei dati).
Per configurare un segnale personalizzato da utilizzare per il monitoraggio del modello, è necessario prima definire il segnale personalizzato e registrarlo come componente di Azure Machine Learning. Il componente di Azure Machine Learning deve disporre di queste firme di input e output:
Firma di input del componente
Il DataFrame di input del componente dovrebbe contenere i seguenti elementi:
- Un
mltablecon i dati elaborati dal componente di pre-elaborazione - Un numero qualsiasi di letterali, ciascuno rappresentante una metrica implementata come parte del componente di segnale personalizzato. Ad esempio, se hai implementato la metrica,
std_deviation, allora si avrà bisogno di un input perstd_deviation_threshold. Generalmente, dovrebbe esserci un input per metrica con il nome<metric_name>_threshold.
| Nome della firma | Tipo | Descrizione | Valore di esempio |
|---|---|---|---|
| production_data | mltable | Un dataset tabulare che corrisponde a un sottoinsieme dello schema dei dati di riferimento. | |
| std_deviation_threshold | letterale, string | Soglia corrispondente per la metrica implementata. | 2 |
Firma di output del componente
La porta di output del componente dovrebbe avere la seguente firma.
| Nome della firma | Tipo | Descrizione |
|---|---|---|
| signal_metrics | mltable | Il mltable che contiene le metriche calcolate. Lo schema è definito nella sezione successiva denominata signal_metrics schema. |
signal_metrics schema
Il DataFrame di output del componente dovrebbe contenere quattro colonne: group, metric_name, metric_value e threshold_value.
| Nome della firma | Tipo | Descrizione | Valore di esempio |
|---|---|---|---|
| group | letterale, string | Raggruppamento logico di livello superiore da applicare a questa metrica personalizzata. | TRANSACTIONAMOUNT |
| metric_name | letterale, string | Il nome della metrica personalizzata. | std_deviation |
| metric_value | numerico | Il valore della metrica personalizzata. | 44,896.082 |
| threshold_value | numerico | La soglia per la metrica personalizzata. | 2 |
La seguente tabella mostra un esempio di output da un componente di segnale personalizzato che calcola la metrica std_deviation:
| group | metric_value | metric_name | threshold_value |
|---|---|---|---|
| TRANSACTIONAMOUNT | 44,896.082 | std_deviation | 2 |
| LOCALHOUR | 3.983 | std_deviation | 2 |
| TRANSACTIONAMOUNTUSD | 54,004.902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| PHYSICALITEMCOUNT | 5.509 | std_deviation | 2 |
Per vedere un esempio di definizione di componente di segnale personalizzato e codice di calcolo della metrica, vedere custom_signal in the azureml-examples repo.
Una volta soddisfatti i requisiti per l'utilizzo di segnali e metriche personalizzate, è possibile configurare il monitoraggio del modello con il seguente comando dell'interfaccia della riga di comando e la definizione YAML:
az ml schedule create -f ./custom-monitoring.yaml
Il seguente YAML contiene la definizione per il monitoraggio del modello con un segnale personalizzato. Alcune cose da notare riguardo al codice:
- Si presume che sia già stato creato e registrato il proprio componente con la definizione di segnale personalizzato in Azure Machine Learning.
component_iddel componente di segnale personalizzato registrato èazureml:my_custom_signal:1.0.0.- Se si sono raccolti i propri dati con l'Agente di raccolta dati, si può omettere la proprietà
pre_processing_component. Se si desidera utilizzare un componente di pre-elaborazione per elaborare i dati di produzione non raccolti dall'Agente di raccolta dati, è possibile specificarlo.
# custom-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: my-custom-signal
trigger:
type: recurrence
frequency: day # can be minute, hour, day, week, month
interval: 7 # #every day
create_monitor:
compute:
instance_type: "standard_e4s_v3"
runtime_version: "3.3"
monitoring_signals:
customSignal:
type: custom
component_id: azureml:my_custom_signal:1.0.0
input_data:
production_data:
input_data:
type: uri_folder
path: azureml:my_production_data:1
data_context: test
data_window:
lookback_window_size: P30D
lookback_window_offset: P7D
pre_processing_component: azureml:custom_preprocessor:1.0.0
metric_thresholds:
- metric_name: std_deviation
threshold: 2
alert_notification:
emails:
- abc@example.com
Interpretare i risultati del monitoraggio
Dopo aver configurato il monitoraggio del modello e completato la prima esecuzione, è possibile tornare alla scheda Monitoraggio in studio di Azure Machine Learning per visualizzare i risultati.
Dalla vista principale Monitoraggio, selezionare il nome del monitoraggio del modello per accedere alla pagina Panoramica monitoraggio. Questa pagina mostra il modello corrispondente, l'endpoint e la distribuzione, insieme ai dettagli relativi ai segnali configurati. L'immagine seguente mostra un dashboard di monitoraggio che include i segnali di deriva dei dati e qualità dei dati. A seconda dei segnali di monitoraggio configurati, il dashboard potrebbe apparire diverso.
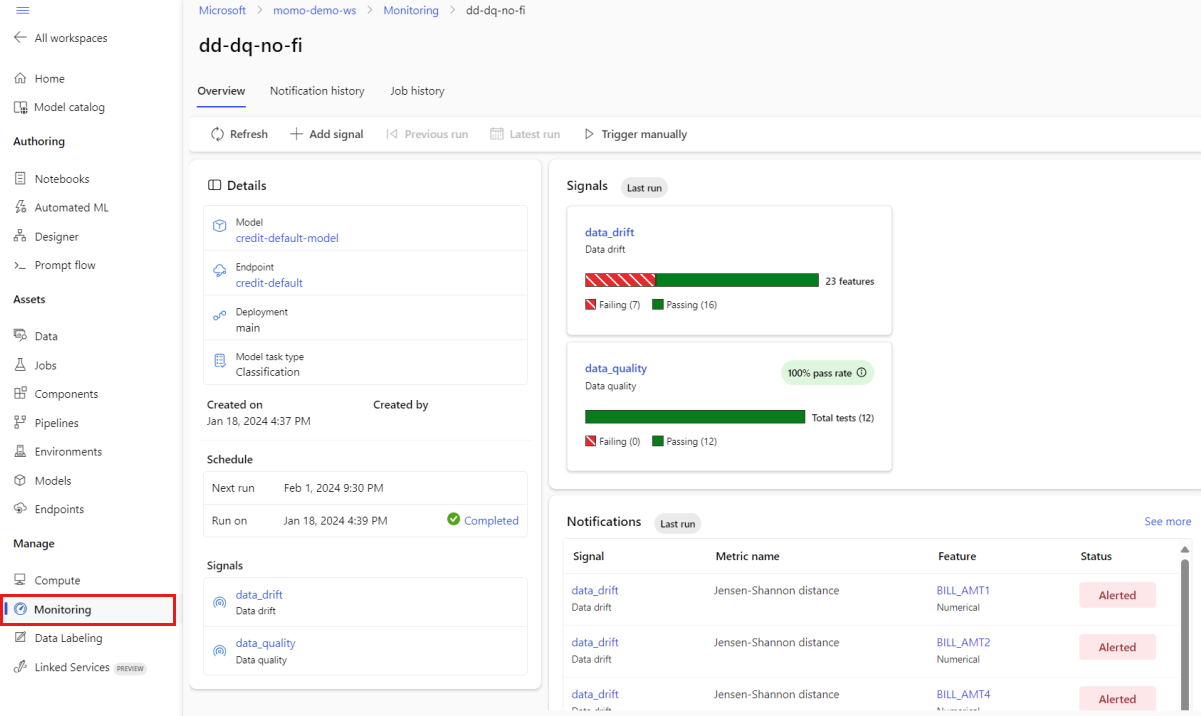
Consultare la sezione Notifiche del dashboard per vedere, per ciascun segnale, quali caratteristiche hanno superato la soglia configurata per le rispettive metriche:
Selezionare data_drift per accedere alla pagina dei dettagli sulla deriva dei dati. Nella pagina dei dettagli, è possibile vedere il valore della metrica di deriva dei dati per ogni caratteristica numerica e categorica inclusa nella configurazione di monitoraggio. Quando il monitoraggio ha registrato più di una esecuzione, si potrà osservare una linea di tendenza per ciascuna caratteristica.
