Informazioni su Apache Kafka in Azure HDInsight
Apache Kafka è una piattaforma di streaming open source distribuita che può essere usata per compilare applicazioni e pipeline di dati in streaming in tempo reale. Kafka offre anche una funzionalità di broker di messaggi simile a una coda di messaggi, dove è possibile pubblicare e sottoscrivere flussi dei dati denominati.
Di seguito sono illustrate le caratteristiche specifiche di Kafka in HDInsight:
È un servizio gestito che fornisce un processo di configurazione semplificato. Il risultato è una configurazione che viene testata e supportata da Microsoft.
Microsoft fornisce un Contratto di servizio (SLA) con disponibilità del 99,9% nel tempo di attività di Kafka. Per altre informazioni, vedere il documento Contratto di servizio per HDInsight.
Usa gli Azure Managed Disks come archivio di backup per Kafka. I Managed Disks possono offrire fino a 16 TB di spazio di archiviazione per broker Kafka. Per informazioni sulla configurazione di dischi gestiti con Kafka in HDInsight, vedere Configurare l'archiviazione e la scalabilità per Apache Kafka in HDInsight.
Per altre informazioni sui dischi gestiti, vedere Panoramica di Azure Managed Disks.
Kafka è stato progettato con una singola vista dimensionale di un rack. Azure separa un rack in due dimensioni: domini di aggiornamento (UD) e domini di errore (FD). Microsoft offre strumenti che consentono il ribilanciamento delle partizioni e delle repliche Kafka tra domini di aggiornamento e domini di errore.
Per altre informazioni, vedere l'articolo relativo alla disponibilità elevata con Apache Kafka in HDInsight.
HDInsight consente di modificare il numero dei nodi di lavoro, che ospitano il broker Kafka, dopo la creazione del cluster. L'operazione di aumento può essere eseguita tramite il portale di Azure, Azure PowerShell e altre interfacce di gestione di Azure. Per Kafka, è consigliabile ribilanciare le repliche delle partizioni dopo le operazioni di ridimensionamento. Il ribilanciamento delle partizioni consente a Kafka di sfruttare il nuovo numero di nodi di lavoro.
HDInsight Kafka non supporta le operazioni di riduzione e la riduzione del numero di broker all'interno di un cluster. Se si tenta di ridurre il numero di nodi, viene restituito un errore di tipo
InvalidKafkaScaleDownRequestErrorCode.Per altre informazioni, vedere l'articolo relativo alla disponibilità elevata con Apache Kafka in HDInsight.
I log di Monitoraggio di Azure possono essere usati per monitorare Kafka in HDInsight. I log di Monitoraggio di Azure presentano informazioni a livello di macchina virtuale, come le metriche relative a dischi e schede di interfaccia di rete e le metriche JMX di Kafka.
Per altre informazioni, vedere Analizzare i log per Apache Kafka in HDInsight.
Apache Kafka sull'architettura di HDInsight
Il diagramma seguente mostra una configurazione tipica di Kafka che usa gruppi di consumer, partizionamento e replica per offrire la lettura parallela degli eventi con tolleranza di errore:
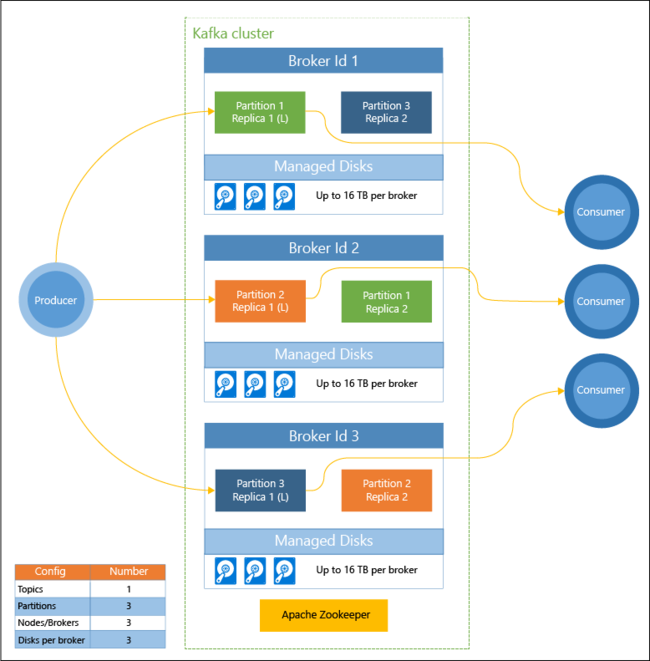
Apache ZooKeeper gestisce lo stato del cluster Kafka. Zookeeper è stato compilato per le transazioni simultanee, resilienti e a bassa latenza.
