Esempi sulle Data Science Virtual Machine di Azure
Una Data Science Virtual Machines (DSVM) di Azure include un set completo di codice di esempio. Questi esempi includono notebook Jupyter e script in linguaggi come Python e R.
Nota
Per altre informazioni su come eseguire i notebook Jupyter in Data Science Virtual Machine, vedere la sezione Accesso a Jupyter.
Prerequisiti
Per eseguire questi esempi, è necessario disporre di una Data Science Virtual Machine Ubuntu di cui è stato effettuato il provisioning.
Esempi disponibili
| Categoria di esempi | Descrizione | Ubicazioni |
|---|---|---|
| Linguaggio di programmazione di Python | Esempi che illustrano come connettersi agli archivi dati cloud basati su Azure e come usare gli scenari di Azure Machine Learning. Linguaggio di programmazione di Python |
~notebooks |
| Linguaggio di programmazione di Julia | Fornisce una descrizione dettagliata del tracciato e di Deep Learning in Julia. Spiega come chiamare C e Python da Julia. Linguaggio di programmazione di Julia |
Windows: ~notebooks/Julia_notebooksLinux: ~notebooks/julia |
| Azure Machine Learning | Illustra come creare modelli di apprendimento automatico e di Deep Learning con Machine Learning. Distribuire i modelli ovunque. Usare le funzionalità automatizzate di Machine Learning e l'ottimizzazione intelligente degli iperparametri. Usare la gestione modelli e il training distribuito. Machine Learning |
~notebooks/AzureML |
| Notebook PyTorch | Esempi di Deep Learning che usano reti neurali basate su PyTorch. I livelli dei notebook vanno dallo scenario per principianti agli scenari avanzati. Notebook PyTorch |
~notebooks/Deep_learning_frameworks/pytorch |
| TensorFlow | Vari esempi e tecniche di rete neurale implementati con il framework TensorFlow. TensorFlow |
~notebooks/Deep_learning_frameworks/tensorflow |
| H2O | Esempi basati su Python che usano H2O per numerosi scenari di problemi reali. H2O |
~notebooks/h2o |
| Linguaggio di programmazione di SparkML | Esempi che usano le funzionalità del toolkit Apache Spark MLLib tramite pySpark e MMLSpark: Microsoft Machine Learning per Apache Spark in Apache Spark 2.x. Linguaggio di programmazione di SparkML |
~notebooks/SparkML/pySpark~notebooks/MMLSpark |
| XGBoost | Esempi standard di Machine Learning in XGBoost, ad esempio classificazione e regressione. XGBoost |
Windows: \dsvm\samples\xgboost\demo |
Accesso a Jupyter
Per accedere a Jupyter, selezionare l'icona Jupyter sul desktop o nel menu dell'applicazione. È anche possibile accedere a Jupyter in un'edizione Linux di una DSVM. Per l'accesso remoto da un Web browser, visitare https://<Full Domain Name or IP Address of the DSVM>:8000 in Ubuntu.
Per aggiungere eccezioni e rendere disponibile l'accesso a Jupyter tramite un browser, usare queste indicazioni:
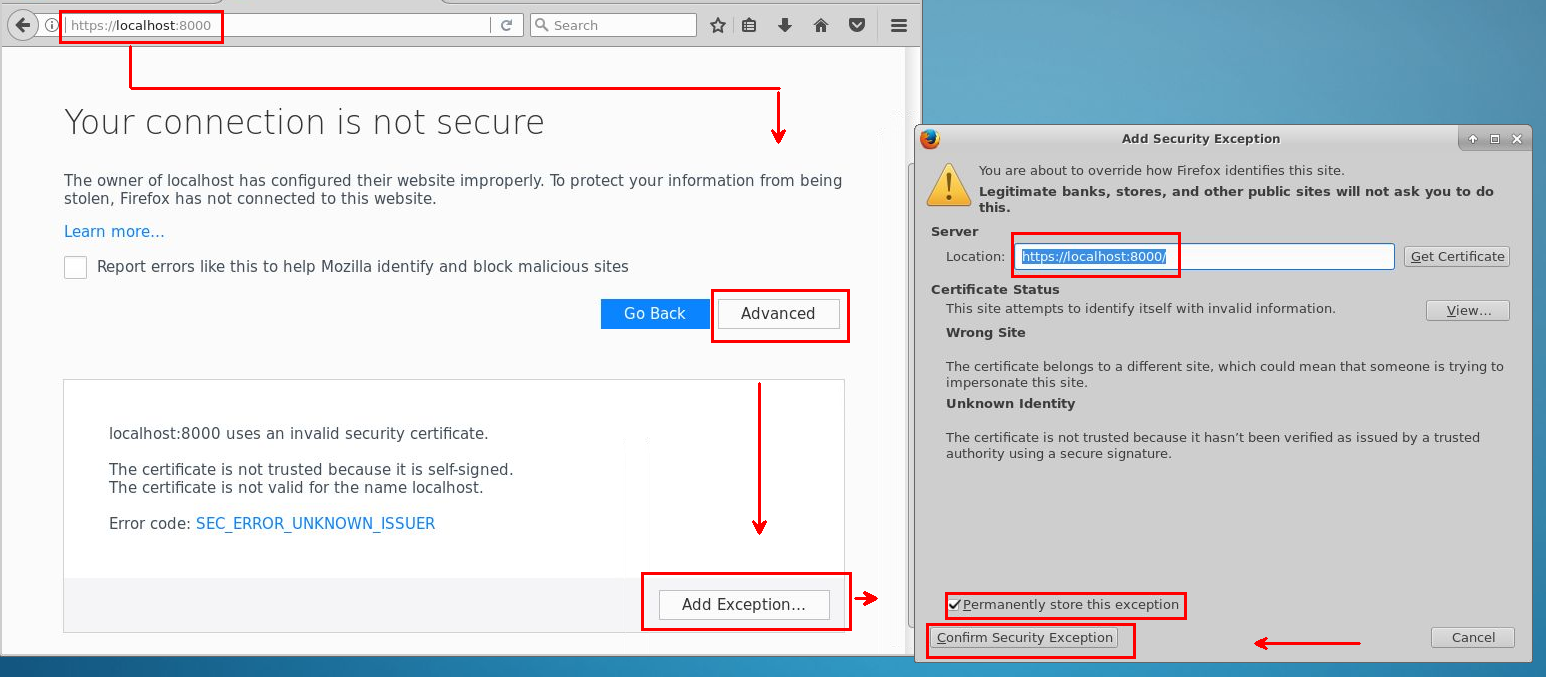
Accedere con la stessa password usata per gli account di accesso di Data Science Virtual Machine.
Pagina iniziale di Jupyter

Linguaggio R

Linguaggio di programmazione di Python

Linguaggio di programmazione di Julia

Azure Machine Learning

PyTorch

TensorFlow

H2O

SparkML

XGBoost
