Trasformare i dati nella finestra di progettazione di Azure Machine Learning
Questo articolo illustra come trasformare e salvare i set di dati nella finestra di progettazione di Azure Machine Learning per preparare i propri dati per l'apprendimento automatico.
Verrà usato il set di dati di esempio Adult Census Income Binary Classification per preparare due set di dati: uno che include le informazioni sul censimento solo degli adulti statunitensi e un altro set di dati che include le informazioni sul censimento degli adulti non statunitensi.
In questo articolo si apprenderà come:
- Trasformare un set di dati per prepararlo per il training.
- Esportare i set di dati risultanti in un archivio dati.
- Visualizzare i risultati.
Questa procedura è un prerequisito per l'articolo Come ripetere il training dei modelli di progettazione. Questo articolo illustra come usare i set di dati trasformati per eseguire il training di più modelli con parametri della pipeline.
Importante
Se non si osservano elementi grafici menzionati in questo documento, ad esempio i pulsanti di Studio o della finestra di progettazione, è possibile che non si abbia il livello di autorizzazioni appropriato per l'area di lavoro. Contattare l'amministratore della sottoscrizione di Azure per verificare che sia stato concesso il livello di accesso corretto. Per altre informazioni, visitare Gestire utenti e ruoli.
Trasformare un set di dati
In questa sezione si apprenderà come importare il set di dati di esempio e suddividere i dati in set di dati statunitensi e non statunitensi. Visitare come importare i dati per altre informazioni su come importare dati personalizzati nella finestra di progettazione.
Importare i dati
Usare questi passaggi per importare il set di dati di esempio:
Accedere a Studio di Azure Machine Learning e selezionare l'area di lavoro da usare
Accedere alla finestra di progettazione. Selezionare Crea una nuova pipeline usando i componenti classici predefiniti per creare una nuova pipeline
A sinistra del canvas della pipeline, nella scheda Componente espandere il nodo Dati di esempio
Trascina la selezione del set di dati Classificazione binaria Adult Census Income nel canvas
Selezionare con il pulsante destro del mouse il componente del set di dati Adult Census Income e selezionare Anteprima dati
Usare la finestra di anteprima dei dati per esplorare il set di dati. Prendere nota speciale dei valori della colonna "native-country"