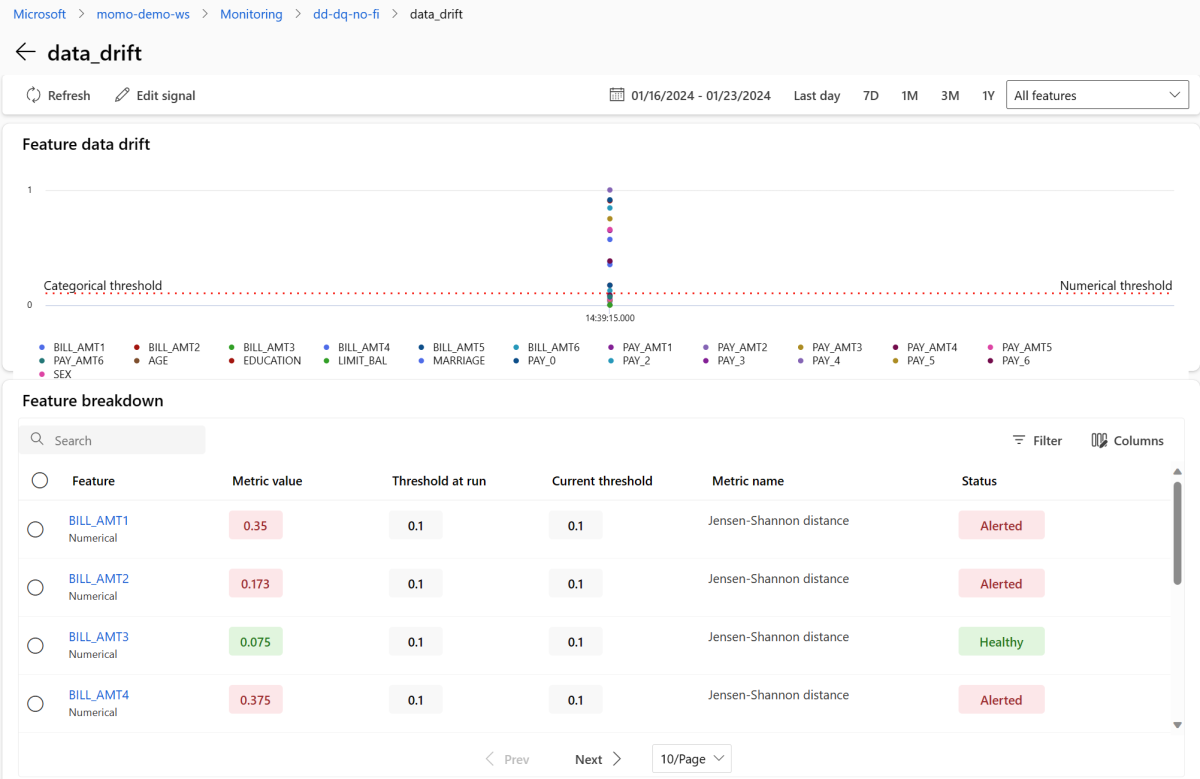
Per visualizzare nel dettaglio una singola caratteristica, selezionare il nome della caratteristica per visualizzare la distribuzione dei dati in produzione rispetto alla distribuzione di riferimento. Questa vista consente anche di tracciare l'andamento della deriva nel tempo per quella specifica caratteristica.