Kafka archivia i record (dati) in argomenti. I record vengono prodotti da producer e usati da consumer. I producer inviano i record ai broker Kafka. Ogni nodo del ruolo di lavoro nel cluster HDInsight è un broker Kafka.
Record di partizione degli argomenti tra broker. Quando si usano i record, è possibile usare fino a un consumer per partizione, per ottenere l'elaborazione parallela dei dati.
Viene usata la replica per duplicare le partizioni tra i nodi e garantire protezione in caso di interruzioni dei nodi (broker). Una partizione indicata da (L) nel diagramma rappresenta l'elemento leader per la partizione specifica. Il traffico dei producer viene indirizzato al leader di ogni nodo, usando lo stato gestito da ZooKeeper.
Perché usare Apache Kafka in HDInsight?
Quelli che seguono sono attività e criteri comuni che possono essere eseguiti usando Kafka in HDInsight:
| Usare | Descrizione |
|---|---|
| Replica dei dati di Apache Kafka | Kafka offre l'utilità MirrorMaker, che replica i dati tra cluster Kafka. Per informazioni sull'uso di MirrorMaker, vedere l'articolo su come replicare gli argomenti Apache Kafka con Apache Kafka in HDInsight. |
| Modello messaggistica di tipo pubblicazione-sottoscrizione | Kafka offre un'API Producer per la pubblicazione di record in un argomento Kafka. L'API Consumer viene usata quando si sottoscrive un argomento. Per altre informazioni, vedere Iniziare a usare Apache Kafka in HDInsight. |
| Elaborazione dei flussi | Kafka viene spesso usato con Spark per l'elaborazione dei flussi in tempo reale. Kafka 2.1.1 e 2.4.1 (HDInsight versione 4.0 e 5.0) supportano l'API di streaming che consente di compilare soluzioni di streaming senza richiedere Spark. Per altre informazioni, vedere Iniziare a usare Apache Kafka in HDInsight. |
| Scalabilità orizzontale | le partizioni Kafka trasmettono nei nodi del cluster HDInsight. È possibile associare processi consumer a singole partizioni per garantire il bilanciamento del carico durante l'utilizzo dei record. Per altre informazioni, vedere Iniziare a usare Apache Kafka in HDInsight. |
| Recapito in ordine | all'interno di ogni partizione, i record vengono archiviati nel flusso nell'ordine in cui sono stati ricevuti. Associando un processo consumer per partizione, è possibile garantire che i record vengano elaborati in ordine. Per altre informazioni, vedere Iniziare a usare Apache Kafka in HDInsight. |
| Messaggistica | poiché supporta il modello di pubblicazione-sottoscrizione dei messaggi, Kafka viene spesso usato come broker di messaggi. |
| Rilevamento attività | poiché Kafka offre la registrazione ordinata dei record, può essere usato per tenere traccia delle attività e per ricrearle. Ad esempio, le azioni dell'utente in un sito Web o in un'applicazione. |
| Aggregazione | Usando l'elaborazione dei flussi, è possibile aggregare informazioni da flussi diversi per combinarle e centralizzarle in dati operativi. |
| Trasformazione | Usando l'elaborazione dei flussi, è possibile combinare e arricchire dati da più argomenti di input in uno o più argomenti di output. |
Passaggi successivi
Usare i collegamenti seguenti per informazioni su come usare Apache Kafka in HDInsight: