Esempio dello streaming Apache Spark (DStream) con Apache Kafka in HDInsight
Informazioni su come è possibile usare Apache Spark per trasmettere dati in streaming all'interno o all'esterno di Apache Kafka su HDInsight per mezzo di DStreams. Questo esempio usa un oggetto Jupyter Notebook che viene eseguito nel cluster Spark.
Nota
La procedura descritta in questo documento permette di creare un gruppo di risorse di Azure che contiene sia un cluster Spark in HDInsight che un cluster Kafka in HDInsight. Entrambi questi cluster si trovano all'interno di una rete virtuale di Azure, che consente al cluster Spark di comunicare direttamente con il cluster Kafka.
Al termine della procedura descritta in questo documento, eliminare i cluster per evitare costi supplementari.
Importante
In questo esempio viene usata la tecnologia DStreams, una tecnologia di streaming Spark meno recente. Per un esempio con funzionalità di streaming Spark più recenti, vedere il documento Streaming strutturato Spark con Apache Kafka.
Creare i cluster
Apache Kafka in HDInsight non fornisce l'accesso ai broker Kafka tramite Internet pubblico. Tutto ciò che comunica con Kafka deve trovarsi nella stessa rete virtuale di Azure dei nodi del cluster Kafka. Per questo esempio, i cluster Spark e Kafka si trovano entrambi in una rete virtuale di Azure. Il diagramma seguente illustra il flusso delle comunicazioni tra i cluster:
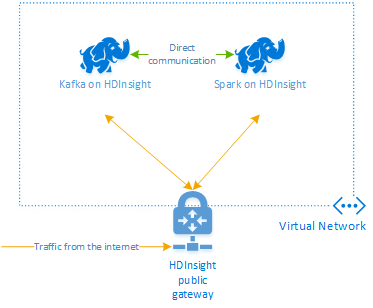
Nota
Anche se Kafka è limitato alle comunicazioni all'interno della rete virtuale, è possibile accedere ad altri servizi del cluster tramite Internet, ad esempio SSH e Ambari. Per altre informazioni sulle porte pubbliche disponibili con HDInsight, vedere Porte e URI usati da HDInsight.
Anche se è possibile creare manualmente cluster Spark e Kafka e una rete virtuale di Azure, è più semplice usare un modello di Azure Resource Manager. Seguire questa procedura per distribuire cluster Spark e Kafka e una rete virtuale di Azure nella sottoscrizione di Azure.
Usare il pulsante seguente per accedere ad Azure e aprire il modello nel portale di Azure.

Avviso
Per garantire la disponibilità di Kafka in HDInsight, il cluster deve contenere almeno quattro nodi di lavoro. Questo modello crea un cluster Kafka che contiene quattro nodi di lavoro.