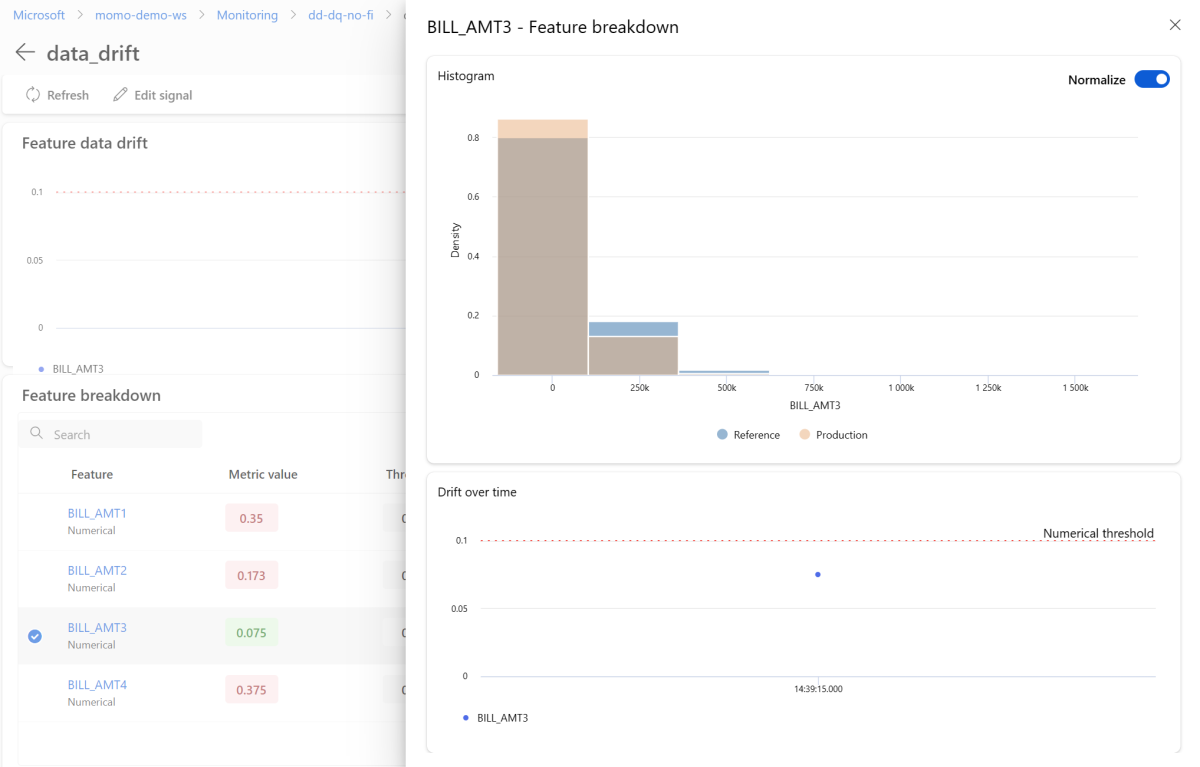
Tornare al dashboard di monitoraggio e selezionare data_quality per visualizzare la pagina del segnale di qualità dei dati. In questa pagina, è possibile vedere i tassi di valori nulli, i tassi di valori fuori intervallo e i tassi di errori sui tipi di dati per ogni caratteristica monitorata.
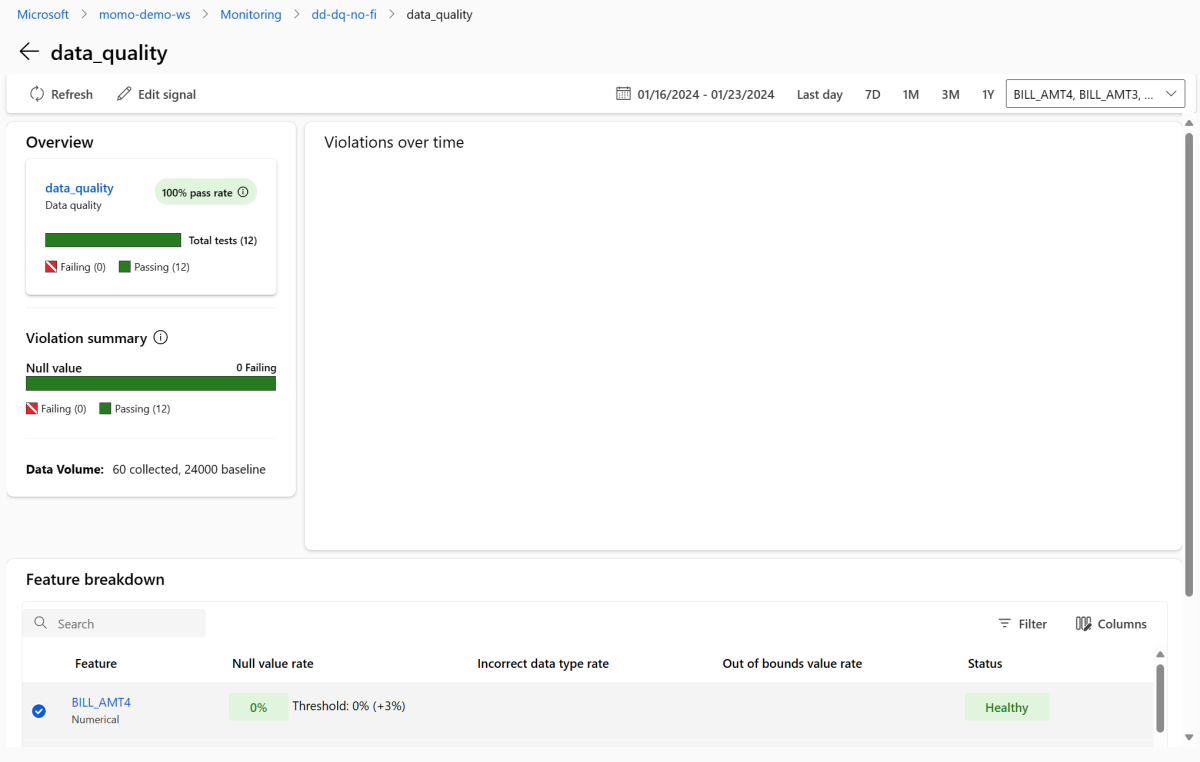




Il monitoraggio dei modelli è un processo continuo. Con il monitoraggio dei modelli di Azure Machine Learning, è possibile configurare più segnali di monitoraggio per ottenere una visione ampia delle prestazioni dei propri modelli in produzione.
Integrazione del monitoraggio dei modelli di Azure Machine Learning con la Griglia di eventi di Azure
È possibile utilizzare gli eventi generati dal monitoraggio dei modelli di Azure Machine Learning per configurare applicazioni, processi o flussi di lavoro CI/CD guidati dagli eventi con la Griglia di eventi di Azure. Si può usufruire di eventi tramite vari gestori di eventi, quali Hub eventi di Azure, funzioni di Azure e app per la logica. In base alla deriva rilevata dai monitoraggi, è possibile intraprendere azioni in modo programmatico, ad esempio configurando un pipeline di Machine Learning per eseguire nuovamente il training di un modello e ridistribuirlo.