Suddividere i dati
In questa sezione si userà il componente Dividi dati per identificare e dividere le righe che contengono "Stati Uniti" nella colonna "native-country"
A sinistra dell'area di disegno, nella scheda dei componenti espandere la sezione Trasformazione dati e individuare il componente Dividi dati
Trascinare il componente Dividi dati nel canvas e rilasciare il componente sotto il componente del set di dati
Connettere il componente del set di dati al componente Dividi dati
Selezionare il componente Dividi dati per aprire il riquadro Dividi dati
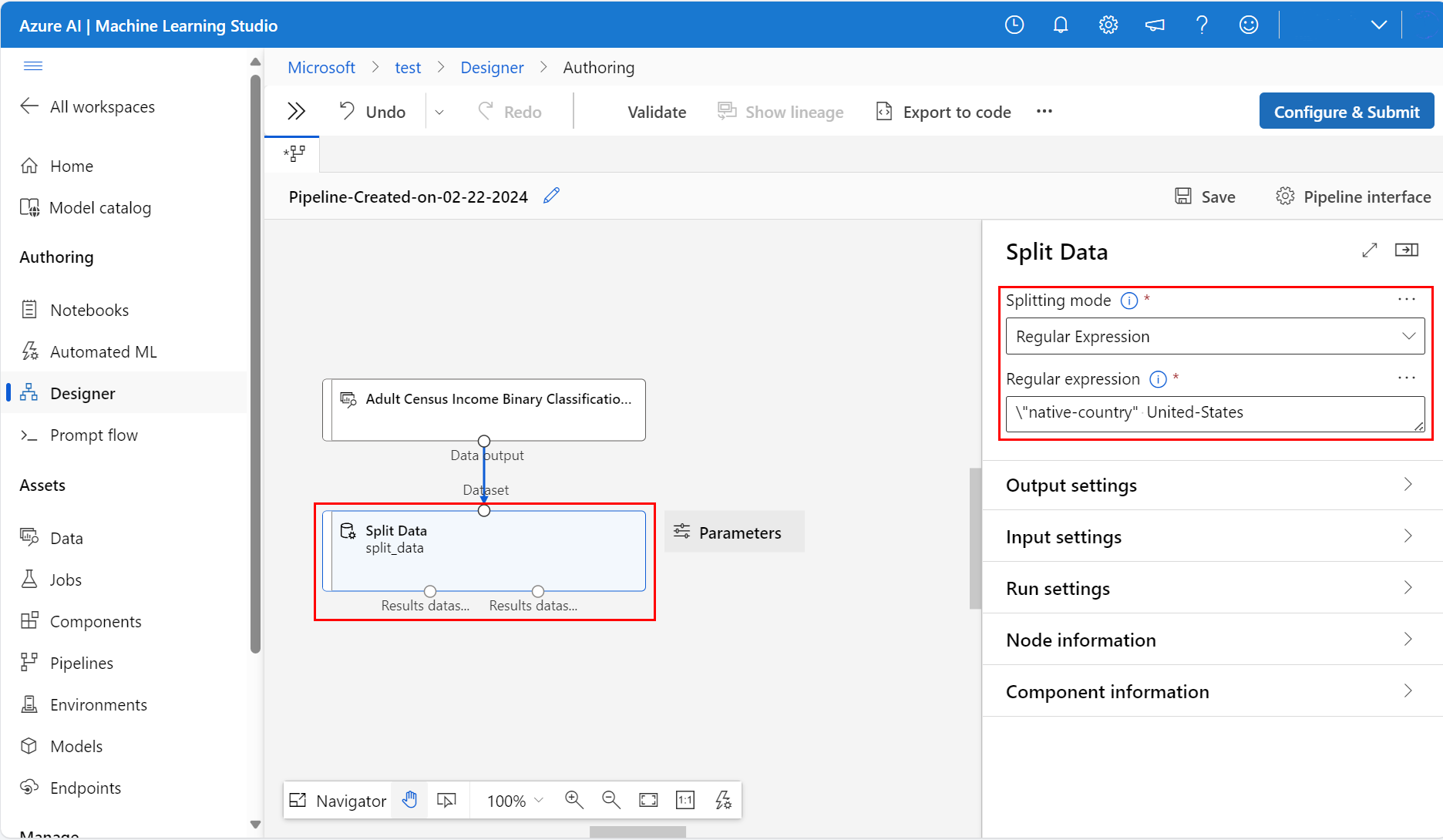
A destra del canvas nell'icona Parametri, impostare Modalità di suddivisione su Espressione regolare
Immettere l'Espressione regolare:
\"native-country" United-StatesLa modalità Espressione regolare esegue il test di una singola colonna per un valore. Per altre informazioni sul componente Dividi dati, visitare la pagina di riferimento relativa al componente algoritmo
La pipeline deve essere simile a questo screenshot:
Salvare i set di dati
Dopo aver configurato la pipeline per suddividere i dati, è necessario specificare la posizione in cui salvare i set di dati. Per questo esempio, utilizzare il componente Esporta dati per salvare il set di dati in un archivio dati. Visitare Connettersi ai servizi di archiviazione di Azure per altre informazioni sugli archivi dati.
A sinistra del canvas nella tavolozza dei componenti espandere la sezione Input e output dei dati e individuare il componente Esporta dati
Trascinare la selezione dei due componenti Esporta dati sotto il componente Dividi dati
Connettere ogni porta di output del componente Dividi dati a un componente Esporta dati diverso
La pipeline deve essere simile a questo:
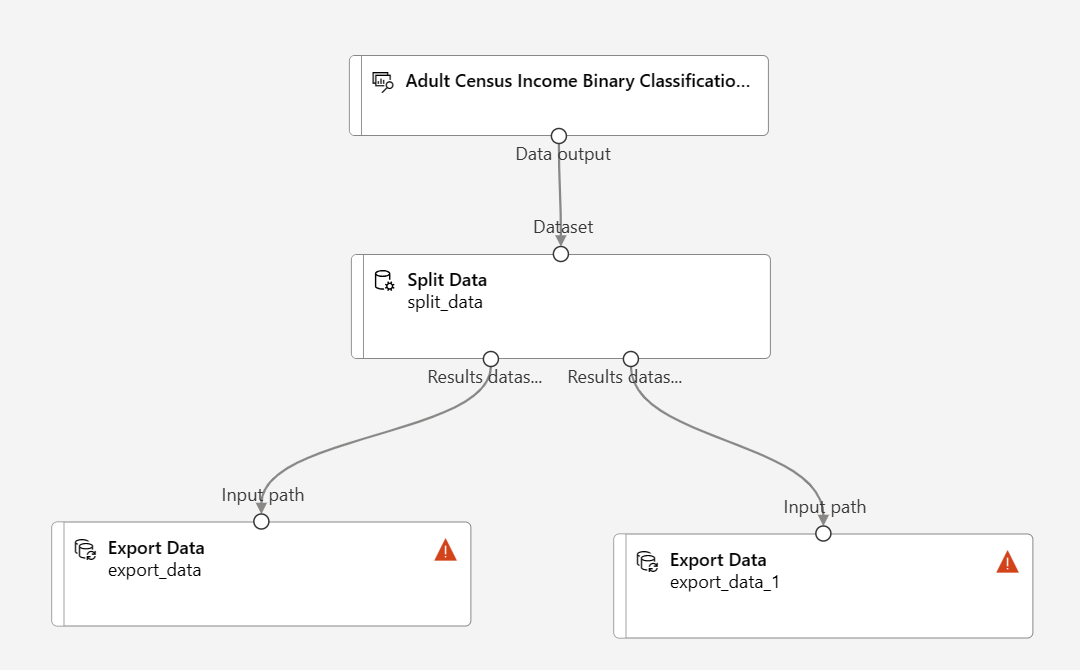
Selezionare il componente Esporta dati connesso alla porta più a sinistra del componente Dividi dati per aprire il riquadro di configurazione Esporta dati
Per il componente Dividi dati, l'ordine delle porte di output è importante. La prima porta di output contiene le righe in cui l'espressione regolare è true. In questo caso, la prima porta contiene righe per il reddito basato su dati statunitensi e la seconda porta contiene righe per il reddito basato su dati non statunitensi
Nel riquadro dei dettagli del componente a destra del canvas, impostare le opzioni seguenti:
