Eccezioni OutOfMemoryError per Apache Spark in Azure HDInsight
Questo articolo descrive le procedure di risoluzione dei problemi e le possibili soluzioni per i problemi relativi all'uso di componenti Apache Spark nei cluster Azure HDInsight.
Scenario: Eccezione OutOfMemoryError per Apache Spark
Problema
L'applicazione Apache Spark non è riuscita con un'eccezione OutOfMemoryError non gestita. È possibile che venga visualizzato un messaggio di errore simile al seguente:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Causa
La causa più probabile per questa eccezione è costituita dall'allocazione di memoria heap insufficiente alle macchine virtuali Java (JVM). Queste macchine virtuali Java vengono avviate come executor o driver come parte dell'applicazione Apache Spark.
Risoluzione
Determinare le dimensioni massime dei dati che possono essere gestiti dall'applicazione Spark. Fare una stima delle dimensioni in base alle dimensioni massime dei dati di input, i dati intermedi prodotti trasformando i dati di input e i dati di output ottenuti dalla trasformazione ulteriore dei dati intermedi. Se la stima iniziale non è sufficiente, aumentare leggermente le dimensioni e ripetere l'operazione fino a quando gli errori di memoria non si attenuano.
Assicurarsi che il cluster HDInsight da utilizzare disponga di sufficienti risorse in termini di memoria e core per supportare l'applicazione Spark. Ciò può essere determinato visualizzando la sezione Metriche cluster dell'interfaccia utente YARN del cluster e confrontando i valori di Memoria usata e Memory Total (Memoria totale) e i valori di VCores Used (VCore usati) e VCores Total (VCore totali).

Impostare le configurazioni spark seguenti sui valori appropriati. Bilanciare i requisiti dell'applicazione con le risorse disponibili nel cluster. Questi valori non devono superare il 90% della memoria e dei core disponibili come visualizzato da YARN e devono soddisfare anche il requisito di memoria minima dell'applicazione Spark:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Memoria totale usata da tutti gli esecutori =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Memoria totale usata dal driver =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Scenario: errore di spazio heap Java durante il tentativo di aprire il server cronologia Apache Spark
Problema
Quando si apre eventi nel server cronologia Spark, viene visualizzato l'errore seguente:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Causa
Questo problema è spesso causato dalla mancanza di risorse quando si aprono file di eventi Spark di grandi dimensioni. Le dimensioni dell'heap Spark sono impostate su 1 GB per impostazione predefinita, ma i file di eventi Spark di grandi dimensioni possono richiedere più di questo.
Se si desidera verificare le dimensioni dei file da caricare, è possibile eseguire i comandi seguenti:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Risoluzione
È possibile aumentare la memoria del server cronologia Spark modificando la proprietà SPARK_DAEMON_MEMORY nella configurazione di Spark e riavviando tutti i servizi.
È possibile eseguire questa operazione dall'interfaccia utente del browser Ambari selezionando la sezione Spark2/Config/Advanced spark2-env.
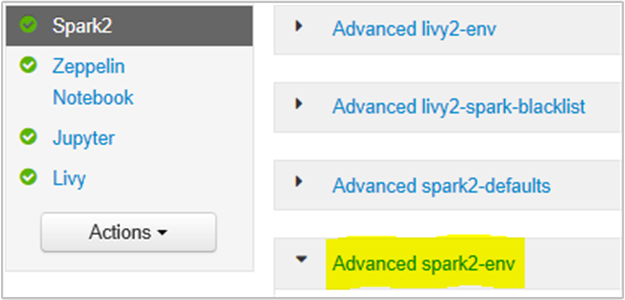
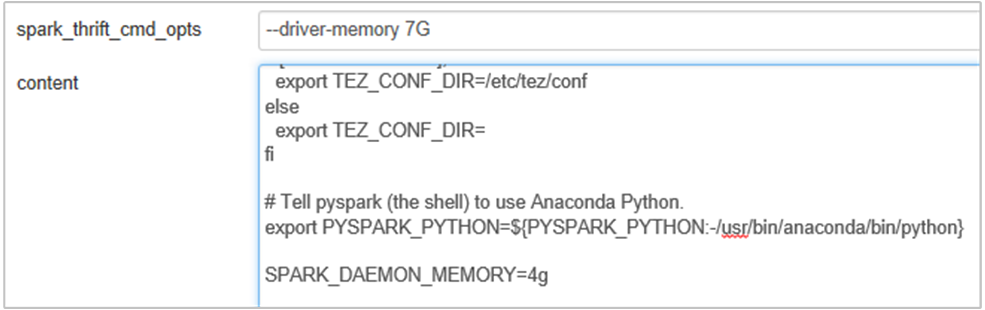
Aggiungere la proprietà seguente per modificare la memoria del server cronologia Spark da 1g a 4g: SPARK_DAEMON_MEMORY=4g.