Per iniziare con l'integrazione del monitoraggio dei modelli di Azure Machine Learning con la Griglia di eventi di Azure:
Seguire i passaggi nella sezione Configurare nel portale di Azure. Dare all'Abbonamento eventi un nome, come MonitoringEvent, e selezionare solo la casella Cambiamento stato esecuzione sotto Tipi di evento.
Avviso
Assicurarsi di selezionare Cambiamento stato esecuzione per il tipo di evento. Non selezionare Rilevamento deriva dataset, poiché si applica alla deriva dei dati v1, piuttosto che al monitoraggio dei modelli di Azure Machine Learning.
Seguire i passaggi in Filtro e abbonamento agli eventi per impostare il filtraggio degli eventi per il proprio scenario. Navigare alla scheda Filtri e aggiungere i seguenti Chiave, Operatore e Valore sotto Filtri avanzati:
- Chiave:
data.RunTags.azureml_modelmonitor_threshold_breached - Valore: non è riuscito a causa della violazione delle soglie metriche da parte di una o più caratteristiche
- Operatore: Contiene stringa
Con questo filtro, gli eventi vengono generati quando lo stato dell'esecuzione cambia (da Completato a Non riuscito, o da Non riuscito a Completato) per qualsiasi monitoraggio all'interno della propria area di lavoro di Azure Machine Learning.
- Chiave:
Per filtrare a livello di monitoraggio, utilizzare i seguenti Chiave, Operatore e Valore sotto Filtri avanzati:
- Chiave:
data.RunTags.azureml_modelmonitor_threshold_breached - Valore:
your_monitor_name_signal_name - Operatore: Contiene stringa
Assicurarsi che
your_monitor_name_signal_namesia il nome di un segnale nel monitoraggio specifico per cui si desidera filtrare gli eventi. Ad esempio,credit_card_fraud_monitor_data_drift. Perché questo filtro funzioni, questa stringa deve corrispondere al nome del segnale di monitoraggio. Si dovrebbe nominare il proprio segnale con sia il nome del monitoraggio che il nome del segnale per questo caso.- Chiave:
Quando si è completata la configurazione dell'Abbonamento eventi, selezionare l'endpoint desiderato per fungere da gestore di eventi, come gli Hub eventi di Azure.
Dopo che gli eventi sono stati acquisiti, è possibile visualizzarli dalla pagina dell'endpoint:
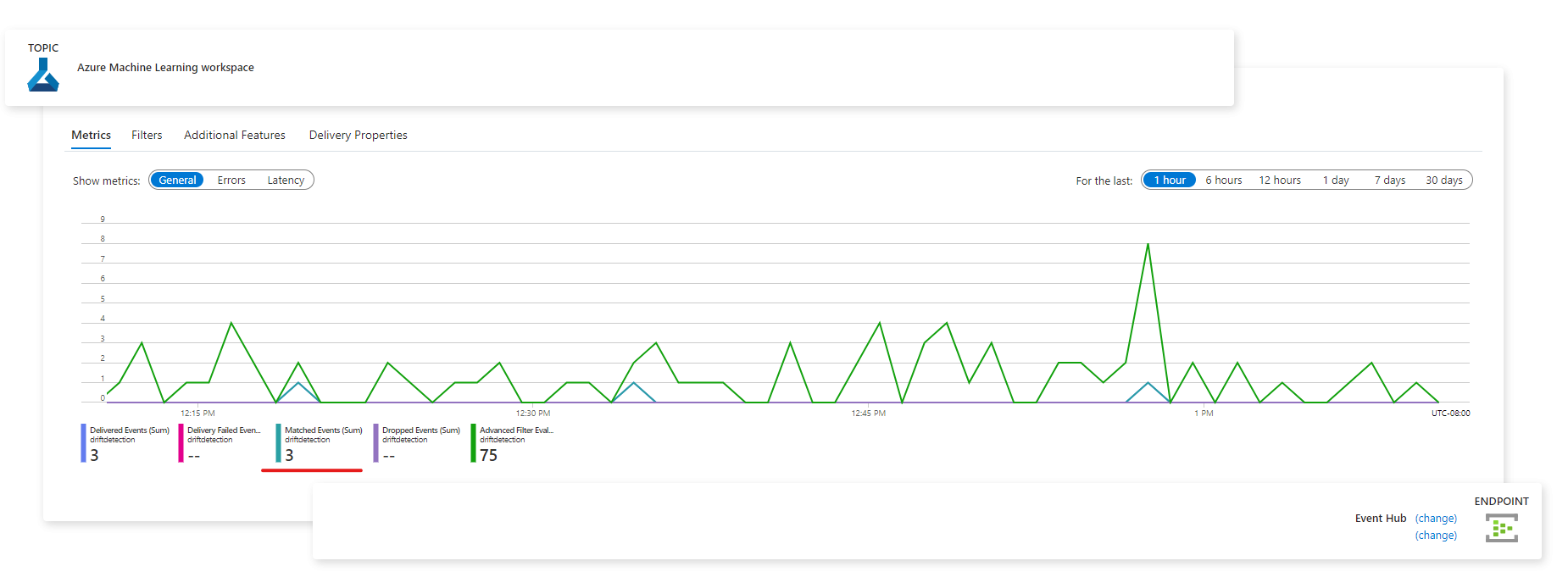

"È possibile visualizzare gli eventi anche nella scheda Metriche di Monitoraggio di Azure:

Contenuto correlato
- Raccolta dati dai modelli in produzione (anteprima)
- Raccogliere dati di produzione dai modelli distribuiti per l'inferenza in tempo reale
- Schema YAML dell'interfaccia della riga di comando (v2) per la pianificazione del monitoraggio dei modelli (anteprima)
- Monitoraggio dei modelli per applicazioni di intelligenza artificiale generativa