Tipo di archivio dati: archiviazione BLOB di Azure
Archivio dati: selezionare un archivio dati esistente oppure selezionare "Nuovo archivio dati" per crearne uno nuovo
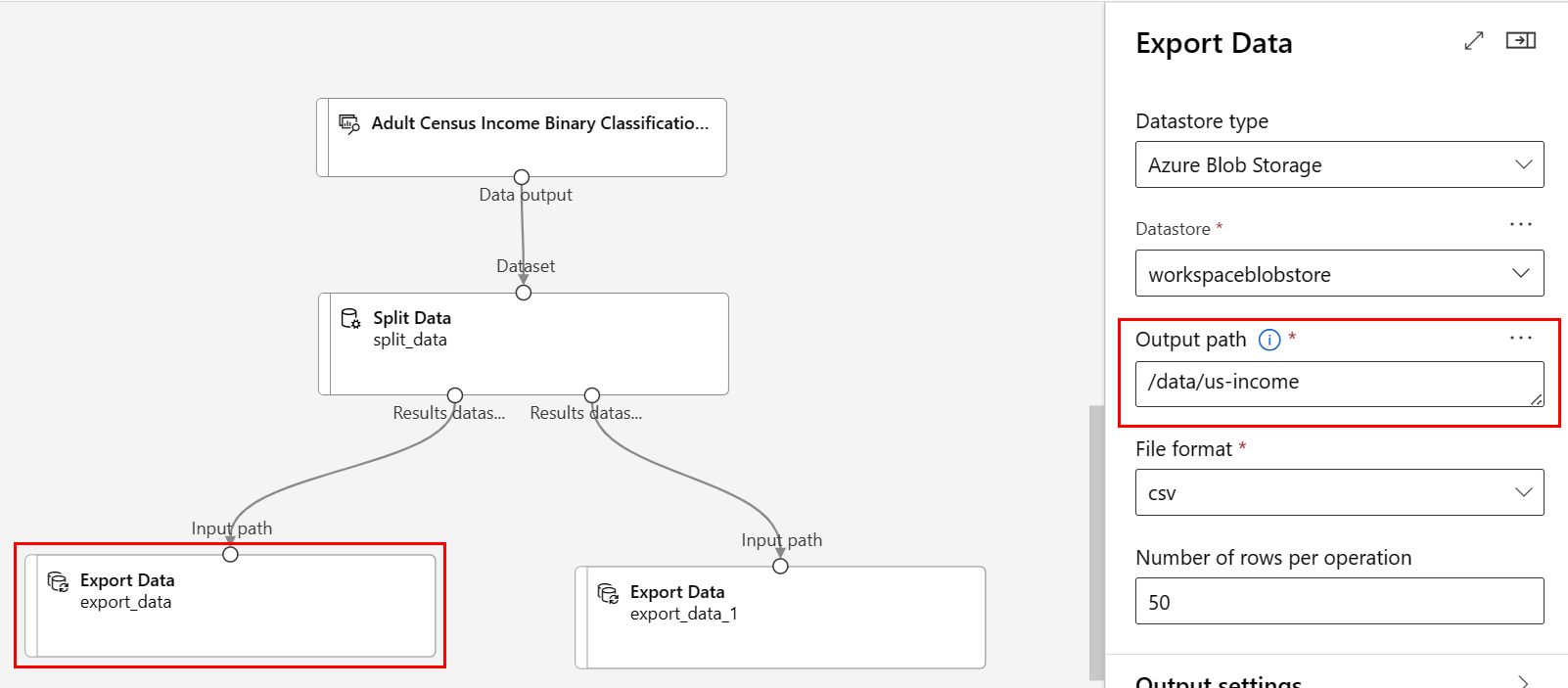
Percorso:
/data/us-incomeFormato file: csv
Nota
Questo articolo presuppone che l'utente abbia accesso a un archivio dati registrato alla corrente area di lavoro di Azure Machine Learning. Per istruzioni sulla configurazione dell'archivio dati, visitare Connettersi ai servizi di archiviazione di Azure
Se non è disponibile, è possibile creare un archivio dati. A titolo esemplificativo, in questo articolo i set di dati vengono salvati nell'account di archiviazione BLOB predefinito associato all'area di lavoro. I set di dati vengono salvati nel contenitore
azuremlin una nuova cartella denominatadataSelezionare il componente Esporta dati connesso alla porta più a destra del componente Dividi dati per aprire il riquadro di configurazione Esporta dati
A destra del canvas nel riquadro dei dettagli del componente, impostare le opzioni seguenti:
Tipo di archivio dati: archiviazione BLOB di Azure
Archivio dati: selezionare l'archivio dati precedente
Percorso:
/data/non-us-incomeFormato file: csv
Verificare che il componente Esporta dati connesso alla porta sinistra di Dividi dati disponga del Percorso
/data/us-incomeVerificare che il componente Esporta dati connesso alla porta destra disponga del Percorso
/data/non-us-incomeLa pipeline e le impostazioni dovrebbero avere un aspetto simile al seguente:
Inviare il processo
Dopo aver configurato la pipeline per suddividere ed esportare i dati, inviare un processo della pipeline.
Selezionare Configura e invia nella parte superiore del canvas
Selezionare l'opzione Crea nuovo nel riquadro Informazioni di base di Configurare il processo della pipeline per creare un esperimento
Gli esperimenti raggruppano logicamente i processi della pipeline correlati. Se si esegue questa pipeline in futuro, è consigliabile usare lo stesso esperimento a scopi di registrazione e verifica
Specificare un nome descrittivo dell'esperimento, ad esempio "split-census-data"
Selezionare Rivedi e inviae quindi selezionare Invia
Visualizza risultati
Al termine dell'esecuzione della pipeline, è possibile passare all'archivio BLOB del portale di Azure per visualizzare i risultati. È anche possibile visualizzare i risultati intermedi del componente Dividi dati per verificare che i dati sono suddivisi correttamente.