Assicurarsi di riavviare tutti i servizi interessati da Ambari.
Scenario: l'avvio del server Livy non riesce nel cluster Apache Spark
Problema
Non è possibile avviare Livy Server in apache Spark [(Spark 2.1 in Linux (HDI 3.6)]. Il tentativo di riavvio comporta lo stack di errori seguente, dai log Livy:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Causa
java.lang.OutOfMemoryError: unable to create new native thread evidenzia che il sistema operativo non può assegnare più thread nativi a JVM. Confermato che questa eccezione è causata dalla violazione del limite di conteggio dei thread per processo.
Quando Livy Server termina in modo imprevisto, vengono terminate anche tutte le connessioni ai cluster Spark, il che significa che tutti i processi e i dati correlati vengono persi. In HDP 2.6 è stato introdotto il meccanismo di recupero della sessione, Livy archivia i dettagli della sessione in Zookeeper da recuperare dopo che Livy Server è tornato.
Quando un numero così elevato di processi viene inviato tramite Livy, nell'ambito della disponibilità elevata per il server Livy archivia questi stati di sessione in cluster ZK (in cluster HDInsight) e ripristina tali sessioni quando il servizio Livy viene riavviato. Al riavvio dopo la terminazione imprevista, Livy crea un thread per sessione e questo accumula alcune sessioni di recupero che causano la creazione di troppi thread.
Risoluzione
Eliminare tutte le voci seguendo questa procedura.
Ottenere l'indirizzo IP dei nodi zookeeper usando
grep -R zk /etc/hadoop/confIl comando precedente elenca tutti gli zookeeper per un cluster
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Ottenere tutti gli indirizzi IP dei nodi zookeeper usando ping Oppure è anche possibile connettersi a zookeeper dal nodo head usando il nome zookeeper
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Dopo aver eseguito la connessione a zookeeper, eseguire il comando seguente per elencare tutte le sessioni che si è tentato di riavviare.
La maggior parte dei casi potrebbe trattarsi di un elenco di più di 8000 sessioni ####
ls /livy/v1/batchIl comando seguente consiste nel rimuovere tutte le sessioni da ripristinare. #####
rmr /livy/v1/batch
Attendere il completamento del comando precedente e il cursore per restituire il prompt e quindi riavviare il servizio Livy da Ambari, che dovrebbe avere esito positivo.
Nota
DELETE la sessione Livy una volta completata l'esecuzione. Le sessioni batch Livy non verranno eliminate automaticamente non appena l'app Spark viene completata, ovvero in base alla progettazione. Una sessione Livy è un'entità creata da una richiesta POST sul server REST Livy. Per eliminare l'entità è necessaria una chiamata DELETE. O dovremmo aspettare che il GC inizi.
Passaggi successivi
Se il problema riscontrato non è presente in questo elenco o se non si riesce a risolverlo, visitare uno dei canali seguenti per ottenere ulteriore assistenza:
Eseguire il debug dell'applicazione Spark nei cluster HDInsight.
Ricevere risposte dagli esperti di Azure tramite la pagina Supporto della community per Azure.
Connettersi con @AzureSupport, l'account ufficiale Microsoft Azure per migliorare l'esperienza del cliente. Mette in contatto la community di Azure con le risorse giuste: risposte, supporto ed esperti.
Se serve ulteriore assistenza, è possibile inviare una richiesta di supporto dal portale di Azure. Selezionare Supporto nella barra dei menu o aprire l'hub Guida e supporto. Per informazioni più dettagliate, vedere Come creare una richiesta di supporto in Azure. L'accesso al supporto per la gestione delle sottoscrizioni e la fatturazione è incluso nella sottoscrizione di Microsoft Azure e il supporto tecnico viene fornito tramite uno dei piani di supporto di Azure.