Ottimizzazione dell'utilizzo della memoria per Apache Spark
Questo articolo illustra come ottimizzare la gestione della memoria del cluster di Apache Spark per ottenere prestazioni ottimali in Azure HDInsight.
Panoramica
Spark funziona inserendo i dati in memoria. Pertanto, la gestione delle risorse di memoria è un aspetto essenziale per ottimizzare l'esecuzione dei processi Spark. Esistono diverse tecniche che è possibile applicare per usare la memoria del cluster in modo efficiente.
- Prediligere partizioni di dati più piccole e tenere conto delle dimensioni, del tipo e della distribuzione dei dati nella strategia di partizionamento.
- Valutare la versione più recente e più efficiente di
Kryo data serialization, anziché la serializzazione Java predefinita. - Prediligere l'uso di YARN, che consente la separazione
spark-submitper batch. - Monitorare e ottimizzare le impostazioni di configurazione di Spark.
La struttura della memoria Spark e alcuni parametri di memoria dell'executor chiave vengono visualizzati nella figura seguente per riferimento.
Considerazioni sulla memoria Spark
Se si usa Apache Hadoop YARN, questo controlla la memoria usata da tutti i contenitori in ogni nodo Spark. Il diagramma seguente mostra gli oggetti chiave e le relative relazioni.
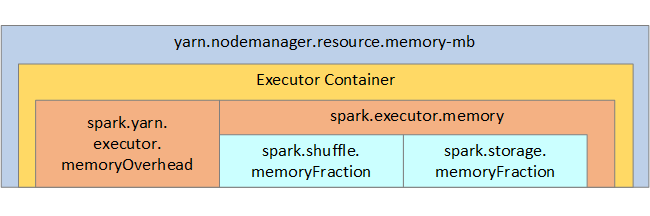
Per indirizzare messaggi di "memoria insufficiente", provare a:
- Esaminare le riproduzioni casuali con gestione DAG. Ridurre mediante riduzione lato mappa, pre-partizione (o assegnazione di bucket) dell'origine dati, ottimizzazione delle riproduzioni con sequenza casuale singole e riduzione della quantità di dati inviati.
- Prediligere
ReduceByKeyper il limite di memoria fissa rispetto aGroupByKey, che fornisce aggregazioni, windowing e altre funzioni, ma non ha limite di memoria. - Prediligere
TreeReduce, che esegue più operazioni su executor e partizioni rispetto aReduce, che esegue tutto il lavoro sul driver. - Usare i frame di dati, anziché gli oggetti RDD di livello inferiore.
- Creare tipi complessi in grado di incapsulare azioni, come ad esempio "Top N", diverse aggregazioni od operazioni di windowing.
Per altri passaggi per la risoluzione dei problemi, vedere Eccezioni OutOfMemoryError per Apache Spark in Azure HDInsight.