Selezionare il componente Dividi dati
Nel riquadro dei dettagli del componente a destra del canvas, selezionare la scheda Output e log
Selezionare l'elenco a discesa Mostra output dei dati
Selezionare l'icona di visualizzazione
 accanto a Set di dati risultati 1
accanto a Set di dati risultati 1Verificare che la colonna "native-country" contenga solo il valore "Stati Uniti"
Selezionare l'icona di visualizzazione
accanto a Set di dati risultati 2Verificare che la colonna "native-country" non contenga il valore "United-States"
Pulire le risorse
Per continuare con la seconda parte di questa guida Ripetere il training dei modelli con la finestra di progettazione di Azure Machine Learning, ignorare questa sezione.
Importante
È possibile usare le risorse create come prerequisiti per altre esercitazioni e procedure dettagliate relative ad Azure Machine Learning.
Eliminare tutto
Se non si prevede di usare le risorse create, eliminare l'intero gruppo di risorse per evitare addebiti.
Nel portale di Azure, selezionare Gruppi di risorse nella parte sinistra della finestra.
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
Se si elimina il gruppo di risorse, vengono eliminate anche tutte le risorse create nella finestra di progettazione.
Eliminare singole risorse
Nella finestra di progettazione in cui è stato creato l'esperimento eliminare le singole risorse selezionandole e quindi selezionando il pulsante Elimina.
La destinazione di calcolo creata qui viene ridimensionata automaticamente a zero nodi quando non viene usata, Questa azione viene intrapresa per ridurre al minimo gli addebiti. Se si vuole eliminare la destinazione di calcolo, eseguire le operazioni seguenti:
La registrazione dei set di dati nell'area di lavoro può essere annullata selezionando ogni set di dati e quindi Annulla registrazione.
Per eliminare un set di dati, passare all'account di archiviazione tramite il portale di Azure o Azure Storage Explorer ed eliminare manualmente tali asset.
Passaggi successivi
In questo articolo si è appreso come trasformare un set di dati e salvarlo in un archivio dati registrato.
Passare alla parte successiva di questa serie di procedure con Ripetere il training dei modelli con la finestra di progettazione di Azure Machine Learning per usare i set di dati trasformati e i parametri della pipeline per eseguire il training dei modelli di Machine Learning.