Questo modello crea un cluster HDInsight 4.0 per Kafka e Spark.
Usare le informazioni seguenti per popolare le voci nel pannello Distribuzione personalizzata:
Proprietà valore Gruppo di risorse creare un gruppo o selezionarne uno esistente. Ufficio Selezionare una località geograficamente vicina. Nome del cluster di base questo valore viene usato come nome di base per i cluster Spark e Kafka. Ad esempio, se si immette hdistreaming viene creato un cluster Spark denominato spark-hdistreaming e un cluster Kafka denominato kafka-hdistreaming. Nome utente dell'account di accesso del cluster nome utente amministratore per i cluster Spark e Kafka. Password di accesso al cluster password dell'utente amministratore per i cluster Spark e Kafka. Nome utente SSH utente SSH da creare per i cluster Spark e Kafka. Password SSH password dell'utente SSH per i cluster Spark e Kafka. 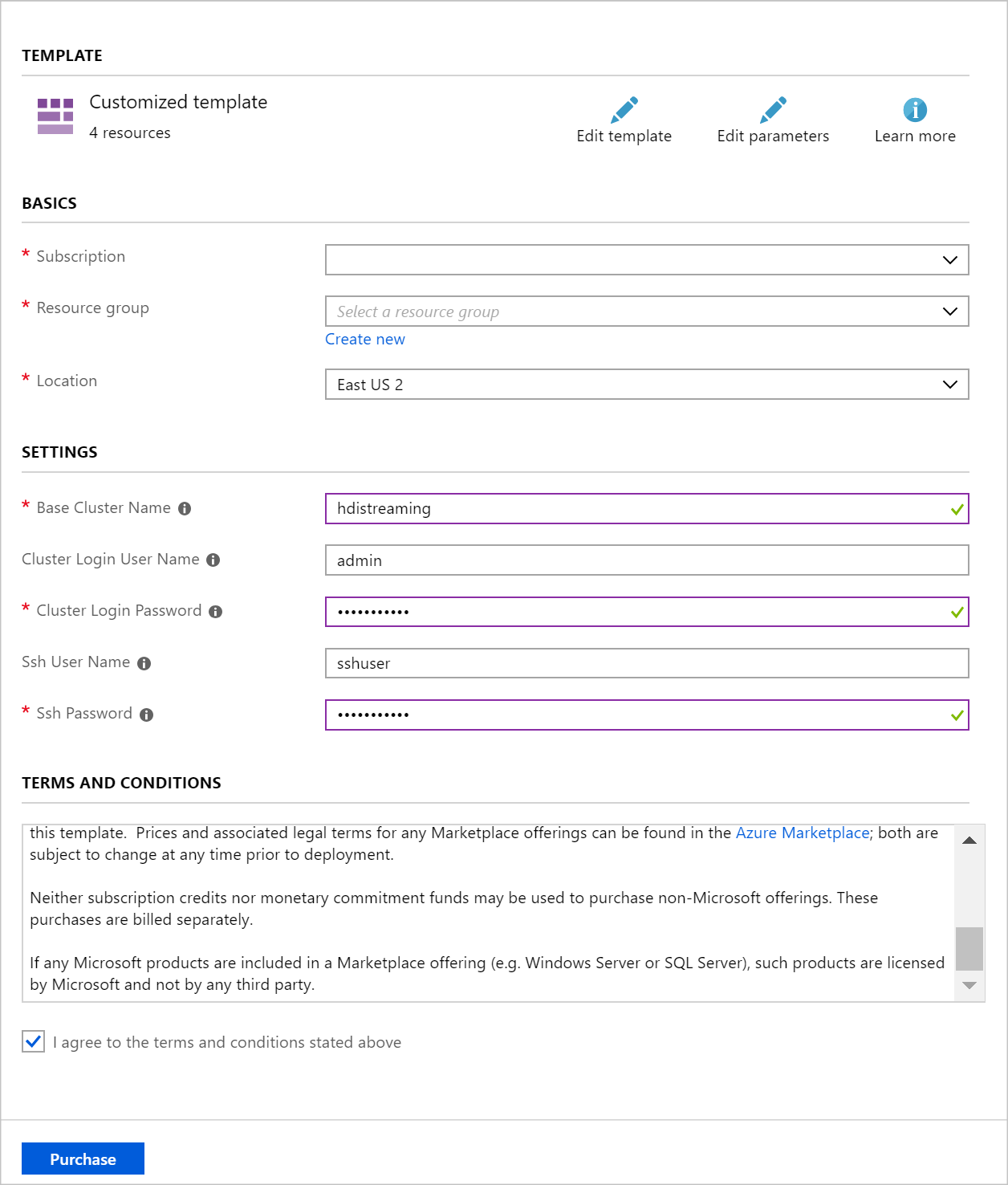
Leggere le Condizioni e quindi selezionare Accetto le condizioni riportate sopra.
Infine selezionare Acquisto. La creazione dei cluster richiede circa 20 minuti.
Dopo avere create le risorse, verrà visualizzata una pagina di riepilogo.
Importante
Si noti che i nomi dei cluster HDInsight sono spark-BASENAME e kafka-BASENAME, dove BASENAME è il nome specificato per il modello. Questi nomi verranno usati nei passaggi successivi per la connessione ai cluster.
Usare i notebook
Il codice di esempio descritto in questo documento è disponibile all'indirizzo https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Eliminare il cluster
Avviso
La fatturazione dei cluster HDInsight viene calcolata al minuto, indipendentemente dal fatto che siano usati o meno. Assicurarsi di eliminare il cluster dopo aver finito di usarlo. Vedere Come eliminare un cluster HDInsight.
Le procedure illustrate in questo documento creano entrambi i cluster nello stesso gruppo di risorse di Azure. È quindi possibile eliminare il gruppo di risorse dal portale di Azure. In questo modo vengono rimosse tutte le risorse create seguendo le istruzioni di questo documento, la rete virtuale di Azure e l'account di archiviazione usato dai cluster.
Passaggi successivi
Questo esempio ha illustrato l'uso di Spark per leggere e scrivere in Kafka. Per trovare altri modi per lavorare con Kafka, vedere i collegamenti seguenti: